 GPT時代醫學AI新賽道:16萬張圖片、70萬問答對的臨床問答數據集MIMIC-Diff-VQA發布
GPT時代醫學AI新賽道:16萬張圖片、70萬問答對的臨床問答數據集MIMIC-Diff-VQA發布

大模型想打開應用前景,要從數據集入手。
胸部 X 光片圖像作為臨床診斷最常用的手段之一,是計算機與醫學結合的一個重要領域。其豐富的視覺和病例報告文本信息促進了 vision-language 在醫學領域發展。醫學 VQA 是其中的一個重要方向,近年來比較著名的 ImageCLEF-VQA-Med,和 VQA-RAD 數據集包含了許多了胸部 X 光片問答對。
然而,盡管 X 胸片檢查報告中包含大量臨床信息,現有醫學 VQA 任務的問題種類和數量有限,在臨床方面的貢獻也相對有限。例如,ImageCLEF-VQA-Med 對于胸部 X 光片模態只有兩種問題,“這張圖片里是否有異常?”,以及 “這張圖片里最主要的異常是什么?”,VQA-RAD 的問題種類雖然更豐富,但是卻只含有 315 張圖片。
在今年的 KDD2023 上,來自德州大學阿靈頓分校,NIH 以及日本理化學研究所,東京大學,國立癌癥研究中心的研究人員和放射科醫生,聯合設計了一個服務臨床診斷的大型 VQA 數據集,MIMIC-Diff-VQA。

論文地址:
https://arxiv.org/abs/2307.11986
該數據基于放射科胸片報告,設計了種類更加豐富,內容更加準確的具有邏輯遞進的問答對,涵蓋 7 種不同的問題類型。
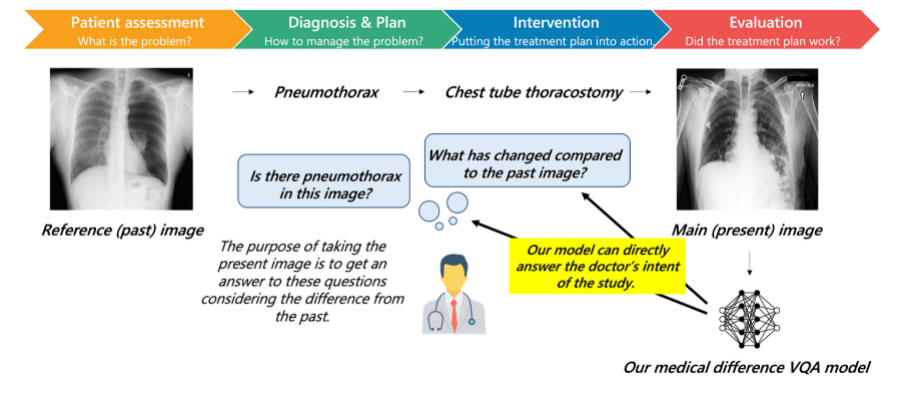
圖 1:臨床的診斷過程,醫生通過比較病程前后圖像的差異做出判斷
該研究同時提出了一個全新任務,圖像對比 VQA (difference VQA):給定兩張圖片,回答關于這兩張圖片差異性的問題。在醫學領域,這個任務直接反映了放射科醫生的需求。在臨床實踐中,如圖 1 所示,醫生經常需要對比回看病人之前的醫學影像,評估病灶變化情況并以評價診療過程。因此 Difference VQA 提出的問題包括” 這張圖片與過去的圖片相比有什么變化?”, “疾病的嚴重程度是否有減輕?” 本次公布的數據集包含 16 萬張圖片和 70 萬問題,這大大刷新了此前的醫學 VQA 數據集的大小記錄。