") 三維場景點(diǎn)云理解與重建技術(shù)
三維場景點(diǎn)云理解與重建技術(shù)

三維場景理解與重建技術(shù)能夠使計(jì)算機(jī)對真實(shí)場景進(jìn)行高精度復(fù)現(xiàn)并引導(dǎo)機(jī)器以三維空間的思維理解整個(gè)真實(shí)世界,從而使機(jī)器擁有足夠智能參與到真實(shí)世界的生產(chǎn)與建設(shè),并能通過場景的模擬為人類的決策和生活提供服務(wù)。
三維場景理解與重建技術(shù)主要包含場景點(diǎn)云特征提取、掃描點(diǎn)云配準(zhǔn)與融合、場景理解與語義分割、掃描物體點(diǎn)云補(bǔ)全與細(xì)粒度重建等,在處理真實(shí)掃描場景時(shí),受到掃描設(shè)備、角度、距離以及場景復(fù)雜程度的影響,對技術(shù)的精準(zhǔn)度和穩(wěn)定性提出了更高的要求,相關(guān)的技術(shù)也十分具有挑戰(zhàn)性。
其中,原始掃描點(diǎn)云特征提取與配準(zhǔn)融合旨在將同場景下多個(gè)掃描區(qū)域進(jìn)行特征匹配,從而融合得到完整的場景點(diǎn)云,是理解與重建技術(shù)的基石;場景點(diǎn)云的理解與語義分割的目的在于對場景模型進(jìn)行整體感知并根據(jù)語義特征劃分為功能性物體甚至是部件的點(diǎn)云,是整套技術(shù)的核心組成部分;后續(xù)的物體點(diǎn)云細(xì)粒度補(bǔ)全主要研究掃描物體的結(jié)構(gòu)恢復(fù)和殘缺部分補(bǔ)全,是場景物體點(diǎn)云細(xì)粒度重建的關(guān)鍵性技術(shù)。
本文圍繞上述系列技術(shù),詳細(xì)分析了基于三維點(diǎn)云的場景理解與重建技術(shù)相關(guān)的應(yīng)用領(lǐng)域和研究方向,歸結(jié)總結(jié)了國內(nèi)外的前沿進(jìn)展與研究成果,對未來的研究方向和技術(shù)發(fā)展進(jìn)行了展望。
00引言
三維場景模型是真實(shí)世界在計(jì)算機(jī)中進(jìn)行數(shù)字化后的具體表征方式,對三維場景模型的研究不僅能夠使機(jī)器模仿人類通過三維空間的思維來理解周圍環(huán)境,更能夠使機(jī)器以智能體的方式參與到真實(shí)三維世界的工業(yè)生產(chǎn)、城市與交通規(guī)劃以及與人體的交互中。
基于三維場景模型研究的核心在于對三維場景的語義理解以及細(xì)粒度重建,而點(diǎn)云作為采集設(shè)備通用的三維數(shù)據(jù)形式,常被主流的工作用于表征三維場景模型進(jìn)行相關(guān)研究。
場景點(diǎn)云通常可以通過色彩深度(RGB-D)相機(jī)、激光雷達(dá)等設(shè)備對場景進(jìn)行掃描來獲得。除此之外,室內(nèi)場景點(diǎn)云也可以利用即時(shí)定位與地圖構(gòu)建(SLAM)的技術(shù)(Hosseinzadeh等,2019),通過相機(jī)拍攝的相鄰幀間的圖像估計(jì)相機(jī)運(yùn)動(dòng),并恢復(fù)場景的空間結(jié)構(gòu)來得到。但是通過掃描方法得到的原始點(diǎn)云往往并不完整,需要后續(xù)的處理,而后續(xù)的掃描點(diǎn)云特征提取與融合主要包括對掃描的原始點(diǎn)云進(jìn)行點(diǎn)級別的幾何特征提取,以及根據(jù)點(diǎn)的特征進(jìn)行配準(zhǔn)從而完成點(diǎn)云的融合。其中的點(diǎn)云配準(zhǔn)是從掃描三維數(shù)據(jù)到完整點(diǎn)云場景模型的核心技術(shù)模塊(李建微和占家旺,2022)。
三維場景掃描與配準(zhǔn)系列技術(shù)可以廣泛應(yīng)用于真實(shí)場景的三維建模以及虛擬混合現(xiàn)實(shí)等信息化生產(chǎn)與數(shù)字娛樂的應(yīng)用中。針對不同點(diǎn)云提取特征的主要挑戰(zhàn)在于探索局部點(diǎn)云幾何特征的平移旋轉(zhuǎn)不變性,找到不同掃描數(shù)據(jù)中的匹配區(qū)域。然而由于掃描設(shè)備掃描角度距離存在差異,同時(shí)受到離群噪聲點(diǎn)的影響,同一區(qū)域的點(diǎn)云也有不同,這會(huì)大幅提升特征提取與匹配的難度。
三維場景語義理解的目的是根據(jù)語義信息識(shí)別場景中不同功能的物體,從而對整個(gè)場景進(jìn)行物體甚至是部件級別的劃分。對場景點(diǎn)云進(jìn)行語義分割的技術(shù)也能直接在機(jī)器人與場景物體的交互以及自動(dòng)駕駛這些場景中得到很好的運(yùn)用。這個(gè)任務(wù)所包含的場景特征識(shí)別、網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)、多任務(wù)協(xié)同以及面對極少標(biāo)注樣本時(shí)的應(yīng)對技術(shù)也都是國內(nèi)外的研究熱點(diǎn)。然而,三維點(diǎn)云的結(jié)構(gòu)不規(guī)則性、不同掃描設(shè)備以及距離角度導(dǎo)致的不均勻性使得魯棒的三維特征提取變得十分困難,而對不同三維場景進(jìn)行精準(zhǔn)的語義分割甚至是實(shí)例分割也成為了一項(xiàng)十分具有挑戰(zhàn)性的任務(wù)(龍霄瀟等,2021)。
物體掃描點(diǎn)云補(bǔ)全的核心作用在于針對遮擋所導(dǎo)致的點(diǎn)云殘缺問題利用已有的大型完整點(diǎn)云數(shù)據(jù)庫學(xué)習(xí)完整點(diǎn)云的先驗(yàn)知識(shí),從而將殘缺的物體點(diǎn)云修復(fù)為完整的點(diǎn)云。該類方法可有效修復(fù)物體掃描時(shí)出現(xiàn)的殘缺,同時(shí)能夠在機(jī)器人應(yīng)用中對不可視區(qū)域做出合理推理。
針對大型合成三維模型數(shù)據(jù)集以及真實(shí)掃描物體的點(diǎn)云補(bǔ)全受到了國內(nèi)外的廣泛關(guān)注,吸引了眾多學(xué)者。此類技術(shù)重點(diǎn)研究點(diǎn)云編解碼方式以及跨域跨數(shù)據(jù)集之間的統(tǒng)一特征學(xué)習(xí)方法。由于點(diǎn)云本身的非結(jié)構(gòu)化表征方式,仍然缺乏細(xì)粒度點(diǎn)云解碼與重建的方法。針對無完整點(diǎn)云的掃描數(shù)據(jù),也很難僅憑借合成的完整模型數(shù)據(jù)集進(jìn)行掃描點(diǎn)云補(bǔ)全。
01點(diǎn)云特征提取與匹配
隨著深度學(xué)習(xí)在二維圖像上的廣泛應(yīng)用,其在三維數(shù)據(jù)上的拓展取得了不錯(cuò)的成就。三維數(shù)據(jù)有多種表示方式,例如體素、網(wǎng)格以及點(diǎn)云等方式。
傳統(tǒng)的深度學(xué)習(xí)框架得益于二維卷積架構(gòu)。結(jié)合現(xiàn)代并行計(jì)算硬件,卷積操作能夠高效地處理規(guī)則的數(shù)據(jù)結(jié)構(gòu),但圖像缺失的深度信息往往會(huì)導(dǎo)致語義歧義性,特別是在極端光照(Tan等,2021)或特殊光路(Tan等,2023)的條件下。
作為在三維數(shù)據(jù)的拓展,三維卷積應(yīng)運(yùn)而生,能夠自然地處理規(guī)則化的體素?cái)?shù)據(jù)。然而,相較于二維圖像,處理體素這種表示方式需要的計(jì)算資源呈指數(shù)級增長。并且,三維結(jié)構(gòu)是稀疏的,這導(dǎo)致體素這一類表示方式會(huì)造成大量的計(jì)算資源浪費(fèi)。面對大場景分析任務(wù)時(shí),體素將不再適合。
相反,點(diǎn)云這種無規(guī)則表征能夠簡單有效地表示稀疏的三維數(shù)據(jù)結(jié)構(gòu),在三維場景理解任務(wù)中發(fā)揮了重要作用。因此,針對點(diǎn)云的特征提取是面向三維場景分析流程中的重要一環(huán)。點(diǎn)云特征提取的技術(shù)取得了前所未有的發(fā)展。
本節(jié)圍繞傳統(tǒng)點(diǎn)云特征提取、深度學(xué)習(xí)在點(diǎn)云上的初應(yīng)用、點(diǎn)云卷積、稀疏卷積和點(diǎn)云Transformer介紹點(diǎn)云特征提取的相關(guān)研究以及點(diǎn)云特征提取在點(diǎn)云匹配任務(wù)下的應(yīng)用。
1.1 傳統(tǒng)點(diǎn)云特征提取
傳統(tǒng)點(diǎn)云特征提取借助三維點(diǎn)云的局部幾何信息進(jìn)行編碼生成幾何算子,作為點(diǎn)云局部幾何特征。一個(gè)好的三維算子具有一些優(yōu)秀的性質(zhì),如可描述性、緊密性和魯棒性等。其中,可描述性以及魯棒性被認(rèn)為是三維局部特征算子最重要的屬性。算子是可描述的是指其能夠封裝三維表面中的主導(dǎo)信息內(nèi)容。
換句話說,算子能夠提供充足的可描述內(nèi)容來區(qū)分兩個(gè)不同的表面。算子的魯棒性是指其對于模型引入的噪聲和變化不敏感。在過去幾十年的發(fā)展中,研究人員提出了針對不同特性的三維幾何算子。大多數(shù)三維局部特征算子都是對局部三維表面的幾何信息進(jìn)行編碼。
在這些算子中,一部分利用局部幾何統(tǒng)計(jì)量來表示局部表面不同的性質(zhì)。具體來說,通過累計(jì)特定域(例如點(diǎn)坐標(biāo)、幾何屬性)中幾何的或拓?fù)涞牧炕担ɡ琰c(diǎn)的數(shù)量)構(gòu)建統(tǒng)計(jì)直方圖,用于表示幾何特征。這些方法依據(jù)統(tǒng)計(jì)的類型可以分為空間分布統(tǒng)計(jì)算子和幾何屬性統(tǒng)計(jì)算子。
基于空間分布統(tǒng)計(jì)算子統(tǒng)計(jì)了局部區(qū)域內(nèi)點(diǎn)云分布狀態(tài)。自旋圖像(SI)算法(Johnson和Hebert,1999)利用給定關(guān)鍵點(diǎn)與其法向量構(gòu)建局部參考坐標(biāo)軸,并記錄局部區(qū)域中任意點(diǎn)到關(guān)鍵點(diǎn)切平面內(nèi)、外的距離作為算子的統(tǒng)計(jì)量。
三維形狀上下文特征(3DSC)方法(Frome等,2004)同樣構(gòu)建參考坐標(biāo)軸。不同的是,其將局部空間劃分為三維球形網(wǎng)格,通過統(tǒng)計(jì)每一個(gè)網(wǎng)格中的點(diǎn)數(shù)量作為該區(qū)域的算子。唯一形狀上下文特征(USC)算法(Tombari等,2010)作為3DSC的一個(gè)拓展,通過構(gòu)建局部坐標(biāo)參考系,鎖定了參考坐標(biāo)軸存在的繞軸旋轉(zhuǎn)的自由度,從而排除了算子歧義性。旋轉(zhuǎn)投影統(tǒng)計(jì)量(RoPS)構(gòu)建局部參考系(Guo等,2013)。
針對每一坐標(biāo)軸,RoPS都將點(diǎn)云繞軸旋轉(zhuǎn)多個(gè)離散角度值,并統(tǒng)計(jì)點(diǎn)云沿坐標(biāo)軸的分布圖來得到最終算子。
基于幾何屬性統(tǒng)計(jì)算子計(jì)算局部表面上點(diǎn)的幾何屬性(例如法向量,曲率)統(tǒng)計(jì)直方圖來表示特征。
局部表面補(bǔ)丁(LSP)算法(Chen和Bhanu,2007)通過統(tǒng)計(jì)區(qū)域內(nèi)每一點(diǎn)和關(guān)鍵點(diǎn)法向量夾角的余弦值來表征幾何特征。
Thrift算法(Flint等,2007)根據(jù)與關(guān)鍵點(diǎn)之間的偏移角進(jìn)行劃分,統(tǒng)計(jì)不同偏移角度區(qū)間點(diǎn)分布情況作為幾何特征。
持久特征直方圖(PFH)算法(Rusu等,2008)依據(jù)局部區(qū)域任意兩點(diǎn)構(gòu)成的點(diǎn)對的表面法向量來構(gòu)建Darboux參考系,通過統(tǒng)計(jì)參考系中的距離角度信息作為局部幾何特征。
快速點(diǎn)特征直方圖(FPFH)算法(Rusu等,2009)作為PFH的改進(jìn),僅采用中心點(diǎn)與區(qū)域中任一點(diǎn)構(gòu)成的點(diǎn)對計(jì)算特征值,降低了計(jì)算復(fù)雜度。
方向直方圖特征(SHOT)算法(Salti等,2014)首先構(gòu)建局部參考系,并將局部空間根據(jù)半徑、方位角以及仰角劃分為球形網(wǎng)格,統(tǒng)計(jì)了每一個(gè)網(wǎng)格中點(diǎn)法向量分布,構(gòu)成最終的算子。
點(diǎn)對特征(PPF)方法(Drost等,2010)依據(jù)計(jì)算任意點(diǎn)對的距離、法向量之間的夾角以及兩點(diǎn)連線與法向量之間的夾角構(gòu)成4維特征來表示幾何結(jié)構(gòu)。
1.2 點(diǎn)云深度學(xué)習(xí)
點(diǎn)云特征提取的先驅(qū)是Qi等人(2017a)提出的PointNet。點(diǎn)云數(shù)據(jù)由于其離散以及不規(guī)則性,傳統(tǒng)需要權(quán)重共享的卷積操作無法直接應(yīng)用到點(diǎn)云數(shù)據(jù)上。
傳統(tǒng)的研究方法將點(diǎn)云轉(zhuǎn)換到對應(yīng)的三維體素網(wǎng)格或多視角下的圖像數(shù)據(jù),從而可以間接使用卷積操作構(gòu)建深度網(wǎng)絡(luò)結(jié)構(gòu),提取特征。然而,這種方式會(huì)生成龐大而不必要的冗余數(shù)據(jù),并引入了許多量化計(jì)算,會(huì)改變數(shù)據(jù)原本包含的信息內(nèi)容。
