 動態環境中基于神經隱式表示的RGB-D SLAM
動態環境中基于神經隱式表示的RGB-D SLAM
1. 原文摘要
神經隱式表示已經被探索用于增強視覺SLAM掩碼算法,特別是在提供高保真的密集地圖方面。現有的方法在靜態場景中表現出強大的魯棒性,但卻難以應對移動物體造成的干擾。在本文中,我們提出了NID-SLAM,它顯著地提高了神經SLAM掩碼在動態環境中的性能。我們提出了一種新的方法來增強語義掩碼中不準確的區域,特別是在邊緣區域。利用深度圖像中存在的幾何信息,這種方法能夠準確地移除動態物體,從而降低了相機漂移的概率。此外,我們還引入了一種針對動態場景的關鍵幀選擇策略,它提高了相機跟蹤對大尺度物體的魯棒性,并提高了建圖的效率。在公開的RGB-D數據集上的實驗表明,我們的方法在跟蹤精度和建圖質量方面優于競爭的神經SLAM方法。

圖1. NID-SLAM在我們采集的大型動態場景上的三維重建結果。
2. 方法提出
視覺同時定位與地圖建構(SLAM)在各種應用中發揮著關鍵作用,如機器人導航、增強現實(AR)和虛擬現實(VR)。視覺SLAM算法利用傳感器(如單目、立體和RGB-D相機)收集的數據來估計先前未知環境中相機的姿態,并逐步構建周圍場景的地圖。在各種視覺傳感器中,RGB-D相機同時記錄顏色和深度數據,為三維環境信息的獲取提供了更有效和精確的基礎。這增強了大多數SLAM算法的三維重建性能。
最近的方法已經將神經隱式表示引入到SLAM中。最典型的例子就是神經輻射場(NeRF),它將場景顏色和體素密度編碼到神經網絡的權重中,直接從數據中學習場景細節的高頻信息,極大地增強了建圖的平滑性和連續性。結合基于體積表示的渲染方法,通過訓練,NeRF可以重新合成輸入圖像,并推廣到相鄰未見的視點。
但是,這些神經SLAM算法是基于靜態環境的假設,其中一些可以處理合成場景中的小動態物體。在真實的動態場景中,這些算法可能會由于動態物體的存在而在稠密重建和相機跟蹤精度方面出現顯著的性能下降。這可能在很大程度上是由于動態物體導致的數據關聯不正確,嚴重破壞了跟蹤過程中的姿態估計。此外,動態物體的信息通常會合并到地圖中,妨礙其長期適用性。
語義信息已經在許多研究中被引入到動態場景中的視覺SLAM算法中。其主要思想是將語義信息與幾何約束相結合以消除場景中的動態物體。然而,一方面,由于場景中靜態信息的減少,這些算法中的地圖質量和內在聯系較差。另一方面,由于缺乏對未觀測區域的合理幾何預測能力,這些算法通常存在恢復背景中可觀的空洞。
為了解決這個問題,我們提出了神經隱式動態SLAM(NID-SLAM)。我們整合精度提高的深度信息與語義分割以檢測和移除動態物體,并通過將靜態地圖投影到當前幀中以填補這些物體遮擋的背景。
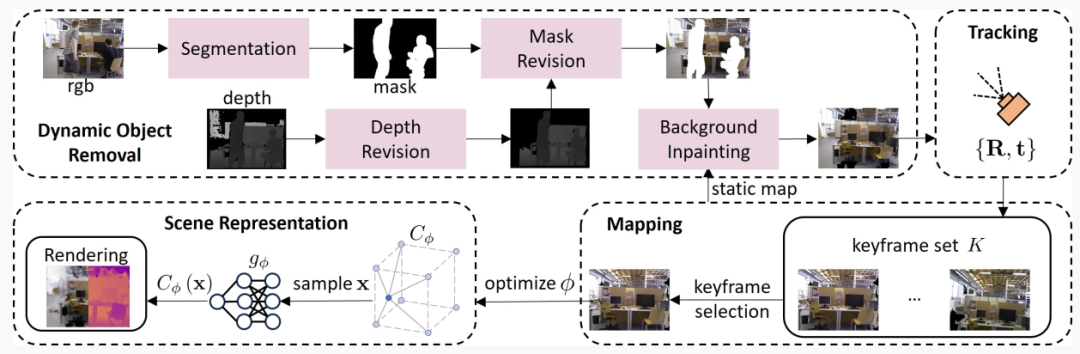
圖2. 系統概覽。1) 動態物體移除:通過使用語義分割和掩碼修正,精確地消除RGB-D圖像中的動態物體,然后徹底恢復被遮擋的背景。2) 跟蹤:通過最小化損失來優化相機姿態{R, t}。3) 建圖:采用基于掩碼的策略來選擇關鍵幀,用于優化特征網格場景表示。4) 場景表示:通過表面聚焦的點采樣,實現預測的顏色和深度值的高效渲染。
3. 方法詳解
