") 用LLM生成反駁:首先洞察審稿人的心理,再巧妙回應(yīng)!
用LLM生成反駁:首先洞察審稿人的心理,再巧妙回應(yīng)!
在科研領(lǐng)域,同行評審(review-rebuttal)是保證學(xué)術(shù)質(zhì)量的關(guān)鍵環(huán)節(jié)。這一過程中的辯論和反駁非常具有挑戰(zhàn)性。傳統(tǒng)的同行評審生成任務(wù)通常集中在表面層面的推理。研究人員發(fā)現(xiàn),考慮論點(diǎn)背后的態(tài)度根源和主題可以提高反駁的有效性。
今天介紹的這篇研究將心理學(xué)理論與辯論技術(shù)相結(jié)合,為計(jì)算辯論領(lǐng)域帶來了新的視角。具體來說,文章主要做了以下工作:
- 提出了一種全新的同行評審反駁生成任務(wù)——柔道辯論(Jiu-Jitsu Argumentation),結(jié)合態(tài)度根源和主題進(jìn)行辯論。
- 開發(fā)了JITSUPEER數(shù)據(jù)集,包含豐富的態(tài)度根源、主題和典型反駁案例。
- 為同行評審反駁生成提供了強(qiáng)大的基準(zhǔn)線。

Paper: Exploring Jiu-Jitsu Argumentation for Writing Peer Review Rebuttals
Link: https://arxiv.org/pdf/2311.03998.pdf
做一個專門面向年輕NLPer的每周在線論文分享平臺
Jiu-Jitsu Argumentation
同行評審對于確保科學(xué)的高質(zhì)量至關(guān)重要:作者提交研究成果,而審稿人則辯論應(yīng)不應(yīng)該接受其發(fā)表。通常評審后還會有一個反駁階段。在這里,作者有機(jī)會通過反駁論點(diǎn)來說服審稿人提高他們的評估分?jǐn)?shù)。
這篇文章探索了同行評審領(lǐng)域中態(tài)度根源的概念,即在審查科學(xué)論文的標(biāo)準(zhǔn)時,識別審稿人的潛在信仰和觀點(diǎn)。
作者首先定義典型的rebuttal為:一種與潛在態(tài)度根源相一致并解決它們的反駁論點(diǎn)。它足夠通用,可以作為模板用于許多相同(態(tài)度根源-主題)審稿元組的實(shí)例,同時表達(dá)特定的反駁行動。
根據(jù)這個定義,作者提出了態(tài)度根源和主題引導(dǎo)的反駁生成任務(wù):給定一個同行評審論點(diǎn)rev和一個反駁行動a,任務(wù)是根據(jù)rev的態(tài)度根源和主題生成典型反駁c。
