") 如何打通機(jī)器學(xué)習(xí)的“三大玄關(guān)”,你該這樣Get新技能!
如何打通機(jī)器學(xué)習(xí)的“三大玄關(guān)”,你該這樣Get新技能!

來源:FPGA之家
隨著時(shí)下智能時(shí)代的發(fā)展,機(jī)器學(xué)習(xí)已成為不少專業(yè)人士的“必備技能”。盡管如此,可它在實(shí)用性上仍然存在一些問題。因而設(shè)計(jì)師們采取了架構(gòu)精簡(jiǎn)、壓縮、以及硬件加速等三種途徑。都有啥特點(diǎn)呢?請(qǐng)往下看~
精簡(jiǎn)架構(gòu)設(shè)計(jì),輸入/輸出的極致簡(jiǎn)化設(shè)計(jì)師減少層數(shù)或網(wǎng)絡(luò)中各層之間連接數(shù)量的任何努力,都會(huì)直接降低推理的內(nèi)存要求和計(jì)算量。因此,我們很難預(yù)測(cè)指定網(wǎng)絡(luò)設(shè)計(jì)在指定問題和訓(xùn)練集上的作用,除非有經(jīng)驗(yàn)可供參考。確定您是否需要特定深度學(xué)習(xí)網(wǎng)絡(luò)設(shè)計(jì)中全部 16 層的唯一方法,是以網(wǎng)絡(luò)的數(shù)層為樣本對(duì)其進(jìn)行訓(xùn)練和測(cè)試。但由于此類探索工作的費(fèi)用較高,設(shè)計(jì)師往往更傾向于使用他們熟悉的網(wǎng)絡(luò)架構(gòu);當(dāng)然,探索也可能有助于節(jié)省大量成本。
讓我們以 ImageNet 當(dāng)前面臨的眾所周知的靜態(tài)圖像分類挑戰(zhàn)為例。深度學(xué)習(xí)網(wǎng)絡(luò)一般從上一層的每個(gè)節(jié)點(diǎn)為自身的每個(gè)節(jié)點(diǎn)獲取加權(quán)輸入,而圖像分類研究人員有了重大發(fā)現(xiàn),即使用卷積神經(jīng)網(wǎng)絡(luò) (CNN) 可以化繁為簡(jiǎn)(圖1)。
在其初層中,CNN 使用較少的卷積引擎替代完全連接的節(jié)點(diǎn)。卷積引擎并不為每項(xiàng)輸入提供權(quán)重,僅具有小型卷積核心。它可使用輸入圖像對(duì)核心進(jìn)行卷積處理,生成特征圖—一種 2D 數(shù)組,表示圖像和圖像各點(diǎn)處核心之間的相似度。然后,特征圖可收到非線性化信息。卷積層的輸出是一個(gè)三維數(shù)組:該層中每個(gè)節(jié)點(diǎn)的 2D 特征圖。然后,該數(shù)組將經(jīng)過池化運(yùn)算降低分辨率,從而縮減 2D 特征圖的大小。
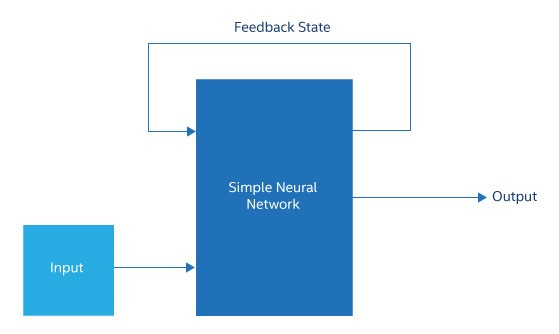
圖1.遞歸神經(jīng)網(wǎng)絡(luò)通常只是將其部分中間狀態(tài)或輸出饋送回輸入的簡(jiǎn)單神經(jīng)網(wǎng)絡(luò)
現(xiàn)代 CNN 可能具有許多卷積層,每個(gè)卷積層跟著一個(gè)池化層。在靠近網(wǎng)絡(luò)輸出端的位置,卷積和池化層終止,其余層是完全連接的。因此,網(wǎng)絡(luò)從輸入端到輸出端逐漸變細(xì),最終形成一個(gè)完全連接的層,其寬度剛好足以為每個(gè)所需的標(biāo)記生成一個(gè)輸出。與具有相似深度的完全連接的深度學(xué)習(xí)網(wǎng)絡(luò)相比,該網(wǎng)絡(luò)能夠大幅減少權(quán)重、連接數(shù)和節(jié)點(diǎn)數(shù)。