其實(shí),點(diǎn)云本身是一種簡單統(tǒng)一的表示方式,直接從點(diǎn)云提取特征可以避免不必要以及不規(guī)則的組合計(jì)算,又可以降低三維結(jié)構(gòu)表征的復(fù)雜度。
PointNet是一個(gè)統(tǒng)一的點(diǎn)云處理架構(gòu),直接以點(diǎn)云數(shù)據(jù)的三維坐標(biāo)作為輸入,可以預(yù)測完整點(diǎn)云的類別標(biāo)簽用于點(diǎn)云分類任務(wù),還能夠輸出逐點(diǎn)的語義標(biāo)簽用于物體部件分割以及場景語意分割等任務(wù)。PointNet方法的關(guān)鍵技術(shù)是利用一個(gè)簡單的對稱函數(shù)max-pooling,使模型網(wǎng)絡(luò)能夠有效學(xué)習(xí)到一組優(yōu)化指標(biāo)。這些指標(biāo)可以挑選出表示完整點(diǎn)云信息的關(guān)鍵特征。同時(shí),對稱函數(shù)可以確保輸出的結(jié)果與輸入點(diǎn)的排列順序無關(guān)。
PointNet最后的全連接層將這些學(xué)習(xí)優(yōu)化后的特征值匯聚到一個(gè)全局的描述子中用于表示整個(gè)點(diǎn)云,可以進(jìn)一步用于預(yù)測逐點(diǎn)的語義標(biāo)簽。點(diǎn)云的另一個(gè)優(yōu)勢是模型可以輕易地對其進(jìn)行剛體或仿射變化,因?yàn)槊恳粋€(gè)點(diǎn)的變換是獨(dú)立的。于是,PointNet引入一個(gè)獨(dú)立于數(shù)據(jù)的空間變換網(wǎng)絡(luò)(STN),使PointNet開始處理輸入數(shù)據(jù)之前,先將輸入數(shù)據(jù)標(biāo)準(zhǔn)化,從而進(jìn)一步提升實(shí)驗(yàn)結(jié)果。
研究人員對于處理點(diǎn)云數(shù)據(jù)對稱函數(shù)也展開了許多相關(guān)研究(Ravanbakhsh等,2017;Zaheer等,2017;Li等,2018a)。
PointNet開創(chuàng)了點(diǎn)云特征提取的先河,學(xué)習(xí)得到每一個(gè)輸入點(diǎn)的空間編碼,然后將各個(gè)單獨(dú)的點(diǎn)匯總成一個(gè)全局點(diǎn)云標(biāo)志。PointNet設(shè)計(jì)的全局對稱函數(shù)造成其無法捕獲局部的結(jié)構(gòu)信息。
然而,對于局部信息的探索被證實(shí)為卷積神經(jīng)網(wǎng)絡(luò)的重要成功因素。一個(gè)標(biāo)準(zhǔn)卷積神經(jīng)網(wǎng)絡(luò)可以在逐漸增加的尺度上不斷地提取特征,從而形成一個(gè)多尺度的分層架構(gòu)來獲取不同分辨率下的局部特征。在低層的神經(jīng)一般具有較小的感受野,在高層的則具有更大的感受野。
為了點(diǎn)云特征提取結(jié)構(gòu)也能夠繼承2維卷積神經(jīng)網(wǎng)絡(luò)的特點(diǎn),獲取局部幾何信息,Qi等人(2017b)在PointNet基礎(chǔ)上進(jìn)一步提出了分層結(jié)構(gòu)的PointNet++,首先利用最遠(yuǎn)點(diǎn)采樣(FPS)將輸入的點(diǎn)云根據(jù)距離標(biāo)準(zhǔn)劃分為若干互相重疊的球形局部區(qū)域。
與卷積神經(jīng)網(wǎng)絡(luò)相似,每一個(gè)小的局部區(qū)域都會(huì)用PointNet提取特征,作為細(xì)粒度的局部幾何結(jié)構(gòu)表征,同時(shí)不同區(qū)域可以貢獻(xiàn)特征提取的權(quán)重。類似的局部特征會(huì)聚集組合到一個(gè)更大的幾何單元中,從而處理得到更高層的特征。該步驟會(huì)不斷重復(fù),直至得到完整點(diǎn)云的特征。
PointNet++最顯著的貢獻(xiàn)在于其利用在不同尺度下的鄰域幾何信息來實(shí)現(xiàn)魯棒的細(xì)粒度特征提取。
1.3 點(diǎn)云卷積
PointNet++提供了分層和多尺度提取點(diǎn)云局部特征的范式。不過與2維卷積操作相比,其特征提取方式與2維卷積操作仍存在差異。
傳統(tǒng)卷積操作針對鄰域中不同區(qū)域賦予了相互獨(dú)立的權(quán)重用于區(qū)分各自的相對位置。PointNet++對局部鄰域中的每一個(gè)點(diǎn)都賦予相同的權(quán)重進(jìn)行特征提取,未區(qū)分各自點(diǎn)的在鄰域中的相對位置。后續(xù)研究均利用該信息進(jìn)一步改進(jìn),并提出了點(diǎn)云的卷積操作。
Li等人(2018b)提出了點(diǎn)卷積神經(jīng)網(wǎng)絡(luò)(PointCNN),通過在點(diǎn)云上的卷積操作實(shí)現(xiàn)了點(diǎn)云卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)的搭建。2維卷積依據(jù)每一個(gè)像素在規(guī)則的局部網(wǎng)格中的位置,按順序賦予權(quán)重進(jìn)行卷積操作。與2維規(guī)則的網(wǎng)格數(shù)據(jù)不同,三維數(shù)據(jù)局部鄰域中點(diǎn)云的空間分布是不規(guī)則的,其排序方式有多種方式。根據(jù)不同的排序方式,點(diǎn)云卷積得到的結(jié)果往往是不相等的。因此,確定鄰域中點(diǎn)的順序使之與權(quán)重順序相對應(yīng)是PointCNN解決的一個(gè)難題。PointCNN提出了χ-卷積操作。χ-卷積首先依據(jù)輸入鄰域中心點(diǎn),并將鄰域中點(diǎn)相對中心的位置用多層感知器進(jìn)行編碼。結(jié)合位置編碼以及輸入點(diǎn)特征,再次利用多層感知器生成χ-變換矩陣,將鄰域中點(diǎn)依據(jù)變換矩陣進(jìn)行排序使之產(chǎn)生固定的順序,從而賦予對應(yīng)位置下的卷積權(quán)重。χ-卷積操作確保了點(diǎn)云卷積結(jié)果不受輸入點(diǎn)排列順序改變的影響。PointCNN最早實(shí)現(xiàn)了2維卷積到點(diǎn)云卷積的拓展,為點(diǎn)云特征提取打下了良好的基石。后續(xù)研究工作提出了各種各樣點(diǎn)云卷積的變體。
SpiderCNN(Xu等,2018)利用鄰域中點(diǎn)的測地信息以及三線性插值方式來生成給定鄰域中的濾波器,依據(jù)該濾波器便可對鄰域點(diǎn)進(jìn)行卷積操作。Hua等人(2018)設(shè)計(jì)了逐點(diǎn)的卷積操作,通過核支持區(qū)域劃分局部空間用于卷積操作。
動(dòng)態(tài)圖卷積神經(jīng)網(wǎng)絡(luò)(DGCNN)算法(Wang等,2019)利用鄰域點(diǎn)中心點(diǎn)位置和鄰域點(diǎn)的相對位置生成對應(yīng)點(diǎn)特征每一維的權(quán)重來實(shí)現(xiàn)卷積操作。形狀關(guān)系卷積神經(jīng)網(wǎng)絡(luò)(RSCNN)算法(Liu等,2019b)也利用鄰域中點(diǎn)的相對位置生成權(quán)重來實(shí)現(xiàn)卷積操作。
不同于利用多層感知器生成卷積權(quán)重的方法,核心點(diǎn)卷積(KPConv)算法(Thomas等,2019)是一種全新的點(diǎn)云卷積運(yùn)算。KPConv的靈感同樣來自于基于2維圖像的卷積。類似2維卷積使用像素網(wǎng)格作為卷積核,KPConv定義了一系列固定位置的核點(diǎn)用于卷積操作。卷積的權(quán)重分別由這些核點(diǎn)生成。每一個(gè)核點(diǎn)所輻射的空間根據(jù)相關(guān)函數(shù)來確定。輸入的點(diǎn)通過尋找與其相鄰最近的核點(diǎn),利用其核點(diǎn)對應(yīng)的權(quán)重以及到核點(diǎn)的距離的計(jì)算結(jié)果作為卷積操作的輸出值。值得注意的是,鄰域中核點(diǎn)的數(shù)量是不確定的,使得KPConv能夠靈活地適應(yīng)不同的輸入點(diǎn)云,并且不受輸入點(diǎn)云密度變化的影響。在此基礎(chǔ)上,KPConv還拓展出可形變的形式。對于每一個(gè)核點(diǎn),網(wǎng)絡(luò)可以針對每一個(gè)卷積區(qū)域生成對應(yīng)的偏移向量去改變核點(diǎn)的空間位置,使其更好地適應(yīng)輸入點(diǎn)云結(jié)構(gòu)。KPConv可以構(gòu)建出非常深的網(wǎng)絡(luò)架構(gòu),同時(shí)保持快速的訓(xùn)練以及推理時(shí)間。
將點(diǎn)云構(gòu)建成圖結(jié)構(gòu),在圖上進(jìn)行卷積操作也是提取點(diǎn)云特征的一種方式。這種方式與直接在點(diǎn)云上卷積具有一定的相似性。在圖上的卷積可以使用在其光譜表示上的乘法來實(shí)現(xiàn)(Defferrard等,2016;Yi等,2017),也可以利用在點(diǎn)云表面上所構(gòu)建得到的圖來實(shí)現(xiàn)(Masci等,2015;Bronstein等,2017;Simonovsky和Komodakis,2017;Monti等,2017)。
1.4 稀疏卷積
由于三維數(shù)據(jù)的稀疏性,完整的三維物體體素表示并不適合作為三維特征提取的輸入。借鑒點(diǎn)云離散表示三維場景表面的方式,將點(diǎn)云進(jìn)一步轉(zhuǎn)化為稀疏體素,并利用稀疏卷積網(wǎng)絡(luò)來提取特征成為研究的熱點(diǎn)。稀疏卷積網(wǎng)絡(luò)僅對空間中非空的體素進(jìn)行卷積操作,從而避免了傳統(tǒng)三維卷積在非空體素上浪費(fèi)大量的計(jì)算和存儲(chǔ)資源。
Graham等人(2018)率先提出了稀疏卷積的概念,并設(shè)計(jì)了子流形稀疏卷積和網(wǎng)絡(luò)框架來處理稀疏的三維場景數(shù)據(jù)。Choy等人(2019a)提出了稀疏卷積網(wǎng)絡(luò)架構(gòu)Minkowski Engine。對于傳統(tǒng)語音、文字以及圖像數(shù)據(jù),特征往往是稠密地提取。然而對于三維掃描數(shù)據(jù),甚至在更高維度的空間中,這種稠密的表示效率十分低。原因是數(shù)據(jù)在高維空間的分布往往是稀疏的。因此,Choy等人(2019a)認(rèn)為可以僅保存空間中非空的部分作為其坐標(biāo)以及關(guān)聯(lián)的特征,即稀疏矩陣在高維空間的拓展,名為稀疏張量。在稀疏張量上卷積的定義與傳統(tǒng)卷積操作一樣,僅需要給出卷積步長、稀疏張量坐標(biāo)以及點(diǎn)云轉(zhuǎn)換成稀疏張量時(shí)的步長。實(shí)現(xiàn)稀疏卷積最重要的步驟就是確定輸入張量和輸出張量的映射。不同于2維卷積輸出坐標(biāo)容易計(jì)算得到,稀疏張量是點(diǎn)任意聚集在一起的。因此,稀疏卷積需要給出輸入張量到輸出的映射來實(shí)現(xiàn)輸入和卷積核的卷積操作,該映射定義為核映射。最后,給定核映射、權(quán)重以及輸入輸出坐標(biāo)即可實(shí)現(xiàn)稀疏卷積操作,從而對稀疏體素進(jìn)行特征提取。
Liu等人(2019c)提出點(diǎn)—體素卷積(PVC),同時(shí)在點(diǎn)云和體素兩種表示下提取特征。PVC利用點(diǎn)云表示輸入三維數(shù)據(jù)來減少內(nèi)存消耗,同時(shí)利用體素表示減少組合不規(guī)則數(shù)據(jù)帶來的不必要的計(jì)算浪費(fèi)。對于點(diǎn)云處理分支,PVC對每一個(gè)點(diǎn)進(jìn)行單獨(dú)處理;對于體素處理分支,PVC對體素化的點(diǎn)進(jìn)行卷積處理。盡管基于PVC的神經(jīng)網(wǎng)絡(luò)(PVCNN)能夠處理大體積的體素?cái)?shù)據(jù)。單個(gè)體素包含大范圍的實(shí)際區(qū)域,但是PVCNN對于小個(gè)體(例如行人)的識(shí)別能力很差。因?yàn)樾€(gè)體僅占用了少量的體素從而增強(qiáng)了識(shí)別難度。一種解決方案是將大范圍場景用滑動(dòng)窗口劃分為不同的子區(qū)域,在子區(qū)域進(jìn)行特征提取,然而子區(qū)域劃分的操作并不適用于實(shí)時(shí)的應(yīng)用。針對PVCNN的缺陷,Tang等人(2020)在PVCNN的基礎(chǔ)上提出了稀疏的點(diǎn)—體素卷積(sparse point-voxel convolution,SPVC)。對于點(diǎn)云分支,SPVC依舊保持高精度的特征提取。而對于體素分支,SPVC則借鑒稀疏卷積,在不同尺度進(jìn)行特征提取。兩個(gè)分支之間的信息傳遞所需要的資源是可以忽略的。
1.5 點(diǎn)云Transformer
基于自注意力機(jī)制的Transformer(Vaswani等,2017)網(wǎng)絡(luò)結(jié)構(gòu)在自然語言處理任務(wù)上引發(fā)了巨大變革,確立了大模型在自然語言處理各項(xiàng)任務(wù)上的領(lǐng)先地位。與此同時(shí),自注意力機(jī)制在圖像分析任務(wù)上的拓展也取得了不錯(cuò)的成就。參考Transformer在自然語言處理和圖像分析領(lǐng)域上的成功,研究人員展開了在點(diǎn)云數(shù)據(jù)處理上的Transformer拓展。
