 PyTorch教程-5.7. 在 Kaggle 上預測房價
PyTorch教程-5.7. 在 Kaggle 上預測房價

現在我們已經介紹了一些用于構建和訓練深度網絡并使用包括權重衰減和丟失在內的技術對其進行正則化的基本工具,我們準備通過參加 Kaggle 競賽將所有這些知識付諸實踐。房價預測競賽是一個很好的起點。數據相當通用,沒有表現出可能需要專門模型(如音頻或視頻可能)的奇異結構。該數據集由 De Cock ( 2011 )收集,涵蓋 2006 年至 2010 年愛荷華州埃姆斯的房價。 它比Harrison 和 Rubinfeld (1978)著名的波士頓住房數據集大得多,擁有更多的例子和更多的特征。
在本節中,我們將帶您了解數據預處理、模型設計和超參數選擇的詳細信息。我們希望通過實踐方法,您將獲得一些直覺,這些直覺將指導您作為數據科學家的職業生涯。
%matplotlib inline import pandas as pd import torch from torch import nn from d2l import torch as d2l
%matplotlib inline import pandas as pd from mxnet import autograd, gluon, init, np, npx from mxnet.gluon import nn from d2l import mxnet as d2l npx.set_np()
%matplotlib inline import jax import numpy as np import pandas as pd from jax import numpy as jnp from d2l import jax as d2l
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
%matplotlib inline import pandas as pd import tensorflow as tf from d2l import tensorflow as d2l
5.7.1. 下載數據
在整本書中,我們將在各種下載的數據集上訓練和測試模型。在這里,我們實現了兩個實用函數來下載文件和提取 zip 或 tar 文件。同樣,我們將它們的實現推遲到 第 23.7 節。
def download(url, folder, sha1_hash=None): """Download a file to folder and return the local filepath.""" def extract(filename, folder): """Extract a zip/tar file into folder."""
5.7.2. 格格
Kaggle是一個舉辦機器學習競賽的流行平臺。每場比賽都以數據集為中心,許多比賽由利益相關者贊助,他們為獲勝的解決方案提供獎勵。該平臺幫助用戶通過論壇和共享代碼進行交互,促進協作和競爭。雖然排行榜追逐經常失控,研究人員短視地關注預處理步驟而不是提出基本問題,但平臺的客觀性也具有巨大價值,該平臺有助于競爭方法之間的直接定量比較以及代碼共享,以便每個人都可以了解哪些有效,哪些無效。如果你想參加 Kaggle 比賽,你首先需要注冊一個賬號(見圖 5.7.1)。
圖 5.7.1 Kaggle 網站。
在房價預測比賽頁面,如圖 5.7.2所示,可以找到數據集(在“數據”選項卡下),提交預測,就可以看到你的排名,網址在這里:
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
圖 5.7.2房價預測比賽頁面。
5.7.3. 訪問和讀取數據集
請注意,比賽數據分為訓練集和測試集。每條記錄包括房屋的屬性值和街道類型、建造年份、屋頂類型、地下室狀況等屬性。特征由各種數據類型組成。例如,建造年份用整數表示,屋頂類型用離散的分類分配表示,其他特征用浮點數表示。這就是現實使事情復雜化的地方:例如,一些數據完全缺失,缺失值簡單地標記為“na”。每個房子的價格僅包含在訓練集中(畢竟這是一場比賽)。我們希望對訓練集進行分區以創建驗證集,但我們只能在將預測上傳到 Kaggle 后才能在官方測試集上評估我們的模型。圖 5.7.2有下載數據的鏈接。
首先,我們將pandas使用我們在第 2.2 節中介紹的方法讀入和處理數據。為了方便起見,我們可以下載并緩存 Kaggle 住房數據集。如果與此數據集對應的文件已存在于緩存目錄中并且其 SHA-1 匹配sha1_hash,我們的代碼將使用緩存文件以避免因冗余下載而阻塞您的互聯網。
class KaggleHouse(d2l.DataModule): def __init__(self, batch_size, train=None, val=None): super().__init__() self.save_hyperparameters() if self.train is None: self.raw_train = pd.read_csv(d2l.download( d2l.DATA_URL + 'kaggle_house_pred_train.csv', self.root, sha1_hash='585e9cc93e70b39160e7921475f9bcd7d31219ce')) self.raw_val = pd.read_csv(d2l.download( d2l.DATA_URL + 'kaggle_house_pred_test.csv', self.root, sha1_hash='fa19780a7b011d9b009e8bff8e99922a8ee2eb90'))
