") 基于實(shí)體和動(dòng)作時(shí)空建模的視頻文本預(yù)訓(xùn)練
基于實(shí)體和動(dòng)作時(shí)空建模的視頻文本預(yù)訓(xùn)練
摘要
盡管常見的大規(guī)模視頻-文本預(yù)訓(xùn)練模型已經(jīng)在很多下游任務(wù)取得不錯(cuò)的效果,現(xiàn)有的模型通常將視頻或者文本視為一個(gè)整體建模跨模態(tài)的表示,顯示結(jié)合并建模細(xì)粒度信息的探索并不多,本文提出了STOA-VLP,一種時(shí)間和空間維度上同時(shí)建模動(dòng)態(tài)的實(shí)體和動(dòng)作信息的video-language預(yù)訓(xùn)練框架,以進(jìn)一步增強(qiáng)跨模態(tài)的細(xì)粒度關(guān)聯(lián)性。
簡(jiǎn)介
細(xì)粒度的信息對(duì)于理解視頻場(chǎng)景并建模跨模態(tài)關(guān)聯(lián)具有很重要的作用。如圖1-a中:基于視頻生成對(duì)應(yīng)的視頻描述,需要關(guān)注其中的人、狗兩個(gè)實(shí)體,隨著時(shí)間的推移,兩個(gè)實(shí)體之間的相對(duì)狀態(tài)和空間位置發(fā)生了變化,模型需要對(duì)動(dòng)態(tài)的實(shí)體信息和實(shí)體之間的交互進(jìn)行建模,才能正確地生成對(duì)應(yīng)的視頻描述。更進(jìn)一步地,如圖1-b中:在同一個(gè)視頻片段當(dāng)中,視頻中的實(shí)體,如猴子和貓之間的不同交互產(chǎn)生了多個(gè)不同的動(dòng)作狀態(tài),而問題就是針對(duì)相關(guān)聯(lián)的動(dòng)作提出的,模型不但需要建模視頻片段中的多個(gè)動(dòng)作,感知?jiǎng)幼鳡顟B(tài)的變化,還需要推理出動(dòng)作狀態(tài)之間的關(guān)聯(lián)才能得到正確的答案。
 圖1:例子
圖1:例子
在本文中,我們提出了一個(gè)視頻-文本預(yù)訓(xùn)練方法——STOA-VLP,通過顯式地建模時(shí)序相關(guān)的實(shí)體軌跡和多個(gè)時(shí)空動(dòng)作特征來更好地應(yīng)對(duì)視頻中實(shí)體的動(dòng)態(tài)變化和實(shí)體交互。此外,我們?cè)O(shè)計(jì)了兩個(gè)輔助預(yù)訓(xùn)練任務(wù):實(shí)體-文本對(duì)齊(object text alignment, OTA)任務(wù)和動(dòng)作集合預(yù)測(cè)(Action Set Prediction, ASP)任務(wù)以在與訓(xùn)練階段利用文本特征輔助建模前述的實(shí)體軌跡和動(dòng)作特征。
方法
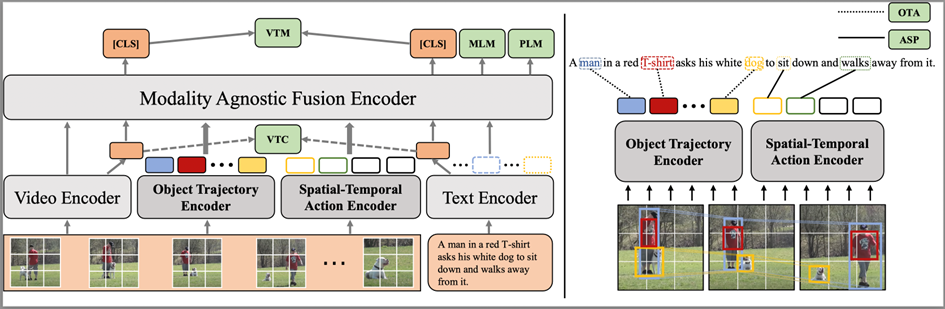 圖2:模型整體架構(gòu)
圖2:模型整體架構(gòu)
模型架構(gòu)