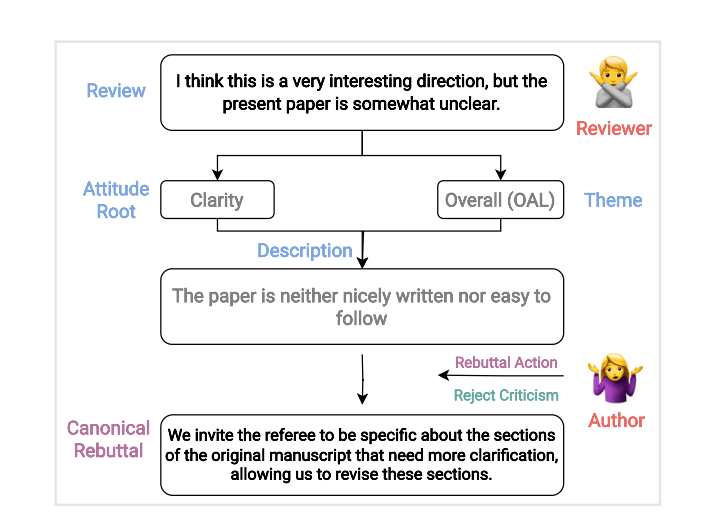
下圖展示了如何通過一系列中間步驟,將審稿內(nèi)容映射到標(biāo)準(zhǔn)的反駁上。這個審稿的主要觀點(diǎn)是關(guān)于清晰度和整體性。
JITSUPEER 數(shù)據(jù)集
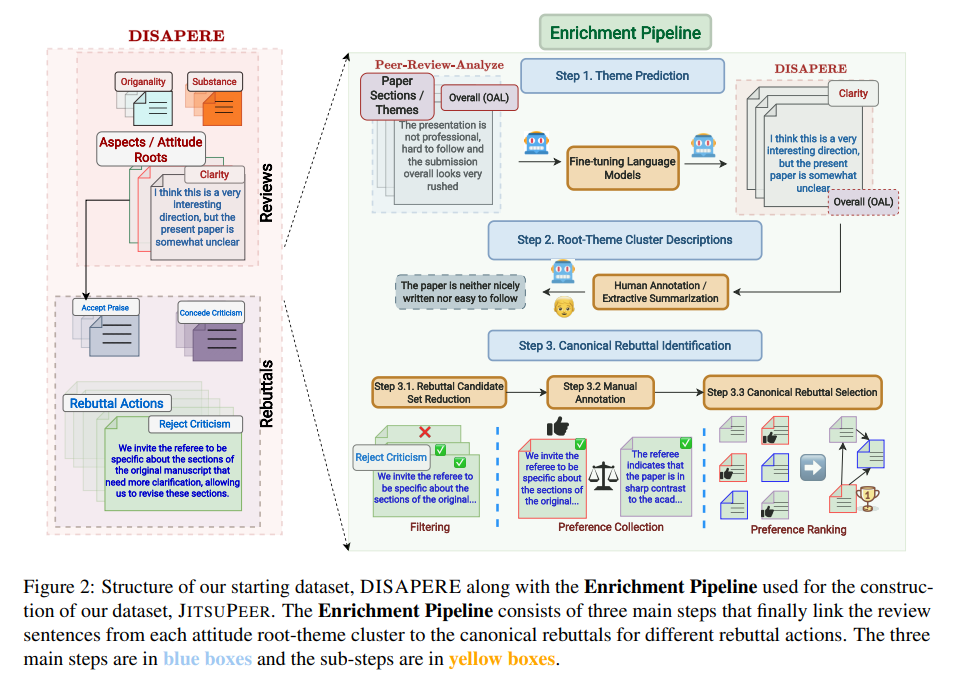
為了評估反駁生成任務(wù),作者構(gòu)建了JITSUPEER數(shù)據(jù)集。該數(shù)據(jù)集專注于同行評審過程中的態(tài)度根源和主題,通過連接這些元素與基于特定反駁行動的典型反駁,實(shí)現(xiàn)了一種態(tài)度和主題引導(dǎo)的反駁生成方法。
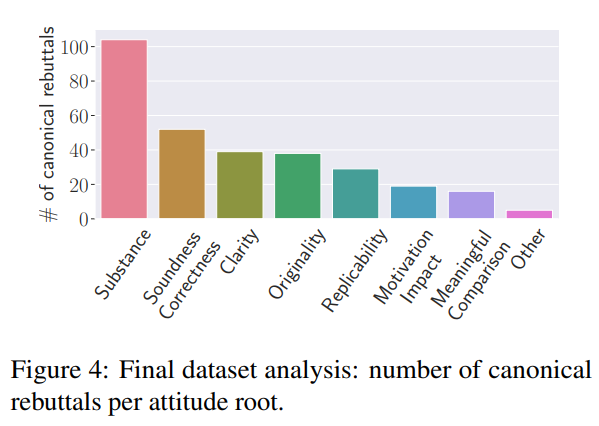
- 態(tài)度根源與主題分布: 大多數(shù)審稿句子的態(tài)度根源是“實(shí)質(zhì)性”(Substance),這也是擁有最多主題(29個)的根源。最常見的主題是方法論(Methodology)、實(shí)驗(yàn)(Experiments)和相關(guān)工作(Related Work)。這一發(fā)現(xiàn)符合直覺,因?yàn)?a target="_blank">機(jī)器學(xué)習(xí)領(lǐng)域的審稿者通常非常關(guān)注方法論的穩(wěn)健性和實(shí)用性。
- 典型反駁識別: 研究團(tuán)隊(duì)為不同的態(tài)度根源和反駁行動識別了302個典型反駁。這些典型反駁可以映射到2,219個審稿句子(總共2,332個)。與“完成任務(wù)”(Task Done)這一反駁行動和“實(shí)質(zhì)性”態(tài)度根源相關(guān)的典型反駁句子數(shù)量最多。
- 典型反駁示例: 在報(bào)告的表格中,研究團(tuán)隊(duì)展示了一些典型反駁的例子。顯然,不同的態(tài)度根源-主題描述與不同的典型反駁相關(guān)聯(lián)。
起始數(shù)據(jù)集
作為JITSUPEER的基礎(chǔ),研究團(tuán)隊(duì)采用了名為DISAPERE的數(shù)據(jù)集,該數(shù)據(jù)集包含了2019年和2020年ICLR會議的審稿和相應(yīng)反駁。這些審稿和反駁被細(xì)致地分解成單個句子,并被三層注釋標(biāo)記,包括審稿方面和極性、審稿與反駁之間的鏈接,以及反駁行動的直接注釋。特別地,研究團(tuán)隊(duì)關(guān)注于需要反駁的負(fù)面審稿句子,探索了審稿方面的使用,以此來體現(xiàn)社區(qū)共享的科學(xué)價值觀。
