 谷歌Gemini模型AI網絡及TPU拆解
谷歌Gemini模型AI網絡及TPU拆解
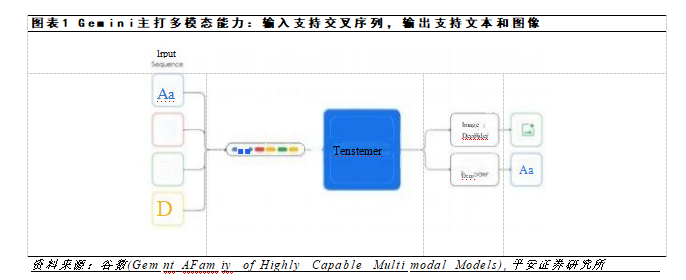
Gemini 是一款新型的多模態大語言模型,此前多模態大模型在處理視頻、文字、圖像等多維度輸入信息時是采用分別訓練分別輸出再進行拼接的方式,這種方式的缺點在于面對復雜邏輯問題時,大模型的回復略顯遲鈍。
Gemini 采用了全新的訓練方式,直接在多模態數據上進行預訓練,并利用額外的多模態數據進行微調,因而可在處理復雜邏輯問題上更加智能。
下載鏈接:
Gemini 模型一共包括三個版本,可以在不同設備上進行使用。
1)Gemini Nano—端側設備上最高效的模型。這款模型專為智能手機設計,可以在沒有連接外部服務器的情況下完成 AI 處理任務。
2)Gemini Pro—運行在谷歌數據中心。Pro 版本將在最新版本的 AI 聊天機器人 Bard 提供支持,是 Bard推出以來的最大升級。目前為 170 多個國家和地區提供英語服務,計劃未來幾個月內支持新的語言和地區,并應用于搜索、廣告、Chrome 和 Duet AI 等更多谷歌產品。
3)Gemini Ultra —規模最大且功能最強大的模型,專用于高度復雜的任務,會在完成當前測試階段后的明年初向開發者和企業客戶提供。屆時還會推出基于 Gemini Ultra 的 Bard Advanced 更新版本。
Gemini 模型訓練基于谷歌自研 TPU 芯片,發布 TPU v5P,性能全部升級。谷歌較早就開始布局 AI 市場,2015 年便發布了專門用于 AI 領域的專用芯片 TPU v1,2015 年至今,谷歌已經完成了五個版本的迭代。目前現階段谷歌展示的 Gemini 1.0 模型就是基于 TPU v4 和 TPU v5e 兩類芯片來完成訓練過程。
在發布 Gemini 模型的同時,谷歌發布了最新的 TPU v5p 系列。v5p 進一步增強了方案可拓展性,并為了應對復雜模型的推理訓練與調整需求,設計了新的硬件架構。在 v5p 構建的集群,每個 Pod 計算單元由 8960顆芯片互聯,數量較之前的版本翻倍。計算性能上,新的 pod 浮點運算能力相比 v4 提升了兩倍,訓練速度相比 v4 提升 2.8 倍以上。