模型的整體架構(gòu)如圖2左側(cè)所示,模型整體結(jié)構(gòu)包括模態(tài)相關(guān)編碼器:視頻編碼器(Video Encoder)、文本編碼器(Text Encoder)、和一個(gè)模態(tài)無關(guān)編碼器(Modality-agnostic Fusion Encoder),文本和視頻分別經(jīng)過視頻和文本編碼器進(jìn)行特征抽取。為了顯式地建模動(dòng)態(tài)的實(shí)體軌跡和時(shí)空動(dòng)作特征,我們引入了兩個(gè)新的特征編碼器:實(shí)體軌跡編碼器(Object Trajectory Encoder)和時(shí)空動(dòng)作編碼器(Spatial-Temporal Action Encoder),我們從視頻幀中抽取實(shí)體的邊界框(bounding box)信息,其中的實(shí)體bounding box、分類信息用于與視頻特征結(jié)合生成對(duì)應(yīng)的實(shí)體有噪標(biāo)注,作為實(shí)體軌跡編碼器和時(shí)空動(dòng)作編碼器的輸入。最終,四個(gè)模態(tài)相關(guān)的編碼器抽取的特征會(huì)同時(shí)進(jìn)入模態(tài)無關(guān)編碼器進(jìn)行信息融合交互。所有的編碼器都采用Transformer[1]結(jié)構(gòu)。我們利用視頻編碼器和文本編碼器分別得到對(duì)應(yīng)的視頻、文本特征和,其余各模塊的具體介紹如下:
實(shí)體軌跡編碼追蹤器:正如前文例子所示,如果模型不能很好地建模視頻幀之間實(shí)體的動(dòng)態(tài)變化,在下游任務(wù)上可能無法獲得最好的效果。因此,我們通過建模跨視頻幀的有噪實(shí)體軌跡來解決這個(gè)問題:a. 使用離線的實(shí)體檢測(cè)模型(VinVL[2])分別對(duì)每一幀進(jìn)行實(shí)體檢測(cè)。b. 每幀保留Top-K個(gè)不同的實(shí)體,并且留下其候選框和類別,通過RoIAlign方法[3] 得到top-K個(gè)實(shí)體的表征:,為視頻編碼器編碼的視頻特征的塊(patch)級(jí)別的表征。c. 通過求和不同幀的候選實(shí)體檢測(cè)分類置信分?jǐn)?shù),選取top-N個(gè)實(shí)體類別用作視頻級(jí)需要建模軌跡的候選實(shí)體類別d. 我們將不同視頻幀抽取得到的實(shí)體特征拼接,并合并時(shí)間和實(shí)體維度,得到對(duì)應(yīng)的實(shí)體特征,針對(duì)步驟d中得到的Top-N實(shí)體類別,我們?yōu)槊總€(gè)類別構(gòu)造一個(gè)mask ,mask位置為1,代表中對(duì)應(yīng)位置的實(shí)體特征類別為。通過實(shí)體類別的mask和實(shí)體特征矩陣,我們能夠掩碼得到對(duì)應(yīng)實(shí)體在不同幀的特征合成的特征軌跡,稱之為實(shí)體軌跡序列。e. 對(duì)于每個(gè)視頻,我們最終能夠構(gòu)造得到N個(gè)實(shí)體軌跡序列,我們將其輸入實(shí)體軌跡編碼器,最終取位置的特征,得到實(shí)體軌跡特征。
