 大模型背景下,AI芯片廠商面臨怎樣的機遇與挑戰?
大模型背景下,AI芯片廠商面臨怎樣的機遇與挑戰?

從2022.11.30的ChatGPT,到2023.6.13的360智腦大模型2.0,全球AI界已為大模型持續瘋狂了七個多月。ChatGPT們正如雨后春筍般涌現,向AI市場投放一個個“炸彈”:辦公、醫療、教育、制造,亟需AI的賦能。
而AI應用千千萬,把大模型打造好才是硬道理。
對于大模型“世界”來說,算法是“生產關系”,是處理數據信息的規則與方式;算力是“生產力”,能夠提高數據處理、算法訓練的速度與規模;數據是“生產資料”,高質量的數據是驅動算法持續迭代的養分。在這之中,算力是讓大模型轉動的前提。
我們都知道的是,大模型正對算力提出史無前例的要求,具體的表現是:據英偉達數據顯示,在沒有以Transformer模型為基礎架構的大模型之前,算力需求大致是每兩年提升8倍;而自利用Transformer模型后,算力需求大致是每兩年提升275倍。基于此,530B參數量的Megatron-Turing NLG模型,將要吞噬超10億FLOPS的算力。
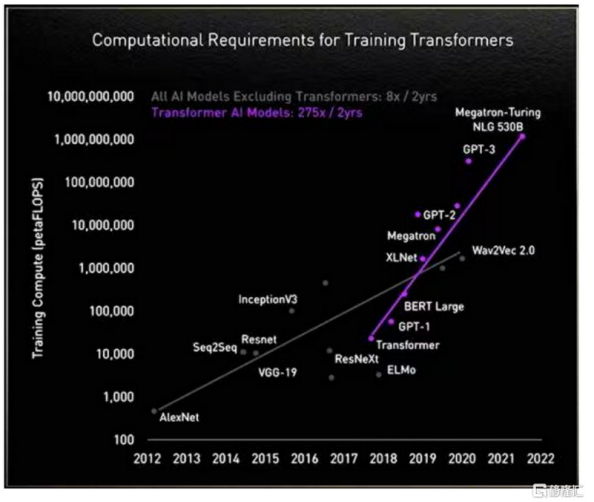
(AI不同模型算法算力迭代情況 圖源:格隆匯)
作為大模型的大腦——AI芯片,是支撐ChatGPT們高效生產及應用落地的基本前提。保證算力的高效、充足供應,是目前AI大算力芯片廠商亟需解決的問題。
GPT-4等大模型向芯片廠商獅子大開口的同時,也為芯片廠商尤其是初創芯片廠商,帶來一個利好消息:軟件生態重要性正在下降。
早先技術不夠成熟之時,研究者們只能從解決某個特定問題起步,參數量低于百萬的小模型由此誕生。例如谷歌旗下的AI公司DeepMind,讓AlphaGo對上百萬種人類專業選手的下棋步驟進行專項“學習”。
而小模型多了之后,硬件例如芯片的適配問題迫在眉睫。故,當英偉達推出統一生態CUDA之后,GPU+CUDA迅速博得計算機科學界認可,成為人工智能開發的標準配置。
現如今紛紛涌現的大模型具備多模態能力,能夠處理文本、圖片、編程等問題,也能夠覆蓋辦公、教育、醫療等多個垂直領域。這也就意味著,適應主流生態并非唯一的選擇:在大模型對芯片需求量暴漲之時,芯片廠商或許可以只適配1-2個大模型,便能完成以往多個小模型的訂單。
也就是說,ChatGPT的出現,為初創芯片廠商們提供了彎道超車的機會。這就意味著,AI芯片市場格局將發生巨變:不再是個別廠商的獨角戲,而是多個創新者的群戲。