“壓縮”技術(shù),突破推理的上限機(jī)器學(xué)習(xí)社區(qū)使用壓縮表示與卷積數(shù)據(jù)壓縮截然不同的概念。該語境下的壓縮包含一系列技術(shù),用于減少生成推理所需的計(jì)算數(shù)量并降低其難度,修剪便是此類技術(shù)之一。在進(jìn)行修剪時(shí),深度學(xué)習(xí)網(wǎng)絡(luò)訓(xùn)練通常會(huì)在權(quán)重矩陣中產(chǎn)生多個(gè)零或非常小的數(shù)值。實(shí)際上,這意味著無需計(jì)算將乘以權(quán)重的輸入。因此,表示推理計(jì)算的數(shù)據(jù)流圖表可被剪下一整個(gè)分支。經(jīng)驗(yàn)表明,如果一個(gè)網(wǎng)絡(luò)被修剪后再重新訓(xùn)練,其精度實(shí)際上可以提高。
另一種壓縮方法是減少權(quán)重中的位數(shù)。雖然數(shù)據(jù)中心服務(wù)器可能將所有值保持在單精度浮點(diǎn)中,但研究人員發(fā)現(xiàn),更低的權(quán)重精度和幾個(gè)位足以實(shí)現(xiàn)與 32 位浮點(diǎn)幾乎相同的精度。同樣,在應(yīng)用非線性之后,節(jié)點(diǎn)的輸出可能只需要幾個(gè)位。如果推理模型將在服務(wù)器上執(zhí)行,這幾乎沒有幫助。然而,該方法在一個(gè) MCU 上非常有用,一個(gè)能夠非常有效地實(shí)施 2 位或 3 位乘法器的 FPGA 加速器可以充分利用這種壓縮形式。
總之,在某些情況下,修剪技術(shù)、大幅減少位數(shù)和相關(guān)技術(shù)已經(jīng)被證明可以減少 20 到 50 倍的推理工作。這些技術(shù)可以把經(jīng)過訓(xùn)練的網(wǎng)絡(luò)的推理工作控制在一些邊緣計(jì)算平臺(tái)的范圍內(nèi)。當(dāng)壓縮不足以達(dá)成目的時(shí),設(shè)計(jì)師可以轉(zhuǎn)向硬件加速,而且硬件加速有越來越多的替代方案。
硬件加速的新風(fēng)標(biāo)!推理所需的計(jì)算既不多樣也不復(fù)雜,主要包括許多乘積和 — 乘積累加 (MAC) — 運(yùn)算,用于將輸入乘以權(quán)重和在每個(gè)節(jié)點(diǎn)將結(jié)果相加。該計(jì)算任務(wù)還包括所謂的修正線性單元 (ReLU) — 用于將所有負(fù)值設(shè)置為零 — 等非線性函數(shù)、雙曲正切或 sigmoid 函數(shù) — 用于注入非線性 — 以及用于池化的最大值函數(shù)。總之,該計(jì)算任務(wù)看起來很像一個(gè)典型的線性代數(shù)工作負(fù)載。
應(yīng)用超級(jí)計(jì)算領(lǐng)域的硬件思想。最簡(jiǎn)單的方法是將輸入、權(quán)重和輸出作為向量進(jìn)行組織,并使用內(nèi)置到大型 CPU 中的向量 SIMD 單元。為了提高速度,設(shè)計(jì)師在 GPU 中使用了大量著色引擎。通過在 GPU 的內(nèi)存層次結(jié)構(gòu)中安排輸入、權(quán)重和輸出數(shù)據(jù)避免抖動(dòng)或高缺失率,(絕非無足輕重的小問題,)但這并沒有阻止 GPU 成為數(shù)據(jù)中心深度學(xué)習(xí)領(lǐng)域使用最廣泛的非 CPU 硬件。最近幾代的 GPU 取得了長(zhǎng)足進(jìn)步,增加了更小的數(shù)據(jù)類型和矩陣數(shù)學(xué)塊來補(bǔ)充浮點(diǎn)著色單元,能夠更好地適應(yīng)該應(yīng)用。