時(shí)空動(dòng)作編碼器:識(shí)別視頻片段中動(dòng)作的關(guān)鍵是,識(shí)別場(chǎng)景中的實(shí)體,并建模實(shí)體在視頻場(chǎng)景中的移動(dòng)和不同的交互。在此,我們顯式建模多個(gè)動(dòng)作特征,以捕捉視頻片段中不同的動(dòng)作信息。a. 我們假設(shè)視頻片段中包含有M個(gè)不同的動(dòng)作,為了獲得每個(gè)動(dòng)作的特征,我們構(gòu)造M個(gè)動(dòng)作特征請(qǐng)求(query),。b. 我們使用前述通過視頻編碼器和實(shí)體檢測(cè)模型得到的視頻特征和對(duì)應(yīng)的實(shí)體表征,拼接得到包含場(chǎng)景和實(shí)體信息的視頻特征。c. 我們利用動(dòng)作特征query,通過注意力機(jī)制獲得幀級(jí)別的動(dòng)作特征線索:。d. 我們將每個(gè)動(dòng)作特征序列輸入到時(shí)空動(dòng)作編碼器當(dāng)中,來建模不同幀之間包含的時(shí)序線索,最后,我們得到的動(dòng)作特征編碼。
模態(tài)無關(guān)交互編碼器:通過拼接上游四個(gè)步驟的特征:視頻表征、文本表征、實(shí)體軌跡特征、時(shí)空動(dòng)作特征輸入對(duì)應(yīng)的編碼器進(jìn)行進(jìn)一步的交互,最后,我們?nèi)『臀恢玫妮敵鲎鳛橐曨l和文本的整體表征。
訓(xùn)練目標(biāo)
如圖2所示,STOA-VLP的預(yù)訓(xùn)練過程包含四類訓(xùn)練目標(biāo):視頻-文本對(duì)齊任務(wù)、條件語言建模任務(wù),以及我們提出的兩個(gè)輔助任務(wù)——?jiǎng)討B(tài)實(shí)體-文本對(duì)齊(Dynamic Object-Text Alignment, OTA)和時(shí)空動(dòng)作集合預(yù)測(cè)(Spatial-Temporal Action Set Prediction, ASP)。我們利用視覺-文本對(duì)比學(xué)習(xí)任務(wù)(Visual-Text Contrastive, VTC)和視覺-文本對(duì)齊任務(wù)(Visual-Text Maching)建模視頻-文本的粗粒度對(duì)齊。利用掩碼語言建模(MLM)和前綴語言建模(PLM)來增強(qiáng)模態(tài)無關(guān)編碼器的語言理解和生成能力。為了進(jìn)一步提升實(shí)體軌跡追蹤編碼器的效果,建立細(xì)粒度的跨模態(tài)對(duì)齊表示,我們通過OTA任務(wù)對(duì)齊候選實(shí)體軌跡和文本中相關(guān)文本,以進(jìn)一步提高通過視頻特征得到的實(shí)體軌跡和文本特征的相關(guān)性:
通過詞性標(biāo)注工具,抽取文本中的名詞用作對(duì)齊候選,并使用對(duì)應(yīng)的文本編碼器輸出對(duì)應(yīng)的名詞特征
使用軌跡追蹤編碼器輸出的軌跡特征和名詞特征的相似度為他們之間的關(guān)聯(lián)權(quán)重