此外,研究者還使用了另一數(shù)據(jù)集PEER-REVIEW-ANALYZE,該數(shù)據(jù)集是一個基準(zhǔn)資源,包含2018年ICLR的審稿,同樣配備了多層注釋。這些注釋包括了審稿句子所指目標(biāo)論文的特定部分,如方法、問題陳述等,這些信息被視為態(tài)度主題的關(guān)鍵元素。這一研究提供了一個獨(dú)特的視角,通過關(guān)注論文的特定部分,進(jìn)一步豐富了對工作的潛在信仰和主題信息的理解。
數(shù)據(jù)集豐富化
在這項(xiàng)研究中,研究團(tuán)隊(duì)的目標(biāo)是創(chuàng)建一個詳盡的語料庫,其中審稿句子不僅被標(biāo)注為態(tài)度根源和主題,而且還與特定反駁行動的典型反駁句子相連接。為了實(shí)現(xiàn)這一目標(biāo),研究團(tuán)隊(duì)采用了一系列方法來豐富DISAPERE數(shù)據(jù)集。
主題預(yù)測
首先,他們使用了PEER-REVIEW-ANALYZE數(shù)據(jù)集來預(yù)測態(tài)度主題,即審稿句子中所涉及的論文部分。研究團(tuán)隊(duì)測試了不同的模型,包括通用模型和針對同行評審領(lǐng)域的專門模型,如BERT、RoBERTa和SciBERT。他們通過中間層的遮蔽語言模型(MLM)對這些模型進(jìn)行了領(lǐng)域?qū)iT化處理,并在多個配置下進(jìn)行了訓(xùn)練和優(yōu)化。研究團(tuán)隊(duì)在變壓器的頂部添加了sigmoid分類頭,以進(jìn)行微調(diào),并對不同的學(xué)習(xí)率進(jìn)行了網(wǎng)格搜索。他們基于驗(yàn)證性能采用早期停止策略,并在PEER-REVIEW-ANALYZE數(shù)據(jù)集上評估了模型的性能。結(jié)果顯示,所有變壓器模型的性能都顯著優(yōu)于基線模型,其中經(jīng)過領(lǐng)域?qū)iT化處理的SciBERTds_neg模型表現(xiàn)最佳。
根源–主題集群描述
接下來,研究團(tuán)隊(duì)對每個態(tài)度根源–主題集群添加額外的自然語言描述,旨在提供比單純標(biāo)簽元組更豐富的人類可解釋性。他們通過比較自動和手動生成的摘要來完成這一步驟。
