 TCP協議面試常問知識點總結
TCP協議面試常問知識點總結

前言
大家好,這里是浩道Linux,主要給大家分享Linux、Python、網絡通信、網絡安全等相關的IT知識平臺。
不知道大家有沒有這樣的經歷,每每參加求職面試時,經常會倒在一些基礎題目是上,不是大家不會,而是大家容易忽略掉,今天浩道給大家整理了一份面試常見試題,收藏起來,需要用時打開復習即可!
TCP 作為傳輸層的協議,是一個IT工程師素養的體現,也是面試中經常被問到的知識點。在此,我將 TCP 核心的一些問題梳理了一下,希望能幫到各位。
001. 能不能說一說 TCP 和 UDP 的區別?
首先概括一下基本的區別:
TCP是一個面向連接的、可靠的、基于字節流的傳輸層協議。
而UDP是一個面向無連接的傳輸層協議。(就這么簡單,其它TCP的特性也就沒有了)。
具體來分析,和UDP相比,TCP有三大核心特性:
面向連接。所謂的連接,指的是客戶端和服務器的連接,在雙方互相通信之前,TCP 需要三次握手建立連接,而 UDP 沒有相應建立連接的過程。
可靠性。TCP 花了非常多的功夫保證連接的可靠,這個可靠性體現在哪些方面呢?一個是有狀態,另一個是可控制。
TCP 會精準記錄哪些數據發送了,哪些數據被對方接收了,哪些沒有被接收到,而且保證數據包按序到達,不允許半點差錯。這是有狀態。
當意識到丟包了或者網絡環境不佳,TCP 會根據具體情況調整自己的行為,控制自己的發送速度或者重發。這是可控制。
相應的,UDP 就是無狀態,不可控的。
面向字節流。UDP 的數據傳輸是基于數據報的,這是因為僅僅只是繼承了 IP 層的特性,而 TCP 為了維護狀態,將一個個 IP 包變成了字節流。
002: 說說 TCP 三次握手的過程?為什么是三次而不是兩次、四次?
戀愛模擬
以談戀愛為例,兩個人能夠在一起最重要的事情是首先確認各自愛和被愛的能力。接下來我們以此來模擬三次握手的過程。
第一次:
男:我愛你。
女方收到。
由此證明男方擁有愛的能力。
第二次:
女:我收到了你的愛,我也愛你。
男方收到。
OK,現在的情況說明,女方擁有愛和被愛的能力。
第三次:
男:我收到了你的愛。
女方收到。
現在能夠保證男方具備被愛的能力。
由此完整地確認了雙方愛和被愛的能力,兩人開始一段甜蜜的愛情。
真實握手
當然剛剛那段屬于扯淡,不代表本人價值觀,目的是讓大家理解整個握手過程的意義,因為兩個過程非常相似。對應到 TCP 的三次握手,也是需要確認雙方的兩樣能力:發送的能力和接收的能力。于是便會有下面的三次握手的過程:
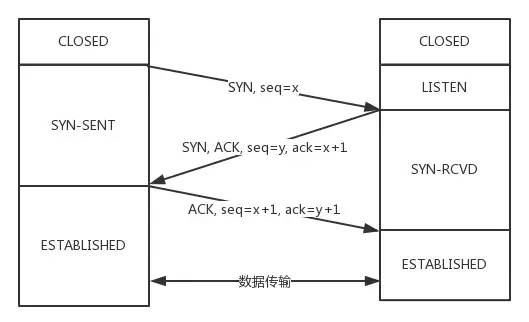
從最開始雙方都處于CLOSED狀態。然后服務端開始監聽某個端口,進入了LISTEN狀態。
然后客戶端主動發起連接,發送 SYN , 自己變成了SYN-SENT狀態。
服務端接收到,返回SYN和ACK(對應客戶端發來的SYN),自己變成了SYN-REVD。
之后客戶端再發送ACK給服務端,自己變成了ESTABLISHED狀態;服務端收到ACK之后,也變成了ESTABLISHED狀態。
另外需要提醒你注意的是,從圖中可以看出,SYN 是需要消耗一個序列號的,下次發送對應的 ACK 序列號要加1,為什么呢?只需要記住一個規則:
凡是需要對端確認的,一定消耗TCP報文的序列號。
SYN 需要對端的確認, 而 ACK 并不需要,因此 SYN 消耗一個序列號而 ACK 不需要。
為什么不是兩次?
根本原因: 無法確認客戶端的接收能力。
分析如下:
如果是兩次,你現在發了 SYN 報文想握手,但是這個包滯留在了當前的網絡中遲遲沒有到達,TCP 以為這是丟了包,于是重傳,兩次握手建立好了連接。
看似沒有問題,但是連接關閉后,如果這個滯留在網路中的包到達了服務端呢?這時候由于是兩次握手,服務端只要接收到然后發送相應的數據包,就默認建立連接,但是現在客戶端已經斷開了。
看到問題的吧,這就帶來了連接資源的浪費。
為什么不是四次?
