") 任意文本、視覺、音頻混合生成,多模態(tài)有了強大的基礎(chǔ)引擎CoDi-2
任意文本、視覺、音頻混合生成,多模態(tài)有了強大的基礎(chǔ)引擎CoDi-2
今年 5 月,北卡羅來納大學(xué)教堂山分校、微軟提出一種可組合擴(kuò)散(Composable Diffusion,簡稱 CoDi)模型,讓一種模型統(tǒng)一多種模態(tài)成為可能。CoDi 不僅支持從單模態(tài)到單模態(tài)的生成,還能接收多個條件輸入以及多模態(tài)聯(lián)合生成。
近日,UC 伯克利、微軟 Azure AI、Zoom、北卡羅來納大學(xué)教堂山分校等多個機(jī)構(gòu)的研究者將 CoDi 升級到了 CoDi-2。

-
論文地址:https://arxiv.org/pdf/2311.18775.pdf
-
項目地址:https://codi-2.github.io/
項目 demo
論文一作 Zineng Tang 表示,「CoDi-2 遵循復(fù)雜的多模態(tài)交錯上下文指令,以零樣本或少樣本交互的方式生成任何模態(tài)(文本、視覺和音頻)。」

圖源:https://twitter.com/ZinengTang/status/1730658941414371820
可以說,作為一種多功能、交互式的多模態(tài)大語言模型(MLLM),CoDi-2 能夠以 any-to-any 輸入-輸出模態(tài)范式進(jìn)行上下文學(xué)習(xí)、推理、聊天、編輯等任務(wù)。通過對齊編碼與生成時的模態(tài)與語言,CoDi-2 使 LLM 不僅可以理解復(fù)雜的模態(tài)交錯指令和上下文示例, 還能在連續(xù)的特征空間內(nèi)自回歸地生成合理和連貫的多模態(tài)輸出。
而為了訓(xùn)練 CoDi-2,研究者構(gòu)建了一個大規(guī)模生成數(shù)據(jù)集,包含了跨文本、視覺和音頻的上下文多模態(tài)指令。CoDi-2 展示了一系列多模態(tài)生成的零樣本能力,比如上下文學(xué)習(xí)、推理以及通過多輪交互對話實現(xiàn)的 any-to-any 模態(tài)生成組合。其中在主題驅(qū)動圖像生成、視覺轉(zhuǎn)換和音頻編輯等任務(wù)上超越了以往領(lǐng)域特定的模型。

