 一種基于表征工程的生成式語言大模型人類偏好對齊策略
一種基于表征工程的生成式語言大模型人類偏好對齊策略
最近復旦大學自然語言處理組鄭驍慶和黃萱菁團隊提出了基于表征工程(Representation Engineering)的生成式語言大模型人類偏好對齊方法RAHF(如圖1所示),作為基于人類反饋的強化學習算法RLHF[1]的代替方法之一,其性能上超過其他現有的替代方案,媲美RLHF。實現較為簡單,訓練時對于硬件資源要求也相對較低。
論 文 內容
動機
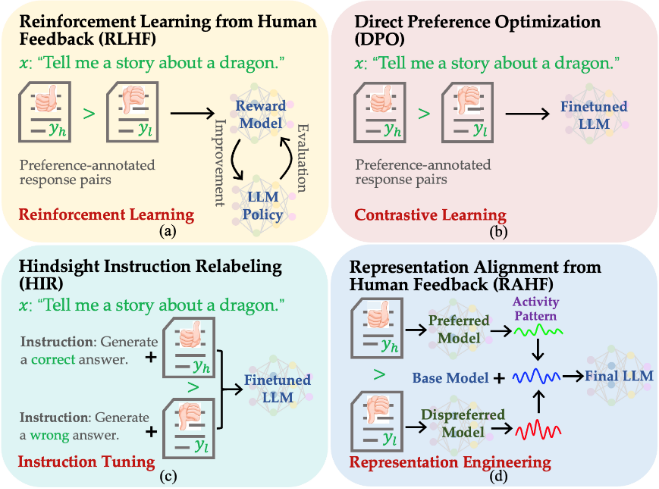
圖1.不同人類偏好對齊算法的對比。(a)人類反饋的強化學習算法RLHF;(b)基于對比學習的偏好優化方法DPO;(c)基于提示工程的HIR;(d) 基于表征工程的RAHF。
構建類似ChatGPT生成式語言大模型一般要經過語言模型、提令精調和強化學習三個主要訓練步驟,其中第三步使用強化學習來實現人類期望對齊既有一定的技術難度,又需要多次人工標注反饋,因而實現上有一定挑戰。經過前兩步語言模型和提令精調之后,語言大模型仍然會生成帶有偏見、歧視或者令人不適的回答。為了提升大模型的安全性、可用性和可信性,與人類期望對齊是必不可少的步驟。然而目前研究表明利用人類反饋的強化學習算法[1](RLHF)存在訓練不穩定、對超參數敏感和訓練代價較高等問題。
針對基于強化學習的人類偏好對齊方法的上述不足,最近提出了一些替代的方法,相關實現思路和方法包括:
(1)借助對比學習的方法[2-4],代表性工作為DPO(Direct preference optimization)[2],即提高符合人類偏好回復生成概率的同時,降低人類滿意度較低回復的生成概率;
(2)基于提示工程的方法[5-6],代表性工作為HIR(Hindsight instruction relabeling)[5],即根據與人類偏好相符程度,設計不同的提示。在推理時使用匹配人類偏好較高的提示,從而引出更好的回答。
雖然上述方法都是Reward-free的方法(即不需要訓練獎勵評估模型),但實驗表明這些替代強化學習方法存在容易受到訓練集中噪聲樣本的影響(比如:錯誤標注、Dull Sentences和較短回復等)。主要原因是它們都是采用在樣本上直接精調的方式實現與人類偏好對齊,因而易受樣本質量的影響,而基于人類反饋的強化學習算法先訓練評估模型,然后采用評估模型的評分來引導模型的訓練過程。即使訓練樣本存在的噪聲,也通過評估模型的“過濾”,對最終模型不會產生直接的影響。
方法