本報告將梳理AI芯片行業發展概況、玩家情況,總結出大算力時代,玩家提高算力的路徑,并基于此,窺探AI大算力芯片的發展趨勢。
PART-01
國產AI芯片,正走向AI3.0時代
現階段的AI芯片,根據技術架構種類來分,主要包括GPGPU、FPGA、以 VPU、TPU 為代表的 ASIC、存算一體芯片。
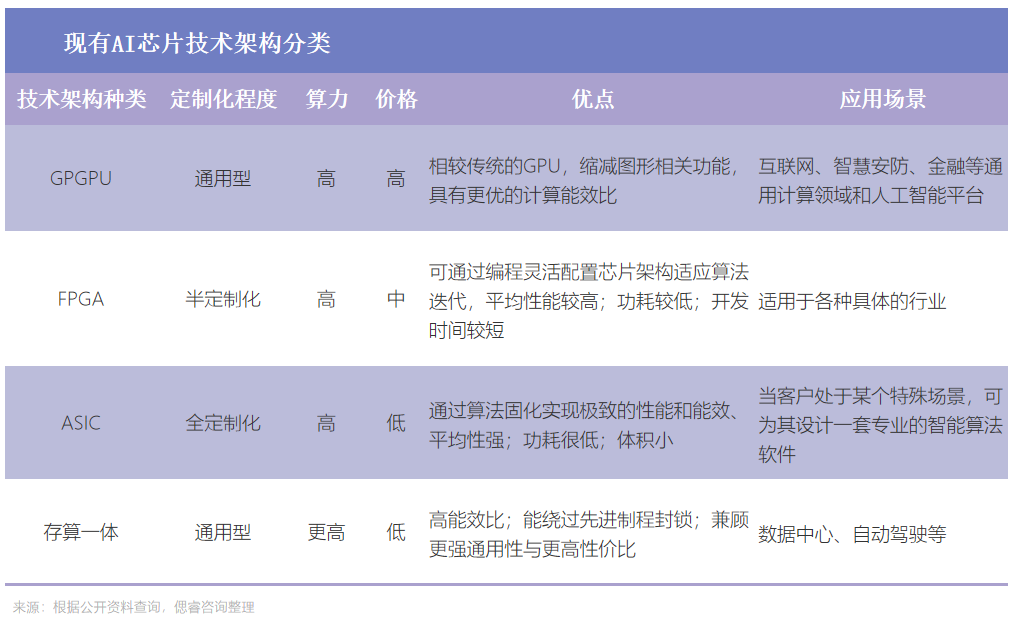
根據其在網絡中的位置,AI 芯片可以分為云端AI芯片 、邊緣和終端AI芯片;
云端主要部署高算力的AI訓練芯片和推理芯片,承擔訓練和推理任務,例如智能數據分析、模型訓練任務等;
邊緣和終端主要部署推理芯片,承擔推理任務,需要獨立完成數據收集、環境感知、人機交互及部分推理決策控制任務。
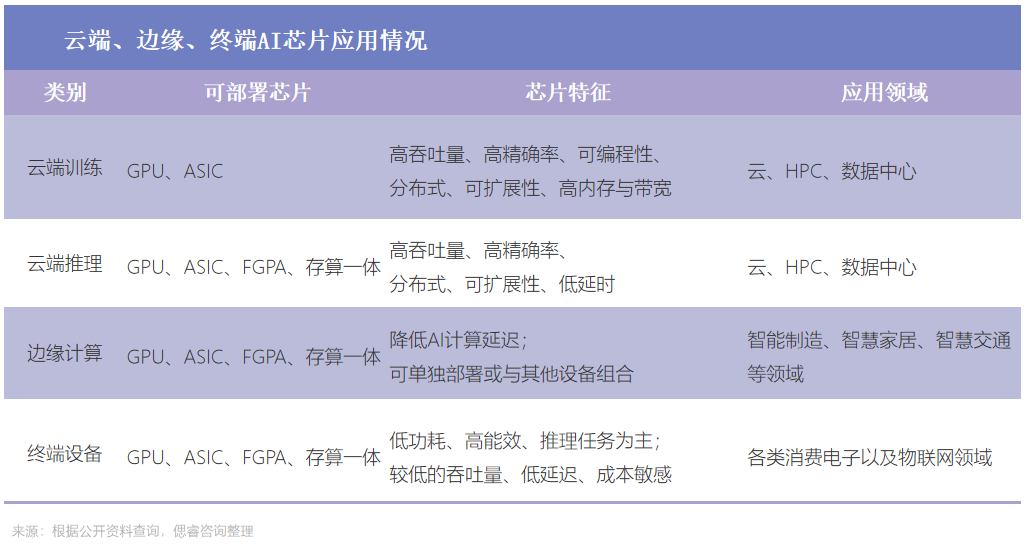
根據其在實踐中的目標,可分為訓練芯片和推理芯片:

縱觀AI芯片在國內的發展史,AI芯片國產化進程大致分為三個時代。
1.0時代,是屬于ASIC架構的時代
自2000年互聯網浪潮拉開AI芯片的序幕后,2010年前后,數據、算法、算力和應用場景四大因素的逐漸成熟,正式引發AI產業的爆發式增長。申威、沸騰、兆芯、龍芯、魂芯以及云端AI芯片相繼問世,標志著國產AI芯片正式啟航。
2016年5月,當谷歌揭曉AlphaGo背后的功臣是TPU時,ASIC隨即成為“當紅辣子雞”。于是在2018年,國內寒武紀、地平線等國內廠商陸續跟上腳步,針對云端AI應用推出ASIC架構芯片,開啟國產AI芯片1.0時代。
ASIC芯片,能夠在某一特定場景、算法較固定的情況下,實現更優性能和更低功耗,基于此,滿足了企業對極致算力和能效的追求。
所以當時的廠商們,多以捆綁合作為主:大多芯片廠商尋找大客戶們實現“專用場景”落地,而有著綜合生態的大廠選擇單打獨斗。
地平線、耐能科技等AI芯片廠商,分別專注AI芯片的細分領域,采用“大客戶捆綁”模式進入大客戶供應鏈。
在中廠們綁定大客戶協同發展之際,自有生態的大廠阿里成立獨資芯片公司平頭哥,著眼AI和量子計算。
在1.0時代,剛出世的國內芯片廠商們選擇綁定大客戶,有綜合生態的大廠選擇向內自研,共同踏上探索AI芯片算力的征途。
2.0時代,更具通用性的GPGPU“引領風騷”
盡管ASIC有著極致的算力和能效,但也存在著應用場景局限、依賴自建生態、客戶遷移難度大、學習曲線較長等問題。
于是,通用性更強的GPGPU(通用圖形處理器)在不斷迭代和發展中成為AI計算領域的最新發展方向,當上AI芯片2.0時代的指路人。