基于該數據集,本文同時也提供了一個利用 GNN 的 VQA 方法作為 basline。為了解決臨床放射科圖片中病人姿態差異的問題,該研究使用 Faster R-CNN 提取器官的特征作為圖的節點,通過整合隱含關系、空間關系和語義關系三種圖網絡關系來融合了醫學專家的知識。其中空間關系是指各個器官之間的位置關系,語義關系包括解剖學和疾病關系知識圖,隱含關系通過全連接關系作為前兩者的補充。這些節點間的關系被嵌入到圖網絡的邊中,并通過 ReGAT (Relation-aware graph attention network) 用于對最終圖特征進行計算。研究團隊希望這個數據集能夠促進醫學領域視覺問答技術的發展,特別是為如 GPT-4 等 LLM 真正服務于臨床提供基準,真正成為支持臨床決策和患者教育有用的工具。
一、 目前醫學 Vision Language 發展現狀
醫學 Vision Language 領域對現有醫療數據庫進行了很多探索來訓練深度學習模型。這些數據庫包括,MIMIC-CXR, NIH14 和 CheXpert 等。在這些工作通常分為三類:疾病標簽的直接分類 (圖 2 (b)),醫學報告生成 (圖 2 (c)) 以及視覺問答任務 (圖 2 (d))。疾病標簽分類任務首先通過簡單的 rule-based 工具,例如 NegBio 和 CheXpert,從報告內容中提取生成預先定義的標簽, 隨后對正樣本和負樣本進行分類。報告生成領域的方法繁多,諸如對比學習,Attention 模型,Encoder-Decoder 模型等,核心工作都是將圖片信息轉化為文字來擬合原始的報告。盡管這些任務取得了很多進展,但從具體臨床應用角度來看仍存在局限性。
例如在疾病標簽分類中 (圖 2 (b)) 中,自然語言處理(NLP)規則經常處理不好不確定性和否定項,導致提取的標簽出了不準確。同時,簡單的標簽只提供了單一的異常信息,無法反映臨床疾病的多樣性。報告生成系統 (圖 2 (c)) 通過挖掘圖像中的隱含信息避免這個問題,但是它不能結合臨床情況回答醫生關注的特定問題。例如圖 2 (a) 中,原始放射學報告中排除了多種常見或是醫生較為關注的疾病,但是人工報告生成器很難猜測放射科醫師想要排除哪些疾病。
