 南開大學提出LSKNet:遙感旋轉目標檢測新SOTA!
南開大學提出LSKNet:遙感旋轉目標檢測新SOTA!
Abstract
最近關于遙感物體檢測的研究主要集中在改進旋轉包圍框的表示方法上,但忽略了遙感場景中出現的獨特的先驗知識。這種先驗知識是非常重要的,因為微小的遙感物體可能會在沒有參考足夠長距離背景的情況下被錯誤地檢測出來,而不同類型的物體所要求的長距離背景可能會有所不同。在本文中,我們將這些先驗因素考慮在內,并提出了Large Selective Kernel Network(LSKNet)。LSKNet可以動態地調整其大空間感受野,以更好地建模遙感場景中各種物體的測距的場景。據我們所知,這是首次在遙感物體檢測領域探索大選擇性卷積核機制的工作。在沒有任何附加條件的情況下,我們LSKNet比主流檢測器輕量的多,而且在多個數據集上刷新了SOTA!HRSC2016(98.46% mAP)、DOTA-v1.0(81.64% mAP)和FAIR1M-v1.0(47.87% mAP)。
Introduction
近期很少有工作考慮到遙感圖像中存在的強大的先驗知識。航空圖像通常是以高分辨率的鳥瞰視角拍攝的。特別是,航空圖像中的大多數物體可能是小尺寸的,僅憑其外觀很難識別。相反,這些物體的成功識別往往依賴于它們的背景,因為周圍的環境可以提供關于它們的形狀、方向和其他特征的寶貴線索。根據對主流遙感數據集的分析,我們確定了兩個重要的前提條件:
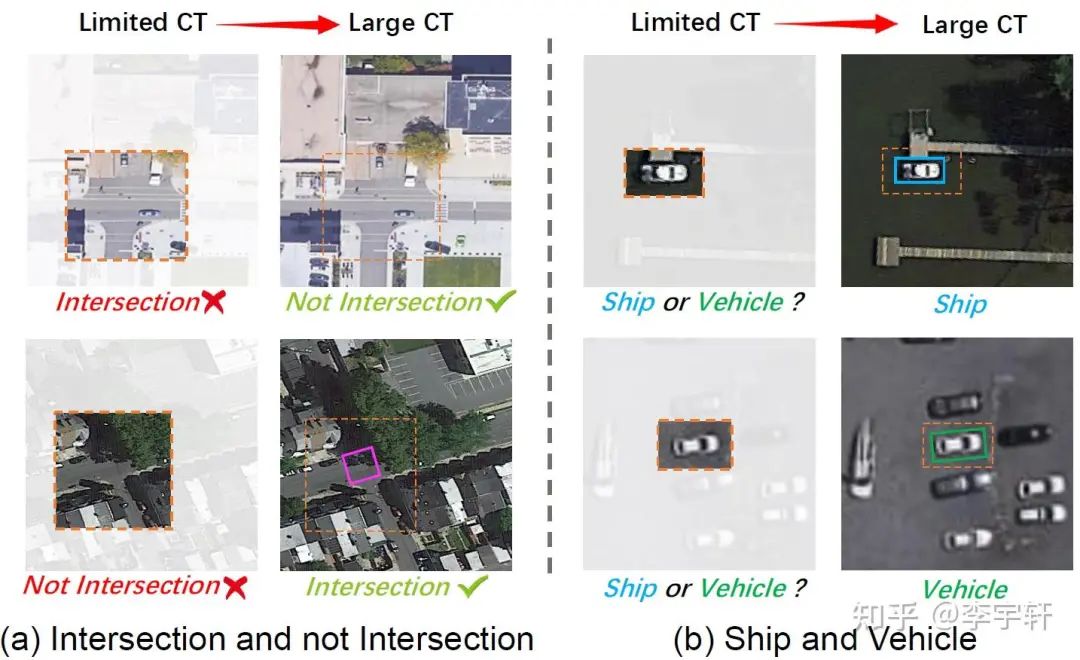
(1)準確檢測遙感圖像中的物體往往需要廣泛的背景信息。
