 基于UWB信號的深度學習算法
基于UWB信號的深度學習算法
基于三個UWB錨點基站,采集近5萬條數據,分別采用BPNN和LSTM兩種神經網絡訓練和預測模型,實現目標區域的判斷;
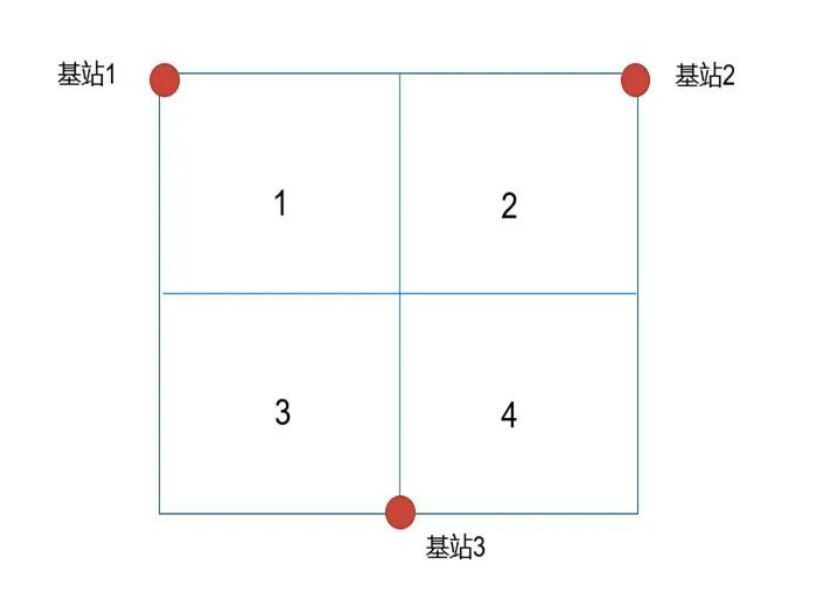
實驗共使用了11741條數據,按照8 : 2的比例劃分為訓練集與測試集
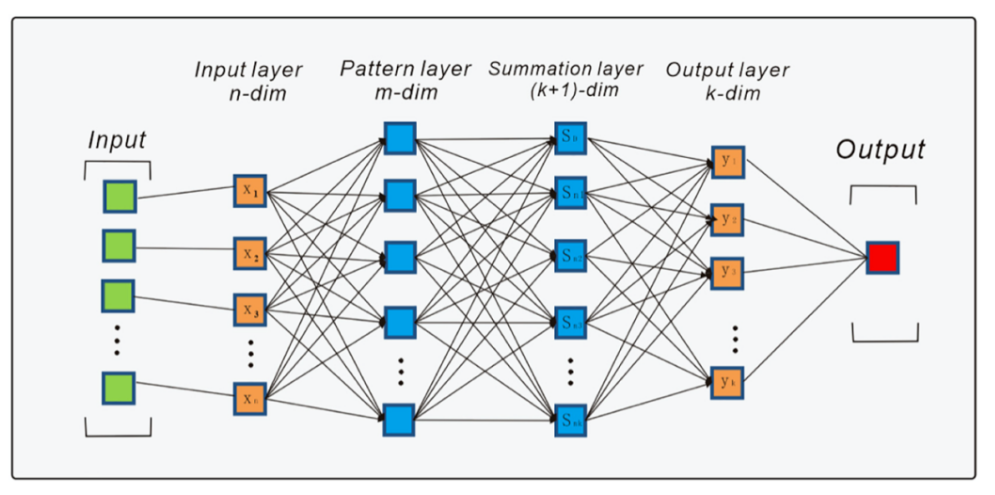
模型采用的是3層BPNN,隱含層為3,維度變化依次為3->32->16->4
損失函數使用的是交叉熵,優化器選擇的是Adam,學習率為0.0001
訓練輪數為100,為了提高訓練效率和泛化能力,將32個數據作為一批,按批進行訓練,在100輪訓練之后,訓練損失逐漸收斂于0.005;
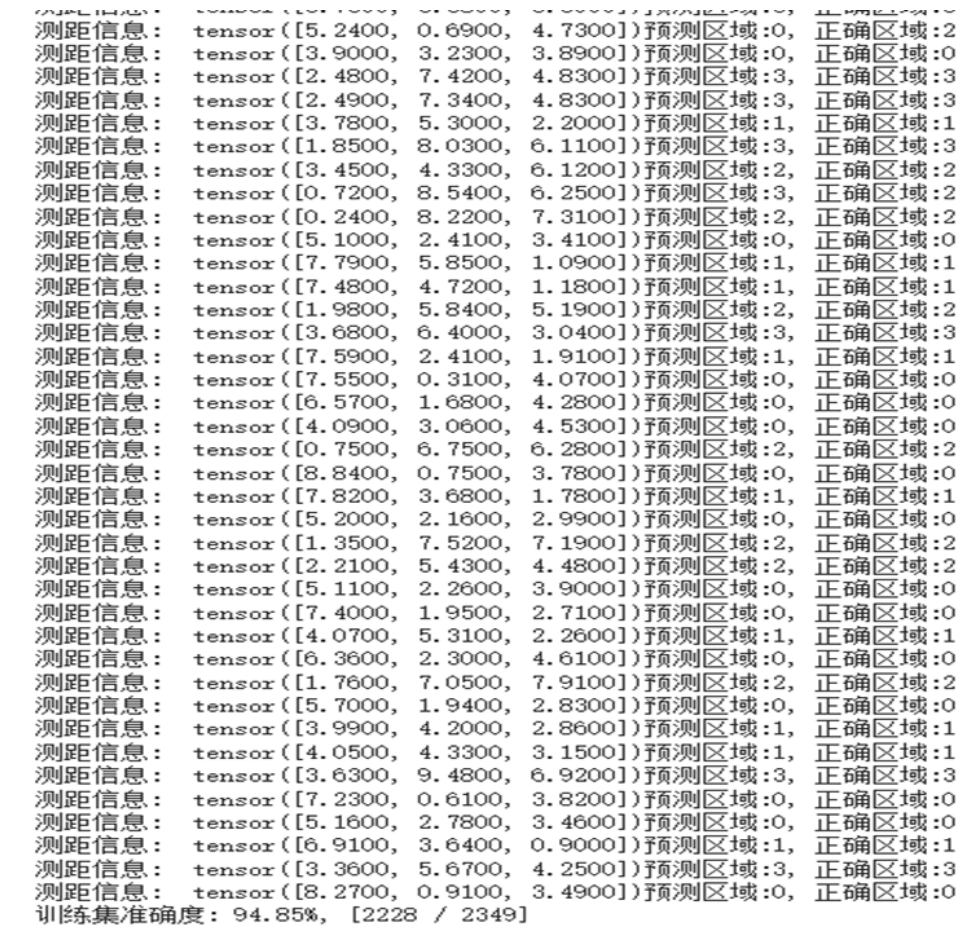
在測試集中的2349個數據中的測試準確率為94.85%
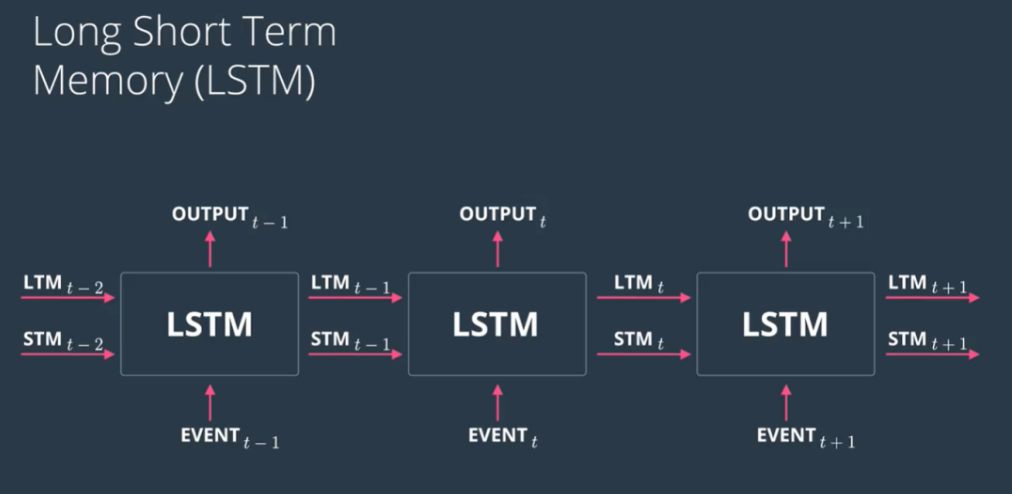
LSTM模型
數據歸一化與劃分,使用numpy的最大值函數獲取每個特征列的最大值,并將數據進行預處理,使用最大值歸一化并將數據按照8:2的比例進行模型的訓練與預測。
模型的構建:使用了Keras來創建模型。模型結構包括一個LSTM層,它有32個神經元,激活函數為Relu。Dropout層設置為20%的丟棄比率。全連接層輸出4個神經元,使用softmax激活函數進行多類分類。對模型進行編譯,使用Adam優化器和分類交叉熵損失函數。之后將模型進行擬合,指定批量大小(batch_size)為20,訓練次數(epochs)為100。
