 如何設計一個高性能短鏈系統?
如何設計一個高性能短鏈系統?
所謂系統設計,就是給一個場景,讓你給出對應的架構設計,需要考慮哪些問題,采用什么方案解決。很多面試官喜歡出這么一道題來考驗你的知識廣度和邏輯思考能力。
雖然各個系統千差萬別,但是設計思想基本一致,學會一些經典的架構設計,掌握基本的設計方法和常見需要考慮的問題,用這一套方法論去應對面試,應該就沒啥問題了。
目前專欄已經包含以下幾個經典系統設計題:
高性能短鏈系統
高性能計數器
高性能未讀數計數器
高性能 Feed 流
高性能限流器
...... 后續會不斷增加
今天來分享下如何設計一個高性能的短鏈系統,字節三面的真實面試題。
什么是短鏈?為什么要用短鏈?
短鏈的好處如下:
鏈接變短,在對內容長度有限制的平臺發文,可編輯的文字就變多了。比如微博限定了只能發 140 個字,如果一串長鏈直接復制上去就沒地方再寫其他文字了
大家接受各種短信的時候,能發現大部分鏈接都是短鏈形式,因為一般短信發文有長度限度,如果用長鏈,一條短信很可能要拆分成兩三條發,相應的成本也就增加了
使用短鏈在排版上更加美觀
短鏈跳轉的基本原理
點擊短鏈后,看下控制臺:
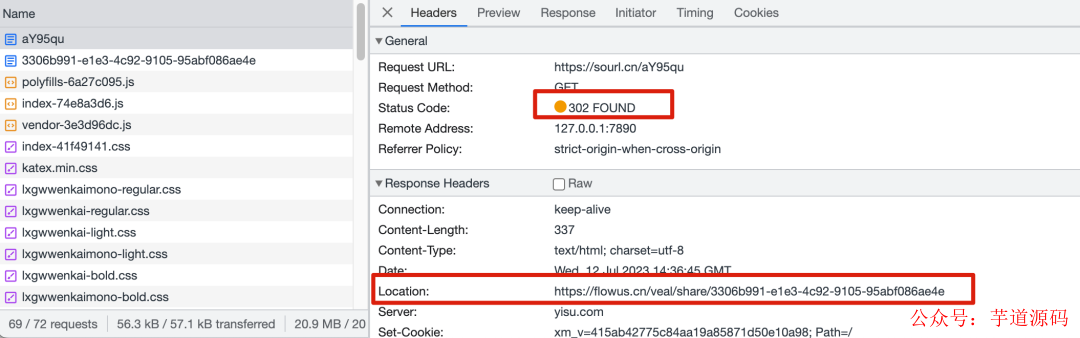
可以看到返回了狀態碼 302(重定向)與 location 值為長鏈的響應,然后瀏覽器會再請求這個長鏈以得到最終的響應,整個交互流程圖如下:
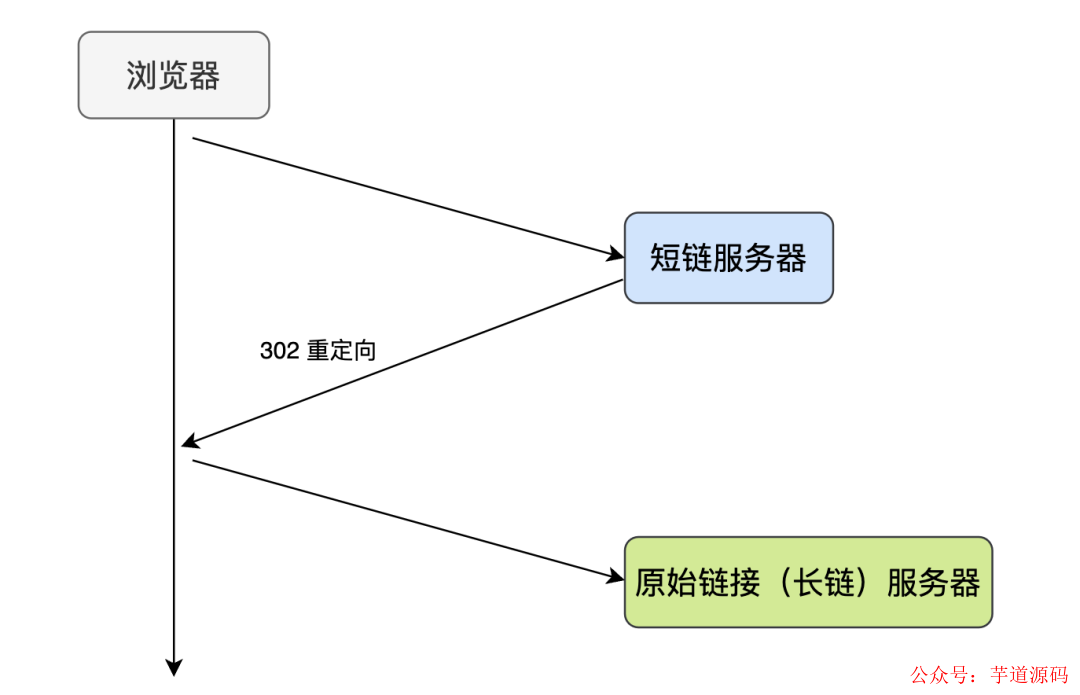
那么問題來了,301 和 302 都是重定向,到底該用哪個,這里需要注意一下 301 和 302 的區別:
301,代表 永久重定向:第一次請求拿到長鏈接后,下次瀏覽器再去請求短鏈的話,不會向短鏈服務器請求了,而是直接從瀏覽器的緩存里拿,這樣的話短鏈服務器就無法獲取到短鏈的點擊數了,不利于數據分析,所以我們一般不采用 301
302,代表 臨時重定向:每次去請求短鏈都會去請求短鏈服務器(除非響應中用 Cache-Control 或 Expired 暗示瀏覽器緩存),這樣便于短鏈服務器統計點擊數
