 優于10倍參數模型!微軟發布Orca 2 LLM
優于10倍參數模型!微軟發布Orca 2 LLM

微軟發布 Orca 2 LLM,這是 Llama 2 的一個調優版本,性能與包含 10 倍參數的模型相當,甚至更好。Orca 2 使用了一個合成訓練數據集和一項稱為 Prompt Erasure(提示詞擦除) 的新技術來實現這一性能。
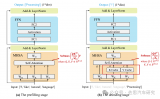
Orca 2 使用了師生模式的訓練方案,其中一個較大、較強的 LLM 作為另一個較小的 LLM(學生)的老師,老師的目標是提升學生的性能,使其與更大模型的性能相媲美。微軟的訓練技術教會較小的模型多種推理技巧,并教其如何為特定任務選擇最有效的技巧。
為此,老師被賦予了復雜的提示詞來觸發某種推理行為。不過,在一種被稱為 Prompt Erasure 的方案中,學生只得到任務要求和期望的響應,而不是老師的提示詞。在基準測試中,一個擁有 13B 參數的 Orca 2 模型的表現超過了一個 13B 參數的基準 Llama 2 模型,提升了 47.54%。而一個擁有 7B 參數的 Orca 2 模型在推理任務方面與一個擁有 70B 參數的 Llama 2 模型相當,甚至更好。
盡管像 ChatGPT 這樣的 LLM 在給定少量提示詞的情況下通常表現良好,但由于其內存和計算需求較大,托管這些模型極具有挑戰性。經過調優的較小的模型也可以表現良好,許多研究人員已經在研究使用較大 LLM 生成的合成數據集對它們進行訓練。
InfoQ 最近報道了谷歌的 Distilling Step-by-Step 方法,該方法會讓老師 LLM 自動生成一個小型的調優數據集,其中包含輸入和輸出標簽,以及為何選擇輸出標簽的“基本原理”。InfoQ 還報道了 Stability AI 的 Stable Beluga 模型,它使用微軟原始的 Orca 1 方案進行訓練,該方案使用了 Explanation Tuning,其中老師 LLM 被提示“生成詳細答案”。
與 Orca 1 類似,Orca 2 訓練數據集是由老師 LLM 生成的,而老師 LLM 收到了詳細的提示詞。然而,微軟新的訓練方法 Cautious Reasoning 將訓練任務與提示詞相結合,引導老師 LLM 使用特定的問題解決策略,如“一步一步”或“解釋你的答案”。然后在學生的訓練過程中,老師的提示詞被刪除,這促使學生學會選擇正確的策略。
為了評估這種方法,微軟將 Orca 2 模型的性能與幾個基準模型進行了比較,包括 Llama 2、ChatGPT(GPT-3.5)和 GPT-4。基準任務包括推理、語言理解、文本完成和摘要。在推理基準測試中,13B 參數 Orca 2 模型優于除 ChatGPT 和 GPT-4 之外的所有基準。他們還發現,給 Orca 2 一個“謹慎”的系統提示詞(“你是一個謹慎的助手,你會仔細遵循指示”)相比無系統提示會略微提升其性能。
有幾位用戶在 X 上發表了關于 Orca 2 的帖子。一位用戶指出:“你不需要用‘一步一步解釋’這樣的技巧來提示它。它自己知道。” AI 研究員 Rudi Ranck 寫道:
許多絕妙的想法都很簡單……就像 Orca 2 中的“提示詞擦除”一樣:完整的提示詞不會呈現給模型,而只呈現任務和答案(它過濾了生成這些答案所使用的完整提示詞)。這有助于模型在更高層次上制定策略。這是一篇非常好的論文。我強烈建議通讀全文。
審核編輯:劉清
-
ChatGPT
+關注
關注
29文章
1589瀏覽量
9030 -
LLM
+關注
關注
1文章
325瀏覽量
817
原文標題:微軟發布 Orca 2 LLM,表現優于 10 倍參數模型
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
小白學大模型:從零實現 LLM語言模型

詳解 LLM 推理模型的現狀
無法在OVMS上運行來自Meta的大型語言模型 (LLM),為什么?
字節跳動發布豆包大模型1.5 Pro
新品| LLM630 Compute Kit,AI 大語言模型推理開發平臺

小白學大模型:構建LLM的關鍵步驟
什么是LLM?LLM在自然語言處理中的應用
LLM技術的未來趨勢分析
如何訓練自己的LLM模型
新品|LLM Module,離線大語言模型模塊
理解LLM中的模型量化





 工商網監
工商網監
評論