自2020年起,以英偉達為代表的GPGPU架構開始有著不錯的性能表現。通過對比英偉達近三代旗艦產品發現,從FP16 tensor 算力來看,性能實現逐代翻倍的同時,算力成本在下降。
于是,國內多個廠商紛紛布局GPGPU芯片,主打CUDA兼容,試探著AI算力芯片的極限。2020年起,珠海芯動力、壁仞科技、沐曦、登臨科技、天數智芯、瀚博半導體等新勢力集結發力,大家一致的動作是:自研架構,追隨主流生態,切入邊緣側場景。
在前兩個時代中,國產AI芯片廠商都在竭力順應時代潮流,前赴后繼地跟隨國際大廠的步伐,通過研發最新芯片解決AI算力芯片的挑戰。
我們能看到的變化是,在2.0時代中,國產AI芯片廠商自主意識覺醒,嘗試著自研架構以求突破。
3.0時代,存算一體芯片或成GPT-4等大模型的最優選
ASIC芯片的弱通用性難以應對下游層出不窮的應用,GPGPU受制于高功耗與低算力利用率,而大模型又對算力提出前所未有的高要求:目前,大模型所需的大算力起碼是1000TOPS及以上。
以 2020 年發布的 GPT-3 預訓練語言模型為例,其采用的是2020年最先進的英偉達A100 GPU, 算力是624TOPS。2023年,隨著模型預訓練階段模型迭代,又新增訪問階段井噴的需求,未來模型對于芯片算力的需求起碼要破千。
再例如自動駕駛領域,根據財通證券研究所表明,自動駕駛所需單個芯片的算力未來起碼要1000+TOPS:2021年4月, 英偉達就已經發布了算力為1000TOPS的DRIVE Atlan芯片;到了今年,英偉達直接推出芯片Thor,達到2000TOPS。
由此,業界亟需新架構、新工藝、新材料、新封裝,突破算力天花板。除此之外,日漸緊張的地緣關系,無疑又給高度依賴先進制程工藝的AI大算力芯片廠商們提出新的挑戰。
在這些大背景下,從2017年到2021年間集中成立的一批初創公司,選擇跳脫傳統馮·諾依曼架構,布局存算一體等新興技術,中國AI芯片3.0時代,正式拉開帷幕。
目前存算一體,正在上升期:
學界,ISSCC上存算/近存算相關的文章數量迅速增加:從20年的6篇上漲到23年的19篇;其中數字存內計算,從21年被首次提出后,22年迅速增加到4篇。
產界,巨頭紛紛布局存算一體,國內陸陸續續也有近十幾家初創公司押注該架構:
在特斯拉2023 Investor Day預告片末尾,特斯拉的dojo超算中心和存算一體芯片相繼亮相;在更早之前,三星、阿里達摩院包括AMD也早早布局并推出相關產品:阿里達摩院表示,相比傳統CPU計算系統,存算一體芯片的性能提升10倍以上,能效提升超過300倍;三星表示,與僅配備HBM的GPU加速器相比,配備HBM-PIM的GPU加速器一年的能耗降低了約2100GWh。