谷歌 TPU:創新網絡拓撲結構,采用光交換技術(OCS)。傳統數據中心網絡結構為 leaf-spine 葉脊架構,英偉達 AI 集群采用的是無收斂胖拓撲結構,谷歌的 AI 網絡集群在 spine 層進行創新,用 OCS 交換機(光路開關,optical circuit switch)代替傳統的電交換機(以太網交換機)。傳統數據中心在 spine 層需要進行大量的電光轉換,會產生較多的功耗,并且隨著數據量增加 spine 層每 2-3 年都需要進行更換。谷歌的 OCS 的目的是替代當下的電網絡交換機,從而實現近一步成本和功耗的降低。
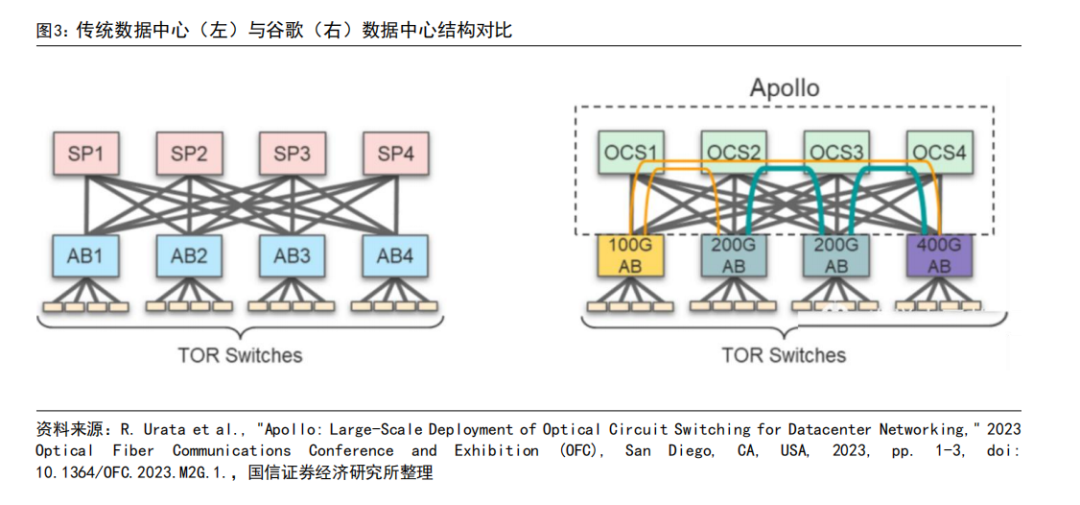
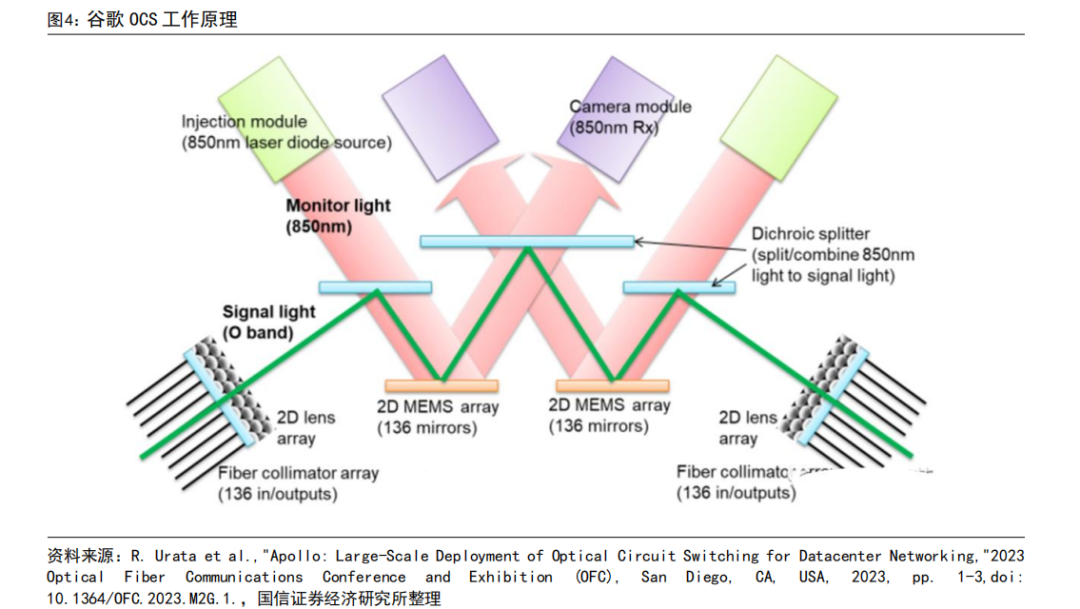
谷歌的 OCS 稱為為 Palomar,內部結構為:輸入輸出為光纖準直器陣列,光纖準直器包括光纖陣列和微透鏡陣列,輸入和數據均為 136 個通道(128 個端口+8 個備用端口)。當光通過光纖進入 OCS 系統后,會通過兩個 2D 的 MEMS 陣列,每個 MEMS 陣列含有 136 個平面鏡,用于調整光的傳播方向。波長為 850nm。
谷歌 AI 網絡結構拆解:TPU v4 為例。在 TPU v4 網絡結構設計時候,每個基礎單元是 4*4*4=64 顆 TPU 組成,每個面有 16 個鏈路,因此每個單元一共有 16*6=96 個鏈路連接到 OCS 的光鏈路.此外因為提供 3D 環面的環繞鏈接,相對側的鏈接必須連接到同一個 OCS。因此,每個基礎單元需要 6×16/2=48 個 OCS。
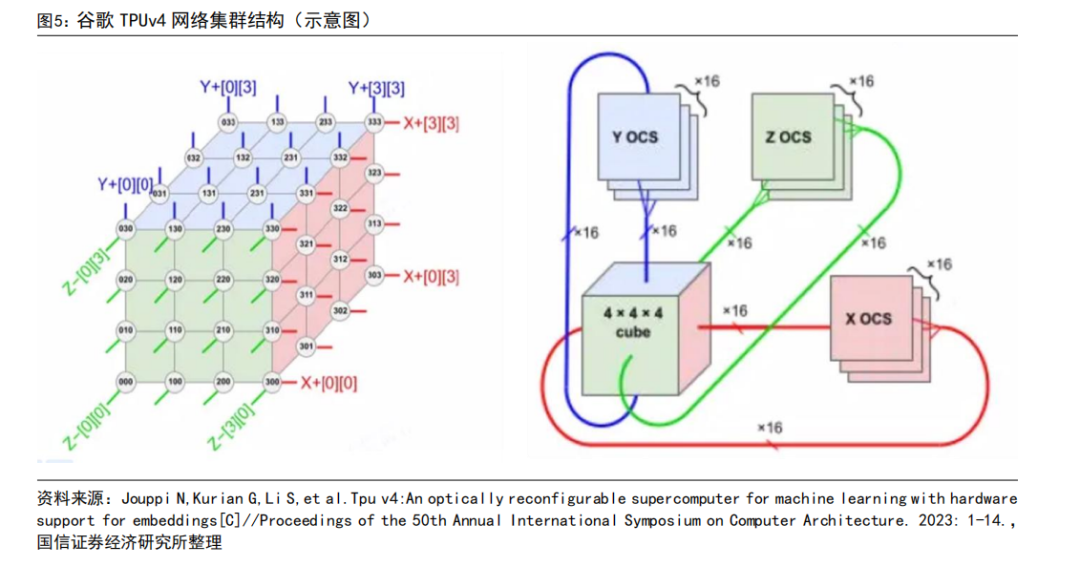
谷歌 TPU v4 支持 4096 顆 TPU 互聯,具體方案為一共使用 64 個機柜,每個機柜內部構建 4*4*4=64 顆 TPU的 3D 網絡結構,其中 3D 結構的外表部分連接到 OCS,中間部分采用無源電纜互聯。在 4096 顆 TPU 互聯的系統中一共使用 48 了個 OCS,每個 OCS128 個端口。此外因為 OCS 本身直接進行光信號的傳輸,所以每個端口只需要 1 個光模塊。因為該集群需要 48*128=6144 個光模塊。TPU:光模塊用量=4096:6144=1:1.5
AMD MI300X 對標英偉達 H100。MI300X 由臺積電代工,基于自研的第三代 CDNA 架構,集成了 1530 億個晶體管。