經過100輪訓練之后,模型的訓練準確率達到了95.52%,損失函數為0.1134.測試數據約3000條的測試準確率為95.99%。
后續會進一步基于兩種神經網絡學習模型,通過減少錨點以及增加時間序列和信號能量以及信號到達角輸入變量,觀察預測模型的準確率;
審核編輯:湯梓紅
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
算法
+關注
關注
23文章
4701瀏覽量
94843 -
UWB
+關注
關注
32文章
1164瀏覽量
62373 -
模型
+關注
關注
1文章
3499瀏覽量
50062 -
深度學習
+關注
關注
73文章
5555瀏覽量
122528
發布評論請先 登錄
相關推薦
熱點推薦

基于遷移深度學習的雷達信號分選識別
基于遷移深度學習的雷達信號分選識別 ? 來源:《軟件學報》?,作者王功明等 ? 摘要:? 針對當前雷達信號分選識別算法普遍存在的低信噪比下識
發表于 03-02 17:35
?1831次閱讀
機器學習和深度學習算法流程
但是無可否認的是深度學習實在太好用啦!極大地簡化了傳統機器學習的整體算法分析和學習流程,更重要的是在一些通用的領域任務刷新了傳統機器
什么是深度學習中優化算法
先大致講一下什么是深度學習中優化算法吧,我們可以把模型比作函數,一種很復雜的函數:h(f(g(k(x)))),函數有參數,這些參數是未知的,深度學習
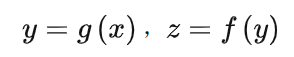
深度學習算法的選擇建議
深度學習算法的選擇建議 隨著深度學習技術的普及,越來越多的開發者將它應用于各種領域,包括圖像識別、自然語言處理、聲音識別等等。對于剛開始





 工商網監
工商網監
評論