Zhao等人(2021)和Guo等人(2021)提出了用于點(diǎn)云特征提取的Transformer架構(gòu)。Guo等人(2021)所設(shè)計(jì)的點(diǎn)云Transformer架構(gòu)將自注意力機(jī)制應(yīng)用到全局的點(diǎn)云上,即輸入點(diǎn)云任意點(diǎn)之間均計(jì)算關(guān)聯(lián)度。這種全局方式受限于內(nèi)存和計(jì)算資源,只能應(yīng)用在點(diǎn)數(shù)量較少的單個(gè)物體或小場景,而無法處理大場景點(diǎn)云數(shù)據(jù)。Zhao等人(2020)基于向量注意力機(jī)制實(shí)現(xiàn)了針對局部點(diǎn)的Transformer架構(gòu)。向量注意力機(jī)制主要計(jì)算給定點(diǎn)與其相鄰點(diǎn)之間的關(guān)聯(lián)度,從而對每個(gè)點(diǎn)均復(fù)用該權(quán)重。關(guān)注局部信息的Transformer顯著降低了內(nèi)存資源的占用。不足的是,基于向量注意力機(jī)制網(wǎng)絡(luò)結(jié)構(gòu)的參數(shù)量隨著深度的增加而大幅度增加,將導(dǎo)致嚴(yán)重的過擬合以及深度限制問題。并且,點(diǎn)云的坐標(biāo)位置相對于2維圖像的像素位置提供了更復(fù)雜的幾何信息,對點(diǎn)云特征提取至關(guān)重要。傳統(tǒng)的用于圖像Transformer的位置編碼不再適用于點(diǎn)云數(shù)據(jù)。針對以上問題,Wu等人(2022)提出改進(jìn)版本的點(diǎn)云Transformer(PTv2),利用分組向量注意力機(jī)制有效降低了模型參數(shù)量,同時(shí)設(shè)計(jì)了專門針對三維點(diǎn)云的位置編碼機(jī)制,提升了模型框架對點(diǎn)之間的幾何關(guān)聯(lián)的敏感程度。
1.6 點(diǎn)云旋轉(zhuǎn)不變特征提取
上述點(diǎn)云特征提取方法與2維卷積相似,僅具有平移不變性。但是對于三維點(diǎn)云,其在現(xiàn)實(shí)空間中會(huì)處在不同的姿態(tài)之下。同時(shí)旋轉(zhuǎn)變換會(huì)給點(diǎn)云特征提取帶來一定程度的影響。因此,許多工作專門針對提取點(diǎn)云旋轉(zhuǎn)不變特征展開研究。點(diǎn)云旋轉(zhuǎn)不變特征提取大致分為3類。第1類利用旋轉(zhuǎn)不變幾何特征作為模型的輸入,代替受旋轉(zhuǎn)變換影響的坐標(biāo)輸入;第2類尋找表示點(diǎn)云旋轉(zhuǎn)不變的局部參考系來避免旋轉(zhuǎn)變化帶來的影響;第3類則是估計(jì)輸入點(diǎn)云的姿態(tài)并將其調(diào)整到標(biāo)準(zhǔn)姿態(tài)再提取特征。
旋轉(zhuǎn)不變卷積(RIConv)算法(Zhang等,2019)、ClusterNet(Chen等,2019)和排序Gram矩陣網(wǎng)絡(luò)(SGMNet)算法(Xu等,2021a)通過計(jì)算輸入點(diǎn)云點(diǎn)之間的相對距離和角度作為特征來代替點(diǎn)坐標(biāo)作為網(wǎng)絡(luò)結(jié)構(gòu)的輸入。由于旋轉(zhuǎn)變換為剛體變換,在整體點(diǎn)云經(jīng)過旋轉(zhuǎn)后,點(diǎn)云內(nèi)部幾何仍舊保持相對不變。因此局部幾何中點(diǎn)之間的相對距離以及角度等信息可以作為低層旋轉(zhuǎn)不變特征,從而利用神經(jīng)網(wǎng)絡(luò)進(jìn)一步提取高層特征。然而,在將點(diǎn)坐標(biāo)轉(zhuǎn)換為這些底層特征的過程中伴隨著重要幾何信息的損失,所以這類方法面臨不同程度的結(jié)果下降。集成位置關(guān)系特征的旋轉(zhuǎn)不變網(wǎng)絡(luò)(PR-invNet)(Yu等,2020)方法和Li等人(2021a)提出的方法首先利用主成分分析(PCA)選取最代表點(diǎn)云幾何結(jié)構(gòu)的3個(gè)坐標(biāo)軸作為參考系表示點(diǎn)云的標(biāo)準(zhǔn)姿態(tài)。但是PCA存在歧義性,點(diǎn)云的標(biāo)準(zhǔn)姿態(tài)并不唯一。因此,這類方法利用固定數(shù)量的旋轉(zhuǎn)增強(qiáng)構(gòu)建一個(gè)姿態(tài)空間來涵蓋所有存在歧義的標(biāo)準(zhǔn)姿態(tài),并利用姿態(tài)選擇器挑選一個(gè)最終姿態(tài)表示該點(diǎn)云的旋轉(zhuǎn)不變表示。旋轉(zhuǎn)不變圖卷積網(wǎng)絡(luò)(RI-GCN)算法(Kim等,2020)和邊緣對齊卷積神經(jīng)網(wǎng)絡(luò)(AECNN)算法(Zhang等,2020a)則設(shè)計(jì)不同的局部參考系提取局部的旋轉(zhuǎn)不變特征,最終匯聚得到全局的旋轉(zhuǎn)不變特征。RI-GCN利用PCA構(gòu)建局部鄰域點(diǎn)對應(yīng)的參考系,而AECNN則利用局部鄰域中心點(diǎn)以及請求點(diǎn)之間的相對位置構(gòu)建局部參考系。局部參考系之所以能夠作為點(diǎn)云的旋轉(zhuǎn)不變特征,是因?yàn)樾D(zhuǎn)變換不改變點(diǎn)云的局部幾何結(jié)構(gòu)。
1.7 點(diǎn)云匹配
點(diǎn)云特征提取方法將無規(guī)則的點(diǎn)云結(jié)構(gòu)抽取為高維包含各種結(jié)構(gòu)信息的幾何特征。這些特征可以用于相似幾何結(jié)構(gòu)的匹配任務(wù),構(gòu)建其對應(yīng)關(guān)系,并依據(jù)對應(yīng)關(guān)系實(shí)現(xiàn)點(diǎn)云的配準(zhǔn)。在現(xiàn)實(shí)場景應(yīng)用中,掃描得到的點(diǎn)云往往不是完整的,拍攝得到的點(diǎn)云序列需要拼接才能得到完整的場景點(diǎn)云數(shù)據(jù)。找到合適的點(diǎn)云特征用于匹配不同掃描點(diǎn)云之間的幾何關(guān)系極為關(guān)鍵。深度點(diǎn)云特征提取方式為場景點(diǎn)云匹配提供了新的思路。
利用預(yù)訓(xùn)練的方式進(jìn)行點(diǎn)云特征匹配是一種常用的方式。首先分別提取輸入兩塊點(diǎn)云的特征。接著利用對比學(xué)習(xí),在特征空間中拉近存在對應(yīng)關(guān)系點(diǎn)的特征對,將幾何結(jié)構(gòu)相差較大的特征對互相推遠(yuǎn),從而使提取的點(diǎn)云特征能夠?qū)⑾嗨茙缀谓Y(jié)構(gòu)的區(qū)域匹配上。3DMatch(Zeng等,2017)提出了用于場景匹配的數(shù)據(jù)集,并將場景中任意兩塊互相有重疊區(qū)域的點(diǎn)云構(gòu)建匹配對用于訓(xùn)練得到匹配特征,利用三維卷積實(shí)現(xiàn)場景的特征提取。3DSmoothNet(Gojcic等,2019)在3DMatch基礎(chǔ)上引入了旋轉(zhuǎn)不變局部參考系,使提取的特征與旋轉(zhuǎn)變換不相關(guān)。全卷積幾何特征(FCGF)算法(Choy等,2019b)利用系數(shù)卷積提取點(diǎn)云特征,并提出了最困難樣本對比學(xué)習(xí),使點(diǎn)云特征彼此更具區(qū)分度,更容易學(xué)習(xí)得到不相關(guān)特征之間的邊界。稠密三維三維局部特征檢測與描述(D3Feat)算法(Bai等,2020)利用稠密特征提取獲取更精細(xì)的點(diǎn)云特征,并利用關(guān)鍵點(diǎn)預(yù)測篩選出更具代表性的候選匹配點(diǎn)。SpinNet(spin network)(Ao等,2021)使用柱形卷積提取點(diǎn)云特征來提升匹配表現(xiàn)。
另一種點(diǎn)云匹配的方法是結(jié)合點(diǎn)云特征提取和點(diǎn)云匹配進(jìn)行端到端的訓(xùn)練。借助2維圖像端到端匹配的思路(Sarlin等,2020;Sun等,2021),首先提取場景點(diǎn)云從粗到細(xì)的特征,接著根據(jù)粗特征生成相似度矩陣進(jìn)行粗匹配,再根據(jù)得到的匹配點(diǎn)周圍的細(xì)粒度特征進(jìn)一步進(jìn)行細(xì)匹配。端到端訓(xùn)練的方式(Yu等,2021a;Qin等,2022;Yew和Lee,2022)在點(diǎn)云匹配任務(wù)上取得了不錯(cuò)的成就。
點(diǎn)云匹配成功地實(shí)現(xiàn)了將真實(shí)場景下拍攝得到的離散的點(diǎn)云碎片拼接成完整的場景點(diǎn)云。
02場景點(diǎn)云語義分割
基于點(diǎn)云場景的語義分割技術(shù)是對三維場景精細(xì)化、智能化理解的關(guān)鍵技術(shù)之一。語義分割任務(wù)早先源于對數(shù)字圖像進(jìn)行逐像素分類的需求(Long等,2015),后逐漸向三維視覺領(lǐng)域拓展。由于點(diǎn)云是三維場景中常用的離散化表征方式,因此逐點(diǎn)的語義類別預(yù)測成為三維視覺中的一項(xiàng)重要研究方向。與特征稠密分布的數(shù)字圖像相比,三維點(diǎn)云場景數(shù)據(jù)規(guī)模大、覆蓋空間廣、特征分布稀疏以及缺乏順序性,使得點(diǎn)云語義分割任務(wù)成為一大挑戰(zhàn)。本節(jié)從點(diǎn)云場景表征與數(shù)據(jù)集、點(diǎn)云語義分割方法分類、多模態(tài)融合的分割方法與場景點(diǎn)云的實(shí)例分割方法四方面綜述國內(nèi)外研究趨勢。
2.1 場景表征與數(shù)據(jù)集
點(diǎn)云場景表征方式可分為室內(nèi)場景表征與室外場景表征。
2.1.1 室內(nèi)場景表征與相關(guān)數(shù)據(jù)集
早期點(diǎn)云場景分割任務(wù)大多定義在室內(nèi)場景中。室內(nèi)傳感器采集到的點(diǎn)云數(shù)據(jù)通常分布相對稠密,具備良好的幾何結(jié)構(gòu)特征,適合神經(jīng)網(wǎng)絡(luò)進(jìn)行細(xì)粒度的分割。室內(nèi)場景表征方法主要包括基于點(diǎn)特征的表征方法、基于圖網(wǎng)絡(luò)的表征方法和基于注意力機(jī)制的表征方法(Ye等,2022)。
基于點(diǎn)的特征提取網(wǎng)絡(luò)PointNet與PointNet++(Qi等,2017a,b)是早期的點(diǎn)云特征提取網(wǎng)絡(luò)。在此基礎(chǔ)上,后續(xù)工作針對室內(nèi)場景分割任務(wù)特點(diǎn)對網(wǎng)絡(luò)進(jìn)行優(yōu)化改進(jìn)。例如,為進(jìn)一步挖掘點(diǎn)云局部區(qū)域間的上下文信息, PointWeb網(wǎng)絡(luò)(Zhao等,2019)在PointNet++基礎(chǔ)上提出自適應(yīng)特征調(diào)整模塊,利用局部區(qū)域中點(diǎn)對點(diǎn)的交互改變其在特征空間中的位置,以獲取更好的區(qū)域特征向量。PointCNN(Li等,2018b)與PointConv(Wu等,2019b)等網(wǎng)絡(luò)致力于定義基于點(diǎn)特征的卷積操作,根據(jù)空間密度、距離權(quán)重等設(shè)計(jì)卷積核,并構(gòu)建深度點(diǎn)卷積網(wǎng)絡(luò)提取特征等。Liu等人(2020)針對點(diǎn)云局部特征聚合操作,總結(jié)了基于多層感知機(jī)(MLP)、基于偽網(wǎng)格特征和基于相對位置加權(quán)的3種改進(jìn)方式。基于點(diǎn)特征提取網(wǎng)絡(luò)能較好地捕捉點(diǎn)云局部信息,但是對于全場景特征提取有欠缺,且在大規(guī)模點(diǎn)云數(shù)據(jù)集上存儲(chǔ)與計(jì)算資源占用較大,不夠高效。
基于圖網(wǎng)絡(luò)的表征方式充分考慮空間中點(diǎn)、邊緣和區(qū)域等元素之間的鄰接關(guān)系,是對三維幾何結(jié)構(gòu)的近似刻畫。如Wang等人(2018a)提出的譜圖卷積網(wǎng)絡(luò),對局部區(qū)域內(nèi)的鄰近點(diǎn)子集構(gòu)建完全圖,通過圖傅里葉變換將特征映射到頻域空間中再進(jìn)行譜濾波,增強(qiáng)了提取空間結(jié)構(gòu)特征的能力。與之類似的正則圖卷積神經(jīng)網(wǎng)絡(luò)(RGCNN)算法(Te等,2018)對點(diǎn)云的圖卷積網(wǎng)絡(luò)的監(jiān)督函數(shù)增加了基于平滑性先驗(yàn)的正則項(xiàng)約束,使圖卷積網(wǎng)絡(luò)學(xué)習(xí)到的空間特征具有更好的幾何連續(xù)性。Wang等人(2019)提出DGCNN,在每一層動(dòng)態(tài)圖上增加對邊卷積網(wǎng)絡(luò)層,能更好地學(xué)習(xí)室內(nèi)物體的形狀特征與潛在語義特征。然而,基于圖網(wǎng)絡(luò)的表征方式同樣面臨在大規(guī)模點(diǎn)云數(shù)據(jù)集上的存儲(chǔ)開銷和計(jì)算速度問題。