如圖1(a)所示,遙感圖像中的物體檢測器所使用的有限范圍的背景往往會導致錯誤的分類。例如,在上層圖像中,由于其典型特征,檢測器可能將T子路口歸類為十字路口,但實際上,它不是一個十字交路口。同樣,在下圖中,由于大樹的存在,檢測器可能將十字路口歸類為非路口,但這也是不正確的。這些錯誤的發生是因為檢測器只考慮了物體附近的有限的上下文信息。在圖1(b)中的船舶和車輛的例子中也可以看到類似的情況。
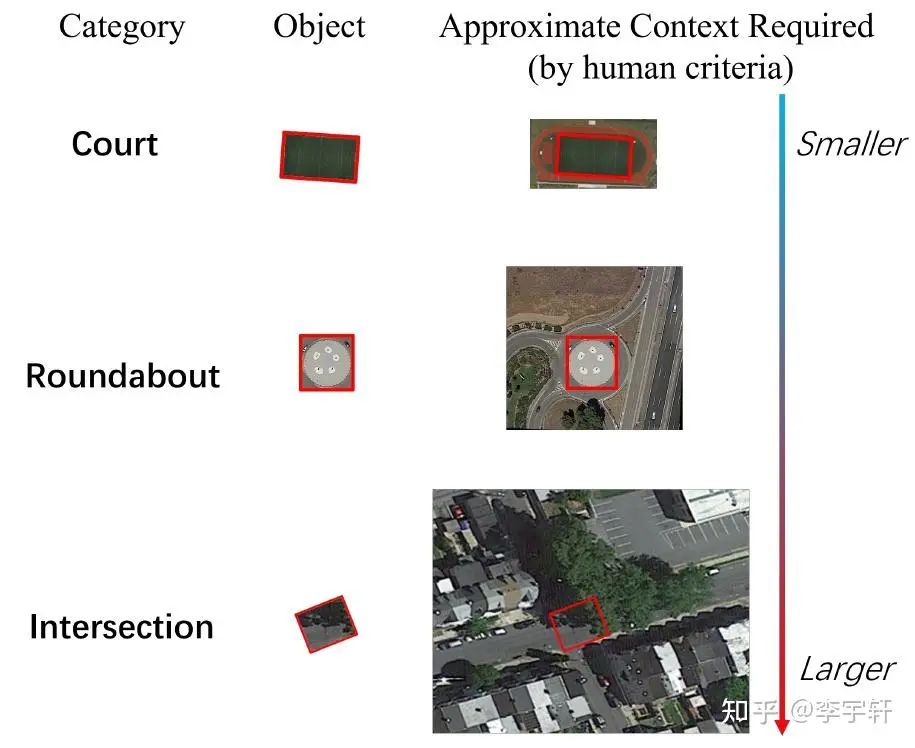
(2) 不同類型的物體所需的上下文信息的范圍非常不同。如圖2所示,在遙感圖像中進行準確的物體檢測所需的背景信息量會因被檢測物體的類型而有很大不同。例如,足球場可能需要相對較少的額外環境信息,因為它有獨特的可區分的球場邊界線。相比之下,環島可能需要更大范圍的上下文信息,以區分花園和環形建筑。交叉口,特別是那些部分被樹木覆蓋的交叉口,由于相交道路之間的長距離依賴性,往往需要一個非常大的感受野。這是因為樹木和其他障礙物的存在會使人們難以僅僅根據外觀來識別道路和交叉口本身。其他物體類別,如橋梁、車輛和船舶,也可能需要不同規模的感受野,以便被準確檢測和分類。
因為這些圖像往往需要廣泛和動態的背景信息,我們提出了一種新的方法,稱為Large Selective Kernel Network(LSKNet)。我們的方法包括動態調整特征提取骨干的感受野,以便更有效地處理被檢測物體的不同的廣泛背景。這是通過一個空間選擇機制來實現的,該機制對一連串的大depth-wise卷積核所處理的特征進行有效加權,然后在空間上將它們合并。這些核的權重是根據輸入動態確定的,允許該模型自適應地使用不同的大核,并根據需要調整空間中每個目標的感受野。據我們所知,我們提出的LSKNet是第一個研究和討論在遙感物體探測中使用大的和有選擇性的卷積核的模型。盡管我們的模型很簡單,但在三個流行的數據集上實現了最先進的性能。HRSC2016(98.46% mAP)、DOTA-v1.0(81.64% mAP)和FAIR1M-v1.0(47.87% mAP),超過了之前公布的結果。此外,我們實驗證明了我們模型的行為與上述兩個先驗假設的一致性。