最終使用匈牙利算法[4]得到二分圖的最大匹配,模型的目標(biāo)是盡力提高最大匹配的相似度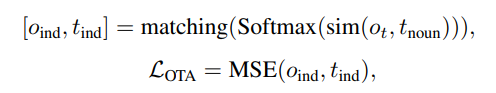 相比于利用抽取得到的特征直接預(yù)測(cè)有限的動(dòng)作類別,我們?cè)谶@里選擇了一種更彈性的方法——從匹配文本中的動(dòng)詞集合中預(yù)測(cè)對(duì)應(yīng)于當(dāng)前動(dòng)作特征的類別,以指導(dǎo)時(shí)空動(dòng)作編碼器的學(xué)習(xí):
相比于利用抽取得到的特征直接預(yù)測(cè)有限的動(dòng)作類別,我們?cè)谶@里選擇了一種更彈性的方法——從匹配文本中的動(dòng)詞集合中預(yù)測(cè)對(duì)應(yīng)于當(dāng)前動(dòng)作特征的類別,以指導(dǎo)時(shí)空動(dòng)作編碼器的學(xué)習(xí):
我們利用詞性標(biāo)注工具和文本編碼器得到對(duì)應(yīng)的動(dòng)詞特征集合。
我們并不能直接標(biāo)注視頻中包含的動(dòng)作類別,也無法知道編碼得到的動(dòng)作特征和文本中包含動(dòng)作的對(duì)應(yīng)關(guān)系,因此我們同樣在這里通過動(dòng)作特征和文本動(dòng)詞特征之間的相似度作為關(guān)聯(lián)權(quán)重,并將最大匹配視為當(dāng)前的ground truth匹配關(guān)系,并最大化最大匹配的相似度: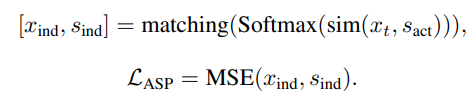 通過優(yōu)化該目標(biāo),比我們編碼的動(dòng)作特征和文本中的動(dòng)詞特征距離將被拉近,動(dòng)作編碼器能夠生成和文本特征更相關(guān)的特征。
通過優(yōu)化該目標(biāo),比我們編碼的動(dòng)作特征和文本中的動(dòng)詞特征距離將被拉近,動(dòng)作編碼器能夠生成和文本特征更相關(guān)的特征。
實(shí)驗(yàn)
實(shí)驗(yàn)細(xì)節(jié)
我們?cè)赪ebVid-2M[5]數(shù)據(jù)集上進(jìn)行模型的預(yù)訓(xùn)練,WebVid-2M包含了250萬個(gè)從網(wǎng)絡(luò)中收集的視頻-文本對(duì)。我們利用CLIP-ViT-B/16[6]初始化我們的視頻編碼器,并用其頂層參數(shù)初始化實(shí)體軌跡編碼器和時(shí)空動(dòng)作編碼器。文本編碼器和模態(tài)編碼器由CLIP文本編碼器的前6層初始化。實(shí)體軌跡編碼的數(shù)量為20,動(dòng)作特征的個(gè)數(shù)為4。
下游任務(wù)
我們?cè)谌惓S玫囊曨l-文本理解和生成任務(wù)上進(jìn)行了實(shí)驗(yàn):視頻描述生成,文本-視頻檢索和視頻問答。
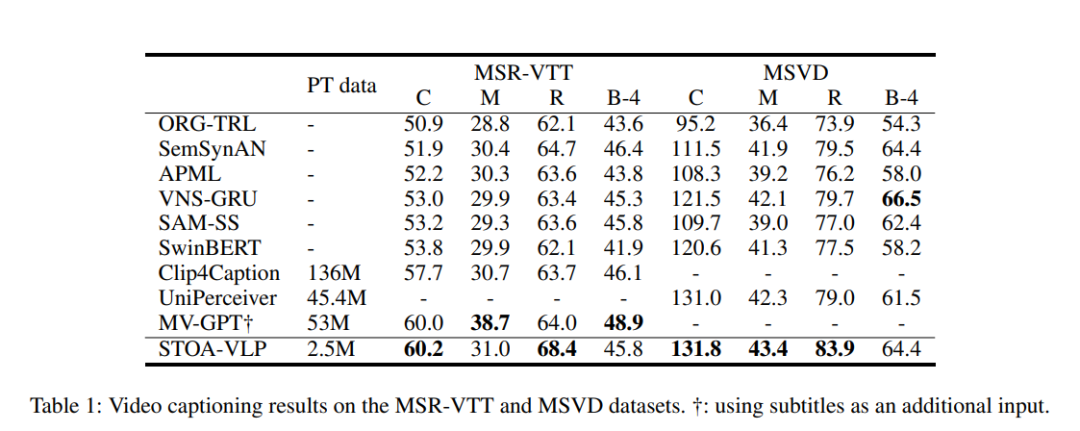 表1:視頻描述生成的實(shí)驗(yàn)結(jié)果
表1:視頻描述生成的實(shí)驗(yàn)結(jié)果