基于注意力網(wǎng)絡(luò)的表征方式通過注意力機(jī)制建模三維空間中點(diǎn)之間或區(qū)域之間的上下文關(guān)系。Feng等人(2020)針對卷積網(wǎng)絡(luò)難以充分提取不規(guī)則點(diǎn)云分布的特征的缺陷,提出了使用基于點(diǎn)的局部注意力和邊緣卷積網(wǎng)絡(luò),通過空間注意力機(jī)制構(gòu)建大范圍內(nèi)長距離的關(guān)系信息。在此基礎(chǔ)上,之后的研究工作開始利用基于Transformer的自注意力機(jī)制來提取點(diǎn)云表征,進(jìn)而獲取豐富的局部鄰域信息和區(qū)域之間的上下文關(guān)系。Park等人(2022)提出由輕量級的自注意力層組成的快速點(diǎn)云Transformer網(wǎng)絡(luò),通過編碼連續(xù)的點(diǎn)云坐標(biāo)和基于體素哈希的架構(gòu)來有效地提升網(wǎng)絡(luò)的計(jì)算效率。Yu等人(2022)設(shè)計(jì)了一種基于掩碼Transformer的點(diǎn)云預(yù)訓(xùn)練方法,首先將整個(gè)輸入點(diǎn)云切分為若干區(qū)域塊并隨機(jī)掩蓋掉部分區(qū)域塊,然后使用基于Transformer的點(diǎn)云網(wǎng)絡(luò)來恢復(fù)缺失的點(diǎn)云數(shù)據(jù),從而達(dá)到預(yù)訓(xùn)練的目的。除此之外,為了解決自注意力機(jī)制在大規(guī)模點(diǎn)云數(shù)據(jù)集上空間和時(shí)間復(fù)雜度較的問題,Zhang等人(2022)提出了基于塊注意力的點(diǎn)云Transformer網(wǎng)絡(luò)來自適應(yīng)地學(xué)習(xí)更小點(diǎn)集的特征,并設(shè)計(jì)了輕量級的多尺度注意力網(wǎng)絡(luò)來構(gòu)建不同場景規(guī)模下的區(qū)域注意力關(guān)系。此類基于Transformer的點(diǎn)云特征提取網(wǎng)絡(luò)利用注意力機(jī)制來獲取三維空間中點(diǎn)之間或區(qū)域之間的上下文關(guān)系,同樣存在對存儲(chǔ)空間占用高的問題。
室內(nèi)點(diǎn)云場景數(shù)據(jù)集主要以RGB-D相機(jī)掃描得到的數(shù)據(jù)為主,包括NYUv2數(shù)據(jù)集(Silberman等,2012)、SUN RGB-D數(shù)據(jù)集(Song等,2015)、S3DIS數(shù)據(jù)集(Armeni等,2016)和ScanNet數(shù)據(jù)集(Dai等,2017)等。這些數(shù)據(jù)集涵蓋多種室內(nèi)場景,包含從物體級別語義標(biāo)注到全場景的高層次標(biāo)注,有力支持了室內(nèi)點(diǎn)云場景分割的研究發(fā)展。
2.1.2 室外場景表征與相關(guān)數(shù)據(jù)集
隨著智慧城市建設(shè)、自動(dòng)駕駛感知等應(yīng)用任務(wù)需求增加,室外場景表征方法受到廣泛關(guān)注。室外場景與室內(nèi)場景相比,場景類型更加復(fù)雜,點(diǎn)云密度更加稀疏,室外天氣與光照影響更加明顯,各類別物體長尾分布現(xiàn)象更加嚴(yán)重,使得室外點(diǎn)云場景分割成為一項(xiàng)極具挑戰(zhàn)性的任務(wù)。
目前的室外場景表征方法大致包括基于環(huán)視圖(range view)的分割方法、基于稀疏卷積(sparse voxel)的方法、基于鳥瞰圖(bird-eye-view,BEV)的方法和基于神經(jīng)輻射場(NeRF)的方法。基于環(huán)視圖的方法(Milioto等,2019;Cortinhal等,2020)將點(diǎn)云數(shù)據(jù)360°投影到預(yù)設(shè)半徑的環(huán)視面(range view)上,形成2維環(huán)視圖,然后使用圖像卷積網(wǎng)絡(luò)提取特征并預(yù)測分割結(jié)果。最后通過相關(guān)后處理算法(k近鄰采樣、雙線性插值等)將環(huán)視圖的分割結(jié)果傳播到點(diǎn)云上。該類方法的優(yōu)勢在于可以用二維卷積網(wǎng)絡(luò)提取三維點(diǎn)云投影降維后的圖像特征,較好滿足實(shí)時(shí)性需求。缺點(diǎn)是將二維分割結(jié)果傳播到三維點(diǎn)云數(shù)據(jù)時(shí)會(huì)造成較大的精度損失。基于稀疏卷積的方法(Graham等,2018)通過將卷積計(jì)算限制在活躍區(qū)域(active region)中,避免納入空區(qū)域的計(jì)算操作,從而大幅減少計(jì)算量。在此基礎(chǔ)上,針對室外激光雷達(dá)數(shù)據(jù)集環(huán)形分布特點(diǎn),Zhu等人(2021)采用扇形卷積的方式劃分點(diǎn)云,更好地滿足近密遠(yuǎn)疏的分布特性。近年基于鳥瞰圖的場景特征提取方法日漸興起。點(diǎn)云場景感知中的鳥瞰圖概念源于2020年特斯拉公司公布的全自動(dòng)駕駛算法,但該方案是純視覺方案,具體做法是將多視角相機(jī)拍攝的數(shù)字圖像轉(zhuǎn)化為鳥瞰圖特征。后續(xù)有很多研究者嘗試使用鳥瞰圖類似地表征激光點(diǎn)云場景,如Zhang等人(2020c)提出的PolarNet網(wǎng)絡(luò),在極坐標(biāo)系下,通過池化層將點(diǎn)云特征投影到固定大小的俯視圖平面上,使用卷積網(wǎng)絡(luò)得到2D特征并獲得預(yù)測結(jié)果,最后同一俯視圖柵格里不同高度的點(diǎn)云賦予相同的預(yù)測類別。雖然基于鳥瞰圖特征的表征方式在實(shí)時(shí)分割的前提下也能獲得不錯(cuò)的精度,但是對于懸吊物體的預(yù)測結(jié)果通常較差。基于神經(jīng)輻射場的相關(guān)表征方法(Kundu等,2022)使用多層感知機(jī)構(gòu)建了從三維場景中的位置坐標(biāo)(視角+距離)到語義特征(顏色+反射率)的映射函數(shù),作為三維場景的神經(jīng)輻射場用于輔助下游語義分割任務(wù)。該類方法可直接用于下游的三維場景分割任務(wù),亦可以作為點(diǎn)云—圖像融合的上游特征提取器,在未來有較大的研究與應(yīng)用前景。
室外場景數(shù)據(jù)集根據(jù)傳感器不同,主要分為激光雷達(dá)(light detection and ranging,LiDAR)數(shù)據(jù)集和毫米波雷達(dá)(radiodetection and ranging,RADAR)數(shù)據(jù)集。室外靜態(tài)LiDAR數(shù)據(jù)集如Semantic3D(Hackel等,2017)提供了包括城市、鄉(xiāng)村、廣場以及街景建筑等多種場景的三維語義數(shù)據(jù)。室外自動(dòng)駕駛場景LiDAR數(shù)據(jù)集,如SemanticKitti(Behley等,2019)、nuScenes(Caesar等,2020)、Waymo Open Dataset(Sun等,2020)和Lyft L5(Houston等,2020)等提供了自動(dòng)駕駛場景下的大規(guī)模點(diǎn)云—圖像多模態(tài)數(shù)據(jù)集,包含行人、非機(jī)動(dòng)車、機(jī)動(dòng)車以及各類交通標(biāo)注物等類別。此外,nuScenes與Waymo Open Dataset數(shù)據(jù)集亦提供毫米波雷達(dá)的相關(guān)數(shù)據(jù),可有效支持在雨天、雪天和霧天等極端天氣下較準(zhǔn)確地探測到移動(dòng)物體。
2.2 點(diǎn)云場景語義分割
2.2.1 全監(jiān)督分割方法
點(diǎn)云場景語義分割任務(wù)需要神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到多種場景下的三維特征表示。由于三維場景的復(fù)雜性,僅依靠數(shù)據(jù)集自身提供的全量標(biāo)簽直接訓(xùn)練特征提取器,難以使神經(jīng)網(wǎng)絡(luò)快速學(xué)習(xí)到有價(jià)值的信息。因此,很多全監(jiān)督分割方法會(huì)挖掘點(diǎn)云的先驗(yàn)信息,如空間分布特征和時(shí)序特征,增強(qiáng)網(wǎng)絡(luò)對點(diǎn)云的識(shí)別與分割能力。Gong等人(2021b)提出了邊緣預(yù)測模塊(boundary prediction module)和邊緣幾何特征編碼模塊(boundary-awaregeometry encoding module),使得神經(jīng)網(wǎng)絡(luò)對物體的邊緣特征更加敏感,從而提升分割準(zhǔn)確率。Chen等人(2022)利用激光點(diǎn)云中的中心對稱性分布特征,提出極角正則化數(shù)據(jù)增強(qiáng)操作,將不同水平角下劃分的點(diǎn)云區(qū)域旋轉(zhuǎn)到相同的角度,減小了因角度多樣性給點(diǎn)云網(wǎng)絡(luò)訓(xùn)練帶來的困難,在多種點(diǎn)云語義分割基線網(wǎng)絡(luò)中得到分割精度的提升。Schutt等人(2022)借鑒光流法的思想,提出基于多級循環(huán)神經(jīng)網(wǎng)絡(luò)連接的前后點(diǎn)云幀時(shí)序融合方法,使點(diǎn)云網(wǎng)絡(luò)能夠更有效地區(qū)分靜止物體與運(yùn)動(dòng)物體。
此外,點(diǎn)云場景的表征方式多種多樣,如何充分利用不同的表征方式融合點(diǎn)云各項(xiàng)信息,從而降低語義分割的訓(xùn)練難度也是研究者關(guān)注的內(nèi)容。Xu等人(2021b)提出環(huán)視圖—點(diǎn)—體素三位一體的融合模塊,增強(qiáng)了同一個(gè)點(diǎn)在不同表征下的特征交互的能力。Ye等人(2021)在點(diǎn)—體素雙路感知網(wǎng)絡(luò)的基礎(chǔ)上,提出了交替轉(zhuǎn)換的訓(xùn)練方法,將原先雙分支各自獨(dú)立訓(xùn)練的方式改為從點(diǎn)云到稀疏體素,從稀疏體素到點(diǎn)云兩種融合模塊,并在這兩種融合模塊間進(jìn)行多輪循環(huán)迭代,充分提取各個(gè)層次上的體素級與點(diǎn)級語義信息。Gong等人(2021a)首次提出一種層次化感受野因果推理模塊,將場景分割問題轉(zhuǎn)化成多種類別所在的子區(qū)域感受野成分分解和編碼問題。Li等人(2022b)提出了基于特征金字塔和注意力感知的點(diǎn)—網(wǎng)格融合插件模塊,對環(huán)視圖—鳥瞰圖雙路點(diǎn)云感知網(wǎng)絡(luò)進(jìn)行增強(qiáng),在多種數(shù)據(jù)集上達(dá)到了領(lǐng)先的性能。
2.2.2 有限標(biāo)注條件下的分割方法
相比全監(jiān)督學(xué)習(xí),有限標(biāo)注信息下的點(diǎn)云語義分割方法有更加豐富的應(yīng)用場景和工業(yè)界落地需求,在實(shí)現(xiàn)精度上接近全監(jiān)督方法的同時(shí),盡可能減少人工標(biāo)注的成本。根據(jù)標(biāo)簽利用方式的不同,可大致分為半監(jiān)督學(xué)習(xí)和弱監(jiān)督學(xué)習(xí)。半監(jiān)督學(xué)習(xí)的目標(biāo)是在只給定部分場景標(biāo)注的條件下訓(xùn)練神經(jīng)網(wǎng)絡(luò)(被選定場景下的點(diǎn)云標(biāo)注是完整的),強(qiáng)化其在不同場景下的泛化能力。而弱監(jiān)督學(xué)習(xí)的目標(biāo)是在給定不完整標(biāo)注的條件下(例如每幀點(diǎn)云場景只隨機(jī)挑選1%的點(diǎn)標(biāo)注),通過學(xué)習(xí)有限區(qū)域的監(jiān)督信息,傳播并習(xí)得所有區(qū)域的點(diǎn)云特征。
針對室內(nèi)半監(jiān)督分割,Li等人(2021b)提出一種基于偽標(biāo)簽置信度預(yù)測的半監(jiān)督分割方法,以減少對大規(guī)模高質(zhì)量人工標(biāo)注的依賴,在分割網(wǎng)絡(luò)的基礎(chǔ)上,額外設(shè)計(jì)判別網(wǎng)絡(luò)(discriminator network),該網(wǎng)絡(luò)目標(biāo)是區(qū)分預(yù)測結(jié)果和真實(shí)標(biāo)注,并對無標(biāo)注點(diǎn)云的預(yù)測結(jié)果輸出置信度預(yù)測,對判別網(wǎng)絡(luò)的訓(xùn)練更好地促進(jìn)了整個(gè)網(wǎng)絡(luò)對無標(biāo)注數(shù)據(jù)的分割與預(yù)測能力。面向室外激光點(diǎn)云數(shù)據(jù)集,Kong等人(2022)基于激光點(diǎn)云掃描線環(huán)視分布的特點(diǎn),提出一種有標(biāo)注場景和無標(biāo)注場景的點(diǎn)云環(huán)形混合增強(qiáng)方法(LaserMix),在多種現(xiàn)有半監(jiān)督方法上均取得較大的分割精度提升。
Xu和Lee(2020)首次在點(diǎn)云上提出弱監(jiān)督語義分割任務(wù),在理論上說明了使用不完整標(biāo)簽的數(shù)據(jù)集訓(xùn)練的網(wǎng)絡(luò)權(quán)重的梯度與全監(jiān)督梯度基本近似,在室內(nèi)點(diǎn)云數(shù)據(jù)集中,提出的基線方法在只使用約10%的點(diǎn)云標(biāo)注條件下,精度可達(dá)到全監(jiān)督方法的95%左右。此后,更多研究者開始關(guān)注如何使用更少的點(diǎn)云標(biāo)注獲得與全監(jiān)督基線更接近的分割性能。Zhang等人(2021b)提出通過加入點(diǎn)云排列增強(qiáng)模塊監(jiān)督預(yù)測結(jié)果的拓?fù)湟恢滦裕谑覂?nèi)場景中使用約1%的真值獲得的mIoU(mean intersection over union)與全監(jiān)督基線的結(jié)果僅相差近2%。基于混合對比學(xué)習(xí)正則化約束的增強(qiáng)方法,Li等人(2022a)使用極少標(biāo)注(0.03%)在室內(nèi)點(diǎn)云數(shù)據(jù)集上獲得的分割精度為全監(jiān)督方法的78.3%。面向室外點(diǎn)云弱監(jiān)督分割任務(wù),Unal等人(2022)提出了首個(gè)室外激光雷達(dá)弱監(jiān)督非精確標(biāo)注數(shù)據(jù)集Scribble-Kitti,并在該數(shù)據(jù)集上使用基于教師—學(xué)生網(wǎng)絡(luò)(Tarvainen和Valpola,2017)改進(jìn)的弱監(jiān)督方法,使用約8%的真值標(biāo)簽獲得的精度可達(dá)到全監(jiān)督方法的96%左右。目前,已有研究工作(Sautier等,2022)在室外激光點(diǎn)云數(shù)據(jù)集上使用約0.8%的真值標(biāo)簽獲得的精度達(dá)到了全監(jiān)督方法的90%左右。