三次握手的目的是確認雙方發送和接收的能力,那四次握手可以嘛?
當然可以,100 次都可以。但為了解決問題,三次就足夠了,再多用處就不大了。
三次握手過程中可以攜帶數據么?
第三次握手的時候,可以攜帶。前兩次握手不能攜帶數據。
如果前兩次握手能夠攜帶數據,那么一旦有人想攻擊服務器,那么他只需要在第一次握手中的 SYN 報文中放大量數據,那么服務器勢必會消耗更多的時間和內存空間去處理這些數據,增大了服務器被攻擊的風險。
第三次握手的時候,客戶端已經處于ESTABLISHED狀態,并且已經能夠確認服務器的接收、發送能力正常,這個時候相對安全了,可以攜帶數據。
同時打開會怎樣?
如果雙方同時發SYN報文,狀態變化會是怎樣的呢?
這是一個可能會發生的情況。
狀態變遷如下:
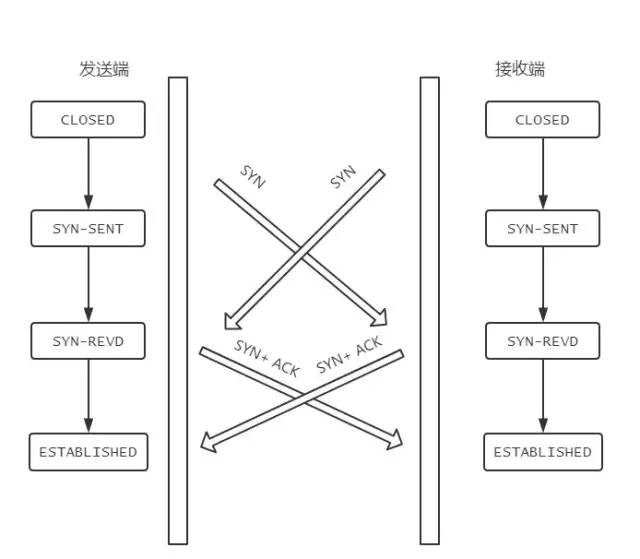
在發送方給接收方發SYN報文的同時,接收方也給發送方發SYN報文,兩個人剛上了!
發完SYN,兩者的狀態都變為SYN-SENT。
在各自收到對方的SYN后,兩者狀態都變為SYN-REVD。
接著會回復對應的ACK + SYN,這個報文在對方接收之后,兩者狀態一起變為ESTABLISHED。
這就是同時打開情況下的狀態變遷。
003: 說說 TCP 四次揮手的過程
過程拆解
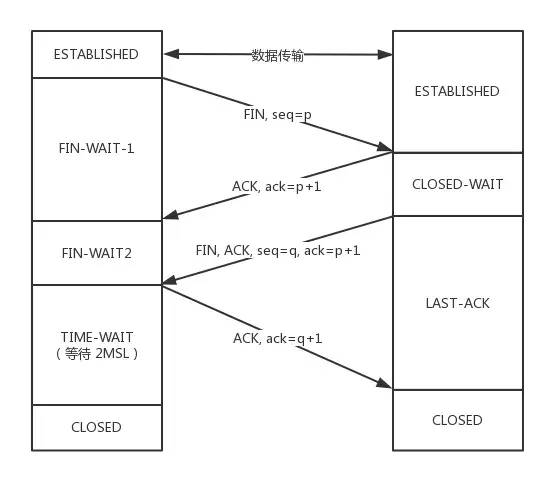
剛開始雙方處于ESTABLISHED狀態。
客戶端要斷開了,向服務器發送FIN報文,在 TCP 報文中的位置如下圖:
發送后客戶端變成了FIN-WAIT-1狀態。注意, 這時候客戶端同時也變成了half-close(半關閉)狀態,即無法向服務端發送報文,只能接收。
服務端接收后向客戶端確認,變成了CLOSED-WAIT狀態。
客戶端接收到了服務端的確認,變成了FIN-WAIT2狀態。
隨后,服務端向客戶端發送FIN,自己進入LAST-ACK狀態,
客戶端收到服務端發來的FIN后,自己變成了TIME-WAIT狀態,然后發送 ACK 給服務端。
注意了,這個時候,客戶端需要等待足夠長的時間,具體來說,是 2 個MSL(Maximum Segment Lifetime,報文最大生存時間), 在這段時間內如果客戶端沒有收到服務端的重發請求,那么表示 ACK 成功到達,揮手結束,否則客戶端重發 ACK。
等待2MSL的意義
如果不等待會怎樣?