目前,國內的億鑄科技、知存科技、蘋芯科技、九天睿芯等十余家初創公司采用存算一體架構投注于AI算力,其中億鑄科技偏向數據中心等大算力場景。
現階段,業內人士表示,存算一體將有望成為繼CPU、GPU架構之后的第三種算力架構。
該提法的底氣在于,存算一體理論上擁有高能效比優勢,又能繞過先進制程封鎖,兼顧更強通用性與更高性價比,算力發展空間巨大。
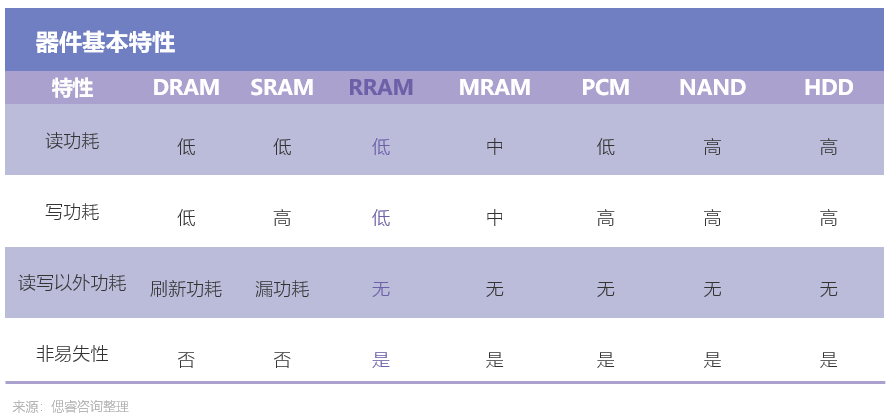
在此基礎上,新型存儲器能夠助力存算一體更好地實現以上優勢。目前可用于存算一體的成熟存儲器有NOR FLASH、SRAM、DRAM、RRAM(ReRAM)、MRAM等。相比之下,RRAM具備低功耗、高計算精度、高能效比和制造兼容CMOS工藝等優勢:
目前,新型存儲器RRAM技術已然落地:2022上半年,國內創業公司昕原半導體宣布,大陸首條RRAM 12寸中試生產線正式完成裝機驗收,并在工控領域達成量產商用。
隨著新型存儲器件走向量產,存算一體AI芯片已經挺進AI大算力芯片落地競賽。
而無論是傳統計算芯片,還是存算一體芯片,在實際加速AI計算時往往還需處理大量的邏輯計算、視頻編解碼等非AI加速計算領域的計算任務。隨著多模態成為大模型時代的大勢所趨,AI芯片未來需處理文本、語音、圖像、視頻等多類數據。
對此,初創公司億鑄科技首個提出存算一體超異構AI大算力技術路徑。億鑄的暢想是,若能把新型憶阻器技術(RRAM)、存算一體架構、芯粒技術(Chiplet)、3D封裝等技術結合,將會實現更大的有效算力、放置更多的參數、實現更高的能效比、更好的軟件兼容性、從而抬高AI大算力芯片的發展天花板。
站在3.0時代門口,國產AI大算力芯片廠商自主意識爆發,以期為中國AI大算力芯片提供彎道超車的可能。
(中略)
算力解決方案,蓄勢待發
以AI云端推理卡為例,我們能看到的是,2018-2023年,算力由于工藝制程“卷不動”等種種原因,成本、功耗、算力難以兼顧。
但國力之爭已然打響,ChatGPT已然到來,市場亟需兼顧成本、功耗、算力的方案。
目前國際大廠、國內主流廠商、初創企業都在謀求計算架構創新,試圖找出兼顧性能、規模、利用率的方案,突破算力天花板。
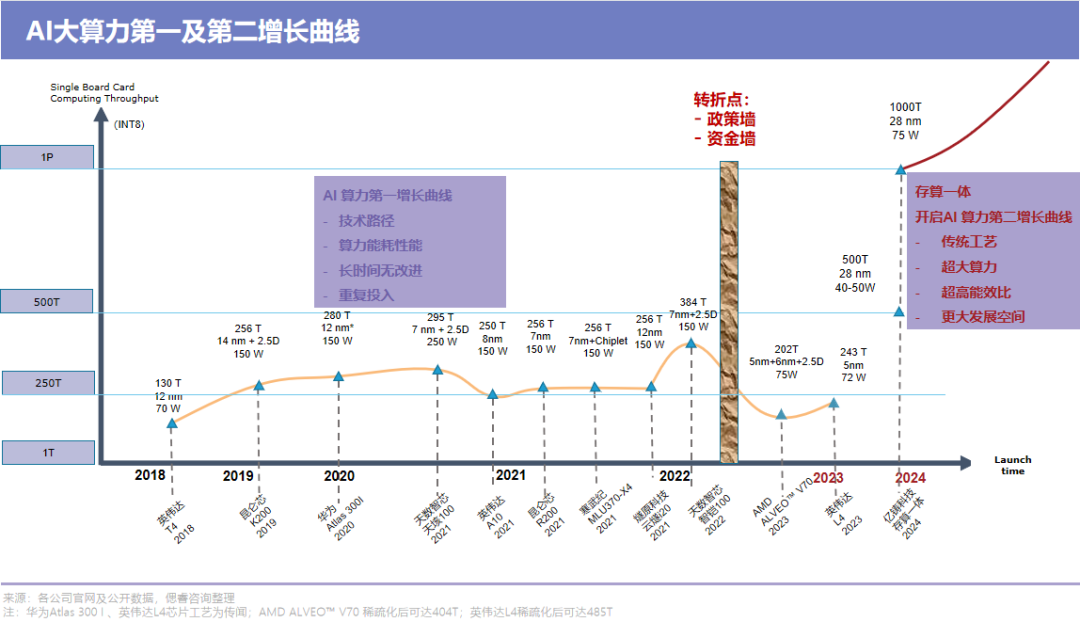
(中略)
AI芯片“新星”存算一體門檻奇高