2.2.3 無監(jiān)督分割方法
無標(biāo)注的分割方法主要聚焦在點(diǎn)云自監(jiān)督學(xué)習(xí)和無監(jiān)督域遷移方向。鑒于點(diǎn)云標(biāo)注非常耗費(fèi)時(shí)間與人力資源,只對部分場景進(jìn)行部分標(biāo)注也難以適應(yīng)海量增長的三維點(diǎn)云數(shù)據(jù)量。因此,采用自監(jiān)督學(xué)習(xí)的方式對海量點(diǎn)云進(jìn)行預(yù)訓(xùn)練是一個(gè)值得深入探討的問題。Sautier等人(2022)首次提出一種室外場景下的圖像預(yù)訓(xùn)練權(quán)重向點(diǎn)云網(wǎng)絡(luò)知識(shí)蒸餾的方法,在不需要任何點(diǎn)云與圖像標(biāo)注的條件下,通過提取超級像素(super pixel)建模圖像與點(diǎn)云間高相似度區(qū)域間的對應(yīng)關(guān)系,并通過基于對比學(xué)習(xí)的蒸餾損失函數(shù)進(jìn)行監(jiān)督。Afham等人(2022)在室內(nèi)場景物體上提出一種簡單的跨模態(tài)三維-二維區(qū)域?qū)?yīng)模塊,分別將點(diǎn)云模態(tài)和圖像模態(tài)提取的特征向量重新投影到一個(gè)公共的特征空間中,并基于最大化與模態(tài)無關(guān)的互信息的思想設(shè)計(jì)對比學(xué)習(xí)損失函數(shù)。總體來看,目前的點(diǎn)云自監(jiān)督學(xué)習(xí)方法與全監(jiān)督方法仍有巨大差距,預(yù)訓(xùn)練權(quán)重對下游全監(jiān)督任務(wù)的提升效果有限,有待進(jìn)一步研究發(fā)掘點(diǎn)云自監(jiān)督學(xué)習(xí)的潛力。
除了在無標(biāo)注信息的條件下做網(wǎng)絡(luò)自監(jiān)督預(yù)訓(xùn)練外,另一個(gè)工業(yè)界與學(xué)術(shù)界的重大需求是克服不同域/數(shù)據(jù)集之間的特征分布差距,使模型在源域數(shù)據(jù)集上訓(xùn)練達(dá)到很好的精度時(shí),遷移到無標(biāo)注的目標(biāo)域上能縮小目標(biāo)域特征分布與源域之間的“距離”。Wu等人(2019a)研究從大規(guī)模道路場景仿真數(shù)據(jù)集向真實(shí)數(shù)據(jù)集域遷移,通過提出的鄰域特征聚合模塊和漸進(jìn)式域校正算法有效克服跨域噪聲干擾與信息丟失問題。此后,許多研究工作,如跨模態(tài)無監(jiān)督域適應(yīng)(xMUDA)算法(Jaritz等,2020)和點(diǎn)無監(jiān)督域適應(yīng)(PointUDA)算法(Bian等,2022),圍繞該方向提出一系列改進(jìn)算法,促進(jìn)了無監(jiān)督分割的研究進(jìn)展。
2.3 多模態(tài)融合的分割方法
單一模態(tài)的場景分割方法雖然已達(dá)到較高的精度性能,但也面臨著與模態(tài)相關(guān)的固有缺陷。如純圖像的場景分割容易受光照、遮擋因素影響;RGB-D點(diǎn)云數(shù)據(jù)受限于室內(nèi)小規(guī)模場景掃描;激光點(diǎn)云數(shù)據(jù)在室外容易受極端天氣的干擾;超聲波雷達(dá)數(shù)據(jù)探測精度相對激光點(diǎn)云會(huì)差等。因此,研究跨傳感器多模態(tài)融合的分割方法,可以較好地實(shí)現(xiàn)模態(tài)間信息互補(bǔ),使網(wǎng)絡(luò)更容易學(xué)習(xí)到魯棒性強(qiáng)的場景特征表示。依據(jù)融合方式,目前多模態(tài)點(diǎn)云分割方法大致可以分為前融合、深度特征融合,后融合、非對稱融合四種(Ma等,2022)。依據(jù)使用的主流傳感器類型,可分為激光點(diǎn)云—相機(jī)融合(Zhuang等,2021)和毫米波點(diǎn)云—相機(jī)融合兩類(Zhou等,2022)。雖然目前多模態(tài)融合方法在許多數(shù)據(jù)集上取得領(lǐng)先的性能,但仍有許多問題須待解決。例如,克服跨模態(tài)特征錯(cuò)位對應(yīng)問題、多模態(tài)數(shù)據(jù)集跨域遷移時(shí)模態(tài)失配問題等。該方法仍有很大提升空間。
2.4 場景點(diǎn)云的實(shí)例分割方法
在場景理解中,語義分割雖然能夠提供每個(gè)點(diǎn)的類別屬性,但是無法區(qū)分出每個(gè)實(shí)例的邊界,即缺乏對場景內(nèi)的3D點(diǎn)云進(jìn)行實(shí)例級別的感知。相比于語義分割,實(shí)例分割的著眼點(diǎn)在于區(qū)分不同的實(shí)例,需要對場景內(nèi)的點(diǎn)進(jìn)行額外的身份標(biāo)識(shí)。因此,實(shí)例分割的研究,能夠使環(huán)境感知系統(tǒng)具備理解三維真實(shí)世界中每個(gè)獨(dú)立物體或個(gè)體的能力,直接影響著與三維場景中每個(gè)實(shí)例的交互活動(dòng)。依照流程,目前的實(shí)例分割方法可分為以3D-BoNet(Yang等,2019a)、生成形狀提議網(wǎng)絡(luò)(GSPN)算法(Yi等,2019)為代表的基于Proposal的方法和以PointGroup(Jiang等,2020)、層次化聚合三維樣例分割(HAIS)算法(Chen等,2021)為代表的Proposal-free的方法。基于Proposal的方法遵循自上而下的流程,首先生成眾多的實(shí)例候選區(qū)域,并在每個(gè)區(qū)域內(nèi)預(yù)測實(shí)例的掩碼;Proposal-free的方法則采用自底向上的方式,通過計(jì)算點(diǎn)之間的相似度或距離,將點(diǎn)聚類至不同的實(shí)例之中。從當(dāng)前的研究工作來看,Proposal-free的實(shí)例分割方法在ScanNet和S3DIS等數(shù)據(jù)集上取得了不錯(cuò)的性能。
03掃描點(diǎn)云物體補(bǔ)全
點(diǎn)云作為一種表征三維物體的基礎(chǔ)數(shù)據(jù)形式,具備高緯度信息量的優(yōu)勢,在自動(dòng)駕駛和場景感知等領(lǐng)域有著廣泛的應(yīng)用。但是在點(diǎn)云數(shù)據(jù)采集的過程中,由于遮擋、噪聲干擾和視角變換等問題,真實(shí)掃描到的三維點(diǎn)云通常會(huì)出現(xiàn)殘缺和數(shù)據(jù)不完整的問題,嚴(yán)重阻礙了下游的點(diǎn)云分析和處理任務(wù)的性能。因此,通過殘缺點(diǎn)云數(shù)據(jù)恢復(fù)出三維物體的整體形狀的三維點(diǎn)云補(bǔ)全任務(wù)逐漸成為一個(gè)新的研究熱點(diǎn)。
本節(jié)首先總結(jié)三維點(diǎn)云補(bǔ)全任務(wù)中常用的數(shù)據(jù)集,然后從全監(jiān)督點(diǎn)云補(bǔ)全和真實(shí)掃描點(diǎn)云跨域補(bǔ)全兩方面介紹三維點(diǎn)云補(bǔ)全任務(wù)。
3.1 點(diǎn)云補(bǔ)全數(shù)據(jù)集
對于三維點(diǎn)云補(bǔ)全任務(wù),常用的數(shù)據(jù)集主要分為人工生成的點(diǎn)云數(shù)據(jù)集和真實(shí)掃描的點(diǎn)云數(shù)據(jù)集兩種類別。人工生成的數(shù)據(jù)集是通過在某個(gè)固定視角下均勻采集三維面片模型的表面點(diǎn)云,得到具有殘缺幾何形狀的三維點(diǎn)云數(shù)據(jù)。真實(shí)掃描的點(diǎn)云數(shù)據(jù)集則是通過激光雷達(dá)等采集設(shè)備從真實(shí)環(huán)境中直接掃描得到不完整的三維點(diǎn)云數(shù)據(jù)。
3.1.1 人工生成的點(diǎn)云補(bǔ)全數(shù)據(jù)集
ShapeNet數(shù)據(jù)集(Chang等,2015)是一個(gè)大規(guī)模的三維模型數(shù)據(jù)集,具有豐富的注釋信息,共包含55種常見的物體類別和220 000個(gè)計(jì)算機(jī)輔助設(shè)計(jì)(computer aided design,CAD)模型,每個(gè)模型對應(yīng)的三維點(diǎn)云大概包含15 000個(gè)數(shù)據(jù)點(diǎn)。對點(diǎn)云補(bǔ)全任務(wù)來說,選取8個(gè)類別的物體,共30 974個(gè)三維CAD。其中,完整的點(diǎn)云數(shù)據(jù)通過在每個(gè)三維模型的表面均勻采樣2 048個(gè)點(diǎn)組成,對應(yīng)的殘缺點(diǎn)云數(shù)據(jù)則是將這個(gè)三維模型隨機(jī)視圖下的深度圖反投影到三維空間來獲得,殘缺點(diǎn)云的點(diǎn)數(shù)也是2 048個(gè)。
ModelNet40數(shù)據(jù)集(Wu等,2015)是一個(gè)綜合的三維CAD模型數(shù)據(jù)集,包含40個(gè)類別和13 356個(gè)模型。殘缺點(diǎn)云數(shù)據(jù)和完整點(diǎn)云數(shù)據(jù)的獲得方法與ShapeNet數(shù)據(jù)集相同。
3.1.2 真實(shí)掃描的點(diǎn)云補(bǔ)全數(shù)據(jù)集
KITTI數(shù)據(jù)集(Geiger等,2012)是通過激光掃描儀收集的。該數(shù)據(jù)集最初是為了評估立體匹配的性能,由雷達(dá)點(diǎn)云、點(diǎn)云數(shù)據(jù)序列和標(biāo)注信息組成,包含22個(gè)點(diǎn)云數(shù)據(jù)序列,其中訓(xùn)練集包括11個(gè)具有標(biāo)注信息的點(diǎn)云數(shù)據(jù)序列,評估集包含11個(gè)沒有標(biāo)注的點(diǎn)云數(shù)據(jù)序列。對于三維點(diǎn)云補(bǔ)全任務(wù)來說,只選取了其中的汽車類別作為訓(xùn)練和測試數(shù)據(jù)。其中,殘缺的三維點(diǎn)云數(shù)據(jù)是通過均勻選取2 048個(gè)數(shù)據(jù)點(diǎn)獲得。KITTI數(shù)據(jù)集中的三維點(diǎn)云數(shù)據(jù)是非常稀疏的,且物體的幾何結(jié)構(gòu)往往是不完整的,因此在這個(gè)數(shù)據(jù)集上進(jìn)行點(diǎn)云補(bǔ)全非常具有挑戰(zhàn)性。
3.2 全監(jiān)督點(diǎn)云補(bǔ)全
三維點(diǎn)云補(bǔ)全任務(wù)旨在從輸入的殘缺點(diǎn)云數(shù)據(jù)中恢復(fù)物體完整的幾何形狀。全監(jiān)督三維點(diǎn)云補(bǔ)全是在有完整點(diǎn)云數(shù)據(jù)作為監(jiān)督標(biāo)簽的情況下,訓(xùn)練點(diǎn)云補(bǔ)全網(wǎng)絡(luò),達(dá)到預(yù)測完整補(bǔ)全結(jié)果的目的。根據(jù)三維點(diǎn)云補(bǔ)全任務(wù)中采用的網(wǎng)絡(luò)結(jié)構(gòu),全監(jiān)督點(diǎn)云補(bǔ)全方法可以分為基于點(diǎn)、基于圖、基于生成對抗模型和基于變分自動(dòng)編碼器的點(diǎn)云補(bǔ)全方法。
3.2.1 基于點(diǎn)的全監(jiān)督點(diǎn)云補(bǔ)全
基于點(diǎn)的點(diǎn)云補(bǔ)全方法通常采用編碼器—解碼器方式設(shè)計(jì)網(wǎng)絡(luò)架構(gòu)。在編碼器—解碼器結(jié)構(gòu)中,補(bǔ)全分支中的編碼器旨在提取全局的三維幾何特征和每個(gè)點(diǎn)的區(qū)域局部特征。而解碼器負(fù)責(zé)預(yù)測三維物體完整的點(diǎn)云并對其進(jìn)行細(xì)化處理。