如果不等待,客戶端直接跑路,當服務端還有很多數據包要給客戶端發,且還在路上的時候,若客戶端的端口此時剛好被新的應用占用,那么就接收到了無用數據包,造成數據包混亂。所以,最保險的做法是等服務器發來的數據包都死翹翹再啟動新的應用。
那,照這樣說一個 MSL 不就不夠了嗎,為什么要等待 2 MSL?
1 個 MSL 確保四次揮手中主動關閉方最后的 ACK 報文最終能達到對端
1 個 MSL 確保對端沒有收到 ACK 重傳的 FIN 報文可以到達
這就是等待 2MSL 的意義。
為什么是四次揮手而不是三次?
因為服務端在接收到FIN, 往往不會立即返回FIN, 必須等到服務端所有的報文都發送完畢了,才能發FIN。因此先發一個ACK表示已經收到客戶端的FIN,延遲一段時間才發FIN。這就造成了四次揮手。
如果是三次揮手會有什么問題?
等于說服務端將ACK和FIN的發送合并為一次揮手,這個時候長時間的延遲可能會導致客戶端誤以為FIN沒有到達客戶端,從而讓客戶端不斷的重發FIN。
同時關閉會怎樣?
如果客戶端和服務端同時發送 FIN ,狀態會如何變化?如圖所示:
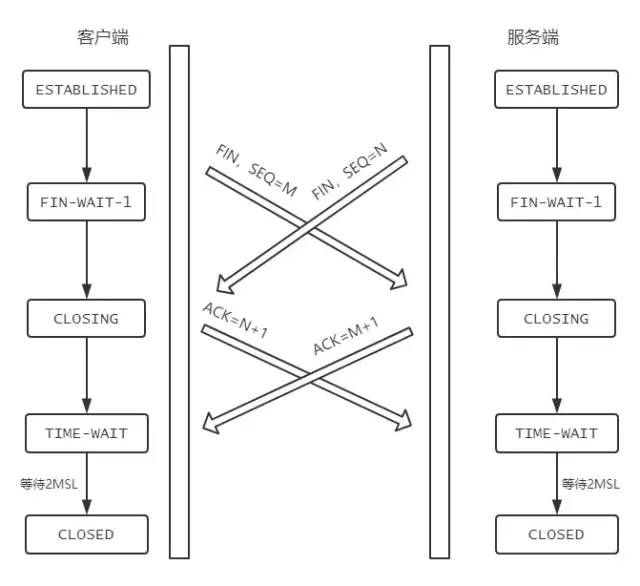
004: 說說半連接隊列和 SYN Flood 攻擊的關系
三次握手前,服務端的狀態從CLOSED變為LISTEN, 同時在內部創建了兩個隊列:半連接隊列和全連接隊列,即SYN隊列和ACCEPT隊列。
半連接隊列
當客戶端發送SYN到服務端,服務端收到以后回復ACK和SYN,狀態由LISTEN變為SYN_RCVD,此時這個連接就被推入了SYN隊列,也就是半連接隊列。
全連接隊列
當客戶端返回ACK, 服務端接收后,三次握手完成。這個時候連接等待被具體的應用取走,在被取走之前,它會被推入另外一個 TCP 維護的隊列,也就是全連接隊列(Accept Queue)。
SYN Flood 攻擊原理
SYN Flood 屬于典型的 DoS/DDoS 攻擊。其攻擊的原理很簡單,就是用客戶端在短時間內偽造大量不存在的 IP 地址,并向服務端瘋狂發送SYN。對于服務端而言,會產生兩個危險的后果:
處理大量的SYN包并返回對應ACK, 勢必有大量連接處于SYN_RCVD狀態,從而占滿整個半連接隊列,無法處理正常的請求。
由于是不存在的 IP,服務端長時間收不到客戶端的ACK,會導致服務端不斷重發數據,直到耗盡服務端的資源。
如何應對 SYN Flood 攻擊?
增加 SYN 連接,也就是增加半連接隊列的容量。
減少 SYN + ACK 重試次數,避免大量的超時重發。
利用 SYN Cookie 技術,在服務端接收到SYN后不立即分配連接資源,而是根據這個SYN計算出一個Cookie,連同第二次握手回復給客戶端,在客戶端回復ACK的時候帶上這個Cookie值,服務端驗證 Cookie 合法之后才分配連接資源。
005: 介紹一下 TCP 報文頭部的字段
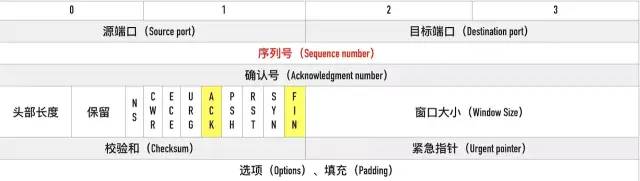
報文頭部結構如下(單位為字節):
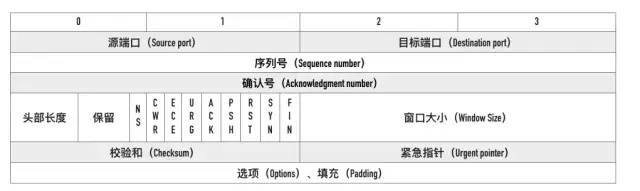
請大家牢記這張圖!