人類與 CoDi-2 的多輪對話為圖像編輯提供了上下文多模態(tài)指令。
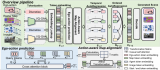
模型架構(gòu)
CoDi-2 在設(shè)計時旨在處理上下文中的文本、圖像和音頻等多模態(tài)輸入,利用特定指令促進(jìn)上下文學(xué)習(xí)并生成相應(yīng)的文本、圖像和音頻輸出。CoDi-2 模型架構(gòu)圖如下所示。
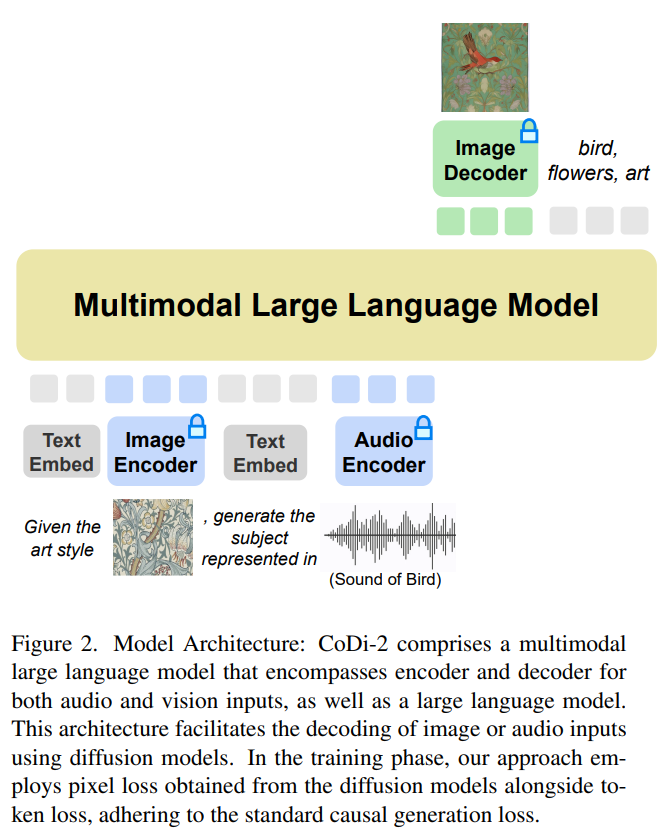
將多模態(tài)大語言模型作為基礎(chǔ)引擎
這種 any-to-any 基礎(chǔ)模型可以消化交錯式模態(tài)輸入,理解和推理復(fù)雜指令(如多輪對話、上下文示例),并與多模態(tài)擴(kuò)散器交互,實現(xiàn)這一切的前提是需要一個強大的基礎(chǔ)引擎。研究者提出將 MLLM 作為這個引擎,它的構(gòu)建需要為僅文本的 LLM 提供多模態(tài)感知。
利用對齊的多模態(tài)編碼器映射,研究者可以無縫地使 LLM 感知到模態(tài)交錯的輸入序列。具體地,在處理多模態(tài)輸入序列時,他們首先使用多模態(tài)編碼器將多模態(tài)數(shù)據(jù)映射到特征序列,然后特殊 token 被添加到特征序列的前后,比如「?audio? [audio feature sequence] ?/audio?」。
基于 MLLM 的多模態(tài)生成
研究者提出將擴(kuò)散模型(DM)集成到 MLLM 中,從而生成多模態(tài)輸出,這里遵循細(xì)致入微的多模態(tài)交錯指令和提示。擴(kuò)散模型的訓(xùn)練目標(biāo)如下所示:
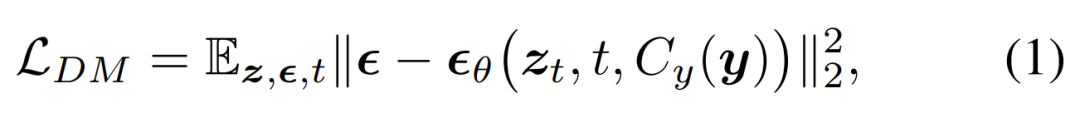
接著他們提出訓(xùn)練 MLLM 以生成條件式特征 c = C_y (y),該特征被饋入到擴(kuò)散模型中以合成目標(biāo)輸出 x。這樣一來,擴(kuò)散模型的生成損失被用來訓(xùn)練 MLLM。
任務(wù)類型
本文提出的模型在以下示例任務(wù)類型中顯示出強大的能力,它提供了一種獨特的方法來提示模型生成或轉(zhuǎn)換上下文中的多模態(tài)內(nèi)容,包括本文、圖像、音頻、視頻及其組合。
1. 零樣本提示。零樣本提示任務(wù)要求模型在沒有任何先前示例的情況下進(jìn)行推理并生成新內(nèi)容。
2. 一次/少量樣本提示。一次或少量樣本提示為模型提供了一個或幾個示例,以便在執(zhí)行類似任務(wù)之前從中學(xué)習(xí)。這種方法在以下任務(wù)中很明顯:模型將學(xué)習(xí)到的概念從一個圖像應(yīng)用到另一個圖像,或者通過理解所提供示例中描述的風(fēng)格來創(chuàng)建一個新的藝術(shù)品。
(1)范例學(xué)習(xí)在要求模型將此學(xué)習(xí)應(yīng)用于新實例之前,向模型顯式顯示期望輸出的示例。(2)概念學(xué)習(xí)涉及模型從這些給定示例的共享概念/屬性中學(xué)習(xí),例如藝術(shù)風(fēng)格或模式,然后創(chuàng)建展示類似概念/屬性的新內(nèi)容。(3)主題驅(qū)動的學(xué)習(xí)側(cè)重于根據(jù)一組提供的圖像生成新的內(nèi)容。
實驗及結(jié)果
模型設(shè)置