Xia等人(2020)設(shè)計(jì)了端到端的三維點(diǎn)云補(bǔ)全網(wǎng)絡(luò),從車輛應(yīng)用中的稀疏點(diǎn)云重建更均勻和更精細(xì)的結(jié)構(gòu),同時(shí)采用上采樣方法生成更均勻的點(diǎn)云。此外,提出一種非對稱的連體特征匹配網(wǎng)絡(luò)(Xia等,2021),其中,非對稱連體自動(dòng)編碼器生成粗略但完整的點(diǎn)云數(shù)據(jù),隨后的細(xì)化單元旨在恢復(fù)具有細(xì)粒度細(xì)節(jié)的最終點(diǎn)云預(yù)測結(jié)果。Mendoza等人(2020)提出一個(gè)由缺失部分預(yù)測模塊和合并細(xì)化模塊共同組成的端到端補(bǔ)全網(wǎng)絡(luò),在保留現(xiàn)有幾何形狀和細(xì)化細(xì)節(jié)的同時(shí)預(yù)測點(diǎn)云數(shù)據(jù)的殘缺部分。Peng等人(2020)提出一種端到端的稀疏到密集多編碼器神經(jīng)網(wǎng)絡(luò)來補(bǔ)全殘缺點(diǎn)云數(shù)據(jù),同時(shí)可以有效保留原始三維物體的形狀細(xì)節(jié)。殘缺的輸入點(diǎn)云分兩個(gè)階段補(bǔ)全和細(xì)化。在第1階段,基于兩層感知機(jī)網(wǎng)絡(luò)生成粗略但完整的結(jié)果;在第2階段,使用新的網(wǎng)絡(luò)對第1階段的稀疏結(jié)果進(jìn)行編碼和解碼,以產(chǎn)生高密度和高保真點(diǎn)云數(shù)據(jù)。Miao等人(2021)提出一種具有形狀保持功能的補(bǔ)全網(wǎng)絡(luò),通過設(shè)計(jì)編碼器—解碼器的方式來保持物體的三維形狀并恢復(fù)重建物體的精細(xì)信息。這種形狀保持網(wǎng)絡(luò)可以學(xué)習(xí)全局特征并整合具有不同方向和尺度的相鄰點(diǎn)的區(qū)域信息。在解碼過程中,信息將融合到潛在向量中。
3.2.2 基于圖的全監(jiān)督點(diǎn)云補(bǔ)全
由于點(diǎn)云和圖都可以視為非歐幾里得的結(jié)構(gòu)化數(shù)據(jù),因此將點(diǎn)或局部區(qū)域作為某些圖的頂點(diǎn)來探索點(diǎn)或局部區(qū)域之間的關(guān)系是很有潛力的方法。基于圖的網(wǎng)絡(luò)可以將輸入中的每個(gè)點(diǎn)都視為頂點(diǎn),同時(shí)利用相鄰點(diǎn)的信息來生成邊。因此,圖卷積網(wǎng)絡(luò)可以適用于點(diǎn)云的處理和補(bǔ)全任務(wù)。
Wang等人(2019)開創(chuàng)性地提出DGCNN,成功地將動(dòng)態(tài)圖卷積結(jié)構(gòu)引入三維點(diǎn)云補(bǔ)全任務(wù)。在動(dòng)態(tài)圖卷積中,相鄰矩陣可以通過來自潛在空間的頂點(diǎn)關(guān)系計(jì)算,該圖是在特征空間中建立的,可以在網(wǎng)絡(luò)訓(xùn)練過程中動(dòng)態(tài)更新。Hassani和Haley(2019)引入多級網(wǎng)絡(luò)來利用點(diǎn)和形狀特征進(jìn)行自監(jiān)督的三維點(diǎn)云補(bǔ)全。Wu等人(2021a,b)提出一種基于學(xué)習(xí)的圖卷積方法,對部分輸入的局部區(qū)域進(jìn)行采樣,對其特征進(jìn)行編碼,并將它們與全局特征相結(jié)合。建立圖后,收集所有區(qū)域特征,并用多頭注意力機(jī)制對圖進(jìn)行卷積。圖注意機(jī)制使每個(gè)局部特征向量能夠跨區(qū)域搜索,并根據(jù)高維特征空間中的關(guān)系選擇性地吸收其他局部特征。同時(shí),設(shè)計(jì)了一個(gè)基于圖注意力的跨區(qū)域注意力單元,該模塊量化了特定背景下區(qū)域特征之間的潛在聯(lián)系,并通過全局特征進(jìn)行解釋。因此,每個(gè)條件區(qū)域特征向量都可以作為圖注意力進(jìn)行搜索。Zhang等人(2021c)設(shè)計(jì)了一個(gè)圖神經(jīng)網(wǎng)絡(luò)模塊,通過局部—全局注意機(jī)制和基于多尺度圖的上下文聚合,全面捕捉點(diǎn)之間的關(guān)系,大幅增強(qiáng)了圖網(wǎng)絡(luò)編碼特征。
3.2.3 基于生成對抗模型的全監(jiān)督點(diǎn)云補(bǔ)全
與傳統(tǒng)的卷積網(wǎng)絡(luò)相比,生成對抗網(wǎng)絡(luò)(generative adverserial network,GAN)利用判別器的隱式學(xué)習(xí)來估計(jì)生成器預(yù)測的完整點(diǎn)云的準(zhǔn)確性。本節(jié)將從端到端機(jī)制和點(diǎn)云精細(xì)化模塊兩部分介紹基于生成對抗模型的全監(jiān)督點(diǎn)云補(bǔ)全。
圍繞端到端機(jī)制,Wang等人(2017)利用編碼器將體素化的三維形狀映射到概率潛在空間中,并使用生成對抗學(xué)習(xí)來幫助解碼器借助潛在特征表示生成完整的點(diǎn)云形狀。Achlioptas等人(2018)則使用全連接層設(shè)計(jì)了具有生成器和判別器的生成對抗網(wǎng)絡(luò),自動(dòng)編碼器被訓(xùn)練來學(xué)習(xí)潛在空間,然后在固定的潛在表示中訓(xùn)練生成模型。這種網(wǎng)絡(luò)在潛在空間中進(jìn)行訓(xùn)練,比普通的生成對抗網(wǎng)絡(luò)更容易訓(xùn)練,從而可以更好地恢復(fù)殘缺的物體的幾何結(jié)構(gòu)。
點(diǎn)云的精細(xì)化模塊常常作為一項(xiàng)關(guān)鍵性的技術(shù)集成到生成對抗學(xué)習(xí)中。Wang等人(2020b)提出一種用于學(xué)習(xí)先驗(yàn)形狀的特征對齊方法。同時(shí),設(shè)計(jì)了一種從粗到細(xì)的方法,將形狀先驗(yàn)與從粗到細(xì)的策略相結(jié)合。除此之外,還設(shè)計(jì)了一個(gè)點(diǎn)云補(bǔ)全網(wǎng)絡(luò)(Wang等,2020a),以級聯(lián)細(xì)化網(wǎng)絡(luò)作為生成器,通過利用輸入的細(xì)節(jié)高質(zhì)量地生成點(diǎn)云殘缺的幾何結(jié)構(gòu)。同時(shí),設(shè)計(jì)了一個(gè)分片化處理的判別器,使用對抗訓(xùn)練來精確地學(xué)習(xí)點(diǎn)云分布,并約束預(yù)測點(diǎn)云與完整點(diǎn)云之間不同的幾何結(jié)構(gòu)。
3.2.4 基于變分自動(dòng)編碼器的全監(jiān)督點(diǎn)云補(bǔ)全
Spurek等人(2021)首次利用變分自動(dòng)編碼器架構(gòu)來補(bǔ)全輸入的殘缺點(diǎn)云的完整幾何結(jié)構(gòu)。其中,點(diǎn)云處理被分成兩個(gè)未連接的數(shù)據(jù)流,并利用超網(wǎng)絡(luò)范式來恢復(fù)丟失部分留下的空間結(jié)構(gòu)。Pan等人(2021)設(shè)計(jì)了一種變分關(guān)系補(bǔ)全網(wǎng)絡(luò),利用雙路徑單元和基于變分編碼器的關(guān)系增強(qiáng)模塊進(jìn)行概率建模,同時(shí)還設(shè)計(jì)了多個(gè)關(guān)系模塊,可以有效地利用和集成多級的點(diǎn)云特征,包括點(diǎn)自注意力內(nèi)核和關(guān)鍵點(diǎn)選擇內(nèi)核單元。Zamorski等人(2020)提出了3種生成建模方法的應(yīng)用,并定量和定性地測試了自動(dòng)編碼器、變分自動(dòng)編碼器和對抗性自動(dòng)編碼器的架構(gòu)特點(diǎn)。
3.3 真實(shí)掃描點(diǎn)云跨域補(bǔ)全
目前主流點(diǎn)云補(bǔ)全網(wǎng)絡(luò)依賴于成對的數(shù)據(jù)監(jiān)督,即對每一個(gè)殘缺的點(diǎn)云掃描需要一個(gè)相應(yīng)的完整點(diǎn)云。成對數(shù)據(jù)通過掃描虛擬三維物體很容易獲得,但在現(xiàn)實(shí)世界中難以獲取,且由于虛擬與現(xiàn)實(shí)域間的數(shù)據(jù)分布差異,使用虛擬成對數(shù)據(jù)訓(xùn)練的補(bǔ)全網(wǎng)絡(luò)難以推廣到真實(shí)數(shù)據(jù)。因此,真實(shí)掃描的點(diǎn)云跨域補(bǔ)全成為一個(gè)新的研究熱點(diǎn)。
3.3.1 基于生成對抗模型的跨域補(bǔ)全
Chen等人(2020)首先提出在不需要成對數(shù)據(jù)的情況下以無監(jiān)督方式進(jìn)行點(diǎn)云補(bǔ)全,該方法訓(xùn)練兩個(gè)獨(dú)立的自動(dòng)編碼器,分別用于重建虛擬完整點(diǎn)云和真實(shí)殘缺點(diǎn)云,并訓(xùn)練生成器將殘缺點(diǎn)云的潛在空間映射到完整點(diǎn)云潛在空間,同時(shí)引入判別器約束目標(biāo)樣本的潛變量與源樣本的分布相同。Wen等人(2021)設(shè)計(jì)了殘缺輸入和完整點(diǎn)云的潛碼之間的雙向循環(huán)轉(zhuǎn)換框架。正向循環(huán)將點(diǎn)云從殘缺域轉(zhuǎn)換到完整域,然后再將其投射回殘缺域。該循環(huán)學(xué)習(xí)完整點(diǎn)云的幾何特征,并保持完整預(yù)測和殘缺輸入點(diǎn)云之間的形狀一致性。反向循環(huán)轉(zhuǎn)換從完整域轉(zhuǎn)換到殘缺域,然后投射回完整域來學(xué)習(xí)殘缺點(diǎn)云的特征。由于神經(jīng)網(wǎng)絡(luò)無法將單個(gè)完整點(diǎn)云表示映射為多個(gè)殘缺點(diǎn)云表示(目標(biāo)混淆問題),故提出缺失區(qū)域編碼以表達(dá)目標(biāo)殘缺點(diǎn)云信息,原始?xì)埲秉c(diǎn)云的編碼表示分解為相應(yīng)完整點(diǎn)云的表示和缺失區(qū)域表示。當(dāng)從殘缺點(diǎn)云預(yù)測完整點(diǎn)云時(shí),只需考慮完整點(diǎn)云表示的部分;而當(dāng)從完整點(diǎn)云中預(yù)測殘缺點(diǎn)云時(shí),則需同時(shí)考慮兩個(gè)編碼表示。該框架不足之處在于雙向循環(huán)過程需各自單獨(dú)建模,尤其完全到殘缺的映射過程難以學(xué)習(xí)。如果一個(gè)方向沒有學(xué)好,另一個(gè)方向也會(huì)受到性能制約。
Zhang等人(2021a)首次在點(diǎn)云補(bǔ)全任務(wù)中引入GAN逆映射。利用在完整點(diǎn)云上預(yù)訓(xùn)練GAN得到的點(diǎn)云形狀先驗(yàn),通過GAN逆映射尋找最佳匹配的潛碼。具體而言,一個(gè)潛碼通過預(yù)訓(xùn)練GAN生成一個(gè)完整點(diǎn)云,再通過一個(gè)三維降采樣模塊將完整點(diǎn)云轉(zhuǎn)化為殘缺點(diǎn)云,進(jìn)而與輸入殘缺點(diǎn)云計(jì)算損失。該框架利用梯度下降方法反傳損失以更新潛碼并微調(diào)預(yù)訓(xùn)練的GAN網(wǎng)絡(luò),從而使生成的完整點(diǎn)云與輸入的殘缺點(diǎn)云在可見部分最接近。三維降采樣模塊尋找輸入的殘缺點(diǎn)云與任意生成的完整點(diǎn)云間的對應(yīng)關(guān)系。具體而言,對殘缺點(diǎn)云中每一個(gè)點(diǎn)尋找完整點(diǎn)云中歐氏距離下最近鄰點(diǎn),所有鄰點(diǎn)的并集構(gòu)成了與輸入殘缺點(diǎn)云對應(yīng)的輸出殘缺點(diǎn)云。該方法在保證泛化能力的同時(shí),對殘缺輸入的不確定性可提供多解,并且保證各解都合理地反映殘缺物體的可見部分。且由于GAN的引入,該框架能夠很好地實(shí)現(xiàn)對已知點(diǎn)云形狀的編輯。然而,與基于學(xué)習(xí)的方法相比,這種基于GAN逆映射反轉(zhuǎn)優(yōu)化的方式效率極低,且補(bǔ)全性能非常依賴于潛碼的初始值。
3.3.2 基于解耦的跨域補(bǔ)全
Cai等人(2022)提出了一個(gè)統(tǒng)一的結(jié)構(gòu)化潛空間以增強(qiáng)殘缺—完整點(diǎn)云的幾何一致性,并提高補(bǔ)全精度。該方法將殘缺點(diǎn)云表示解耦為完整形狀因子和遮擋因子。兩者逐元素乘積用以重建殘缺點(diǎn)云,補(bǔ)全過程僅使用完整形狀因子。為學(xué)習(xí)該結(jié)構(gòu)化潛空間提出了一系列約束條件,包括結(jié)構(gòu)化排名正則、潛碼交換以及潛碼分布監(jiān)督。具體而言,對某輸入殘缺點(diǎn)云進(jìn)行下采樣得到一系列殘缺點(diǎn)云,該系列點(diǎn)云完整形狀因子相同,遮擋因子滿足不等式關(guān)系。同時(shí),該方法引入潛碼判別器使得從殘缺點(diǎn)云學(xué)習(xí)得到的完整形狀因子與從完整點(diǎn)云學(xué)習(xí)得到的完整形狀因子相匹配。
Gong等人(2022)結(jié)合回歸與優(yōu)化兩個(gè)階段提高補(bǔ)全點(diǎn)云與輸入殘缺點(diǎn)云間的一致性,加速模型推理速度。第1階段特征解耦進(jìn)行域級別的對齊,殘缺點(diǎn)云特征被解耦為域、形狀和遮擋3個(gè)因子。其中,殘缺點(diǎn)云的遮擋因子與觀察視角強(qiáng)相關(guān),故設(shè)計(jì)自監(jiān)督視點(diǎn)預(yù)測任務(wù)以學(xué)習(xí)遮擋因子;域因子與形狀因子分別代表域風(fēng)格與點(diǎn)云形狀,故使用域判別器結(jié)合梯度反轉(zhuǎn)同時(shí)訓(xùn)練域因子與形狀因子;設(shè)計(jì)因子排列一致性正則以確保因子間相互獨(dú)立,隨機(jī)交換樣本間因子用以重建特征并約束重建特征一致。第2階段推理優(yōu)化過程進(jìn)行實(shí)例級別的對齊,第1階段預(yù)訓(xùn)練編碼器產(chǎn)生的潛碼并不直接生成點(diǎn)云,而只是作為解碼器的初始輸入。使用輸入殘缺點(diǎn)云與預(yù)測完整點(diǎn)云間的距離作為監(jiān)督,在多輪迭代中微調(diào)潛碼以尋找最佳點(diǎn)云生成效果。
04國內(nèi)研究進(jìn)展
4.1 三維特征提取方式與旋轉(zhuǎn)不變性
三維特征提取在近幾年取得了飛速發(fā)展,國內(nèi)對于點(diǎn)云特征提取的研究也產(chǎn)出了優(yōu)秀的成果。