摘要生成:在自動摘要方面,研究團(tuán)隊(duì)采用了領(lǐng)域特定的SciBERTds_neg模型對句子進(jìn)行嵌入,并根據(jù)余弦相似度選擇最具代表性的審稿句子。
評估: 研究團(tuán)隊(duì)通過展示摘要和相應(yīng)的集群句子給注釋者,讓他們選擇更好地描述集群的摘要。他們使用INCEpTION開發(fā)了注釋界面,并雇用了額外的計(jì)算機(jī)科學(xué)博士生進(jìn)行標(biāo)注。通過測量注釋者間的一致性,研究團(tuán)隊(duì)確保了摘要的質(zhì)量和準(zhǔn)確性。
確定典型反駁
研究團(tuán)隊(duì)為每個態(tài)度根源-主題集群確定典型的反駁,這是通過考慮特定的反駁行動來完成的。這一過程分為三個步驟:首先,減少候選典型反駁的數(shù)量;其次,手動比較縮減后候選集中的反駁句子對;最后,基于成對比較的分?jǐn)?shù)計(jì)算排名,并選擇排名最高的候選作為典型反駁。
候選集減少:為了縮減典型反駁的候選集,研究團(tuán)隊(duì)采用了兩種適用性分類器得出的分?jǐn)?shù)。首先是一個二元分類器,基于自行訓(xùn)練,用于預(yù)測一個反駁句子作為典型反駁的整體適用性。其次,考慮到典型反駁的原型性質(zhì),他們還使用了SPECIFICITELLER模型來獲得特定性分?jǐn)?shù)。該模型是一個預(yù)訓(xùn)練的基于特征的模型,用來評估句子是通用的還是具體的。通過這兩個步驟,研究團(tuán)隊(duì)最終將候選集縮減至1,845個候選。
手動標(biāo)注:在手動決定典型反駁方面,研究團(tuán)隊(duì)設(shè)計(jì)了一套方法:展示來自特定態(tài)度根源和主題集群的≤5個審稿句子,并將這些信息與特定的反駁行動配對。然后,他們隨機(jī)選擇兩個反駁句子,這些句子與集群中的任一審稿句子相關(guān),并對應(yīng)于所選的反駁行動。標(biāo)注者需要從這對反駁句子中選擇更好的一個。對于每個(態(tài)度根源、態(tài)度主題、反駁行動)三元組的n個反駁句子,成對標(biāo)注設(shè)置需要對n(n ? 1)/2對句子進(jìn)行評判。研究團(tuán)隊(duì)雇傭了兩名計(jì)算機(jī)科學(xué)博士生進(jìn)行這項(xiàng)任務(wù)。