2019年后,新增的AI芯片廠商,多數在布局存算一體:據偲睿洞察不完全統計,在2019-2021年新增的AI芯片廠商有20家,在這之中,有10家選擇存算一體路線。
這無一不說明著,存算一體將成為繼GPGPU、ASIC等架構后的,一顆冉冉升起的新星。而這顆新星,并不是誰都可以摘。
在學界、產界、資本一致看好存算一體的境況下,強勁的技術實力、扎實的人才儲備以及對遷移成本接受度的精準把控,是初創公司在業內保持競爭力的關鍵,也是擋在新玩家面前的三大門檻。
存算一體,打破了三堵墻,能夠實現低功耗、高算力、高能效比,但想要實現如此性能,挑戰頗多:
首先是存算一體涉及到芯片制造的全環節:從最底層的器件,到電路設計,架構設計,工具鏈,再到軟件層的研發;
其次是,在每一層做相應改變的同時,還要考慮各層級之間的適配度。
我們一層一層來看,一顆存算一體芯片被造出來,有怎樣的技術難題。
首先,在器件選擇上,廠商就“如履薄冰”:存儲器設計決定芯片的良率,一旦方向錯誤將可能導致芯片無法量產。
其次是電路設計層面。電路層面有了器件之后,需要用其做存儲陣列的電路設計。而目前在電路設計上,存內計算沒有EDA工具指導,需要靠手動完成,無疑又大大增加了操作難度。
緊接著,架構層面有電路之后,需要做架構層的設計。每一個電路是一個基本的計算模塊,整個架構由不同模塊組成,存算一體模塊的設計決定了芯片的能效比。模擬電路會受到噪聲干擾,芯片受到噪聲影響后運轉起來會遇到很多問題。
這種情況下,需要架構師了解模擬存內計算的工藝特點,針對這些特點去設計架構,同時也要考慮到架構與軟件開發的適配度。
軟件層面架構設計完成后,需要開發相應的工具鏈。

而由于存算一體的原始模型與傳統架構下的模型不同,編譯器要適配完全不同的存算一體架構,確保所有計算單元能夠映射到硬件上,并且順利運行。
一條完整的技術鏈條下來,考驗著器件、電路設計、架構設計、工具鏈、軟件層開發各個環節的能力,與協調各個環節的適配能力,是耗時耗力耗錢的持久戰。
根據以上環節操作流程可以看到,存算一體芯片亟需經驗豐富的電路設計師、芯片架構師。
除此之外,鑒于存算一體的特殊性,能夠做成存算一體的公司在人員儲備上需要有以下兩點特征:
1、帶頭人需有足夠魄力。在器件選擇(RRAM、SRAM等)、計算模式(傳統馮諾依曼、存算一體等)的選擇上要有清晰的思路。
這是因為,存算一體作為一項顛覆、創新技術,無人引領,試錯成本極高。能夠實現商業化的企業,創始人往往具備豐富的產業界、大廠經驗和學術背景,能夠帶領團隊快速完成產品迭代。
