") 深度學(xué)習(xí)在時(shí)間序列預(yù)測的總結(jié)和未來方向分析
深度學(xué)習(xí)在時(shí)間序列預(yù)測的總結(jié)和未來方向分析
來源:DeepHub IMBA
2023年是大語言模型和穩(wěn)定擴(kuò)散的一年,時(shí)間序列領(lǐng)域雖然沒有那么大的成就,但是卻有緩慢而穩(wěn)定的進(jìn)展。Neurips、ICML和AAAI等會議都有transformer 結(jié)構(gòu)(BasisFormer、Crossformer、Inverted transformer和Patch transformer)的改進(jìn),還出現(xiàn)了將數(shù)值時(shí)間序列數(shù)據(jù)與文本和圖像合成的新體系結(jié)構(gòu)(CrossVIVIT), 也出現(xiàn)了直接應(yīng)用于時(shí)間序列的可能性的LLM,以及新形式的時(shí)間序列正則化/規(guī)范化技術(shù)(san)。
我們這篇文章就來總結(jié)下2023年深度學(xué)習(xí)在時(shí)間序列預(yù)測中的發(fā)展和2024年未來方向分析
Neurips 2023
在今年的NIPs上,有一些關(guān)于transformer 、歸一化、平穩(wěn)性和多模態(tài)學(xué)習(xí)的有趣的新論文。但是在時(shí)間序列領(lǐng)域沒有任何重大突破,只有一些實(shí)際的,漸進(jìn)的性能改進(jìn)和有趣的概念證明。1、Adaptive Normalization for Non-stationary Time Series
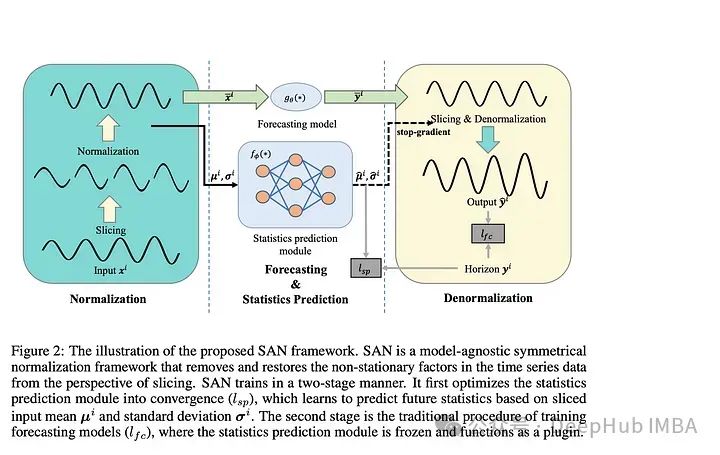
論文介紹了一種“模型不可知的歸一化框架”來簡化非平穩(wěn)時(shí)間序列數(shù)據(jù)的預(yù)測。作者讓SAN分兩步操作:訓(xùn)練一個(gè)統(tǒng)計(jì)預(yù)測模型(通常是ARIMA),然后訓(xùn)練實(shí)際的深度時(shí)間序列基礎(chǔ)模型(使用統(tǒng)計(jì)模型對TS數(shù)據(jù)進(jìn)行切片、歸一化和反歸一化)。統(tǒng)計(jì)模型對輸入時(shí)間序列進(jìn)行切片,以便學(xué)習(xí)更健壯的時(shí)間序列表示并去除非平穩(wěn)屬性。作者指出:“通過對切片級特性進(jìn)行建模,SAN能夠消除局部區(qū)域的非平穩(wěn)性。”SAN還顯式地預(yù)測目標(biāo)窗口的統(tǒng)計(jì)信息(標(biāo)準(zhǔn)差/平均值)。這使得它在處理非平穩(wěn)數(shù)據(jù)時(shí),與普通模型相比,能夠更好地適應(yīng)隨時(shí)間的變化。采用transformer 模型作為基本預(yù)測模型,對典型的時(shí)間序列預(yù)測基準(zhǔn)(如電力、交換、交通等)進(jìn)行指標(biāo)驗(yàn)證。作者發(fā)現(xiàn)SAN在這些基準(zhǔn)數(shù)據(jù)集上持續(xù)提高了基本模型的性能(盡管他們沒有測試Inverted Transformer,因?yàn)檫@篇論文是在Inverted Transformer之前發(fā)布的)。