典型反駁選擇:研究團(tuán)隊(duì)基于收集的偏好通過注釋圖排名得出最佳反駁。具體來說,他們?yōu)槊總€根源-主題-行動集群創(chuàng)建了一個有向圖,圖中的節(jié)點(diǎn)是反駁句子。邊的方向基于偏好:如果A優(yōu)于B,則創(chuàng)建A → B的邊。然后,他們使用PageRank算法對節(jié)點(diǎn)進(jìn)行排名,每條邊的權(quán)重為0.5。排名最低的節(jié)點(diǎn),即很少或沒有入邊的節(jié)點(diǎn),被選為典型反駁。這種方法不僅提高了數(shù)據(jù)集的質(zhì)量和實(shí)用性,也為未來在類似領(lǐng)域的研究提供了一個有力的方法論參考。
實(shí)驗(yàn)分析
研究團(tuán)隊(duì)提出了三項(xiàng)新穎的任務(wù),以在其數(shù)據(jù)集上進(jìn)行測試。分別是典型反駁評分,審稿意見生成,典型反駁生成。
典型反駁評分
這個任務(wù)的目標(biāo)是給定一個自然語言描述d和一個反駁行動a,對所有反駁r(與特定態(tài)度根源-主題集群相關(guān))進(jìn)行評分,以表明r作為該集群的典型反駁的適用性。
這個任務(wù)被視為一個回歸問題。只考慮有典型反駁的反駁行動和態(tài)度根源-主題集群的組合(50個態(tài)度根源-主題集群描述,3,986個反駁句子,其中302個是典型反駁)。使用之前的PageRank分?jǐn)?shù)作為模型訓(xùn)練的預(yù)測目標(biāo)。
結(jié)果
-
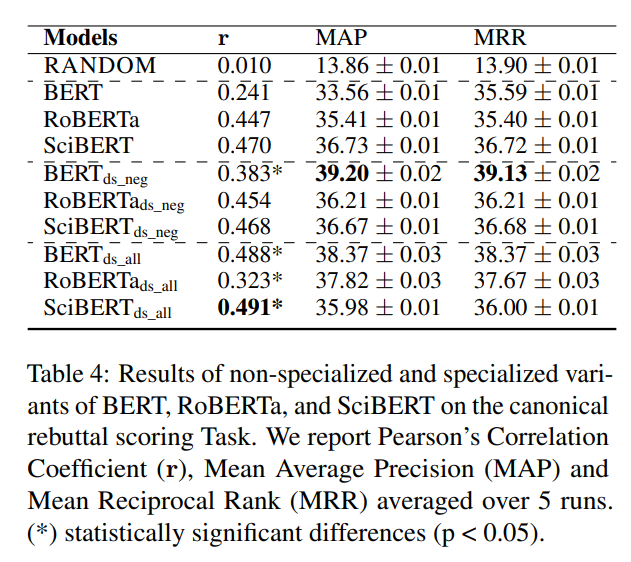
從下表可以看出,大多數(shù)領(lǐng)域?qū)iT化模型的表現(xiàn)優(yōu)于它們的非專門化對應(yīng)模型。
-
SciBERTds_all 在所有方面都有最高的皮爾遜相關(guān)系數(shù),然而,BERTds_neg 在排名分?jǐn)?shù)方面表現(xiàn)最佳。
-
使用其他與集群相關(guān)的信息,如代表性審稿句子,以及對描述進(jìn)行釋義,可能會帶來進(jìn)一步的收益,這將留待未來研究探究。
審稿描述生成
給定一條同行評審句子rev,任務(wù)是生成該句子所屬集群的抽象描述d 。
實(shí)驗(yàn)設(shè)置
- 數(shù)據(jù)集由2,332個審稿句子組成,每個句子都屬于144個集群之一,并且每個集群都有相關(guān)的描述。
- 采用70/10/20的訓(xùn)練-驗(yàn)證-測試分割。