訓練數據集包含 1460 個示例、80 個特征和 1 個標簽,而驗證數據包含 1459 個示例和 80 個特征。
data = KaggleHouse(batch_size=64) print(data.raw_train.shape) print(data.raw_val.shape)
Downloading ../data/kaggle_house_pred_train.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv... Downloading ../data/kaggle_house_pred_test.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv... (1460, 81) (1459, 80)
data = KaggleHouse(batch_size=64) print(data.raw_train.shape) print(data.raw_val.shape)
Downloading ../data/kaggle_house_pred_train.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv... Downloading ../data/kaggle_house_pred_test.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv... (1460, 81) (1459, 80)
data = KaggleHouse(batch_size=64) print(data.raw_train.shape) print(data.raw_val.shape)
Downloading ../data/kaggle_house_pred_train.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv... Downloading ../data/kaggle_house_pred_test.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv... (1460, 81) (1459, 80)
data = KaggleHouse(batch_size=64) print(data.raw_train.shape) print(data.raw_val.shape)
Downloading ../data/kaggle_house_pred_train.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv... Downloading ../data/kaggle_house_pred_test.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv... (1460, 81) (1459, 80)
5.7.4. 數據預處理
我們來看看前四個和最后兩個特征以及前四個示例中的標簽 (SalePrice)。
print(data.raw_train.iloc[:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice 0 1 60 RL 65.0 WD Normal 208500 1 2 20 RL 80.0 WD Normal 181500 2 3 60 RL 68.0 WD Normal 223500 3 4 70 RL 60.0 WD Abnorml 140000
print(data.raw_train.iloc[:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice 0 1 60 RL 65.0 WD Normal 208500 1 2 20 RL 80.0 WD Normal 181500 2 3 60 RL 68.0 WD Normal 223500 3 4 70 RL 60.0 WD Abnorml 140000
print(data.raw_train.iloc[:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice 0 1 60 RL 65.0 WD Normal 208500 1 2 20 RL 80.0 WD Normal 181500 2 3 60 RL 68.0 WD Normal 223500 3 4 70 RL 60.0 WD Abnorml 140000
print(data.raw_train.iloc[:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice 0 1 60 RL 65.0 WD Normal 208500 1 2 20 RL 80.0 WD Normal 181500 2 3 60 RL 68.0 WD Normal 223500 3 4 70 RL 60.0 WD Abnorml 140000