源端口、目標端口
如何標識唯一標識一個連接?答案是 TCP 連接的四元組——源 IP、源端口、目標 IP 和目標端口。
那 TCP 報文怎么沒有源 IP 和目標 IP 呢?這是因為在 IP 層就已經處理了 IP 。TCP 只需要記錄兩者的端口即可。
序列號
即Sequence number, 指的是本報文段第一個字節的序列號。
從圖中可以看出,序列號是一個長為 4 個字節,也就是 32 位的無符號整數,表示范圍為 0 ~ 2^32 - 1。如果到達最大值了后就循環到0。
序列號在 TCP 通信的過程中有兩個作用:
在 SYN 報文中交換彼此的初始序列號。
保證數據包按正確的順序組裝。
ISN
即Initial Sequence Number(初始序列號),在三次握手的過程當中,雙方會用過SYN報文來交換彼此的ISN。
ISN 并不是一個固定的值,而是每 4 ms 加一,溢出則回到 0,這個算法使得猜測 ISN 變得很困難。那為什么要這么做?
如果 ISN 被攻擊者預測到,要知道源 IP 和源端口號都是很容易偽造的,當攻擊者猜測 ISN 之后,直接偽造一個 RST 后,就可以強制連接關閉的,這是非常危險的。
而動態增長的 ISN 大大提高了猜測 ISN 的難度。
確認號
即ACK(Acknowledgment number)。用來告知對方下一個期望接收的序列號,小于ACK的所有字節已經全部收到。
標記位
常見的標記位有SYN,ACK,FIN,RST,PSH。
SYN 和 ACK 已經在上文說過,后三個解釋如下:FIN:即 Finish,表示發送方準備斷開連接。
RST:即 Reset,用來強制斷開連接。
PSH:即 Push, 告知對方這些數據包收到后應該馬上交給上層的應用,不能緩存。
窗口大小
占用兩個字節,也就是 16 位,但實際上是不夠用的。因此 TCP 引入了窗口縮放的選項,作為窗口縮放的比例因子,這個比例因子的范圍在 0 ~ 14,比例因子可以將窗口的值擴大為原來的 2 ^ n 次方。
校驗和
占用兩個字節,防止傳輸過程中數據包有損壞,如果遇到校驗和有差錯的報文,TCP 直接丟棄之,等待重傳。
可選項
可選項的格式如下:

常用的可選項有以下幾個:
TimeStamp: TCP 時間戳,后面詳細介紹。
MSS: 指的是 TCP 允許的從對方接收的最大報文段。
SACK: 選擇確認選項。
Window Scale:窗口縮放選項。
006: 說說 TCP 快速打開的原理(TFO)
第一節講了 TCP 三次握手,可能有人會說,每次都三次握手好麻煩呀!能不能優化一點?
可以啊。今天來說說這個優化后的 TCP 握手流程,也就是 TCP 快速打開(TCP Fast Open, 即TFO)的原理。
優化的過程是這樣的,還記得我們說 SYN Flood 攻擊時提到的 SYN Cookie 嗎?這個 Cookie 可不是瀏覽器的Cookie, 用它同樣可以實現 TFO。
TFO 流程
首輪三次握手
首先客戶端發送SYN給服務端,服務端接收到。
注意哦!現在服務端不是立刻回復 SYN + ACK,而是通過計算得到一個SYN Cookie, 將這個Cookie放到 TCP 報文的Fast Open選項中,然后才給客戶端返回。
客戶端拿到這個 Cookie 的值緩存下來。后面正常完成三次握手。
首輪三次握手就是這樣的流程。而后面的三次握手就不一樣啦!