生成短鏈的兩種方法
方法一:哈希算法
哈希算法可以將一個不管多長的字符串,轉化成一個長度固定的哈希值。我們可以利用哈希算法,來生成短鏈。
常見的哈希算法就是 MD5、SHA 等,但實際上并不需要這些復雜的哈希算法。因為在生成短鏈這個問題上不需要考慮反向解密的難度,只需要關心哈希算法的計算速度和沖突概率就可以了。
能夠滿足這樣要求的簡單的哈希算法有很多,其中比較著名并且應用廣泛的一個哈希算法,那就是 MurmurHash 算法。盡管這個哈希算法在 2008 年才被發明出來,但現在它已經廣泛應用到 Redis、MemCache、Cassandra、HBase、Lucene 等眾多著名的軟件中。
MurmurHash 算法提供了兩種長度的哈希值,一種是 32bits,一種是 128bits。為了讓最終生成的短鏈盡可能短,我們可以選擇 32bits 的哈希值。比如假設某個長鏈接經過 MurmurHash 計算后得到的哈希值是 181338494,再拼上短鏈服務的域名就變成了最終的短鏈 。
如何讓短鏈更短
不過,通過 MurmurHash 算法得到的短鏈還是很長啊。別著急,我們只需要稍微改變一個哈希值的表示方法,就可以輕松把短鏈變得更短些。
將 10 進制的哈希值,轉化成更高進制的哈希值,這樣哈希值就變短了。
16 進制中,用 A~F,來表示 10~15。在網址 URL 中,常用的合法字符有 0~9、a~z、A~Z 這樣 62 個字符。為了讓哈希值表示起來盡可能短,我們可以將 10 進制的哈希值轉化成 62 進制。具體的計算過程如下圖。最終用 62 進制表示的=短鏈就是 http://sourl.cn/cgSqq。
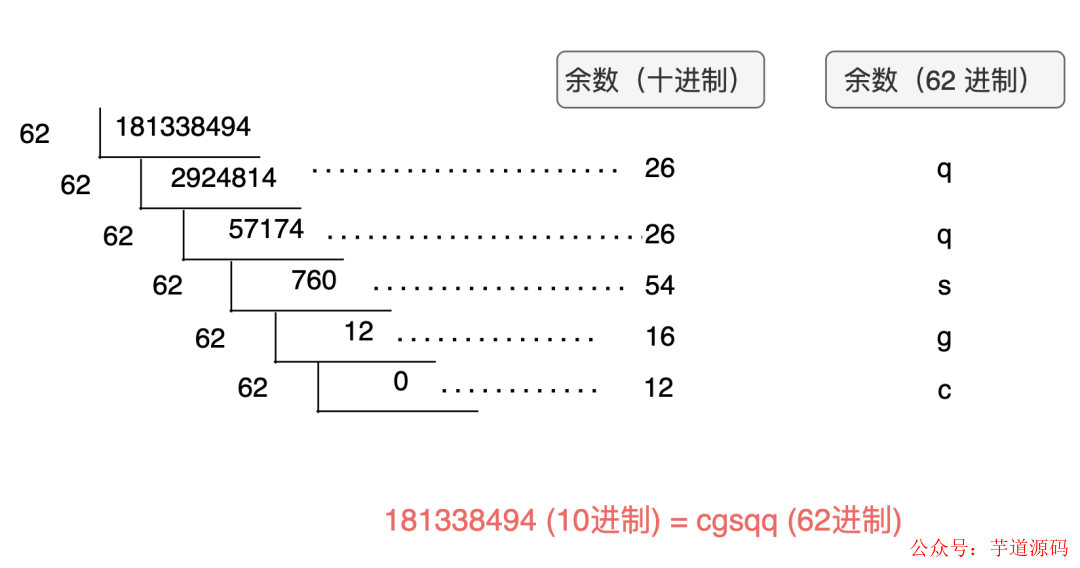
如何解決哈希沖突
哈希算法無法避免的一個問題,就是哈希沖突。盡管 MurmurHash 算法,沖突的概率非常低。但是,一旦沖突,就會導致兩個原始網址被轉化成同一個短鏈。當用戶訪問短鏈的時候,我們就無從判斷,用戶想要訪問的是哪一個原始網址了。這個問題該如何解決呢?