我們可以看到,在每個示例中,第一個特征是 ID。這有助于模型識別每個訓練示例。雖然這很方便,但它不攜帶任何用于預測目的的信息。因此,我們將在將數據輸入模型之前將其從數據集中刪除。此外,鑒于數據類型多種多樣,我們需要在開始建模之前對數據進行預處理。
讓我們從數字特征開始。首先,我們應用啟發式方法,用相應特征的平均值替換所有缺失值。然后,為了將所有特征放在一個共同的尺度上,我們通過將特征重新縮放為零均值和單位方差來標準化數據:
(5.7.1)x←x?μσ,
在哪里μ和σ分別表示平均值和標準偏差。為了驗證這確實改變了我們的特征(變量),使其具有零均值和單位方差,請注意 E[x?μσ]=μ?μσ=0然后 E[(x?μ)2]=(σ2+μ2)?2μ2+μ2=σ2. 直覺上,我們標準化數據有兩個原因。首先,證明它便于優化。其次,因為我們先驗地不知道 哪些特征是相關的,所以我們不想懲罰分配給一個特征的系數比其他任何特征更多。
接下來我們處理離散值。這包括諸如“MSZoning”之類的功能。我們將它們替換為 one-hot 編碼,其方式與我們之前將多類標簽轉換為向量的方式相同(請參閱 第 4.1.1 節)。例如,“MSZoning”采用值“RL”和“RM”。刪除“MSZoning”特征,創建兩個新的指標特征“MSZoning_RL”和“MSZoning_RM”,其值為0或1。根據one-hot編碼,如果“MSZoning”的原始值為“RL”,則“ MSZoning_RL” 為 1,“MSZoning_RM” 為 0。pandas包會自動為我們完成此操作。
@d2l.add_to_class(KaggleHouse)
def preprocess(self):
# Remove the ID and label columns
label = 'SalePrice'
features = pd.concat(
(self.raw_train.drop(columns=['Id', label]),
self.raw_val.drop(columns=['Id'])))
# Standardize numerical columns
numeric_features = features.dtypes[features.dtypes!='object'].index
features[numeric_features] = features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# Replace NAN numerical features by 0
features[numeric_features] = features[numeric_features].fillna(0)
# Replace discrete features by one-hot encoding
features = pd.get_dummies(features, dummy_na=True)
# Save preprocessed features
self.train = features[:self.raw_train.shape[0]].copy()
self.train[label] = self.raw_train[label]
self.val = features[self.raw_train.shape[0]:].copy()
您可以看到此轉換將特征數量從 79 增加到 331(不包括 ID 和標簽列)。
data.preprocess() data.train.shape
(1460, 332)
data.preprocess() data.train.shape
(1460, 332)
data.preprocess() data.train.shape
(1460, 332)
data.preprocess() data.train.shape
(1460, 332)
5.7.5. 誤差測量
首先,我們將訓練一個具有平方損失的線性模型。毫不奇怪,我們的線性模型不會導致提交競賽獲勝,但它提供了完整性檢查以查看數據中是否存在有意義的信息。如果我們在這里不能比隨機猜測做得更好,那么我們很可能遇到數據處理錯誤。如果一切正常,線性模型將作為基線,讓我們直觀地了解簡單模型與最佳報告模型的接近程度,讓我們了解我們應該從更高級的模型中獲得多少收益。
對于房價,就像股票價格一樣,我們更關心相對數量而不是絕對數量。因此我們更傾向于關心相對誤差y?y^y比關于絕對誤差y?y^. 例如,如果我們在估計俄亥俄州農村地區的房屋價格時預測偏離 100,000 美元,那里典型房屋的價值為 125,000 美元,那么我們可能做得很糟糕。另一方面,如果我們在加利福尼亞州的 Los Altos Hills 出現這個數額的錯誤,這可能代表了一個驚人準確的預測(那里的房價中位數超過 400 萬美元)。
解決這個問題的一種方法是衡量價格估計的對數差異。事實上,這也是比賽用來評估提交質量的官方誤差衡量標準。畢竟價值不高δ為了 |log?y?log?y^|≤δ翻譯成 e?δ≤y^y≤eδ. 這導致預測價格的對數與標簽價格的對數之間存在以下均方根誤差:
(5.7.2)1n∑i=1n(log?yi?log?y^i)2.