這些調(diào)整說明了加速硬件設(shè)計(jì)師使用的基本策略:減少或消除指令獲取和解碼,減少數(shù)據(jù)移動(dòng),盡可能多地使用并行性,以及利用壓縮。難點(diǎn)在于確保這些操作在實(shí)施時(shí)不會(huì)互相干擾。
使用這些策略有幾種架構(gòu)方法:
1、在芯片上對(duì)大量的乘法器、加法器和小型 SRAM 塊進(jìn)行實(shí)例化,并通過片上網(wǎng)絡(luò)將它們鏈接起來。這為執(zhí)行推理提供了原始資源,但存在一個(gè)關(guān)鍵挑戰(zhàn),即從計(jì)算元件中高效獲取數(shù)據(jù),以及將數(shù)據(jù)傳輸至計(jì)算元件及程序員。這些設(shè)計(jì)是過去許多大規(guī)模并行計(jì)算芯片的后繼者,所有這些芯片都遭遇了難以攻克的編程挑戰(zhàn)。
2、Google 張量處理單元(TPU)等芯片采用了進(jìn)一步依托應(yīng)用的方法,按照深層學(xué)習(xí)網(wǎng)絡(luò)的固有結(jié)構(gòu)組織計(jì)算元件。這類架構(gòu)將網(wǎng)絡(luò)的輸入權(quán)重乘法視為非常大的矩陣乘法,并創(chuàng)建硬件矩陣乘法器來執(zhí)行它們。在 TPU 中,乘法是在一個(gè)收縮乘法器數(shù)組中完成的,在這個(gè)數(shù)組中,操作數(shù)自然地從一個(gè)單元流到另一個(gè)單元。數(shù)組被緩沖區(qū)包圍,以饋入激活和權(quán)重值,后面是激活函數(shù)和池化硬件。
通過對(duì)芯片進(jìn)行特定的組織在一定程度上自動(dòng)實(shí)施矩陣運(yùn)算,TPU 可讓程序員免于通過計(jì)算元件和 SRAM 對(duì)數(shù)據(jù)移動(dòng)進(jìn)行精細(xì)安排。編程變得非常簡(jiǎn)單,基本就包括將輸入和權(quán)重分組成矩陣并按下按鈕,但存在一個(gè)問題。如上所述,修剪會(huì)產(chǎn)生非常稀疏的矩陣,簡(jiǎn)單地將這些矩陣饋入像 TPU 一樣的設(shè)備會(huì)導(dǎo)致大量毫無意義的乘法和加法。在模型開發(fā)的壓縮階段,可能需要將這些稀疏矩陣重新排列為更小的密集矩陣,以便充分利用硬件。
3、將推理任務(wù)作為一系列矩陣乘法建模,而非作為數(shù)據(jù)流圖表建模。加速器被設(shè)計(jì)成一個(gè)數(shù)據(jù)流引擎,數(shù)據(jù)從一側(cè)進(jìn)入,通過可配置的鏈接流經(jīng)一個(gè)類似于圖表的處理元件網(wǎng)絡(luò),然后進(jìn)行輸出。這種加速器可以配置為僅執(zhí)行所修剪網(wǎng)絡(luò)需要的操作。
一旦選擇了架構(gòu),接下來的問題就是實(shí)施。在開發(fā)過程中,許多架構(gòu)源于 FPGA,以滿足成本和調(diào)度要求。在一些情況下,一些架構(gòu)將留在 FPGA 中——例如,當(dāng)深度學(xué)習(xí)網(wǎng)絡(luò)模型預(yù)計(jì)會(huì)發(fā)生一個(gè)加速器設(shè)計(jì)無法完全處理的過多改變。但是,如果模型的改變很小,例如層排列有所不同和權(quán)重發(fā)生改變,ASIC 或 CPU 集成加速器可能是首選項(xiàng)。