相比之下,視覺問答(VQA)任務 (圖 2 (c)) 更加可行,因為它可以回答醫生或病人所關注的特定問題,比如在之前提到的例子中,問題可以設定為 “圖像中是否有氣胸 “,而答案無疑是” 沒有 “。然而,現有的 VQA 數據集 ImageCLEF-VQA-Med 僅僅包含少量通用問題,比如” 圖像有什么問題嗎?這張圖像的主要異常是什么?",缺乏多樣性。這樣的問題不僅將 VQA 問題降級為分類問題,而且對臨床提供的幫助信息也有限。雖然 VQA-RAD 涵蓋 11 種問題類型的問題更加多樣,但該數據集僅含有 315 張圖像,無法充分發揮出需要大量數據投喂的深度學習模型的性能。為了填補醫學 Vision Language 領域的這個空缺,該研究充分結合放射科醫生的實踐,提出了這項圖像對比 VQA(difference VQA)任務,并且基于此任務構建了一個大型的 MIMIC-Diff-VQA 數據集。
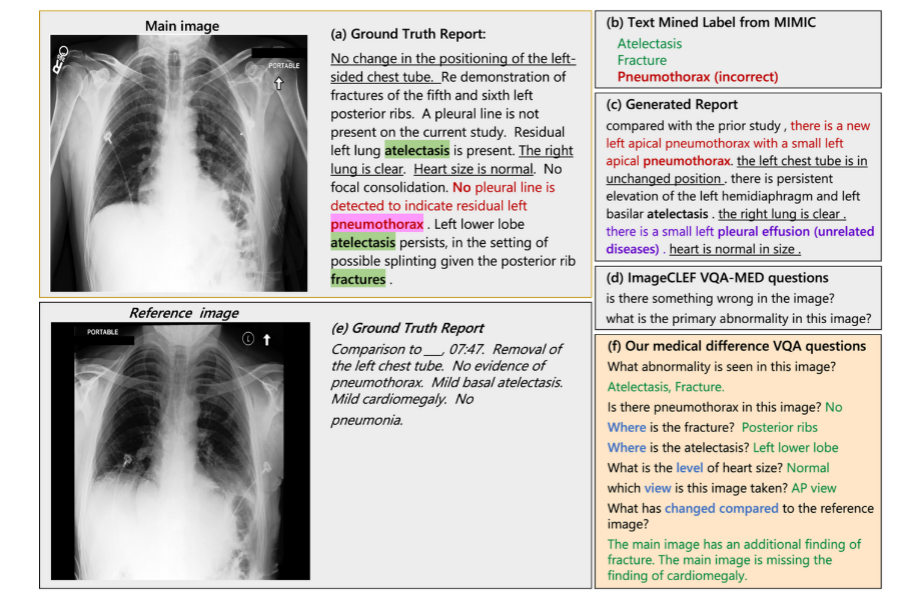
圖 2:目前醫學 Vision Language 各種方法的對比
二、 數據集介紹
MIMIC-Diff-VQA 數據集包括 164,654 張圖片,和 700,703 問題,含蓋 7 種不同的具有臨床意義的問題類型,包括異常,存在,方位,位置,級別,類型,和差異。前六種問題和傳統 VQA 一致,針對于當前圖片提問,只有差異類型問題是針對兩張圖片的問題。各個問題的比例數據和完整問題列表請分別見圖 3 和見表格 1。
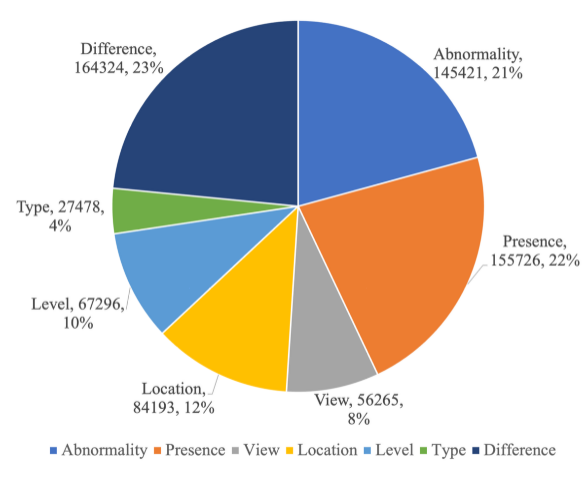
圖 3:MIMIC-Diff-VQA 問題類型的統計數據
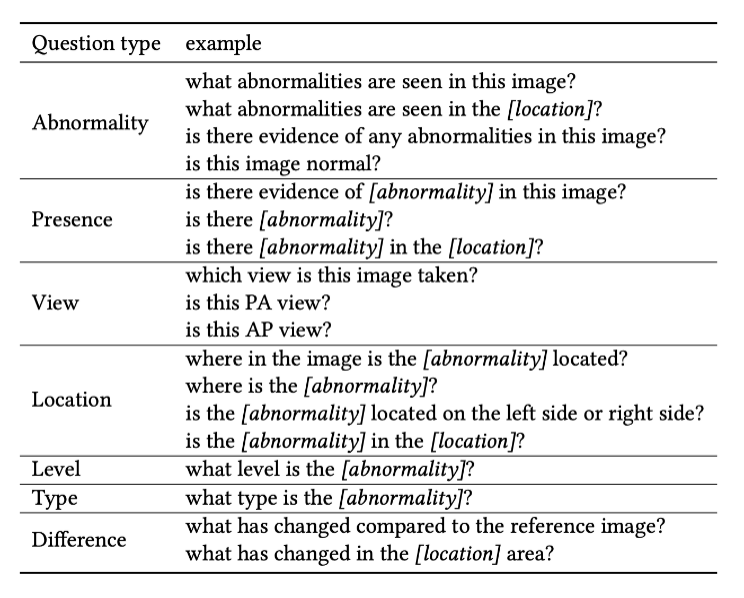
表 1:每種問題類型的問題示例
三、數據集構建
依托于 MIMIC-CXR 提供的海量的胸部 X 光片圖像和文本報告,從 377110 張圖片和 227835 個放射學報告中,該研究在放射科醫生的指導下構建了 MIMIC-Diff-VQA 數據集。
構造 MIMIC-Diff-VQA 數據集的第一步是提取一個 KeyInfo dataset。這個 KeyInfo dataset 包含每個放射學報告中的關鍵信息,比如報告中出現的肯定的異常對象,及其對應的異常名稱、級別、類型、位置,以及否定出現的對象名。提取過程的第一步是根據醫生的意見選取出最常用的異常關鍵詞,和其對應的屬性關鍵詞(級別、類型、位置),之后再設定相應的規則對這些關鍵信息進行提取,同時保留其” 肯定 / 否定 “信息。