在使用更少的視頻-文本預(yù)訓(xùn)練數(shù)據(jù)的情況下,我們的模型在視頻描述生成上得到了更好的結(jié)果,在多數(shù)指標(biāo)上都超過了其他的模型。通過顯式地建模基于文本信息對(duì)齊的實(shí)體軌跡和動(dòng)作信息,模型能夠更好地利用其進(jìn)行視頻描述生成。
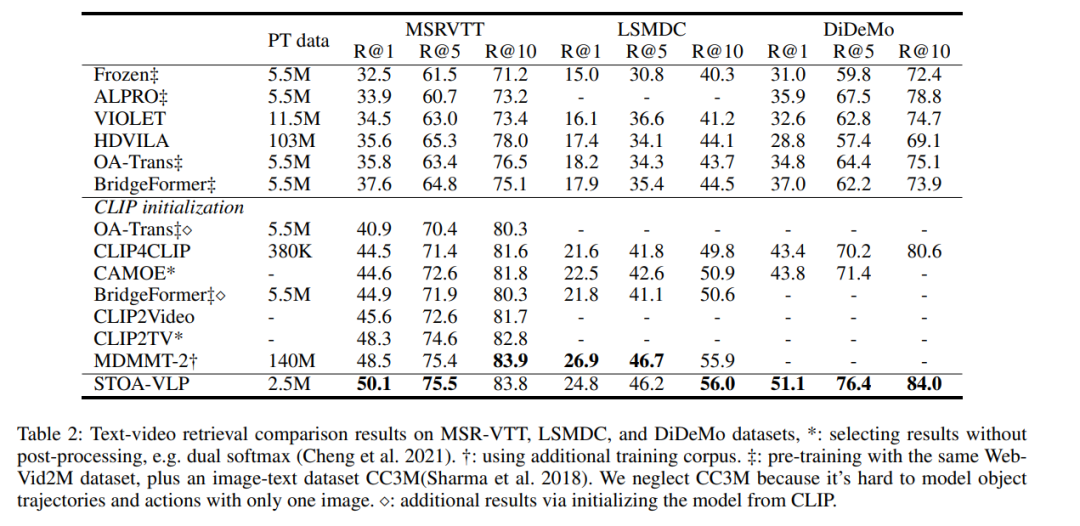 表2:文本-視頻檢索的實(shí)驗(yàn)結(jié)果
表2:文本-視頻檢索的實(shí)驗(yàn)結(jié)果
如表2所示,我們的模型在檢索任務(wù)上的所有指標(biāo)都超過了未基于CLIP初始化的模型,并且在大多數(shù)指標(biāo)上均超過了基于CLIP初始化的模型。
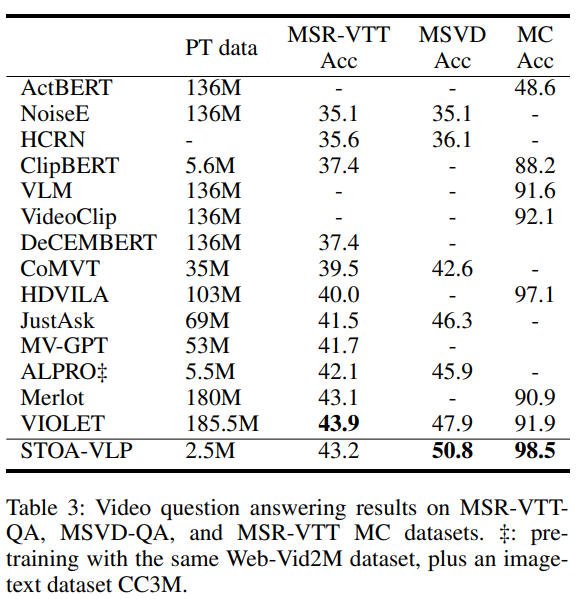 表3:視頻問答的實(shí)驗(yàn)結(jié)果
表3:視頻問答的實(shí)驗(yàn)結(jié)果
如表3所示,在視頻問答任務(wù)上,我們的模型僅使用了2.5M的預(yù)訓(xùn)練數(shù)據(jù),超越了MSVD-QA上的所有其他方法。與之前的SOTA,MSVD-QA的性能提高2.9%,MSR-VTT-MC的性能提高1.4%。我們推測(cè),通過顯式地建模實(shí)體軌跡和動(dòng)作,在問題和視覺特征之間建立了更好的對(duì)齊,并觀察和利用視頻中的細(xì)粒度信息來更好地回答文本問題。
消融實(shí)驗(yàn)
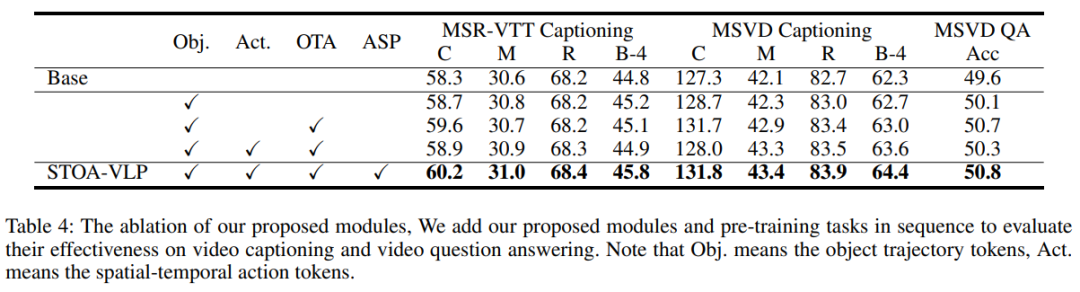 表4:不同模塊的消融實(shí)驗(yàn)
表4:不同模塊的消融實(shí)驗(yàn)
我們進(jìn)一步分析了我們引入的時(shí)空特征和輔助任務(wù)的影響,并在視頻描述生成和視頻問答兩個(gè)任務(wù)上驗(yàn)證,這兩個(gè)任務(wù)在本質(zhì)上需要更細(xì)粒度的信息和對(duì)視頻場(chǎng)景時(shí)空信息的理解。Base模型刪除了所有時(shí)空建模模塊和輔助建模任務(wù)。與Base模型相比,僅僅引入基于時(shí)序的實(shí)體軌跡信息就可以為所有任務(wù)帶來改進(jìn)。我們的OTA任務(wù)進(jìn)一步構(gòu)建了實(shí)體軌跡和名詞之間的細(xì)粒度對(duì)齊,文本模態(tài)的指導(dǎo)進(jìn)一步提升了模型在下游任務(wù)當(dāng)中的表現(xiàn)。我們還發(fā)現(xiàn),不引入輔助任務(wù)ASP的情況下,添加一個(gè)時(shí)空動(dòng)作建模模塊引入時(shí)空動(dòng)作token會(huì)使得下游任務(wù)的部分指標(biāo)更差。我們認(rèn)為,這可能是因?yàn)橐曨l描述生成和視頻問答任務(wù)需要對(duì)視覺部分進(jìn)行細(xì)粒度的語義理解,如果沒有ASP任務(wù)的指導(dǎo),我們抽取的動(dòng)作特征的含義是模糊的,其導(dǎo)致了性能下降。最后,連同我們提出的時(shí)空模塊和兩個(gè)輔助任務(wù),我們?cè)谙掠稳蝿?wù)上取得了最好的結(jié)果,表明我們引入的細(xì)粒度時(shí)空信息和輔助任務(wù)能夠提升預(yù)訓(xùn)練模型在下游任務(wù)的能力,一定程度上緩解了前述的問題。