圖2展示了NID-SLAM的總體框架。給定RGB-D圖像流作為輸入,我們首先使用專門的動態處理過程移除動態物體。隨后,我們通過聯合優化相機姿勢和神經場景表示來完成跟蹤和建圖。利用語義先驗和深度信息,消除動態物體,并通過靜態地圖修復這些物體遮擋的背景。在每次建圖迭代中,選擇關鍵幀以優化場景表示和相機姿態。渲染是通過對查看射線進行采樣并在這些射線上各點處集成預測值來執行的。
3.1 動態物體移除
深度修正:由于深度相機的局限性,物體與相機之間距離增加時的深度估計精度會降低。存在顯著誤差的深度信息可能導致不正確的數據關聯,破壞相機跟蹤的穩定性。在高度動態環境中,這些不準確性變得更加明顯,增加相機漂移的概率。此外,由于深度信息中的錯誤,構建的地圖可能會出現分層現象,其中本應位于相同深度的圖像塊在地圖上表示為不同深度。因此,我們檢測并刪除不準確的深度信息。具體來說,我們計算深度圖的圖像梯度,并將這些梯度用作評估深度信息準確性的指標。當圖像的水平或垂直梯度超過預定義閾值時,說明深度存在顯著變化,我們將梯度方向上后續像素點的深度設置為零,以減輕深度誤差。
基于深度的語義分割:為了檢測動態物體,我們采用基于邊界框的網絡進行輸入圖像的語義分割,在我們的實驗中使用YOLO算法。該網絡以RGB原始圖像為輸入,并輸出圖像中潛在動態或可移動物體的二進制掩碼。語義掩碼存在兩個主要缺點。首先,它們可能無法完全覆蓋動態物體,有時會并入環境中的其他物體。其次,掩碼在邊界區域容易出錯。因此,我們利用深度信息細化掩碼。對于原始掩碼的每個邊界點,我們檢查以其為中心的五像素半徑區域,計算該區域內掩碼中像素的深度值范圍。對于此區域內的掩碼部分,我們計算所有像素的深度值范圍。對于此區域外掩碼的像素,其深度值在計算的范圍內的像素被認為是掩碼的一部分,并隨后被整合。
背景修復:對于移除的動態物體,我們使用從以前的視點獲得的靜態信息來修復被遮擋的背景,合成一個沒有動態物體的逼真圖像。修復后的圖像包含更多的場景信息,使地圖的外觀更準確,增強了相機跟蹤的穩定性。利用先前幀和當前幀的已知位置,我們將一系列先前關鍵幀投影到當前幀的RGB和深度圖像的分割區域。由于這些區域要么尚未出現在場景中,要么已經出現但沒有有效的深度信息,因此仍有一些區域保留未填充。圖1展示了我們自制數據集中用作輸入的三幀和最終重建的場景。可以注意到,動態物體被成功刪除,大多數分割部分修復良好。
3.2 基于掩碼的關鍵幀選擇
對于跟蹤的輸入幀,我們選擇一組關鍵幀,表示為K。我們對關鍵幀的偏好傾向于:1) 動態物體比率較低的幀;2)與前一關鍵幀重疊率較低的幀。我們使用 和 分別表示輸入幀I的兩個比率。當這兩個比率之和小于閾值 時,我們將當前幀插入關鍵幀集。為了解決背景修復中的不準確性和遺漏信息,我們減少關鍵幀中的動態物體比例。這種方法確保整合更多可靠的信息,增強相機跟蹤的準確性和穩定性。同時,關鍵幀之間的重疊更小可以使關鍵幀集包含更多場景信息。在靜態場景中,此策略默認為基于重疊比的選擇。
從K中選擇關鍵幀以優化場景表示時,我們在基于覆蓋的和基于重疊的策略之間交替,旨在在優化效率和質量之間取得平衡。基于覆蓋的策略傾向于覆蓋最大場景區域的幀,確保場景邊緣區域的全面優化。但是,這種方法通常需要大量迭代才能優化相對較小的邊緣區域,降低了整體優化效率。它還會導致重復的選擇結果,因為幀的覆蓋面積是恒定的,覆蓋面積大的幀保持更高的優先級。基于重疊的策略涉及從與當前幀視覺上重疊的關鍵幀中隨機選擇。為避免過度關注邊緣區域并反復優化相同區域,我們首先使用基于覆蓋的策略優化整個場景,然后多次使用基于重疊的策略,定期重復此過程。
3.3 場景表示和圖像渲染