- 使用以下序列到序列(seq2seq)模型:BART (bart-large)、Pegasus (pegasus-large) 和 T5 (t5-large)。
- 對訓(xùn)練周期數(shù)e∈{1, 2, 3, 4, 5}和學(xué)習(xí)率λ∈{1 * 10^-4, 5 * 10^-4, 1 * 10^-5}進(jìn)行網(wǎng)格搜索,批量大小b = 32。
- 使用帶有5個束的束搜索作為解碼策略。
- 在完全微調(diào)設(shè)置以及零次和少次(few-shot)場景中進(jìn)行實(shí)驗(yàn)(隨機(jī)選擇次數(shù))。
- 根據(jù)詞匯重疊和語義相似性(ROUGE-1 (R-1), ROUGE-2 (R-2), ROUGE-L (R-L) 和 BERTscore)報(bào)告性能。
結(jié)果
- R-1分?jǐn)?shù)展示在下圖中,完整結(jié)果在表中。
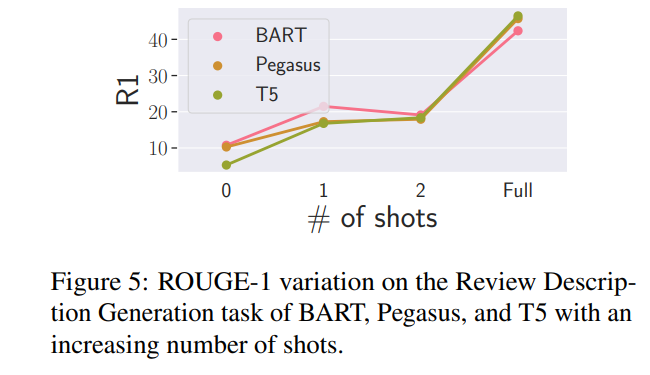
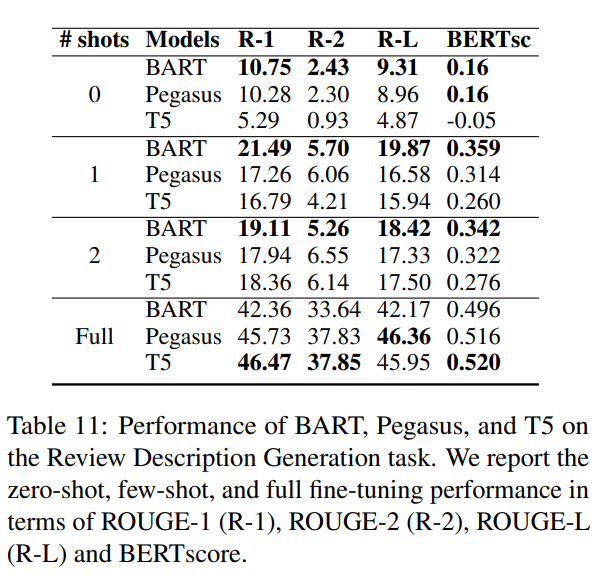
- 有趣的是,所有模型都表現(xiàn)出非常陡峭的學(xué)習(xí)曲線,在僅看到一個例子時,根據(jù)大多數(shù)指標(biāo),性能大致翻了一番。
- 在zero shot和one shot設(shè)置中,BART在所有方面表現(xiàn)出色。
- 但在完全微調(diào)模型時,T5的表現(xiàn)最佳。研究團(tuán)隊(duì)推測這可能與T5更大的容量有關(guān)(BART有406M參數(shù),而T5有770M參數(shù))。
典型反駁生成
給定一條審稿句子rev 和一個反駁a,任務(wù)是生成典型反駁c。
實(shí)驗(yàn)設(shè)置
- 從2,219個有至少一個行動的典型反駁的審稿句子開始。
- 輸入為將rev和a與分隔符連接在一起,產(chǎn)生17,873個獨(dú)特的審稿-反駁行動實(shí)例。
- 使用與前面實(shí)驗(yàn)相同的超參數(shù)、模型和度量標(biāo)準(zhǔn),并進(jìn)行完全微調(diào)以及零次和少次預(yù)測實(shí)驗(yàn)。
- 對這些實(shí)驗(yàn),應(yīng)用70/10/20的訓(xùn)練-驗(yàn)證-測試分割,以獲取訓(xùn)練-驗(yàn)證-測試部分,以典型反駁(302個反駁與17,873個獨(dú)特實(shí)例相連)為層次。