為了保證數據集構建的質量,該研究主要遵循 “提取 - 檢查 - 修改” 的步驟,首先通過正則表達式設定的規則對數據庫報告中的關鍵信息進行提取,然后利用手動和自動的方法對提取結果進行檢查,接下來對出現問題的地方進行修改使提取結果更加準確。其中,檢查時使用的自動方法包括:使用 ScispaCy 提取報告中的 entity 名稱,考慮 Part-of-Speech 在句子中的作用,交叉驗證 MIMIC-CXR-JPG 數據集中的 label 提取結果。綜合這些自動化方法和手動驗證篩選,通過 “提取 - 檢查 - 修改” 的步驟,該研究最終完成了 KeyInfo dataset 的構建。
在完成 KeyInfo dataset 的構建之后,該研究便可以在其基礎上設計每一個病人的單次或多次訪問對應的問題和答案,最終構成了 MIMIC-Diff-VQA 數據集。
四、質量保證
為了進一步保證生成數據集的質量,該研究使用三個人工驗證者隨機對總計 1700 個考題和答案進行了人工驗證,如表 2 所示,最終的平均正確率達到了 97.4%。
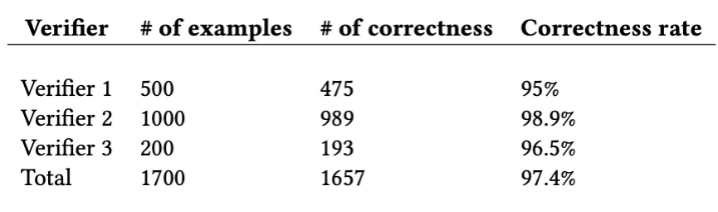
表 2:人工驗證數據集結果
五、Baseline 模型介紹
同時,在提出的數據集基礎上,該研究針對胸部 X 光片和 Difference VQA 任務設計了一個圖網絡模型。如圖 4 所示,考慮拍攝胸部 X 光片的過程中,到同一個病人在不同時間點可能由于身體姿態的不同,拍攝的圖像可能伴隨著大尺度的位移和改變。
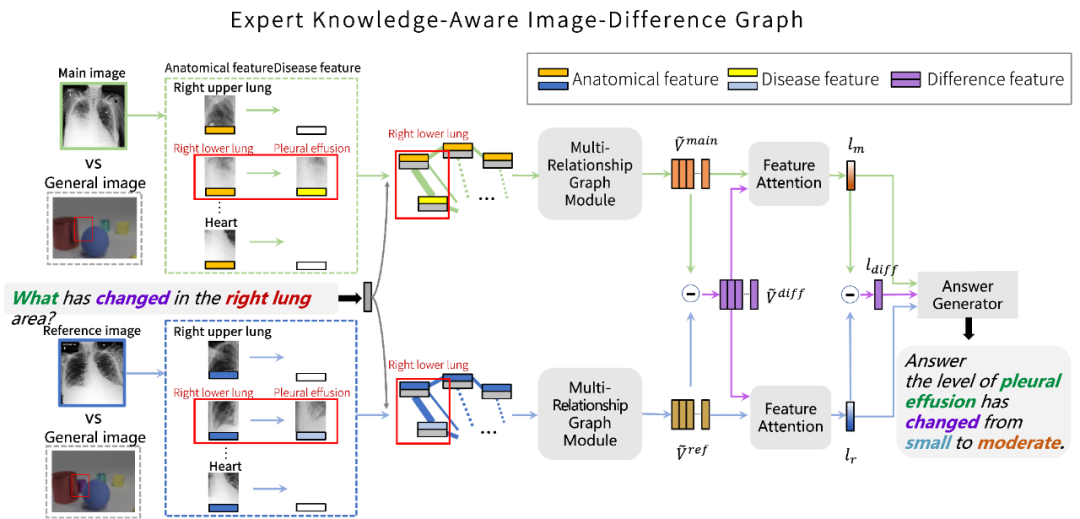
圖 4:該研究提出方法的模型結構
因此,gai通過對輸入的圖片進行解剖學結構定位,并提取對應檢測對象的特征作為圖網絡的節點,以排除病人身體姿態對特征的影響。圖網絡中的每一個節點是一個解剖學結構位置的特征與問題特征的結合。為了充分挖掘圖像中可能包含的病變信息,該研究通過不同的預訓練模型為每一個解剖學結構提取一個純解剖學結構特征和一個疾病特征。