后面的三次握手
在后面的三次握手中,客戶端會將之前緩存的Cookie、SYN和HTTP請求(是的,你沒看錯)發送給服務端,服務端驗證了 Cookie 的合法性,如果不合法直接丟棄;如果是合法的,那么就正常返回SYN + ACK。
重點來了,現在服務端能向客戶端發 HTTP 響應了!這是最顯著的改變,三次握手還沒建立,僅僅驗證了 Cookie 的合法性,就可以返回 HTTP 響應了。
當然,客戶端的ACK還得正常傳過來,不然怎么叫三次握手嘛。
流程如下:
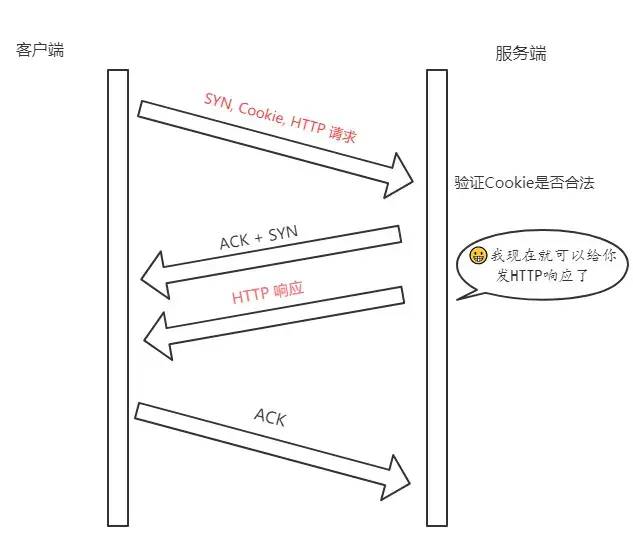
注意: 客戶端最后握手的 ACK 不一定要等到服務端的 HTTP 響應到達才發送,兩個過程沒有任何關系。
TFO 的優勢
TFO 的優勢并不在與首輪三次握手,而在于后面的握手,在拿到客戶端的 Cookie 并驗證通過以后,可以直接返回 HTTP 響應,充分利用了1 個RTT(Round-Trip Time,往返時延)的時間提前進行數據傳輸,積累起來還是一個比較大的優勢。
007: 能不能說說TCP報文中時間戳的作用?
timestamp是 TCP 報文首部的一個可選項,一共占 10 個字節,格式如下:
kind(1字節) +length(1字節) +info(8個字節)
其中 kind = 8, length = 10, info 有兩部分構成:timestamp和timestamp echo,各占 4 個字節。
那么這些字段都是干嘛的呢?它們用來解決那些問題?
接下來我們就來一一梳理,TCP 的時間戳主要解決兩大問題:
計算往返時延 RTT(Round-Trip Time)
防止序列號的回繞問題
計算往返時延 RTT
在沒有時間戳的時候,計算 RTT 會遇到的問題如下圖所示:
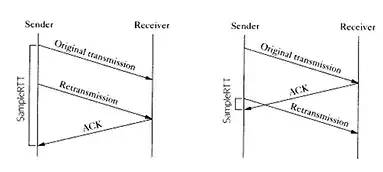
如果以第一次發包為開始時間的話,就會出現左圖的問題,RTT 明顯偏大,開始時間應該采用第二次的;
如果以第二次發包為開始時間的話,就會導致右圖的問題,RTT 明顯偏小,開始時間應該采用第一次發包的。
實際上無論開始時間以第一次發包還是第二次發包為準,都是不準確的。
那這個時候引入時間戳就很好的解決了這個問題。
比如現在 a 向 b 發送一個報文 s1,b 向 a 回復一個含 ACK 的報文 s2 那么:
step 1:a 向 b 發送的時候,timestamp中存放的內容就是 a 主機發送時的內核時刻ta1。
step 2:b 向 a 回復 s2 報文的時候,timestamp中存放的是 b 主機的時刻tb,timestamp echo字段為從 s1 報文中解析出來的 ta1。
step 3:a 收到 b 的 s2 報文之后,此時 a 主機的內核時刻是 ta2, 而在 s2 報文中的 timestamp echo 選項中可以得到ta1, 也就是 s2 對應的報文最初的發送時刻。然后直接采用 ta2 - ta1 就得到了 RTT 的值。
防止序列號回繞問題
現在我們來模擬一下這個問題。
序列號的范圍其實是在0 ~ 2 ^ 32 - 1, 為了方便演示,我們縮小一下這個區間,假設范圍是 0 ~ 4,那么到達 4 的時候會回到 0。
| 第幾次發包 | 發送字節 | 對應序列號 | 狀態 |
|---|---|---|---|
| 1 | 0 ~ 1 | 0 ~ 1 | 成功接收 |
| 2 | 1 ~ 2 | 1 ~ 2 | 滯留在網絡中 |
| 3 | 2 ~ 3 | 2 ~ 3 | 成功接收 |
| 4 | 3 ~ 4 | 3 ~ 4 | 成功接收 |
| 5 | 4 ~ 5 | 0 ~ 1 | 成功接收,序列號從0開始 |
| 6 | 5 ~ 6 | 1 ~ 2 | ??? |
假設在第 6 次的時候,之前還滯留在網路中的包回來了,那么就有兩個序列號為1 ~ 2的數據包了,怎么區分誰是誰呢?這個時候就產生了序列號回繞的問題。
那么用 timestamp 就能很好地解決這個問題,因為每次發包的時候都是將發包機器當時的內核時間記錄在報文中,那么兩次發包序列號即使相同,時間戳也不可能相同,這樣就能夠區分開兩個數據包了。
008: TCP 的超時重傳時間是如何計算的?