2、在核心團隊中,需要在技術的各個層級中配備經驗豐富的人才。例如架構師,其是團隊的核心。架構師需要對底層硬件,軟件工具有深厚的理解和認知,能夠把構想中的存算架構通過技術實現出來,最終達成產品落地;
3、此外,據量子位報告顯示,國內缺乏電路設計的高端人才,尤其在混合電路領域。存內計算涉及大量的模擬電路設計,與強調團隊協作的數字電路設計相比,模擬電路設計需要對于工藝、設計、版圖、模型pdk以及封裝都極度熟悉的個人設計師。
落地,是第一生產力。在交付時,客戶考量的并不僅僅是存算一體技術,而是相較于以往產品而言,存算一體整體SoC的能效比、面效比和易用性等性能指標是否有足夠的提升,更重要的是,遷移成本是否在承受范圍內。
如果選擇新的芯片提升算法表現力需要重新學習一套編程體系,在模型遷移上所花的人工成本高出購買一個新GPU的成本,那么客戶大概率不會選擇使用新的芯片。
因此,存算一體在落地過程中是否能將遷移成本降到最低,是客戶在選擇產品時的關鍵因素。
目前來看,英偉達憑借著更為通用的GPGPU霸占了中國AI加速卡的市場。
然而,存算一體芯片憑借著低功耗但高能效比的特性,正成為芯片賽道,冉冉升起的一顆新星。
而存算一體市場,風云未定,仍處于“小荷才露尖尖角”階段。但我們不可否認的是,存算一體玩家已然構筑了三大高墻,非技術實力雄厚,人才儲備扎實者,勿進。
PART-04
行業發展趨勢
存算一體,算力的下一級
隨著人工智能等大數據應用的興起,存算一體技術得到國內外學界與產界的廣泛研究與應用。在2017年微處理器頂級年會(Micro 2017)上,包括英偉達、英特爾、微軟、三星、加州大學圣塔芭芭拉分校等都推出他們的存算一體系統原型。
自此,ISSCC上存算/近存算相關的文章數量迅速增加:從20年的6篇上漲到23年的19篇;其中數字存內計算,從21年被首次提出后,22年迅速增加到4篇,23年有6篇。

(ISSCC2023存算一體相關文章 圖源:ISSCC2023)
系統級創新,嶄露頭角
系統級創新正頻頻現身半導體TOP級會議,展露著打破算力天花板的潛力。
在 AMD 的總裁兼CEO Lisa Su(蘇姿豐)帶來的主旨演講“Innovation for the next decade of compute efficiency“(下一個十年計算效率的創新)中,她提到了AI應用的突飛猛進,以及它給芯片帶來的需求。
Lisa Su表示,根據目前計算效率每兩年提升2.2倍的規律,預計到2035年,如果想要算力達到十萬億億級,則需要的功率可達500MW,相當于半個核電站能產生的功率,“這是極為離譜、不切合實際的”。