@d2l.add_to_class(KaggleHouse)
def get_dataloader(self, train):
label = 'SalePrice'
data = self.train if train else self.val
if label not in data: return
get_tensor = lambda x: torch.tensor(x.values, dtype=torch.float32)
# Logarithm of prices
tensors = (get_tensor(data.drop(columns=[label])), # X
torch.log(get_tensor(data[label])).reshape((-1, 1))) # Y
return self.get_tensorloader(tensors, train)
@d2l.add_to_class(KaggleHouse)
def get_dataloader(self, train):
label = 'SalePrice'
data = self.train if train else self.val
if label not in data: return
get_tensor = lambda x: np.array(x.values, dtype=np.float32)
# Logarithm of prices
tensors = (get_tensor(data.drop(columns=[label])), # X
np.log(get_tensor(data[label])).reshape((-1, 1))) # Y
return self.get_tensorloader(tensors, train)
@d2l.add_to_class(KaggleHouse)
def get_dataloader(self, train):
label = 'SalePrice'
data = self.train if train else self.val
if label not in data: return
get_tensor = lambda x: jnp.array(x.values, dtype=jnp.float32)
# Logarithm of prices
tensors = (get_tensor(data.drop(columns=[label])), # X
jnp.log(get_tensor(data[label])).reshape((-1, 1))) # Y
return self.get_tensorloader(tensors, train)
@d2l.add_to_class(KaggleHouse)
def get_dataloader(self, train):
label = 'SalePrice'
data = self.train if train else self.val
if label not in data: return
get_tensor = lambda x: tf.constant(x.values, dtype=tf.float32)
# Logarithm of prices
tensors = (get_tensor(data.drop(columns=[label])), # X
tf.reshape(tf.math.log(get_tensor(data[label])), (-1, 1))) # Y
return self.get_tensorloader(tensors, train)
5.7.6.K-折疊交叉驗證
您可能還記得我們在第 3.6.3 節中介紹了交叉驗證 ,我們在那里討論了如何處理模型選擇。我們將充分利用它來選擇模型設計和調整超參數。我們首先需要一個返回ith將數據折疊成 K-折疊交叉驗證程序。它通過切出ith段作為驗證數據并將其余部分作為訓練數據返回。請注意,這不是處理數據的最有效方式,如果我們的數據集相當大,我們肯定會做一些更聰明的事情。但是這種增加的復雜性可能會不必要地混淆我們的代碼,因此由于問題的簡單性,我們可以在這里安全地省略它。
def k_fold_data(data, k):
rets = []
fold_size = data.train.shape[0] // k
for j in range(k):
idx = range(j * fold_size, (j+1) * fold_size)
rets.append(KaggleHouse(data.batch_size, data.train.drop(index=idx),
data.train.loc[idx]))
return rets
我們訓練時返回平均驗證錯誤K時間在K- 折疊交叉驗證。
def k_fold(trainer, data, k, lr):
val_loss, models = [], []
for i, data_fold in enumerate(k_fold_data(data, k)):
model = d2l.LinearRegression(lr)
model.board.yscale='log'
if i != 0: model.board.display = False
trainer.fit(model, data_fold)
val_loss.append(float(model.board.data['val_loss'][-1].y))
models.append(model)
print(f'average validation log mse = {sum(val_loss)/len(val_loss)}')
return models
5.7.7. 選型
在這個例子中,我們選擇了一組未調整的超參數,并留給讀者來改進模型。找到一個好的選擇可能需要時間,具體取決于優化了多少變量。有了足夠大的數據集和正常的超參數,K-折疊交叉驗證往往對多重測試具有合理的彈性。然而,如果我們嘗試了不合理的大量選項,我們可能會幸運地發現我們的驗證性能不再代表真正的錯誤。
trainer = d2l.Trainer(max_epochs=10) models = k_fold(trainer, data, k=5, lr=0.01)
average validation log mse = 0.17563143908977508

trainer = d2l.Trainer(max_epochs=10) models = k_fold(trainer, data, k=5, lr=0.01)
average validation log mse = 0.1256050333380699

trainer = d2l.Trainer(max_epochs=10) models = k_fold(trainer, data, k=5, lr=0.01)
average validation log mse = 0.1252850264310837

trainer = d2l.Trainer(max_epochs=10) models = k_fold(trainer, data, k=5, lr=0.01)
average validation log mse = 0.17464343845844268

請注意,有時一組超參數的訓練錯誤數量可能非常低,即使 K-折疊交叉驗證要高得多。這表明我們過度擬合。在整個培訓過程中,您需要監控這兩個數字。較少的過度擬合可能表明我們的數據可以支持更強大的模型。大規模過度擬合可能表明我們可以通過結合正則化技術來獲益。
5.7.8. 在 Kaggle 上提交預測
現在我們知道應該選擇什么樣的超參數,我們可以計算所有超參數對測試集的平均預測 K楷模。將預測保存在 csv 文件中將簡化將結果上傳到 Kaggle 的過程。以下代碼將生成一個名為submission.csv.