Method
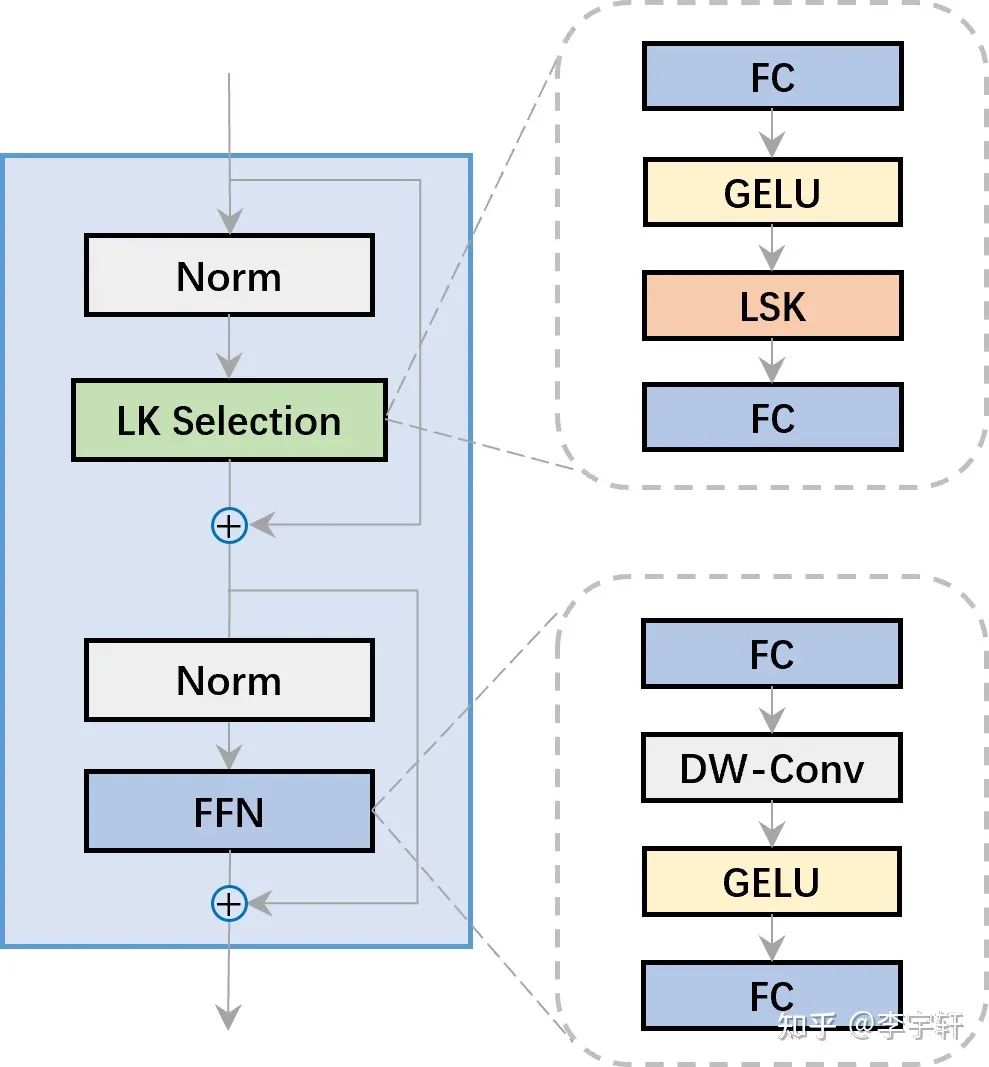
LSKNet Architecture
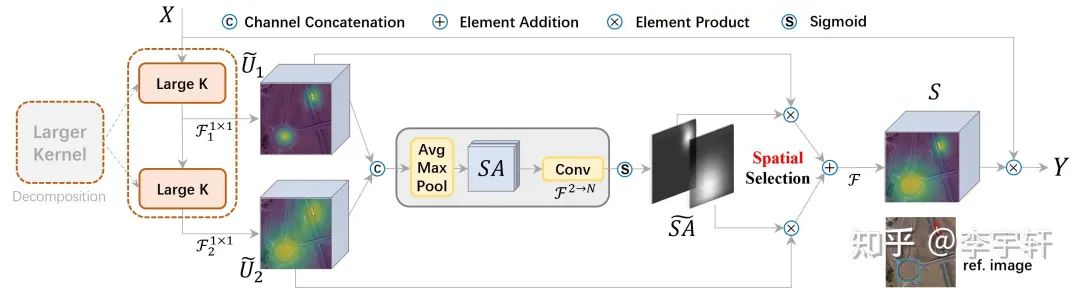
圖3展示了一個LSKNet Bolck的圖示,是主干網中的一個重復塊,其靈感來自ConvNeXt, PVT-v2, VAN, Conv2Former 和 MetaFormer。每個LSKNet塊由兩個剩余子塊組成:大核選擇(LK Selection)子塊和前饋網絡(FFN)子塊。LK選擇子塊根據需要動態地調整網絡的感受野。前饋網絡子塊用于通道混合和特征細化,由一個全連接層、一個深度卷積、一個GELU激活和第二個全連接層組成的序列。核心模塊LSK Module(圖4)被嵌入到LK選擇子塊中。它由一連串的大內核卷積和一個空間內核選擇機制組成。
Large Kernel Convolutions & Spatial Kernel Selection
根據Introduction中所說的先驗(2),建議對一系列的多個尺度的背景進行建模,以進行適應性選擇。因此,我們建議通過明確地將其分解為一連串具有大的卷積核和不斷擴張的depth-wise卷積來構建一個更大感受野的網絡。其序列中第i個深度卷積的核大小k、擴張率d和感受野RF的擴展定義如下:
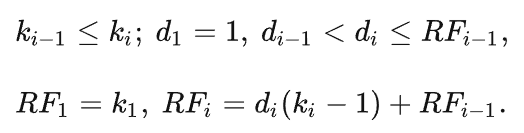