而為了實現這樣的效率提升,系統級創新是最關鍵的思路之一。
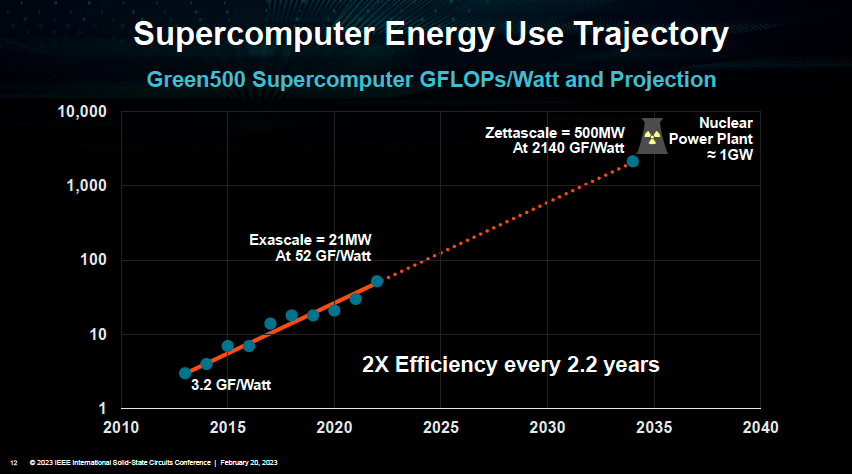
(算力與功耗關系 圖源:ISSCC2023大會)
在另一個由歐洲最著名三個的半導體研究機構IMEC/CEA Leti/Fraunhofer帶來的主旨演講中,系統級創新也是其核心關鍵詞。
該演講中提到,隨著半導體工藝逐漸接近物理極限,新的應用對于芯片的需求也必須要從系統級考慮才能滿足,并且提到了下一代智能汽車和AI作為兩個尤其需要芯片從系統級創新才能支持其新需求的核心應用。
“從頭到腳”打破算力天花板
系統級創新,是協同設計上中下游多個環節,實現性能的提升。還有一種說法是,系統工藝協同優化。
系統工藝協同優化為一種“由外向內”的發展模式,從產品需支持的工作負載及其軟件開始,到系統架構,再到封裝中必須包括的芯片類型,最后是半導體制程工藝。
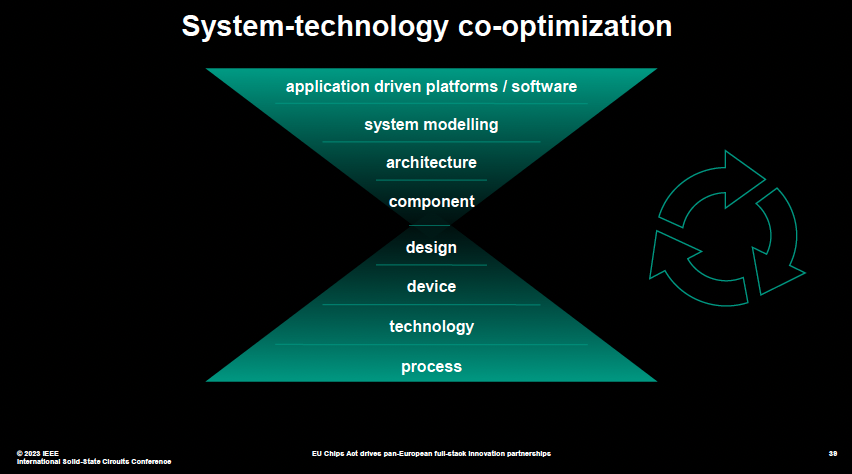
(系統工藝協同優化 圖源:ISSCC2023大會)
簡單來說,就是把所有環節共同優化,由此盡可能地改進最終產品。
對此,Lisa Su給出了一個經典案例:在對模型算法層面使用創新數制(例如8位浮點數FP8)的同時,在電路層對算法層面進行優化支持,最終實現計算層面數量級的效率提升:相比傳統的32位浮點數(FP32),進行系統級創新的FP8則可以將計算效率提升30倍之多。而如果僅僅是優化FP32計算單元的效率,無論如何也難以實現數量級的效率提升。
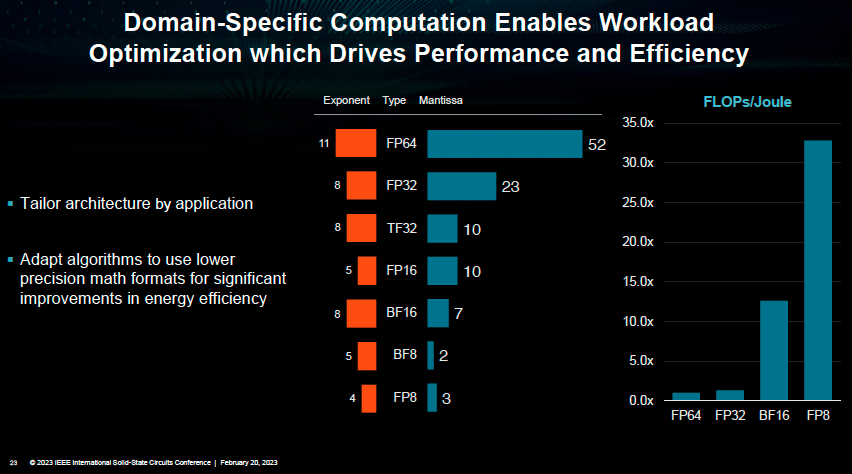
(特定域計算支持工作負載優化,從而提高性能和效率 圖源:ISSCC2023大會)
這便是系統級創新成為關鍵路徑的原因所在:如果電路設計僅僅停留在電路這一層——只是考慮如何進一步優化FP32計算單元的效率,無論如何也難以實現數量級的效率提升。
對此,在未來發展機會模塊的演講中,Lisa Su給出了未來系統級封裝架構的大致模樣:包含異構計算叢集,特定加速單元,先進封裝技術,高速片間UCIe互聯,存算一體等內存技術。
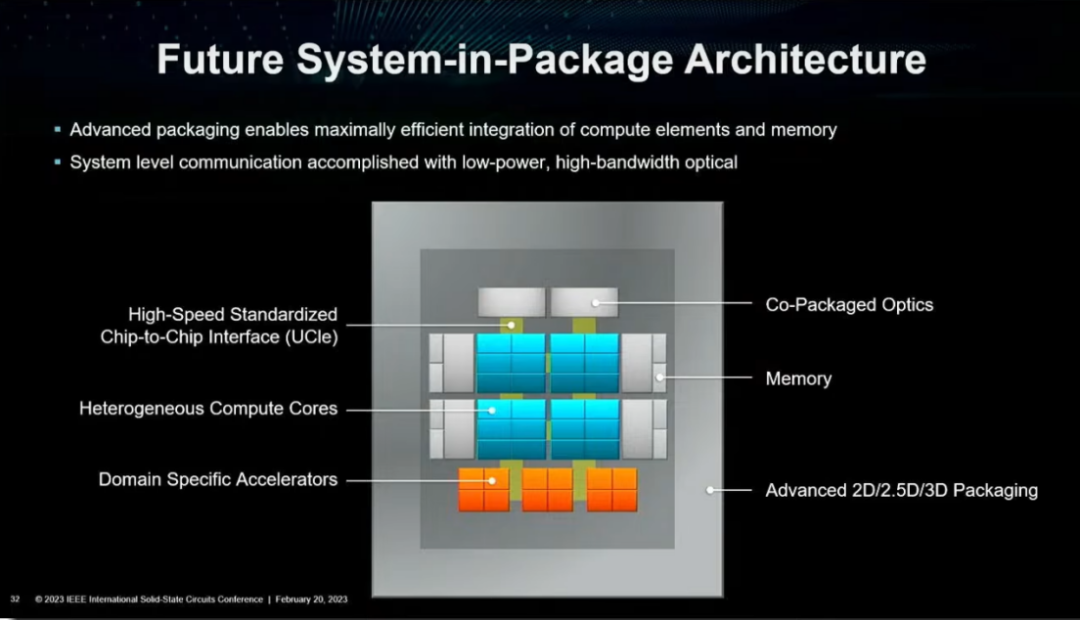
(未來的系統級封裝架構 圖源:ISSCC2023大會)
百舸爭流,創新者先
技術路徑、方案已然明確,接下來就是拼魄力的階段。
每一個新興技術的研發廠商,在前期無疑要面臨技術探索碰壁,下游廠商不認同等各個層面的問題。而在早期,誰先預判到未來的發展趨勢,并用于邁出探索的腳步,鋪下合理的資源去嘗試,就會搶到先機。