TCP 具有超時重傳機制,即間隔一段時間沒有等到數據包的回復時,重傳這個數據包。
那么這個重傳間隔是如何來計算的呢?
今天我們就來討論一下這個問題。
這個重傳間隔也叫做超時重傳時間(Retransmission TimeOut, 簡稱RTO),它的計算跟上一節提到的 RTT 密切相關。這里我們將介紹兩種主要的方法,一個是經典方法,一個是標準方法。
經典方法
經典方法引入了一個新的概念——SRTT(Smoothed round trip time,即平滑往返時間),沒產生一次新的 RTT. 就根據一定的算法對 SRTT 進行更新,具體而言,計算方式如下(SRTT 初始值為0):
SRTT= (α * SRTT) + ((1- α) * RTT)
其中,α 是平滑因子,建議值是0.8,范圍是0.8 ~ 0.9。
拿到 SRTT,我們就可以計算 RTO 的值了:
RTO= min(ubound, max(lbound, β * SRTT))
β 是加權因子,一般為1.3 ~ 2.0,lbound是下界,ubound是上界。
其實這個算法過程還是很簡單的,但是也存在一定的局限,就是在 RTT 穩定的地方表現還可以,而在 RTT 變化較大的地方就不行了,因為平滑因子 α 的范圍是0.8 ~ 0.9, RTT 對于 RTO 的影響太小。
標準方法
為了解決經典方法對于 RTT 變化不敏感的問題,后面又引出了標準方法,也叫Jacobson / Karels 算法。
一共有三步。
第一步: 計算SRTT,公式如下:
SRTT= (1- α) * SRTT + α * RTT
注意這個時候的α跟經典方法中的α取值不一樣了,建議值是1/8,也就是0.125。
第二步: 計算RTTVAR(round-trip time variation)這個中間變量。
RTTVAR= (1- β) * RTTVAR + β * (|RTT - SRTT|)
β 建議值為 0.25。這個值是這個算法中出彩的地方,也就是說,它記錄了最新的 RTT 與當前 SRTT 之間的差值,給我們在后續感知到 RTT 的變化提供了抓手。
第三步: 計算最終的RTO:
RTO= μ * SRTT + ? * RTTVAR
μ建議值取1,?建議值取4。
這個公式在 SRTT 的基礎上加上了最新 RTT 與它的偏移,從而很好的感知了 RTT 的變化,這種算法下,RTO 與 RTT 變化的差值關系更加密切。
009: 能不能說一說 TCP 的流量控制?
對于發送端和接收端而言,TCP 需要把發送的數據放到發送緩存區, 將接收的數據放到接收緩存區。
而流量控制索要做的事情,就是在通過接收緩存區的大小,控制發送端的發送。如果對方的接收緩存區滿了,就不能再繼續發送了。
要具體理解流量控制,首先需要了解滑動窗口的概念。
TCP 滑動窗口
TCP 滑動窗口分為兩種:發送窗口和接收窗口。
發送窗口
發送端的滑動窗口結構如下:
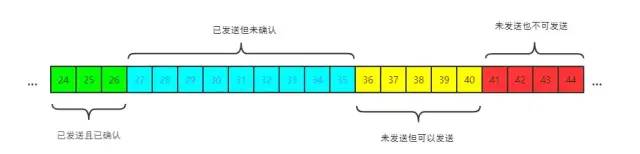
其中包含四大部分:
已發送且已確認
已發送但未確認
未發送但可以發送
未發送也不可以發送
其中有一些重要的概念,我標注在圖中:
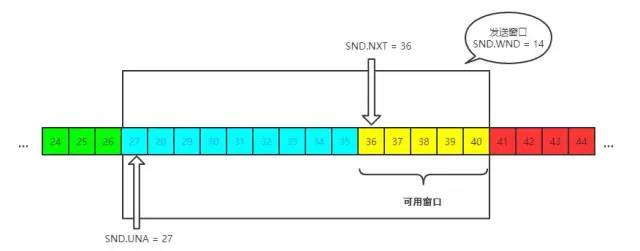
發送窗口就是圖中被框住的范圍。SND 即send, WND 即window, UNA 即unacknowledged, 表示未被確認,NXT 即next, 表示下一個發送的位置。
接收窗口
接收端的窗口結構如下:
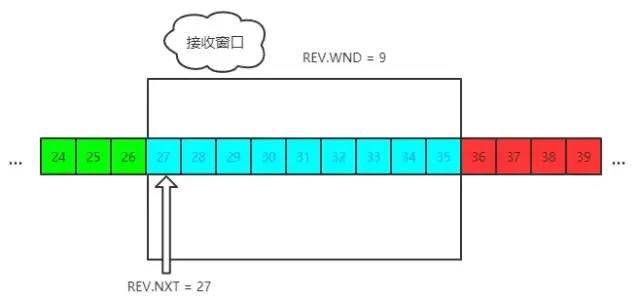
REV 即receive,NXT 表示下一個接收的位置,WND 表示接收窗口大小。
流量控制過程
這里我們不用太復雜的例子,以一個最簡單的來回來模擬一下流量控制的過程,方便大家理解。
首先雙方三次握手,初始化各自的窗口大小,均為 200 個字節。
假如當前發送端給接收端發送 100 個字節,那么此時對于發送端而言,SND.NXT 當然要右移 100 個字節,也就是說當前的可用窗口減少了 100 個字節,這很好理解。