為了獲得輕量級、易實現和Reward-free的人類偏好對齊方法,同時也緩解最終模型受訓練樣本中噪聲數據的不利影響。受到表征工程Representation Engineering)[7]方面最新進展的啟發,我們提出了RAHF(Representation Alignment from Human Feedback)方法。在神經網絡中,網絡權重決定了隱層表征、隱層表征決定了網絡輸出、網絡輸出決定了網絡行為(如:安全、真實、偏見等方面)。我們通過首先發現模型在生成不同質量回復時網絡隱層激發模式及差異,然后利用差異來對模型行為進行調整和操控。具體方法包括以下三個主要步驟:
(1)使用帶偏好注釋的數據集來讓大型語言模型“感知”人類的偏好;
(2)收集模型在不同偏好“刺激”情況下的隱層激活模式;
(3)利用收集到的激活模式及差異來調整模型使其與與人類偏好對齊。
我們嘗試了兩種方法讓模型“感知”人類偏好:單一模型(RAHF-SCIT)和二元模型(RAHF-DualLLMs)。都取得了不錯的結果,雖然二元模型RAHF-DualLLMs性能更佳,但單一模型RAHF-SCIT實現更為簡單,對硬件資源的要求也更低。
結果
我們在對話任務上對進行了對比實驗。實驗結果表明所提出的RAHF人類偏好對齊方法在各項指標上都優于其他非強化學習方法,并取得了與RLHF-PPO相媲美的結果。如表1所示,在Anthropic-HH數據集上相對于首選回復的勝率(結果使用GPT-4進行評判),我們所提出的RAHF-DualLLMs超過了除RLHF-PPO之外的所有代替方法,并且與RLHF-PPO僅有0.01的差距。表2報告了在不同生成采樣溫度下,偏好注釋數據上我們自己所訓練的獎勵模型(Reward model)和第三方提供的獎勵模型上的各方法的平均得分比較,這些數據也與表1的結果相吻合,并且表現出相似的趨勢。
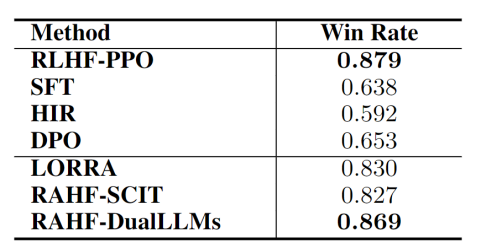
表1. 在Anthropic-HH數據集上相對于首選回復的勝率(結果使用GPT-4進行評判)。
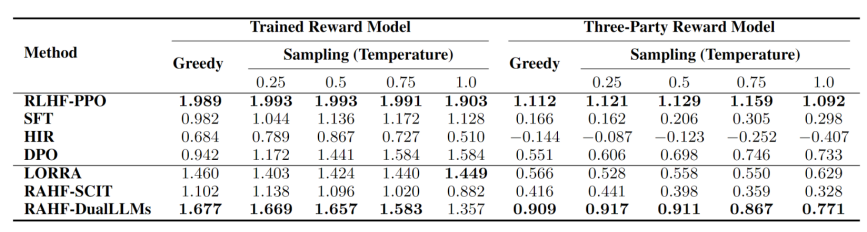
表2. 在不同生成采樣溫度下,偏好注釋數據上所訓練的獎勵模型(Reward model)和第三方提供的獎勵模型上的各方法的平均得分比較。
這項工作我們嘗試了一種受認知神經科學理論啟發的基于表征工程來實現生成式語言大模型與人類偏好對齊的策略,旨在提出一種輕量級和易實現的解決方案。目前仍然還有許多可改進的空間,我們希望這項研究能夠有助于更可控人工智能技術的發展。
審核編輯:劉清
-
自然語言處理
+關注
關注
1文章
628瀏覽量
14041
原文標題:基于表征工程的生成式語言大模型人類偏好對齊
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的應用
大語言模型:原理與工程時間+小白初識大語言模型
一種基于策略元素三元組的策略描述語言
一種基于用戶偏好的權重搜索及告警選擇方法

LLMs實際上在假對齊!

2024 年 19 種最佳大型語言模型







 工商網監
工商網監
評論