在 “多關系圖網絡模塊” 中,該研究進行了三種不同的圖網絡關系來計算最終的圖網絡特征,包括:隱含關系,空間關系,語義關系。對于隱含關系,使用簡單的全連接以讓模型在潛在關系中發掘有價值的信息。對于空間關系,研究團隊考慮了節點之間 11 種不同的空間關系作為邊,并用 ReGAT (Relation-aware Graph Attention Network) 進行計算。對于語義關系,該研究引入了兩種知識圖譜,即,共現知識圖譜(Co-occurrence Knowledge graph),和解剖學知識圖譜(Anatomical Knowledge graph)。前者考慮不同疾病之間共同出現的概率關系,后者考慮疾病與解剖學之間的關系。
由于該研究在第一步提取了對應的解剖學結構特征和疾病特征,于是便可以將他們嵌入到這兩種知識圖譜當中。與空間關系的圖網絡計算類似,該研究考慮了三種語義關系:共現關系,解剖學關系,無關系,來作為圖網絡的邊,每一種關系用一個數字標簽來進行表征,并使用 ReGAT 進行運算。
最終,三種關系圖網絡計算后的節點特征進行全局平均池化,得到最終圖像對應的圖特征。將兩張圖片的圖特征相減便可得到差異圖特征。對這些特征通過注意力機制得到對應的特征向量,然后將兩張圖片的特征向量和相減后得到的差異特征向量輸入最終的 LSTM 答案生成器,便可得到最終的答案。
該研究將模型與領域內最先進的方法做對比,包括 MMQ (Multiple Meta-model Quantifying), MCCFormers ( Multi-Change Captioning transformers), 和 IDCPCL (Image Difference Captioning with Pre-training and Contrastive Learning)。其中 MMQ 是傳統醫學 VQA 模型,MCCFormers 和 IDCPCL 是差異描述(Difference Captioning)模型。由于 MMQ 無法處理多張圖像,該研究僅在除了 Difference 類問題以外的其他六種問題上將它與所提模型作對比。對于 MCCFormers 和 IDCPCL,由于他們不是 VQA 模型并且必須同時輸入兩張圖片,因此該研究僅在 Difference 類問題上與他們進行對比。對比結果如表 3 和表 4 所示,該模型在 Difference VQA 上顯示出了更優越的性能。
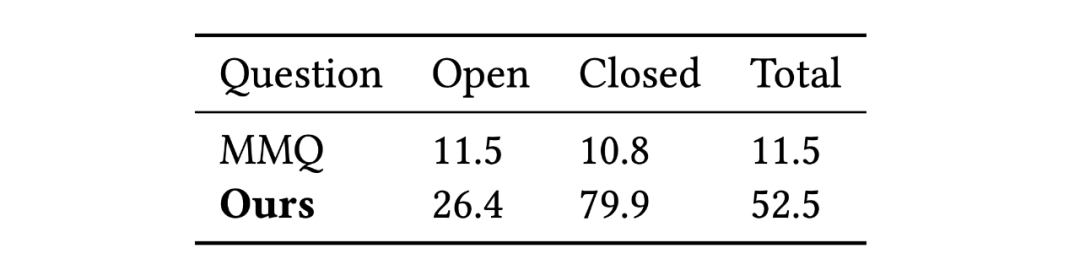