Li等人(2018b)提出了PointCNN,設(shè)計(jì)了χ-卷積初步實(shí)現(xiàn)對離散點(diǎn)集進(jìn)行卷積操作,為之后點(diǎn)云卷積的發(fā)展鋪下了良好的基石。Liu等人(2019b)提出形狀關(guān)系卷積神經(jīng)網(wǎng)絡(luò)(RSCNN),利用點(diǎn)云幾何形狀的特征生成對應(yīng)卷積核的權(quán)重來實(shí)現(xiàn)點(diǎn)云卷積,帶來了顯著的效果提升。
Yan等人(2020)設(shè)計(jì)了點(diǎn)適應(yīng)性采樣與局部非局部模塊(PointASNL),在點(diǎn)云卷積神經(jīng)網(wǎng)絡(luò)中引入注意力機(jī)制。PointASNL利用注意力機(jī)制提出自適應(yīng)采樣,使得降采樣點(diǎn)具有偏移能力,從而提升其代表能力。同時(shí),引入局部與非局部模塊提升不同局部模塊之間的關(guān)聯(lián)程度,提升特征的全局表達(dá)能力。
馬利莊團(tuán)隊(duì)(Liu等,2022)提出了ScatterNet(scatter network),利用散布探索模塊代替?zhèn)鹘y(tǒng)的最近鄰搜索和球形搜索算法,實(shí)現(xiàn)更長、更廣范圍的局部鄰域點(diǎn)組合,使卷積操作能夠從更詳細(xì)的局部幾何信息中提取特征。
Guo等人(2021)以及Zhao等人(2021)率先在點(diǎn)云上拓展了Transformer框架。前者利用自注意力機(jī)制通過挖掘輸入點(diǎn)云整體點(diǎn)之間的關(guān)聯(lián)度來提取逐點(diǎn)的特征。但是全局的方式會(huì)占用大量的內(nèi)存資源,導(dǎo)致無法適用于大規(guī)模的場景點(diǎn)云特征提取任務(wù)。后者則將自注意力機(jī)制運(yùn)用到局部點(diǎn)云上,并在不同局部幾何上復(fù)用自注意力模塊。該方式有效減少了計(jì)算資源的浪費(fèi),并且使得點(diǎn)云Transformer達(dá)到相當(dāng)?shù)男Чu等人(2022)在Point Transformer v1(2021)的基礎(chǔ)上拓展了Point Transformer v2。PTv2提出了分組向量注意力機(jī)制,改善了深度模型過擬合等問題,使得點(diǎn)云Transformer模型也可以部署足夠深度的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
針對點(diǎn)云旋轉(zhuǎn)不變特征提取,國內(nèi)也展開了研究。Chen等人(2019)提出ClusterNet,利用局部鄰域中點(diǎn)之間的相對角度和相對距離代替坐標(biāo)作為神經(jīng)網(wǎng)絡(luò)的輸入來提取點(diǎn)云的特征。由于旋轉(zhuǎn)變換是剛體變換,不會(huì)改變點(diǎn)云局部的幾何結(jié)構(gòu)。相對距離和相對角度作為局部幾何的一種衡量標(biāo)準(zhǔn)可以作為低層的旋轉(zhuǎn)不變特征。因此,ClusterNet能夠進(jìn)一步將低層特征提取為高層的旋轉(zhuǎn)不變特征。You等人(2020)提出逐點(diǎn)旋轉(zhuǎn)不變網(wǎng)絡(luò)(PRIN)算法以及稀疏逐點(diǎn)旋轉(zhuǎn)不變網(wǎng)絡(luò)(Sparse PRIN,SPRIN)算法(You等,2022)來提取點(diǎn)云旋轉(zhuǎn)不變特征。PRIN將旋轉(zhuǎn)空間劃分為離散的球形體素,并利用球形體素卷積提取逐點(diǎn)的旋轉(zhuǎn)不變特征。Yu等人(2020)設(shè)計(jì)PR-invNet,利用PCA初步計(jì)算一種輸入點(diǎn)云的參考系,并在此基礎(chǔ)上用固定角度的旋轉(zhuǎn)增強(qiáng)來構(gòu)建旋轉(zhuǎn)空間。PR-invNet借助提出的姿態(tài)選擇器從旋轉(zhuǎn)空間中挑選輸入點(diǎn)云的標(biāo)準(zhǔn)姿態(tài)后,將其作為神經(jīng)網(wǎng)絡(luò)的輸入,從而提取旋轉(zhuǎn)不變特征。Zhao等人(2022a)同樣借助局部相對信息,提出局部全局表征網(wǎng)絡(luò)(LGR-Net),利用更精細(xì)的8維相對距離角度特征來代替坐標(biāo)輸入,在實(shí)現(xiàn)旋轉(zhuǎn)不變特征提取的同時(shí),提升了實(shí)驗(yàn)結(jié)果。
4.2 場景點(diǎn)云語義分割
點(diǎn)云場景分割在三維視覺感知中具有關(guān)鍵作用。目前國內(nèi)點(diǎn)云場景理分割的相關(guān)技術(shù)在快速發(fā)展,在多個(gè)子方向與賽道上均有許多出色研究工作涌現(xiàn)。其中,馬利莊團(tuán)隊(duì)在全監(jiān)督和弱監(jiān)督點(diǎn)云場景分割任務(wù)上有重要研究進(jìn)展。
點(diǎn)云場景中對物體邊緣的識(shí)別能力對分割效果有著重要影響。基于此,馬利莊團(tuán)隊(duì)(Gong等,2021b)提出邊緣預(yù)測模塊(boundry prediction module)對不同類別物體的邊緣進(jìn)行預(yù)測。其中,邊緣預(yù)測模塊預(yù)測結(jié)果如圖1所示。同時(shí),提出邊緣感知的幾何特征編碼模塊(boundary-aware geometry encoding module)從局部區(qū)域里挖掘邊緣敏感的幾何特征。相比現(xiàn)有的基于點(diǎn)特征的表征方式PointNet++(Qi等,2017b)和PointCNN(Li等,2018b)、基于圖卷積表征的方法分割圖卷積網(wǎng)絡(luò)(graph convolution network for segmentation,SegGCN)算法(Lei等,2020)以及基于注意力機(jī)制的表征方式點(diǎn)注意力轉(zhuǎn)化器(point attention transformer,PAT)算法(Yang等,2019b)等多種現(xiàn)有分割方法,均得到了顯著的分割精度提升。

圖1 ScanNet場景邊緣預(yù)測結(jié)果(Gong等,2021b)
面向場景點(diǎn)云分割中的細(xì)粒度學(xué)習(xí)與因果推理,馬利莊團(tuán)隊(duì)(Gong等,2021a)首次提出一種層次化場景感受野成分推理模塊,將場景分割問題轉(zhuǎn)化成多種類別所在的子區(qū)域感受野成分分解問題。基于感受野的子區(qū)域成分編碼(receptive field component code)很好地刻畫了區(qū)域語義類別信息,將不同層次的感受野成分編碼從粗粒度向細(xì)粒度分解,最后得到逐點(diǎn)的語義類別推理結(jié)果。此外,在網(wǎng)絡(luò)訓(xùn)練階段亦可對全層次的中間層編碼進(jìn)行多尺度監(jiān)督。相關(guān)研究成果(Gong等,2021a)在室內(nèi)點(diǎn)云數(shù)據(jù)集S3DIS和室外點(diǎn)云數(shù)據(jù)集Semantic3D上均取得領(lǐng)先的分割效果。劉盛等人(2021)設(shè)計(jì)了空間深度殘差網(wǎng)絡(luò)(spatial depthwise residual network,SDRNet),結(jié)合空間深度卷積與殘差結(jié)構(gòu)以及擴(kuò)張?zhí)卣髡夏K有效減少了計(jì)算量,保持較快的分割速率。
在弱監(jiān)督點(diǎn)云分割中,馬利莊團(tuán)隊(duì)提出一種混合對比學(xué)習(xí)正則化約束的增強(qiáng)方法(Li等,2022a)。現(xiàn)有基于對比學(xué)習(xí)的弱監(jiān)督點(diǎn)云分割方法通過對真實(shí)點(diǎn)云做數(shù)據(jù)增強(qiáng)(如隨機(jī)旋轉(zhuǎn)、隨機(jī)翻轉(zhuǎn)等)形成參照樣本,通過構(gòu)建原始點(diǎn)云和參照樣本之間的正負(fù)樣本對,從而使用對比損失函數(shù)訓(xùn)練。此外,該方法進(jìn)一步考慮點(diǎn)與其近鄰區(qū)域間語義類別應(yīng)具有局部連續(xù)性的特點(diǎn),結(jié)合偽標(biāo)簽和一致性約束的相關(guān)技術(shù),提出一種混合對比學(xué)習(xí)的網(wǎng)絡(luò)結(jié)構(gòu),如圖2所示。在局部區(qū)域里,每個(gè)視角的點(diǎn)云與另一視角下的鄰域空間滿足一致性約束;在全局層次里,每個(gè)視角的預(yù)測結(jié)果與另一視角下的全局類原型特征通過對比學(xué)習(xí)建立約束。在S3DIS數(shù)據(jù)集上成功實(shí)現(xiàn)每幀點(diǎn)云場景只使用0.03%標(biāo)注獲得的分割精度為全監(jiān)督方法的78.3%左右。
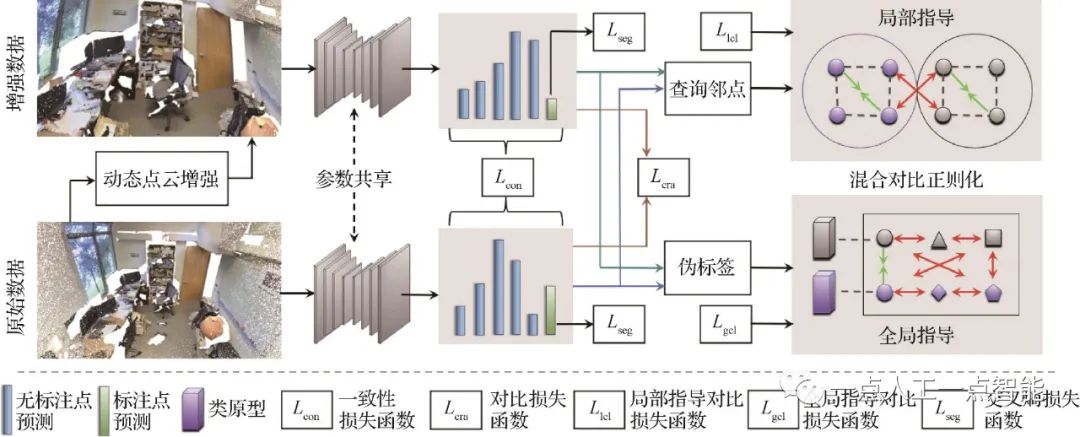
圖2 混合對比學(xué)習(xí)正則化約束的增強(qiáng)方法框架(Li等,2022a)
4.3 場景點(diǎn)云樣例分割與檢測
在場景理解中,3D點(diǎn)云實(shí)例分割是一項(xiàng)具有挑戰(zhàn)性的任務(wù)。相比于語義分割,實(shí)例分割需要對場景內(nèi)的點(diǎn)進(jìn)行更為細(xì)粒度的推理。具體來說,實(shí)例分割除了需要區(qū)分不同語義類別的點(diǎn),還需要進(jìn)一步分離屬于同一語義類別的單獨(dú)實(shí)例。現(xiàn)有的研究方法可以歸納為兩類,即基于Proposal的方法和Proposal-free的方法。
基于Proposal的方法遵循一種自上而下的策略,通過生成一系列的proposal來檢測出每個(gè)實(shí)例,并在每個(gè)proposal內(nèi)分割出實(shí)例掩碼。
Yang等人(2019a)提出3D-BoNet來直接回歸點(diǎn)云中所有實(shí)例的3D邊界框,并同時(shí)預(yù)測出每個(gè)實(shí)例掩碼。對于目標(biāo)proposal的生成,3D邊界框是對物體的一種簡單幾何近似形式。然而,對于大部分物體3D邊界框是不可靠的,因?yàn)?D邊界框不依賴于對目標(biāo)物體幾何形狀的深入理解,導(dǎo)致單個(gè)proposal內(nèi)會(huì)包含多個(gè)對象或僅包含對象的某個(gè)部分。因此,Yi等人(2019)提出了GSPN方法,沒有將目標(biāo)proposal的生成視為一個(gè)直接的邊界框回歸問題,而是采用綜合分析的策略,通過場景內(nèi)的噪音觀察重建形狀以生成優(yōu)質(zhì)的目標(biāo)proposal。
Proposal-free的方法摒棄了對Proposal的依賴,將實(shí)例分割作為語義分割的后續(xù)聚類步驟。
Wang等人(2018b)提出了相似性群提議網(wǎng)絡(luò)(SGPN),以PointNet作為骨干網(wǎng)絡(luò)來提取點(diǎn)的特征,并設(shè)置了相似度矩陣模塊來學(xué)習(xí)所有點(diǎn)對在特征空間上的相似度,從而將相似的點(diǎn)融合為實(shí)例。然而,構(gòu)造點(diǎn)對的相似矩陣需要占用大量內(nèi)存,且相似矩陣存在較多的冗余信息,難以拓展到大規(guī)模的點(diǎn)云數(shù)據(jù)中。
因此,Liu等人(2019a)提出了基于稀疏卷積的多尺度親和度(MASC),該方法首先對點(diǎn)云做體素化處理,并在子流形稀疏卷積的基礎(chǔ)上預(yù)測每個(gè)非空體素的語義得分,同時(shí)生成不同尺度下相鄰體素的親和度,最后根據(jù)語義預(yù)測和親和度大小來生成實(shí)例。除了通過相似度矩陣和親和度來進(jìn)行實(shí)例聚類外,許多現(xiàn)有方法計(jì)算點(diǎn)的中心偏移量,并依據(jù)偏移點(diǎn)之間的空間距離來進(jìn)行實(shí)例分組。
Jiang等人(2020)提出PointGroup方法,在預(yù)測點(diǎn)語義標(biāo)簽的同時(shí)估計(jì)點(diǎn)到對應(yīng)實(shí)例中心的偏移量,并用該偏移量來生成一個(gè)偏移點(diǎn)集。然后,PointGroup在原始點(diǎn)集和偏移點(diǎn)集內(nèi)均進(jìn)行實(shí)例聚類。對于點(diǎn)集內(nèi)的每個(gè)點(diǎn),PointGroup以點(diǎn)的坐標(biāo)作為參考,將點(diǎn)與其鄰近且有著相同語義的點(diǎn)進(jìn)行分組,并漸進(jìn)地?cái)U(kuò)大每個(gè)實(shí)例組。
在PointGroup的基礎(chǔ)上,Chen等人(2021)提出分層聚合的HAIS方法,首先將點(diǎn)聚合至距離閾值較低的點(diǎn)集中,以避免過分割,然后再用動(dòng)態(tài)的距離閾值合并點(diǎn)集以形成完整的實(shí)例。考慮到點(diǎn)集的聚合會(huì)將噪聲點(diǎn)吸收至實(shí)例中,HAIS設(shè)計(jì)了針對實(shí)例內(nèi)部的子網(wǎng)絡(luò),用于去除實(shí)例內(nèi)部的噪點(diǎn)并對實(shí)例掩碼的質(zhì)量進(jìn)行評分。PointGroup和HAIS在區(qū)分前景點(diǎn)和背景點(diǎn)時(shí),均采用了硬語義分割的形式,即一個(gè)點(diǎn)僅被分配單個(gè)語義類別,然而在大多數(shù)情況下,點(diǎn)云物體的局部通常都是模糊的,這使得同一個(gè)物體的不同部分易被預(yù)測為不同的類別,此時(shí)使用硬語義分割的結(jié)果進(jìn)行后續(xù)的實(shí)例聚類將導(dǎo)致語義分割的錯(cuò)誤預(yù)測被傳播至實(shí)例分割結(jié)果。