3.4 建圖和跟蹤

4. 實驗
本方法在公開的RGB-D數據集上進行了實驗,包括TUM RGB-D數據集和Replica數據集,并與現有的方法進行了比較。實驗結果表明,該方法在動態環境中的跟蹤精度和建圖質量方面都優于其他的神經SLAM方法。

表1. TUM RGB-D數據集上的相機跟蹤結果。評估指標為ATE RMSE。 代表相應文獻中沒有提到對應的數值。
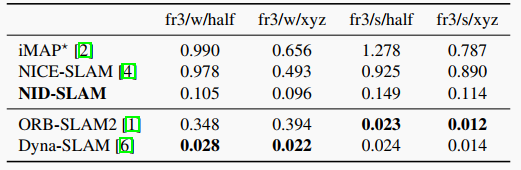
表2. TUM數據集上的平移RPE RMSE結果。
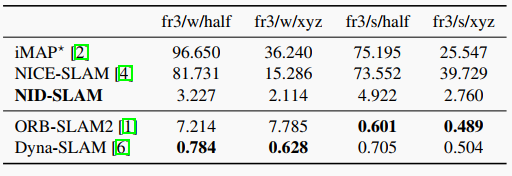
表3. TUM數據集上的旋轉RPE RMSE結果。

圖3. TUM RGB-D數據集上的重建結果。紅框標出有動態物體的區域。

圖4. Replica數據集上的重建結果。紅框標出改進的區域。
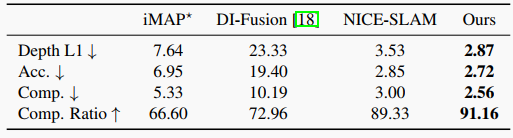
表4. Replica數據集上的重建結果(8個場景的平均值)。
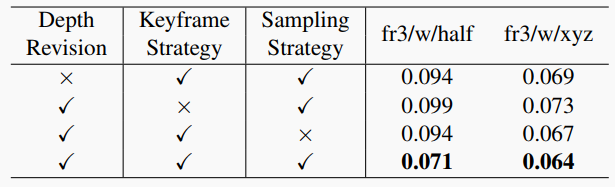
表5. 消融實驗結果。
5. 結論
我們介紹了NID-SLAM,這是一種動態RGB-D神經SLAM方法。我們證明神經SLAM能夠在動態場景中實現高質量的建圖和可信的孔填充。利用動態物體移除,我們的方法實現了穩定的相機跟蹤并創建可重復使用的靜態地圖。準確獲得的無動態物體圖像也可以在進一步的應用中使用,如機器人導航。
審核編輯:劉清
-
機器人
+關注
關注
213文章
29533瀏覽量
211736 -
RGB
+關注
關注
4文章
804瀏覽量
59649 -
編解碼器
+關注
關注
0文章
272瀏覽量
24666 -
SLAM
+關注
關注
24文章
436瀏覽量
32355 -
MLP
+關注
關注
0文章
57瀏覽量
4504
原文標題:NID-SLAM:動態環境中基于神經隱式表示的RGB-D SLAM
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于動態環境中的魯棒BA和選擇性全局優化的魯棒VI-SLAM框架
如何去開發一款基于RGB-D相機與機械臂的三維重建無序抓取系統
基于RGB-D圖像物體識別方法
基于UWB、里程計和RGB-D融合的室內定位方法
用于SLAM的神經隱含可擴展編碼
用于快速高保真RGB-D表面重建的神經特征網格優化的GO-Surf
基于RGB-D相機的三維重建和傳統SFM和SLAM算法有什么區別?
瞄準AGV/AMR領域-維感科技發布高性價比RGB-D ToF相機DS86/87

一種基于RGB-D圖像序列的協同隱式神經同步定位與建圖(SLAM)系統
常用的RGB-D SLAM解決方案
一種適用于動態環境的3DGS-SLAM系統






 工商網監
工商網監
評論