一般情況下,我們會保存短鏈跟原始網址之間的對應關系,以便后續用戶在訪問短鏈的時候,可以根據對應關系,查找到原始網址。存儲這種對應關系的方式有很多,比如我們自己設計存儲系統或者利用現成的數據庫比如 MySQL、Redis。
以 MySQL 為例,當有一個新的原始網址需要生成短鏈的時候,我們先利用 MurmurHash 算法,生成短鏈。然后將這個新生成的短鏈,在 MySQL 數據庫中查找:
當用戶訪問短鏈的時候,短鏈服務先通過短鏈,在數據庫中查找到對應的原始網址。如果原始網址有拼接特殊字符(這個很容易通過字符串匹配算法找到),就先將特殊字符去掉,然后再將不包含特殊字符的原始網址返回給瀏覽器。
如果沒有找到相同的短鏈,這就表明這個新生成的短鏈沒有沖突。于是我們就將這個短鏈返回給用戶,然后將這個短鏈與原始網址之間的對應關系,存儲到 MySQL 數據庫中
如果在數據庫中找到了相同的短鏈,那也并不一定說明就沖突了。我們先從數據庫中將這個短鏈對應的原始網址取出來:
如果數據庫中的原始網址,跟我們現在正在處理的原始網址是一樣的,這就說明已經有人請求過這個原始網址的短鏈了。我們就可以拿這個短鏈直接用。
如果數據庫中記錄的原始網址,跟我們正在處理的原始網址不一樣,那就說明哈希算法發生了沖突。不同的原始網址,經過計算,得到的短鏈重復了。這個時候,我們可以給原始網址拼接一串特殊字符,比如 DUPLICATED,然后再重新計算哈希值,兩次哈希計算都沖突的概率,顯然是非常低的。
假設出現非常極端的情況,又發生沖突了,我們可以再換一個拼接字符串,比如 OHMYGOD,再計算哈希值。然后把計算得到的哈希值,跟原始網址拼接了特殊字符串之后的文本,一并存儲在 MySQL 數據庫中。
如何優化性能
在短鏈生成的過程中,服務器會執行兩條 SQL 語句:
第一個 SQL 語句是通過短鏈查詢短鏈與原始網址的對應關系
第二個 SQL 語句是將新生成的短鏈和原始網址之間的對應關系存儲到數據庫
很顯然,第二步是無法避免的,而第一步可以通過給短鏈字段建立唯一索引來優化
這樣,當有新的原始網址需要生成短鏈的時候,并不會拿生成的短鏈在數據庫中查找判重,而是直接將生成的短鏈與對應的原始網址嘗試存儲到數據庫中。如果數據庫能夠將數據正常寫入,那說明并沒有違反唯一索引,也就是說,這個新生成的短鏈并沒有沖突。
當然,如果數據庫反饋違反唯一性索引異常,那我們還得重新執行上述的“查詢、寫入”過程,SQL 語句執行的次數不減反增。但是,MurmurHash 的沖突概率還是比較低的,所以,從整體上看,總的 SQL 語句執行次數會大大減少。
那如果數據量非常大,沖突概率大幅上升,這種情況下該怎么辦?