結(jié)果
- 模型間的差異與之前的發(fā)現(xiàn)一致:BART在零次和少次設(shè)置中表現(xiàn)出色,T5雖然起點(diǎn)最低,但很快趕上其他模型。
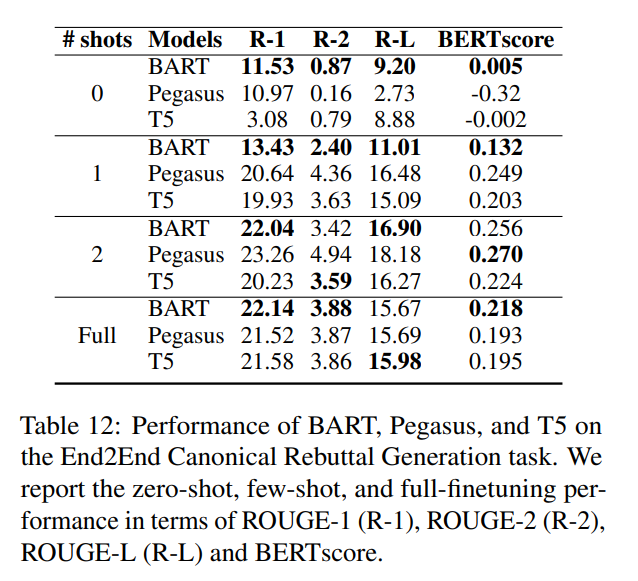
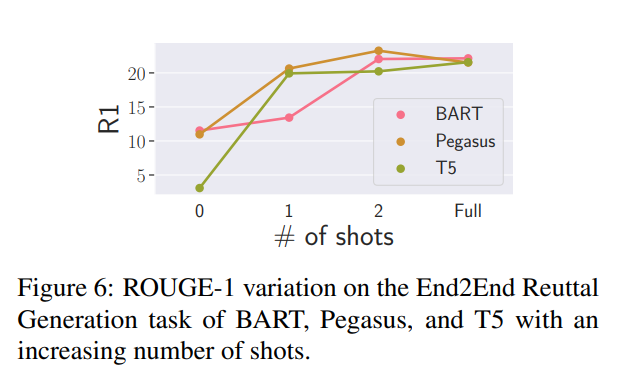
- 模型的表現(xiàn)比以前更加陡峭,并在兩次嘗試后就似乎達(dá)到了一個平臺。研究團(tuán)隊(duì)認(rèn)為這與典型反駁的有限多樣性有關(guān),以及他們決定在典型反駁層次上進(jìn)行的訓(xùn)練-測試分割——任務(wù)是生成模板,并對這些模板進(jìn)行概括。看到其中只有幾個模板后,模型很快就能抓住一般的要點(diǎn),但無法超越它們所展示的內(nèi)容。
結(jié)語
在這項(xiàng)工作中,研究團(tuán)隊(duì)探索了基于審稿者潛在態(tài)度驅(qū)動的同行評審中的柔術(shù)式論證,為此他們創(chuàng)建了JITSUPEER數(shù)據(jù)集。這個新穎的數(shù)據(jù)集包含與典型反駁相連的審稿句子,這些典型反駁可以作為撰寫有效同行評審反駁的模板。團(tuán)隊(duì)在這個數(shù)據(jù)集上提出了不同的自然語言處理任務(wù),并對多種基線策略進(jìn)行了基準(zhǔn)測試。JITSUPEER的注釋將公開提供,研究團(tuán)隊(duì)相信這個數(shù)據(jù)集將成為促進(jìn)計(jì)算論證領(lǐng)域中有效同行評審反駁寫作研究的寶貴資源。
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25291 -
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14038 -
LLM
+關(guān)注
關(guān)注
1文章
321瀏覽量
696
原文標(biāo)題:用LLM生成反駁:首先洞察審稿人的心理,再巧妙回應(yīng)!
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實(shí)踐

小白學(xué)大模型:從零實(shí)現(xiàn) LLM語言模型

詳解 LLM 推理模型的現(xiàn)狀





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論