表 3:該研究提出的方法與 MMQ 在 non-difference 類問題上的準確率對比
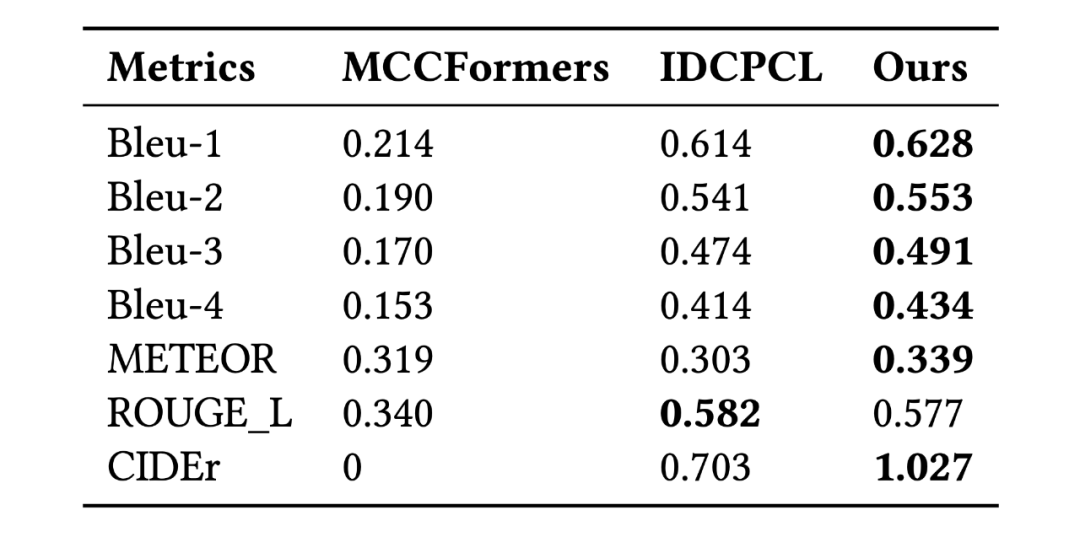
表 4:幾種方法與差異描述方法在 Difference 類問題上的對比
六、總結與討論
該研究提出了一個醫學 Difference VQA 問題,并收集了一個大規模的 MIMIC-Diff-VQA 數據集,以此希望能對推動學界相關技術的發展,同時為醫學界提供有力的支持,包括提供臨床決策輔助和患者教育工具等方面。同時,該研究設計了一個專家知識感知的多關系圖網絡模型來解決這個問題,為學界提供了一個基準模型作為參照。與當前在相關領域最先進的方法的比較表明,該研究所提方法取得了顯著改進。
然而,該研究的數據集和方法仍存在一定的局限性,比如數據集沒有考慮對于特殊情況下同一個病灶出現在多于兩處的情況,以及同義詞的合并也有進一步的提升空間。
此外,所提模型也會產生一些錯誤,包括:
對同一異常的不同呈現方面的混淆,例如肺不張和肺浸潤被互相誤認。
相同類型異常的不同名稱,例如心影增大被錯誤分類為心臟肥大。
用于提取圖像特征的預訓練模型(Faster-RCNN)可能提供不準確的特征,并導致錯誤的預測,例如錯誤地將肺浸潤識別為胸膜積液。
-
模型
+關注
關注
1文章
3517瀏覽量
50392 -
數據集
+關注
關注
4文章
1224瀏覽量
25437 -
大模型
+關注
關注
2文章
3135瀏覽量
4056
原文標題:KDD2023 | GPT時代醫學AI新賽道:16萬張圖片、70萬問答對的臨床問答數據集MIMIC-Diff-VQA發布
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【高手問答】第9期——張工帶你玩轉STM32問答
谷歌重磅發布自然問題數據集
還在愁到哪里找到需要的機器學習數據集嗎?

電容電路應用35個問答,你都能答對嗎資料下載

無監督的多跳問答的可能性研究

全新科學問答數據集ScienceQA讓深度學習模型推理有了思維鏈
問答對話文本數據,構建智能問答對話系統的基礎
問答對話文本數據:解鎖智能問答的未來
自然語言理解問答對話文本數據,賦予計算機智能交流的能力
NVIDIA 知乎精彩問答甄選 | 分享 NVIDIA 助力醫學研究的相關精彩問答





 工商網監
工商網監
評論