preds = [model(torch.tensor(data.val.values, dtype=torch.float32))
for model in models]
# Taking exponentiation of predictions in the logarithm scale
ensemble_preds = torch.exp(torch.cat(preds, 1)).mean(1)
submission = pd.DataFrame({'Id':data.raw_val.Id,
'SalePrice':ensemble_preds.detach().numpy()})
submission.to_csv('submission.csv', index=False)
preds = [model(np.array(data.val.values, dtype=np.float32))
for model in models]
# Taking exponentiation of predictions in the logarithm scale
ensemble_preds = np.exp(np.concatenate(preds, 1)).mean(1)
submission = pd.DataFrame({'Id':data.raw_val.Id,
'SalePrice':ensemble_preds.asnumpy()})
submission.to_csv('submission.csv', index=False)
preds = [model.apply({'params': trainer.state.params},
jnp.array(data.val.values, dtype=jnp.float32))
for model in models]
# Taking exponentiation of predictions in the logarithm scale
ensemble_preds = jnp.exp(jnp.concatenate(preds, 1)).mean(1)
submission = pd.DataFrame({'Id':data.raw_val.Id,
'SalePrice':np.asarray(ensemble_preds)})
submission.to_csv('submission.csv', index=False)
preds = [model(tf.constant(data.val.values, dtype=tf.float32))
for model in models]