核的大小和擴張率的增加確保了感受野有足夠快的擴展。我們對擴張率設定了一個上限,以保證擴張卷積不會在特征圖之間引入空隙。
所提出的設計有兩個優點。第一,它明確地產生了具有各種大感受野的多個特征,這使得后來的內核選擇更加容易。第二,順序分解比簡單地應用一個較大的核更有效更高效。為了提高網絡關注檢測目標的最相關的空間背景區域的能力,我們使用了一種空間選擇機制,從不同尺度的大卷積核中空間選擇特征圖。圖4顯示了LSK模塊的詳細概念圖,在這里我們直觀地展示了大選擇核是如何通過自適應地收集不同物體的相應大感受野而發揮作用的。
LSK Module 的pytorch代碼如下:
class LSKmodule(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.convl = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv0_s = nn.Conv2d(dim, dim//2, 1)
self.conv1_s = nn.Conv2d(dim, dim//2, 1)
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
self.conv_m = nn.Conv2d(dim//2, dim, 1)
def forward(self, x):
attn1 = self.conv0(x)
attn2 = self.convl(attn1)
attn1 = self.conv0_s(attn1)
attn2 = self.conv1_s(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid()
attn = attn1 * sig[:,0,:,:].unsqueeze(1) + attn2 * sig[:,1,:,:].unsqueeze(1)
attn = self.conv_m (attn)
return x * attn
Results
在我們的實驗中,我們報告了HRSC2016、DOTA-v1.0和FAIR1M-v1.0數據集上的檢測模型結果。為了保證公平性,我們遵循與其他主流方法相同的數據集處理方法和訓練方式(如S2A-Net, Oriented RCNN, R3Det...)。
在不同檢測框架下,使用我們的LSKNet骨干,模型更輕量,對檢測模型性能提升巨大!(表1)
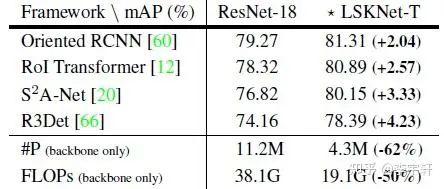
在相同檢測框架的不同骨干網絡(大卷積核和選擇性機制的骨干網絡)中,在相似模型復雜的的前提下,我們的LSKNet骨干mAP更強!(表2)
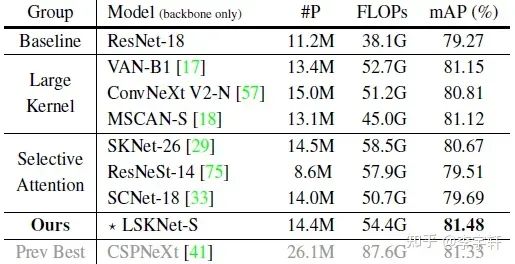
在HRSC2016數據集上,性能超越之前所有的方法!(表3)
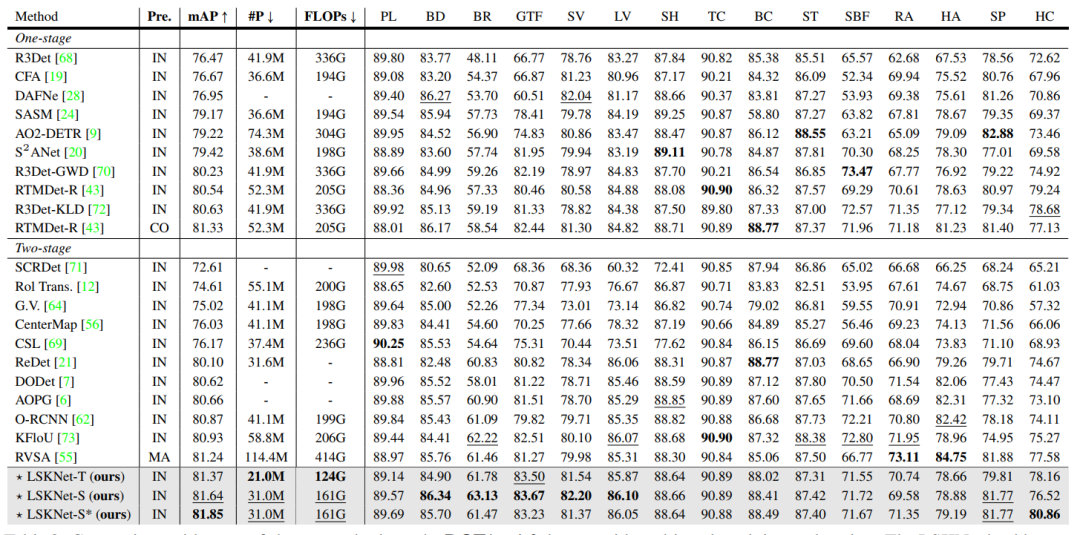
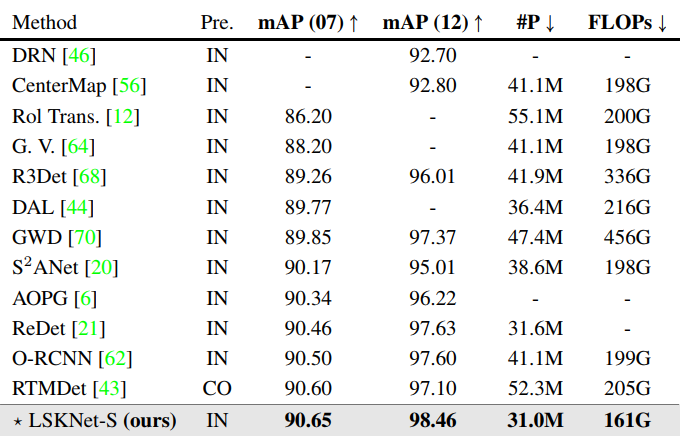
在DOTA-v1.0數據集上,性能超越之前所有的方法!(表4)在此數據集上,(近期的方法在性能上近乎飽和,最近的SOTA方法RVSA用了極為重量的模型和在龐大的數據集上做預訓練才勉強突破0.81的mAP,RTMDet則是在COCO預訓練,36epoch加EMA的微調方式,而其他主流方法都是ImageNet預訓練和12epoch w/o EMA微調,才達到81.33的性能。)我們的方法在模型參數量和計算復雜度全面小于其他方法的前提下,性能刷新了新的SOTA!