芯片巨頭NVIDIA在這方面做出了很好的榜樣。
當數據中心浪潮還未鋪天蓋地襲來、人工智能訓練還是小眾領域之時,英偉達已經投入重金,研發通用計算GPU和統一編程軟件CUDA,為英偉達謀一個好差事——計算平臺。
而在當時,讓GPU可編程,是“無用且虧本”的:不知道其性能是否能夠翻倍,但產品研發會翻倍。為此,沒有客戶愿意為此買單。但預判到單一功能圖形處理器不是長遠之計的英偉達毅然決定,在所有產品線上都應用CUDA。
在芯東西與英偉達中國區工程和解決方案高級總監賴俊杰博士的采訪中,賴俊杰表示:“為了計算平臺這一愿景,早期黃仁勛快速調動了英偉達上上下下非常多的資源。”
遠見+重金投入,在2012年,英偉達拿到了創新者的獎勵:2012年,深度學習算法的計算表現轟動學術圈,作為高算力且更為通用、易用的生產力工具,GPU+CUDA迅速風靡計算機科學界,成為人工智能開發的“標配”。
現如今,存算一體已顯現出強大的性能,在人工智能神經網絡、多模態的人工智能計算、類腦計算等大算力場景,有著卓越的表現。
國內廠商也在2019年前后紛紛布局存算一體,同時選擇3D封裝、chiplet等新興技術,RRAM、SRAM等新興存儲器,突破算力天花板。
AI大算力芯片的戰爭,創新者為先。
結語:
ChatGPT火爆來襲,引發AI產業巨浪,國產AI芯片正迎來3.0時代;在3.0時代,更適配大模型的芯片架構——存算一體將嶄露頭角,同時系統級創新將成為未來的發展趨勢,搶先下注的廠商將先吃到ChatGPT帶來的紅利。
-
gpu
+關注
關注
28文章
4936瀏覽量
131090 -
AI芯片
+關注
關注
17文章
1982瀏覽量
35851 -
大模型
+關注
關注
2文章
3116瀏覽量
4027
原文標題:億分享 | 大模型背景下,AI芯片廠商面臨怎樣的機遇與挑戰?
文章出處:【微信號:億鑄科技,微信公眾號:億鑄科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI?時代來襲,手機芯片面臨哪些新挑戰?


首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
模型原生操作系統:機遇、挑戰與展望 CCCF精選

全球驅動芯片市場機遇與挑戰
大模型訓練:開源數據與算法的機遇與挑戰分析
AMD MI300X AI芯片面臨挑戰
Cadence如何應對AI芯片設計挑戰
產業"內卷化"下磁性元件面臨的機遇與挑戰







 工商網監
工商網監
評論