# Taking exponentiation of predictions in the logarithm scale
ensemble_preds = tf.reduce_mean(tf.exp(tf.concat(preds, 1)), 1)
submission = pd.DataFrame({'Id':data.raw_val.Id,
'SalePrice':ensemble_preds.numpy()})
submission.to_csv('submission.csv', index=False)
接下來,如圖5.7.3所示,我們可以在 Kaggle 上提交我們的預測,并查看它們如何與測試集上的實際房價(標簽)進行比較。步驟很簡單:
登錄Kaggle網站,訪問房價預測比賽頁面。
單擊“提交預測”或“延遲提交”按鈕(截至撰寫本文時,該按鈕位于右側)。
單擊頁面底部虛線框中的“上傳提交文件”按鈕,然后選擇您要上傳的預測文件。
單擊頁面底部的“提交”按鈕以查看結果。
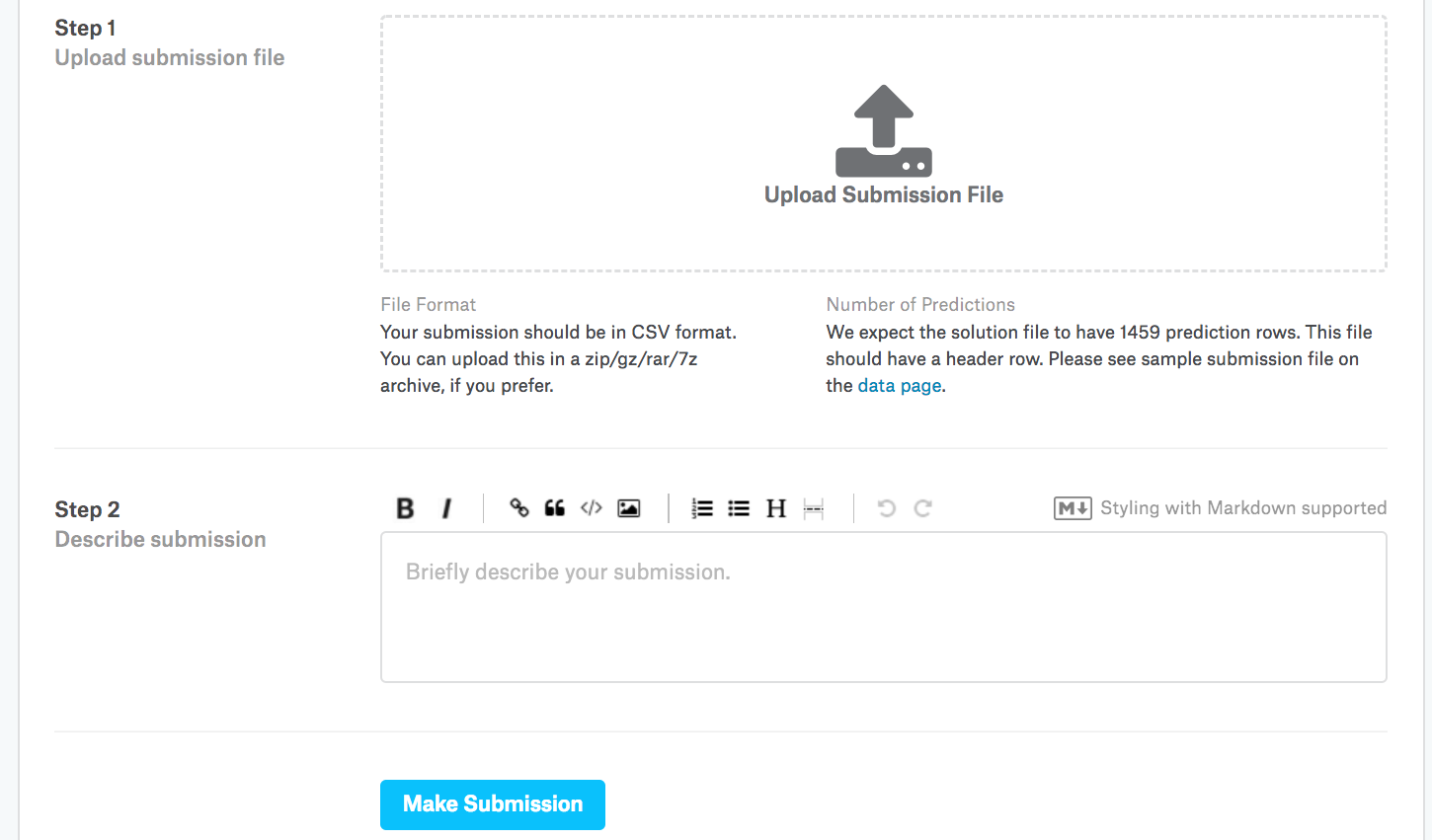
圖 5.7.3向 Kaggle 提交數據
5.7.9. 概括
真實數據通常包含不同數據類型的混合,需要進行預處理。將實值數據重新調整為零均值和單位方差是一個很好的默認值。用平均值替換缺失值也是如此。此外,將分類特征轉換為指示特征允許我們將它們視為單熱向量。當我們更關心相對誤差而不是絕對誤差時,我們可以用預測的對數來衡量差異。要選擇模型并調整超參數,我們可以使用K折疊交叉驗證。
5.7.10。練習
將你對本節的預測提交給 Kaggle。你的預測有多好?
用平均值替換缺失值總是一個好主意嗎?提示:你能構造一個值不隨機缺失的情況嗎?
通過調整超參數來提高 Kaggle 的分數 K- 折疊交叉驗證。
通過改進模型(例如,層數、權重衰減和丟失)來提高分數。
如果我們不像本節所做的那樣對連續數值特征進行標準化,會發生什么情況?
-
pytorch
+關注
關注
2文章
809瀏覽量
13914
發布評論請先 登錄
[原創]房價整體上漲推力到底是什么!
15年,房價變向降了
qiuzitao機器學習:桑坦德銀行客戶交易預測項目
在Ubuntu 18.04 for Arm上運行的TensorFlow和PyTorch的Docker映像
通過Cortex來非常方便的部署PyTorch模型
北京房價均降1萬!中國房價稱霸全球,北京房價均降一萬是皮毛!王健林的選擇是對是錯?
如何很容易地將數據共享為Kaggle數據集

這些年來,我們的數據科學究竟發生了什么變化?
如何使用改進GM模型進行房價預測模型資料說明

pytorch怎么在pycharm中運行
使用PyTorch在英特爾獨立顯卡上訓練模型





 工商網監
工商網監
評論