可以使用布隆過濾器。
把已經生成的短鏈,構建成布隆過濾器。當有新的短鏈生成的時候,我們先拿這個新生成的短鏈,在布隆過濾器中查找。如果查找的結果是不存在,那就說明這個新生成的短鏈并沒有沖突。這個時候,我們只需要再執行寫入短鏈和對應原始網頁的 SQL 語句就可以了。
方法二:ID 生成器
我們可以維護一個 ID 自增生成器。它可以生成 1、2、3…這樣自增的整數 ID。當短鏈服務接收到一個原始網址轉化成短鏈的請求之后,它先從 ID 生成器中取一個號碼,然后將其轉化成 62 進制表示法,拼接到短鏈服務的域名(比如http://sourl.cn/)后面,就形成了最終的短鏈。最后,我們還是會把生成的短鏈和對應的原始網址存儲到數據庫中。
理論非常簡單好理解。不過,這里有幾個細節問題需要處理。
相同的原始網址可能會對應不同的短鏈
每次新來一個原始網址,我們就生成一個新的短鏈,這種做法就會導致兩個相同的原始網址生成了不同的短鏈。這個該如何處理呢?實際上,我們有兩種處理思路。
第一種處理思路是不做處理。聽起來有點匪夷所依,但實際上,相同的原始網址對應不同的短鏈,這個用戶是完全可以接受的。在大部分短鏈的應用場景里,用戶只關心短鏈能否正確地跳轉到原始網址。至于短鏈長什么樣子,他其實根本就不關心。
第二種處理思路是拿原始網址在數據庫中查找,看數據庫中是否已經存在相同的原始網址了。如果數據庫中存在,那我們就取出對應的短鏈,直接返回給用戶。
不過,這種處理思路有個問題,我們需要給數據庫中的短鏈和原始網址這兩個字段,都添加索引。短鏈上加索引是為了提高用戶查詢短鏈對應的原始網頁的速度,原始網址上加索引是為了加快剛剛講的通過原始網址查詢短鏈的速度。這種解決思路雖然能滿足 “相同原始網址對應相同短鏈” 這樣一個需求,但是是有代價的:一方面兩個索引會占用更多的存儲空間,另一方面索引還會導致插入、刪除等操作性能的下降。
如何實現高性能的 ID 生成器
實現 ID 生成器的方法有很多,比如利用數據庫自增。當然我們也可以自己維護一個計數器,不停地加一加一。但是,一個計數器來應對頻繁的短鏈生成請求,顯然是有點吃力的(因為計數器必須保證生成的 ID 不重復,籠統概念上講,就是需要加鎖)。如何提高 ID 生成器的性能呢?關于這個問題,實際上,有很多解決思路。我這里給出兩種思路。