在近期中國空天院提出的FAIR1M-v1.0數據集上,我們也刷新了mAP。
Ablation Study
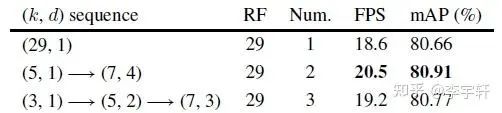
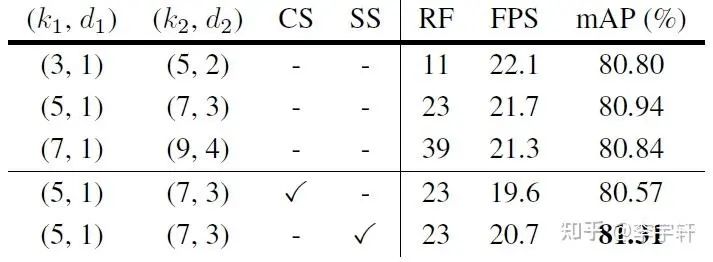
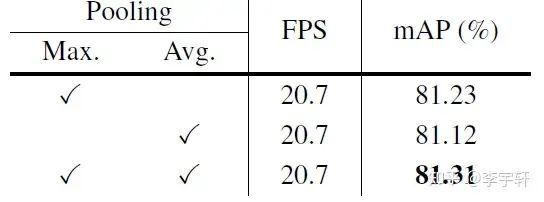
消融實驗部分,為了提高實驗效率,我們采用LSKNet-T骨架在ImageNet上做100個epoch的骨干預訓練。
Analysis

圖5所示,LSKNet-S可以捕捉到更多與檢測到的目標相關的背景信息,從而在各種困難情況下有更好的表現,這證明了我們的先驗(1)。
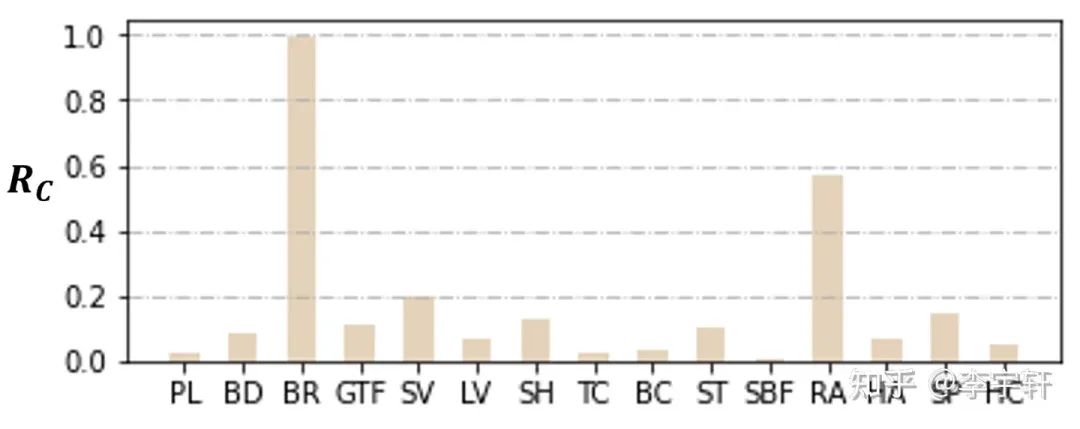
為了研究每個物體類別的感受野范圍,我們定義物體類別預期感受野和GT框面積的比率:Rc。此數值越大,說明目標需要的額外感受野越大。圖6中結果表明,與其他類別相比,橋梁類別需要更多的額外上下文信息,這主要是由于它與道路的特征相似,并且需要語境線索來確定它是否被水所包圍。相反,球場類別,如足球場,由于其獨特的紋理屬性,特別是球場邊界線,需要最少的上下文信息。這與我們的常識相吻合,并進一步支持先前的觀點(2),即不同的物體類別所需的上下文信息的相對范圍有很大不同。

我們進一步研究我們的LSKNet中的大核選擇傾向性行為。我們定義了Kernel Selection Difference(較大的感受野卷積核特征圖激活值 - 較小的感受野卷積核特征圖激活值)。
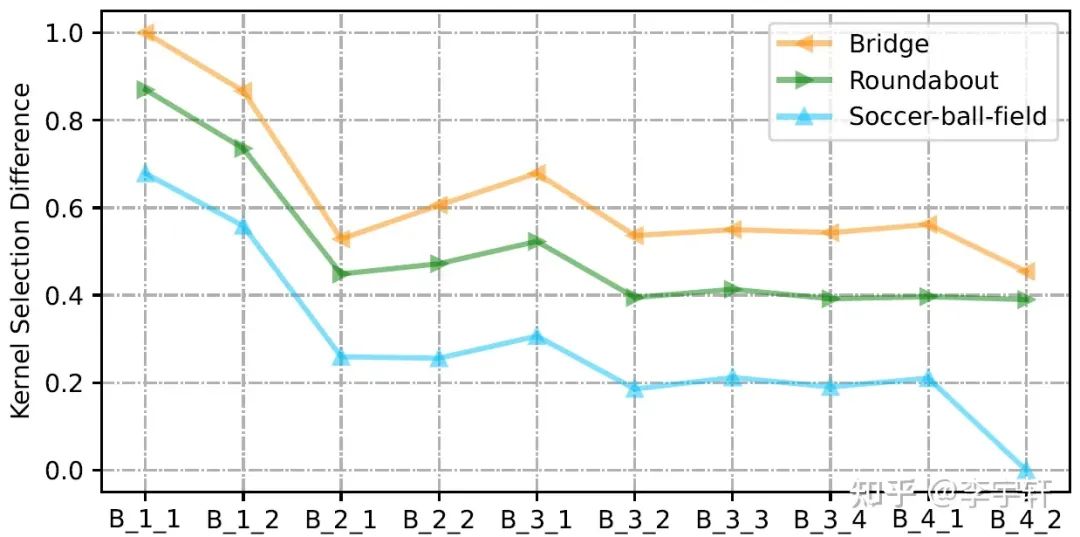