現在這 100 個到達了接收端,被放到接收端的緩沖隊列中。不過此時由于大量負載的原因,接收端處理不了這么多字節,只能處理 40 個字節,剩下的60個字節被留在了緩沖隊列中。
注意了,此時接收端的情況是處理能力不夠用啦,你發送端給我少發點,所以此時接收端的接收窗口應該縮小,具體來說,縮小 60 個字節,由 200 個字節變成了 140 字節,因為緩沖隊列還有 60 個字節沒被應用拿走。
因此,接收端會在 ACK 的報文首部帶上縮小后的滑動窗口 140 字節,發送端對應地調整發送窗口的大小為 140 個字節。
此時對于發送端而言,已經發送且確認的部分增加 40 字節,也就是 SND.UNA 右移 40 個字節,同時發送窗口縮小為 140 個字節。
這也就是流量控制的過程。盡管回合再多,整個控制的過程和原理是一樣的。
010: 能不能說說 TCP 的擁塞控制?
上一節所說的流量控制發生在發送端跟接收端之間,并沒有考慮到整個網絡環境的影響,如果說當前網絡特別差,特別容易丟包,那么發送端就應該注意一些了。而這,也正是擁塞控制需要處理的問題。
對于擁塞控制來說,TCP 每條連接都需要維護兩個核心狀態:
擁塞窗口(Congestion Window,cwnd)
慢啟動閾值(Slow Start Threshold,ssthresh)
涉及到的算法有這幾個:
慢啟動
擁塞避免
快速重傳和快速恢復
接下來,我們就來一一拆解這些狀態和算法。首先,從擁塞窗口說起。
擁塞窗口
擁塞窗口(Congestion Window,cwnd)是指目前自己還能傳輸的數據量大小。
那么之前介紹了接收窗口的概念,兩者有什么區別呢?
接收窗口(rwnd)是接收端給的限制
擁塞窗口(cwnd)是發送端的限制
限制誰呢?
限制的是發送窗口的大小。
有了這兩個窗口,如何來計算發送窗口?
發送窗口大小 =min(rwnd, cwnd)
取兩者的較小值。而擁塞控制,就是來控制cwnd的變化。
慢啟動
剛開始進入傳輸數據的時候,你是不知道現在的網路到底是穩定還是擁堵的,如果做的太激進,發包太急,那么瘋狂丟包,造成雪崩式的網絡災難。
因此,擁塞控制首先就是要采用一種保守的算法來慢慢地適應整個網路,這種算法叫慢啟動。運作過程如下:
首先,三次握手,雙方宣告自己的接收窗口大小
雙方初始化自己的擁塞窗口(cwnd)大小
在開始傳輸的一段時間,發送端每收到一個 ACK,擁塞窗口大小加 1,也就是說,每經過一個 RTT,cwnd 翻倍。如果說初始窗口為 10,那么第一輪 10 個報文傳完且發送端收到 ACK 后,cwnd 變為 20,第二輪變為 40,第三輪變為 80,依次類推。
難道就這么無止境地翻倍下去?當然不可能。它的閾值叫做慢啟動閾值,當 cwnd 到達這個閾值之后,好比踩了下剎車,別漲了那么快了,老鐵,先 hold 住!
在到達閾值后,如何來控制 cwnd 的大小呢?
這就是擁塞避免做的事情了。
擁塞避免
原來每收到一個 ACK,cwnd 加1,現在到達閾值了,cwnd 只能加這么一點:1 / cwnd。那你仔細算算,一輪 RTT 下來,收到 cwnd 個 ACK, 那最后擁塞窗口的大小 cwnd 總共才增加 1。
也就是說,以前一個 RTT 下來,cwnd翻倍,現在cwnd只是增加 1 而已。
當然,慢啟動和擁塞避免是一起作用的,是一體的。
快速重傳和快速恢復
快速重傳
在 TCP 傳輸的過程中,如果發生了丟包,即接收端發現數據段不是按序到達的時候,接收端的處理是重復發送之前的 ACK。
比如第 5 個包丟了,即使第 6、7 個包到達的接收端,接收端也一律返回第 4 個包的 ACK。當發送端收到 3 個重復的 ACK 時,意識到丟包了,于是馬上進行重傳,不用等到一個 RTO 的時間到了才重傳。
這就是快速重傳,它解決的是是否需要重傳的問題。
選擇性重傳
那你可能會問了,既然要重傳,那么只重傳第 5 個包還是第5、6、7 個包都重傳呢?