對比英偉達 H100,集成了 800 億個晶體管。在性能指標上:1)AI 芯片算力:8 位精度浮點數(FP8)計算水平來看,MI300X 為 42petaFLOPs(每秒千萬億次浮點運算),H100 則為 32petaFLOPs;2)內存:MI300X為 192GB,英偉達 H109 為 120GB。目前,集合 8 張 MI300X 的 Instinct 工作臺已經可以支持運行 Llama2(700 億參數)、BLOOM(1760 億參數)大模型的訓練與推理。
MI300A:首款高性能 APU。具體參數上,MI300A 具有 228 個 CDNA3 架構的計算核心,24 個 Zen4 架構的 X86核心,4 個 I/O DIe,8 個 HBM3,128GB 顯存,5.3TB 峰值帶寬,256MB 的 Infinity 緩存,采用 3.5D 的封裝形式。
審核編輯:湯梓紅
-
谷歌
+關注
關注
27文章
6227瀏覽量
107708 -
Gemini
+關注
關注
0文章
65瀏覽量
7873 -
AI
+關注
關注
88文章
34520瀏覽量
276046 -
語言模型
+關注
關注
0文章
561瀏覽量
10703 -
TPU
+關注
關注
0文章
152瀏覽量
21112
原文標題:谷歌Gemini模型AI網絡及TPU拆解
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規模思考與推理的 AI 模型新引擎?
谷歌揭秘Gemini,AMD對峙英偉達
成都匯陽投資關于谷歌攜 Gemini 王者歸來,AI 算力和應用值得期待
谷歌發布多模態Gemini大模型及新一代TPU系統Cloud TPU v5p
谷歌最新人工智能模型Gemini Pro已在歐洲上市
谷歌計劃重新推出改進后的Gemini AI模型人像生成功能
谷歌Gemini 1.5 Flash模型升級,AI聊天速度飆升50%
谷歌計劃12月發布Gemini 2.0模型
谷歌發布Gemini 2.0 AI模型
谷歌發布“深度研究”AI工具,利用Gemini模型進行網絡信息檢索
借助谷歌Gemini和Imagen模型生成高質量圖像

谷歌Gemini AI目標年底用戶達5億
谷歌 Gemini 2.0 Flash 系列 AI 模型上新
谷歌AI霸主歸來!多線反擊OpenAI,開啟安卓Gemini時代





 工商網監
工商網監
評論