因此,Vu等人(2022)提出了SoftGroup模型,允許每個(gè)點(diǎn)關(guān)聯(lián)多個(gè)類別,以緩解語義預(yù)測錯(cuò)誤對實(shí)例分割的影響,并將假陽性的實(shí)例預(yù)測視為背景類來進(jìn)一步提高語義分割的性能。
4.4 掃描場景與物體點(diǎn)云補(bǔ)全
4.4.1 全監(jiān)督點(diǎn)云補(bǔ)全
三維點(diǎn)云補(bǔ)全任務(wù)旨在從輸入的殘缺點(diǎn)云中預(yù)測完整的幾何形狀。隨著點(diǎn)云處理方法的快速發(fā)展,全監(jiān)督點(diǎn)云補(bǔ)全任務(wù)不斷取得性能上的提升。
Zhang等人(2020b)提出兩種特征組裝策略進(jìn)行三維點(diǎn)云補(bǔ)全,利用多尺度特征的功能并整合不同的信息來分別表示給定的部分和缺失的部分。同時(shí),借助全局和局部特征聚合和殘差特征聚合來恢復(fù)完整的點(diǎn)云幾何結(jié)構(gòu)。此外,還設(shè)計(jì)了一個(gè)細(xì)化模塊,以防止生成的點(diǎn)云分布不均和異常值。Zhao等人(2021)設(shè)計(jì)了一種缺失點(diǎn)云部分的補(bǔ)全方法,主要強(qiáng)調(diào)兩個(gè)點(diǎn)云非常接近且上下文相關(guān)的配對場景,還設(shè)計(jì)了一個(gè)網(wǎng)絡(luò)來編碼單個(gè)的幾何形狀以及成對場景中不同點(diǎn)云之間的空間關(guān)系,使用不同點(diǎn)云序列之間的一致性損失作為監(jiān)督來訓(xùn)練雙路徑網(wǎng)絡(luò),這種方法可以處理點(diǎn)云之間嚴(yán)重相互遮擋的復(fù)雜情況。
Yu等人(2021b)首先將基于Transformer的編碼器—解碼器網(wǎng)絡(luò)集成到點(diǎn)云完成任務(wù)中,并通過解決集合到集合的轉(zhuǎn)換問題完成殘缺點(diǎn)云的補(bǔ)全。劉心溥等人(2022)提出多尺度的嵌入注意力模塊,通過特征嵌入層與Transformer層提取融合不同尺度特征,優(yōu)化細(xì)節(jié)補(bǔ)全效果。
除此之外,受經(jīng)典幾何建模理論的啟發(fā),馬利莊團(tuán)隊(duì)(Tang等,2022)提出一種創(chuàng)新性的關(guān)鍵點(diǎn)—骨架—形狀的點(diǎn)云補(bǔ)全網(wǎng)絡(luò),利用三維物體的幾何和結(jié)構(gòu)化拓?fù)湫畔磔o助點(diǎn)云完整結(jié)構(gòu)的恢復(fù)。該方法包括關(guān)鍵點(diǎn)定位、骨架生成和形狀細(xì)化3個(gè)步驟,這種遞進(jìn)式的網(wǎng)絡(luò)結(jié)構(gòu)有效提升了點(diǎn)云補(bǔ)全的準(zhǔn)確性和精度。
4.4.2 真實(shí)掃描點(diǎn)云跨域補(bǔ)全
Chen等人(2020)利用兩個(gè)自動(dòng)編碼器來重構(gòu)虛擬完整的點(diǎn)云和真實(shí)的殘缺點(diǎn)云,并使用映射函數(shù)將真實(shí)點(diǎn)云的編碼映射到虛擬完整空間中來補(bǔ)全點(diǎn)云。然后,設(shè)計(jì)了對抗性損失以確保目標(biāo)樣本的映射隱藏編碼與源樣本共享相同的分布。Wen等人(2021)在輸入的潛在空間編碼和完整點(diǎn)云的空間編碼之間設(shè)計(jì)了雙向循環(huán)轉(zhuǎn)換機(jī)制,并引入了從完整分支到殘缺分支的反向映射功能,以進(jìn)一步保持形狀一致性。Cai等人(2022)提出一種統(tǒng)一的結(jié)構(gòu)化網(wǎng)絡(luò),將部分點(diǎn)云解耦為完整的形狀因子和遮擋因子,可以有效提高形狀完成精度,完整形狀因子和遮擋因子兩者逐元素乘積用以重建殘缺點(diǎn)云,補(bǔ)全過程僅使用完整形狀因子,為學(xué)習(xí)該結(jié)構(gòu)化潛空間提出了一系列約束條件,包括結(jié)構(gòu)化排名正則、潛碼交換以及潛碼分布監(jiān)督。馬利莊團(tuán)隊(duì)(Gong等,2022)結(jié)合回歸與優(yōu)化兩個(gè)階段提高補(bǔ)全點(diǎn)云與輸入殘缺點(diǎn)云間的一致性,加速模型推理速度。其中,特征解耦進(jìn)行域級別的對齊,殘缺點(diǎn)云特征被解耦為域、形狀和遮擋3個(gè)因子。殘缺點(diǎn)云的遮擋因子與觀察視角強(qiáng)相關(guān),故設(shè)計(jì)自監(jiān)督視點(diǎn)預(yù)測任務(wù)以學(xué)習(xí)遮擋因子;域因子與形狀因子分別代表域風(fēng)格與點(diǎn)云形狀,故使用域判別器結(jié)合梯度反轉(zhuǎn)同時(shí)訓(xùn)練域因子與形狀因子。
05發(fā)展趨勢與展望
得益于激光雷達(dá)等遠(yuǎn)距離傳感器和結(jié)構(gòu)光等近距離傳感器的發(fā)展,三維點(diǎn)云場景數(shù)據(jù)的獲取變得愈發(fā)便利。相比于2維圖像,點(diǎn)云數(shù)據(jù)受外界光照和成像距離的影響較小,并能夠更為有效地反映三維真實(shí)世界的空間結(jié)構(gòu),呈現(xiàn)出更為豐富的幾何信息、形狀信息和尺度信息。憑借這些優(yōu)勢,三維場景理解與重建技術(shù)能夠使機(jī)器以三維空間的思維來記錄和理解真實(shí)世界,這對于工業(yè)生產(chǎn)自動(dòng)化、城市管理信息化以及生活?yuàn)蕵分悄芑兄匾饬x。三維場景理解與重建系列技術(shù)可廣泛應(yīng)用于場景模型重建、SLAM、機(jī)器人感知、路況分析和歷史文物保護(hù)等場景中。為此,眾多研究聚焦三維點(diǎn)云的場景理解與重建中點(diǎn)云特征提取與匹配融合、場景理解與語義分割以及掃描點(diǎn)云補(bǔ)全等關(guān)鍵問題,取得了一系列重大進(jìn)展。但是,目前仍然存在掃描場景差距大、高精度三維場景計(jì)算開銷大的問題,極大程度影響真實(shí)場景應(yīng)用精度;點(diǎn)云數(shù)據(jù)表征非結(jié)構(gòu)化、真實(shí)物體形態(tài)多種多樣,要求補(bǔ)全方法具有極強(qiáng)的魯棒性和泛化能力;對于三維場景中存在的人物,要求進(jìn)一步探索場景與人物行為之間的聯(lián)系。為進(jìn)一步發(fā)展相關(guān)技術(shù),促進(jìn)落地應(yīng)用,仍需針對室外點(diǎn)云有限標(biāo)注下的分割、大規(guī)模場景形狀與紋理補(bǔ)全以及三維場景下人物行為理解生成等問題進(jìn)行更深層次的探索。
在場景點(diǎn)云分割領(lǐng)域中,雖然現(xiàn)有方法模型已經(jīng)展現(xiàn)出了優(yōu)秀的性能,但依舊存在許多挑戰(zhàn)。例如,在基于激光雷達(dá)掃描的室外場景語義分割中,點(diǎn)云的特征較弱,大多僅包含三維坐標(biāo)和反射強(qiáng)度,加劇了算法區(qū)分點(diǎn)語義類別的難度;在真實(shí)應(yīng)用場景下,不同物體所對應(yīng)的點(diǎn)云規(guī)模差別很大,對模型分割不同尺度的點(diǎn)云物體提出了極高要求;由于點(diǎn)云非結(jié)構(gòu)化的性質(zhì),催生了多視圖、2D/3D投影等多種點(diǎn)云的數(shù)據(jù)表征類型,每種數(shù)據(jù)類別有著各自的優(yōu)勢,但也存在著各式各樣的缺點(diǎn);相比于圖像分割模型,訓(xùn)練點(diǎn)云分割模型需要更大的計(jì)算開銷,對模型訓(xùn)練時(shí)長和硬件資源有著更高的要求。此外,由于分割任務(wù)的定義,對3D點(diǎn)云的數(shù)據(jù)標(biāo)注要求較為嚴(yán)格,需要進(jìn)行逐點(diǎn)的標(biāo)簽標(biāo)注,然而3D點(diǎn)云的標(biāo)注是昂貴、費(fèi)力且易出錯(cuò)的。因此,在有限標(biāo)簽數(shù)據(jù)的條件下,研究快速且精準(zhǔn)的點(diǎn)云分割算法和框架是該領(lǐng)域的研究重點(diǎn)。
在場景重建領(lǐng)域,隨著人工智能技術(shù)的發(fā)展,場景重建的真實(shí)還原度和紋理細(xì)節(jié)方面得到了明顯的提升,但在基于圖像視頻的場景重建、大規(guī)模場景點(diǎn)云補(bǔ)全等任務(wù)內(nèi)還存在許多有待完善的問題。首先,在基于圖像視頻的場景重建中,不同相機(jī)或不同場景條件下的場景深度估計(jì)精度難以得到保障,尤其是被遮擋的物體輪廓部分,雖然在圖像中往往占比較小,卻是場景重建的重要線索;當(dāng)針對視頻數(shù)據(jù)進(jìn)行場景重建時(shí),需要關(guān)注如何解決視頻幀數(shù)據(jù)對應(yīng)的問題;對于點(diǎn)云的稠密化,需要解決的不僅是如何從原本稀疏的點(diǎn)云來生成稠密的點(diǎn)云,更重要的是如何保證生成的點(diǎn)能夠均勻且準(zhǔn)確地附著在物體的表面。其次,在大規(guī)模場景點(diǎn)云補(bǔ)全中,需要關(guān)注如何解決大規(guī)模點(diǎn)云場景整體特征提取與物體間信息傳遞的問題;如何解決掃描數(shù)據(jù)中密度差異巨大的問題,以及如何處理大規(guī)模點(diǎn)云中細(xì)粒度特征重建的問題。這些問題都是值得未來研究的重要方向。
在三維場景理解與重建的基礎(chǔ)上,對真實(shí)世界的數(shù)字化建模更要求能夠探索三維場景與人之間的關(guān)系,對場景中人的行為進(jìn)行理解甚至能夠?qū)鼍爸械娜宋镞M(jìn)行模擬和動(dòng)作生成。但點(diǎn)云場景的非結(jié)構(gòu)化表征與人體行為的多樣性都使得人體與場景之間的關(guān)聯(lián)很難通過簡單的顯式表達(dá)式進(jìn)行定義。因此,在基于場景的人物行為理解與生成中,如何更好地建模三維點(diǎn)云場景與人物行為之間的關(guān)聯(lián)性和一致性;如何在三維場景下生成人物長時(shí)間且真實(shí)的行為動(dòng)作;在保證生成的人物行為在3D場景中是自然且合理的同時(shí)如何提升動(dòng)作合成的效率以實(shí)現(xiàn)分鐘級別的動(dòng)作生成速度等仍需要后續(xù)的工作進(jìn)行進(jìn)一步探索。
綜上所述,基于三維點(diǎn)云的場景理解與重建的相關(guān)技術(shù)面臨著許多亟待解決的問題和挑戰(zhàn)。
在未來,場景點(diǎn)云語義分割的研究應(yīng)當(dāng)綜合考慮3D真實(shí)物理世界在不同視角下的映射,并設(shè)計(jì)對硬件資源更為友好的算法框架;場景重建領(lǐng)域的研究重心應(yīng)在于重建出細(xì)致化且更為真實(shí)的大規(guī)模場景;對于三維場景和人的關(guān)系,重心在于理解和遵循兩者之間存在的規(guī)律,建模人與三維場景之間更為精細(xì)化的聯(lián)系,以及探索快速生成自然且合理的人物行為的模型。毫無疑問的是,三維點(diǎn)云的場景理解與重建對國民日常生活、工業(yè)生產(chǎn)和國防建設(shè)有著巨大的經(jīng)濟(jì)和社會(huì)價(jià)值。
期待點(diǎn)云特征提取、場景點(diǎn)云分割和掃描點(diǎn)云補(bǔ)全等相關(guān)領(lǐng)域得到進(jìn)一步發(fā)展,在數(shù)據(jù)集建設(shè)、模型計(jì)算優(yōu)化以及魯棒性和可解釋性上取得更大的前進(jìn),為實(shí)現(xiàn)自動(dòng)駕駛、數(shù)字工廠和智慧城市等方面提供持續(xù)且可靠的動(dòng)力。
-
三維
+關(guān)注
關(guān)注
1文章
518瀏覽量
29456 -
數(shù)字化
+關(guān)注
關(guān)注
8文章
9480瀏覽量
63428 -
點(diǎn)云
+關(guān)注
關(guān)注
0文章
58瀏覽量
3951
原文標(biāo)題:三萬字收藏 | 三維場景點(diǎn)云理解與重建技術(shù)
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
三維快速建模技術(shù)與三維掃描建模的應(yīng)用
怎樣去設(shè)計(jì)一種基于RGB-D相機(jī)的三維重建無序抓取系統(tǒng)?
如何去開發(fā)一款基于RGB-D相機(jī)與機(jī)械臂的三維重建無序抓取系統(tǒng)
無人機(jī)三維建模的信息
基于FPGA的醫(yī)學(xué)圖像三維重建系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
基于非量測相片的三維模型重建
如何使用單目視覺進(jìn)行高精度三維場景重建技術(shù)研究
深度學(xué)習(xí)背景下的圖像三維重建技術(shù)進(jìn)展綜述
如何使用純格雷碼進(jìn)行三維重建?
基于NeRF的三維場景重建和理解
NerfingMVS:引導(dǎo)優(yōu)化神經(jīng)輻射場實(shí)現(xiàn)室內(nèi)多視角三維重建
三維重建:從入門到入土
如何實(shí)現(xiàn)整個(gè)三維重建過程
基于光學(xué)成像的物體三維重建技術(shù)研究





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論