這又回到了邊緣計(jì)算及其限制的話題。如果機(jī)器學(xué)習(xí)網(wǎng)絡(luò)要在一組服務(wù)器上執(zhí)行,那么在服務(wù)器 CPU、GPU、FPGA 或大型 ASIC 加速器芯片上執(zhí)行都是可行的選擇。但是,如果必須在一個(gè)更為有限的環(huán)境中執(zhí)行,例如車間機(jī)器、無人機(jī)或攝像頭,則需要一個(gè)小型的 FPGA 或 ASIC。
對(duì)于極其有限環(huán)境中的小型深度學(xué)習(xí)模型,例如手機(jī),內(nèi)置于應(yīng)用處理器 SOC 中的低功耗 ASIC 或加速器塊可能是唯一的選擇。盡管到目前為止,這些限制往往會(huì)促使設(shè)計(jì)師努力設(shè)計(jì)簡(jiǎn)單的乘法器數(shù)組,但神經(jīng)形態(tài)設(shè)計(jì)的卓越能效可能會(huì)使它們對(duì)下一代深度嵌入式加速器非常重要。
無論如何,機(jī)器學(xué)習(xí)都不再局限于數(shù)據(jù)中心范疇,推理正邁向邊緣。隨著研究人員不再聚焦當(dāng)前的傳統(tǒng)深度學(xué)習(xí)網(wǎng)絡(luò),將視線投向更多概念,邊緣的機(jī)器學(xué)習(xí)問題有望成為架構(gòu)開發(fā)的前沿課題。
-
芯片
+關(guān)注
關(guān)注
459文章
52329瀏覽量
438281 -
硬件
+關(guān)注
關(guān)注
11文章
3472瀏覽量
67313 -
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7788瀏覽量
90575 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134283 -
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22680
發(fā)布評(píng)論請(qǐng)先 登錄
解鎖BNC插頭拆卸新技能,輕松應(yīng)對(duì)維修難題

獲獎(jiǎng)名單公布!新春有獎(jiǎng)活動(dòng)!金蛇迎春,蛇年大吉,留言分享贏取精美禮品!
選購真空共晶爐也有門道,快來get新技能!

傳統(tǒng)機(jī)器學(xué)習(xí)方法和應(yīng)用指導(dǎo)

如何選擇云原生機(jī)器學(xué)習(xí)平臺(tái)
什么是機(jī)器學(xué)習(xí)?通過機(jī)器學(xué)習(xí)方法能解決哪些問題?

NPU與機(jī)器學(xué)習(xí)算法的關(guān)系
麻省理工學(xué)院推出新型機(jī)器人訓(xùn)練模型
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】+ 鳥瞰這本書
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】+ 簡(jiǎn)單建議
【《時(shí)間序列與機(jī)器學(xué)習(xí)》閱讀體驗(yàn)】+ 了解時(shí)間序列
如何理解機(jī)器學(xué)習(xí)中的訓(xùn)練集、驗(yàn)證集和測(cè)試集
按照這樣學(xué)習(xí)C語言,成為卷王不是夢(mèng)!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論