本文模型的實現(xiàn)基于 Llama2,特別是 Llama-2-7b-chat-hf。研究者使用 ImageBind ,它具有對齊的圖像、視頻、音頻、文本、深度、thermal 和 IMU 模式編碼器。研究者使用 ImageBind 對圖像和音頻特征進(jìn)行編碼,并通過多層感知器(MLP)將其投射到 LLM(Llama-2-7b-chat-hf)的輸入維度。MLP 由線性映射、激活、歸一化和另一個線性映射組成。當(dāng) LLM 生成圖像或音頻特征時,他們通過另一個 MLP 將其投射回 ImageBind 特征維度。本文圖像擴(kuò)散模型基于 StableDiffusion2.1 (stabilityai/stable-diffusion-2-1-unclip)、AudioLDM2 和 zeroscope v2。
對于需要更高保真原始輸入的圖像或音頻,研究者還將原始圖像或音頻輸入到擴(kuò)散模型中,同時通過連接擴(kuò)散噪聲生成特征。這種方法在保留輸入內(nèi)容的最大感知特征方面尤為有效,添加新內(nèi)容或改變風(fēng)格等指令編輯也是如此。
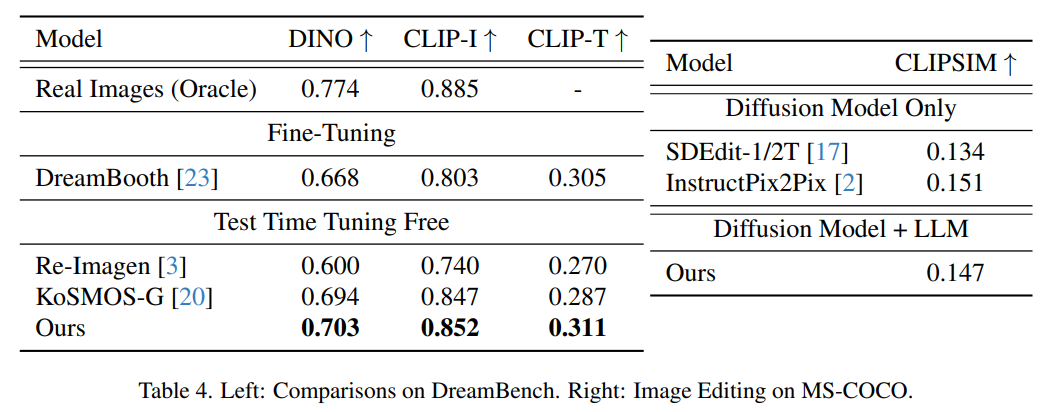
圖像生成評估
下圖展示了 Dreambench 上主題驅(qū)動圖像生成的評估結(jié)果和 MSCOCO 上的 FID 分?jǐn)?shù)。本文方法實現(xiàn)了極具競爭力的零樣本性能,顯示了其對未知新任務(wù)的泛化能力。
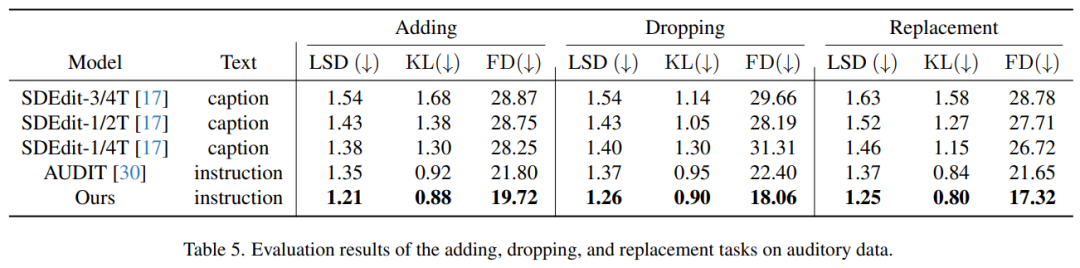
音頻生成評估
表 5 展示了音頻處理任務(wù)的評估結(jié)果,即添加、刪除和替換音軌中的元素。從表中可以明顯看出,與之前的方法相比,本文方法表現(xiàn)出了卓越的性能。值得注意的是,在所有三個編輯任務(wù)中,它在所有指標(biāo) — 對數(shù)譜距離(LSD)、Kullback-Leibler(KL)發(fā)散和 Fréchet Dis- tance(FD)上都取得了最低得分。
原文標(biāo)題:任意文本、視覺、音頻混合生成,多模態(tài)有了強大的基礎(chǔ)引擎CoDi-2
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2927文章
45974瀏覽量
388891
原文標(biāo)題:任意文本、視覺、音頻混合生成,多模態(tài)有了強大的基礎(chǔ)引擎CoDi-2
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

一種多模態(tài)駕駛場景生成框架UMGen介紹
移遠(yuǎn)通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

移遠(yuǎn)通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

?VLM(視覺語言模型)?詳細(xì)解析

?多模態(tài)交互技術(shù)解析
階躍星辰開源多模態(tài)模型,天數(shù)智芯迅速適配

字節(jié)跳動即將推出多模態(tài)視頻生成模型OmniHuman
字節(jié)跳動發(fā)布OmniHuman 多模態(tài)框架

高通與智譜推動多模態(tài)生成式AI體驗的終端側(cè)部署
利用OpenVINO部署Qwen2多模態(tài)模型
Meta發(fā)布多模態(tài)LLAMA 3.2人工智能模型
基于Qwen-Agent與OpenVINO構(gòu)建本地AI智能體






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論