結(jié)論
在本文中,我們通過在視頻-文本預(yù)訓(xùn)練的過程中顯式建模細(xì)粒度的時(shí)空特征來更好地構(gòu)建跨模態(tài)的對(duì)齊。我們提出的STOA-VLP引入了兩個(gè)新的模塊,在時(shí)空維度上建模實(shí)體軌跡和動(dòng)作特征。我們?cè)O(shè)計(jì)了兩個(gè)輔助任務(wù)來建立由粗到細(xì)的跨模態(tài)對(duì)齊。僅僅使用中等規(guī)模的與訓(xùn)練數(shù)據(jù),我們?cè)谙掠稳蝿?wù)上就觀察到了較好的表現(xiàn),該方法進(jìn)一步增強(qiáng)了視覺特征和文本特征之間的關(guān)聯(lián)性。
-
編碼器
+關(guān)注
關(guān)注
45文章
3740瀏覽量
136359 -
建模
+關(guān)注
關(guān)注
1文章
315瀏覽量
61290 -
模型
+關(guān)注
關(guān)注
1文章
3452瀏覽量
49727
原文標(biāo)題:AAAI 2023 | 基于實(shí)體和動(dòng)作時(shí)空建模的視頻文本預(yù)訓(xùn)練
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
為什么要使用預(yù)訓(xùn)練模型?8種優(yōu)秀預(yù)訓(xùn)練模型大盤點(diǎn)
一種側(cè)重于學(xué)習(xí)情感特征的預(yù)訓(xùn)練方法

基于BERT的中文科技NLP預(yù)訓(xùn)練模型
怎樣去增強(qiáng)PLM對(duì)于實(shí)體和實(shí)體間關(guān)系的理解?
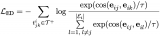
多模態(tài)圖像-文本預(yù)訓(xùn)練模型

如何實(shí)現(xiàn)更綠色、經(jīng)濟(jì)的NLP預(yù)訓(xùn)練模型遷移
文本預(yù)訓(xùn)練的模型架構(gòu)及相關(guān)數(shù)據(jù)集
利用視覺語言模型對(duì)檢測(cè)器進(jìn)行預(yù)訓(xùn)練
基于VQVAE的長(zhǎng)文本生成 利用離散code來建模文本篇章結(jié)構(gòu)的方法
復(fù)旦&微軟提出?OmniVL:首個(gè)統(tǒng)一圖像、視頻、文本的基礎(chǔ)預(yù)訓(xùn)練模型
預(yù)訓(xùn)練數(shù)據(jù)大小對(duì)于預(yù)訓(xùn)練模型的影響
ELMER: 高效強(qiáng)大的非自回歸預(yù)訓(xùn)練文本生成模型
NLP中的遷移學(xué)習(xí):利用預(yù)訓(xùn)練模型進(jìn)行文本分類
基于文本到圖像模型的可控文本到視頻生成






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論