第一種思路是給 ID 生成器裝多個前置發號器。我們批量地給每個前置發號器發送 ID 號碼段(這一段的 ID 歸屬于這個發號器,不用擔心ID 重復)。當我們接受到短鏈生成請求的時候,只需要選擇一個前置發號器來取號碼就行了。這樣通過多個前置發號器,明顯提高了并發發號的能力。
可能不是很好理解,這里類比下 “無鎖的并發生產者 - 消費者模型”:
對于生產者來說,它往隊列中添加數據之前,先申請可用空閑存儲單元,并且是批量地申請連續的 n 個(n≥1)存儲單元。當申請到這組連續的存儲單元之后,后續往隊列中添加元素,就可以不用加鎖了,因為這組存儲單元是這個線程獨享的。不過,申請存儲單元的過程還是需要加鎖的。
對于消費者來說,處理的過程跟生產者是類似的。它先去申請一批連續可讀的存儲單元(這個申請的過程也是需要加鎖的),當申請到這批存儲單元之后,后續的讀取操作就可以不用加鎖了。
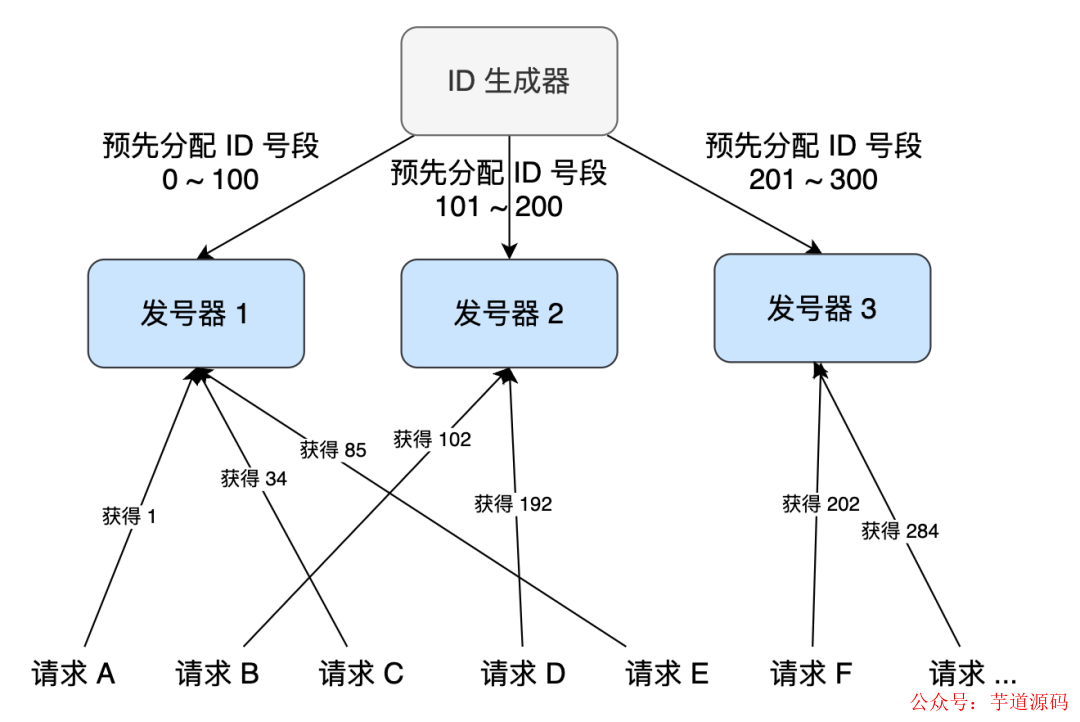
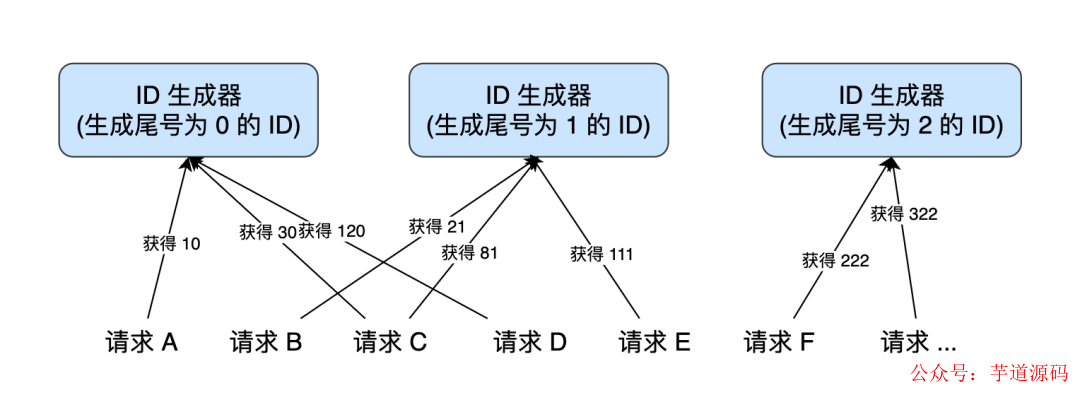
第二種思路跟第一種差不多。不過,我們不再使用一個 ID 生成器和多個前置發號器這樣的架構,而是直接實現多個 ID 生成器同時服務。每個 ID 生成器按照不同的規則來生成 ID 號碼,從而保證每個 ID 生成器生成的 ID 不重復。比如,第一個 ID 生成器只能生成尾號為 0 的,第二個只能生成尾號為 1 的,以此類推。這樣通過多個 ID 生成器同時工作,也提高了 ID 生成的效率。
審核編輯:劉清
-
計數器
+關注
關注
32文章
2283瀏覽量
95850 -
URL
+關注
關注
0文章
139瀏覽量
15752 -
限流器
+關注
關注
0文章
43瀏覽量
14623 -
SHA
+關注
關注
0文章
17瀏覽量
8516 -
哈希算法
+關注
關注
1文章
56瀏覽量
10885
原文標題:字節三面:如何設計一個高性能短鏈系統?
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

設備的優勢,高性能
解鎖高性能計算與區塊鏈應用,阿里云Kubernetes服務召喚神龍
請問怎么設計一種高性能數據采集系統?
電源系統優化系列——如何分析高性能信號鏈中電源紋波
基于區塊鏈中心化應用設計的下一代高性能公鏈MultiVAC介紹

分享一個高性能通信庫的簡單使用技巧





 工商網監
工商網監
評論