在圖8中,我們展示了三個典型類別的所有圖像的歸一化Kernel Selection Difference:橋梁、環形路和足球場,以及每個LSKNet-T塊的情況。正如預期的那樣,Bridge的所有塊的大核的參與度高于Roundabout,而Roundabout則高于Soccer-ball-field。這與常識一致,即Soccer-ball-field確實不需要大量的上下文,因為它本身的紋理特征已經足夠明顯和具有鑒別性。我們還出人意料地發現了LSKNet在網絡深度上的另一種選擇模式。LSKNet通常在其淺層利用較大感受野的卷積核,而在較高的層次利用較小的。這表明,網絡傾向于在網絡淺層迅速擴大感受野捕捉信息,以便高層次的語義學能夠包含足夠的感受野,從而獲得更好的辨別力。
-
檢測器
+關注
關注
1文章
888瀏覽量
48489 -
圖像
+關注
關注
2文章
1094瀏覽量
41076 -
遙感
+關注
關注
0文章
252瀏覽量
17114 -
數據集
+關注
關注
4文章
1223瀏覽量
25311
原文標題:ICCV 2023 | 南開大學提出LSKNet:遙感旋轉目標檢測新SOTA!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
TINA-TI 9與TINA8對同一個電路圖仿真結果不同是怎么回事?
南開大學origin使用指南
南開大學提出了高性能太赫茲隱身材料設計的新思路

南開大學提出最新邊緣檢測和圖像過分割被 IEEE PAMI 錄用
南開大學開發出一種具有超高容量的鋰離子電池有機正極材料
南開大學孫軍教授:逆流而上,為光電材料盡一份力
“人工智能+機器人”高端論壇在南開大學舉行
綜述:基于柔性致動器的跳躍運動
南開大學OpenHarmony技術俱樂部揭牌成立

南開大學和字節跳動聯合開發一款StoryDiffusion模型
火山引擎與南開大學深化合作簽約,攜手共建“AI+教育”新生態
南開大學攜手華為發布“人工智能賦能人才培養行動計劃”






 工商網監
工商網監
評論