當然第 6、7 個都已經到達了,TCP 的設計者也不傻,已經傳過去干嘛還要傳?干脆記錄一下哪些包到了,哪些沒到,針對性地重傳。
在收到發送端的報文后,接收端回復一個 ACK 報文,那么在這個報文首部的可選項中,就可以加上SACK這個屬性,通過left edge和right edge告知發送端已經收到了哪些區間的數據報。因此,即使第 5 個包丟包了,當收到第 6、7 個包之后,接收端依然會告訴發送端,這兩個包到了。剩下第 5 個包沒到,就重傳這個包。這個過程也叫做選擇性重傳(SACK,Selective Acknowledgment),它解決的是如何重傳的問題。
快速恢復
當然,發送端收到三次重復 ACK 之后,發現丟包,覺得現在的網絡已經有些擁塞了,自己會進入快速恢復階段。
在這個階段,發送端如下改變:
擁塞閾值降低為 cwnd 的一半
cwnd 的大小變為擁塞閾值
cwnd 線性增加
以上就是 TCP 擁塞控制的經典算法:慢啟動、擁塞避免、快速重傳和快速恢復。
011: 能不能說說 Nagle 算法和延遲確認?
Nagle 算法
試想一個場景,發送端不停地給接收端發很小的包,一次只發 1 個字節,那么發 1 千個字節需要發 1000 次。這種頻繁的發送是存在問題的,不光是傳輸的時延消耗,發送和確認本身也是需要耗時的,頻繁的發送接收帶來了巨大的時延。
而避免小包的頻繁發送,這就是 Nagle 算法要做的事情。
具體來說,Nagle 算法的規則如下:
當第一次發送數據時不用等待,就算是 1byte 的小包也立即發送
后面發送滿足下面條件之一就可以發了:
數據包大小達到最大段大小(Max Segment Size, 即 MSS)
之前所有包的 ACK 都已接收到
延遲確認
試想這樣一個場景,當我收到了發送端的一個包,然后在極短的時間內又接收到了第二個包,那我是一個個地回復,還是稍微等一下,把兩個包的 ACK 合并后一起回復呢?
延遲確認(delayed ack)所做的事情,就是后者,稍稍延遲,然后合并 ACK,最后才回復給發送端。TCP 要求這個延遲的時延必須小于500ms,一般操作系統實現都不會超過200ms。
不過需要主要的是,有一些場景是不能延遲確認的,收到了就要馬上回復:
接收到了大于一個 frame 的報文,且需要調整窗口大小
TCP 處于 quickack 模式(通過tcp_in_quickack_mode設置)
發現了亂序包
兩者一起使用會怎樣?
前者意味著延遲發,后者意味著延遲接收,會造成更大的延遲,產生性能問題。
012. 如何理解 TCP 的 keep-alive?
大家都聽說過 http 的keep-alive, 不過 TCP 層面也是有keep-alive機制,而且跟應用層不太一樣。
試想一個場景,當有一方因為網絡故障或者宕機導致連接失效,由于 TCP 并不是一個輪詢的協議,在下一個數據包到達之前,對端對連接失效的情況是一無所知的。
這個時候就出現了 keep-alive, 它的作用就是探測對端的連接有沒有失效。
在 Linux 下,可以這樣查看相關的配置:
sudo sysctl -a | grep keepalive // 每隔 7200 s 檢測一次 net.ipv4.tcp_keepalive_time =7200 // 一次最多重傳 9 個包 net.ipv4.tcp_keepalive_probes =9 // 每個包的間隔重傳間隔 75 s net.ipv4.tcp_keepalive_intvl =75
不過,現狀是大部分的應用并沒有默認開啟 TCP 的keep-alive選項,為什么?
站在應用的角度:
7200s 也就是兩個小時檢測一次,時間太長
時間再短一些,也難以體現其設計的初衷, 即檢測長時間的死連接
因此是一個比較尷尬的設計。
-
Linux
+關注
關注
87文章
11497瀏覽量
213262 -
TCP
+關注
關注
8文章
1401瀏覽量
80666 -
網絡通信
+關注
關注
4文章
824瀏覽量
30843 -
傳輸層
+關注
關注
0文章
31瀏覽量
11066
原文標題:建議每一位運維or網工面試前能夠刷一遍這些題目~
文章出處:【微信號:浩道linux,微信公眾號:浩道linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Linux驅動工程面試必問知識點

開關電源模塊知識點總結








 工商網監
工商網監
評論