由于該模型結(jié)合了一個(gè)統(tǒng)計(jì)模型(通常是ARIMA)和一個(gè)普通的transformer ,我認(rèn)為調(diào)優(yōu)和調(diào)試(特別是在新的數(shù)據(jù)集上)可能會很棘手和麻煩。因?yàn)閹缀跛械臅r(shí)間序列模型都將序列輸入長度作為超參數(shù)。另外就是“切片”的切片與普通的序列窗口有何不同?作者還是沒有說清楚。總的來說,我認(rèn)為這仍然是一個(gè)相當(dāng)強(qiáng)大的貢獻(xiàn),因?yàn)樗膶?shí)驗(yàn)結(jié)果和即插即用屬性。2、BasisFormer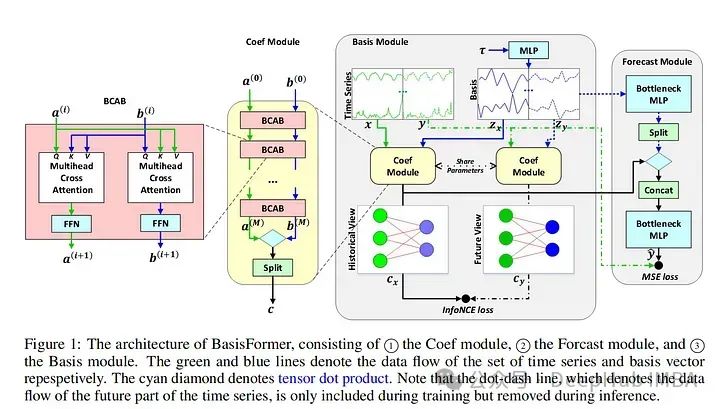 BasisFormer使用可學(xué)習(xí)和可解釋的“basis”來改進(jìn)一般的transformer 體系結(jié)構(gòu)。這里的“basis”指的是創(chuàng)建一個(gè)類似于NBeats的神經(jīng)“basis”(例如,為基于多項(xiàng)式的函數(shù)學(xué)習(xí)趨勢、季節(jié)性等的系數(shù))。該模型分為三個(gè)部分:基礎(chǔ)模塊、系數(shù)模塊和預(yù)測模塊。基模塊試圖以自監(jiān)督的方式確定一組適用于歷史和未來時(shí)間序列數(shù)據(jù)的數(shù)據(jù)基礎(chǔ)趨勢。basis模塊通過對比學(xué)習(xí)和一個(gè)名為InfoNCE loss的特定損失函數(shù)(該函數(shù)試圖學(xué)習(xí)未來和過去時(shí)間序列之間的聯(lián)系)。coef模型試圖“模擬時(shí)間序列和一組基礎(chǔ)趨勢之間的相似性”。對于coef模型,作者使用了一個(gè)交叉注意力模塊,該模塊將basis和時(shí)間序列作為輸入。然后將輸出輸入到包含多個(gè)MLP的預(yù)測模塊中。作者在典型的時(shí)間序列預(yù)測數(shù)據(jù)集(ETH1, ETH, weather, exchange)上評估他們的論文。發(fā)現(xiàn)BasisFormer比其他模型(Fedformer、Informer等)的性能提高了11-15%。BasisFormer還沒有被拿來和Inverted Transformer比較,因?yàn)樗€沒有發(fā)布。似乎Inverted Transformer和可能的Crossformer 可能會略優(yōu)于BasisFormer。還記的去年我們看到了“Are Transformers Effective for Time Series Forecasting?”這篇論文批評了許多Transformers 模型,并展示了一個(gè)簡單的模型“D-Linear”如何超越它們。在2023年從BasisFromer開始,已經(jīng)開始緩慢的解決這些問題,并超越上面提到的基準(zhǔn)模型。這篇論文模型的技術(shù)是可靠的,但這篇論文優(yōu)點(diǎn)難理解。因?yàn)樽髡呓榻B了學(xué)習(xí)“basis”的概念,但并沒有真正解釋這種方法的新穎性以及它與其他模型的不同之處。
BasisFormer使用可學(xué)習(xí)和可解釋的“basis”來改進(jìn)一般的transformer 體系結(jié)構(gòu)。這里的“basis”指的是創(chuàng)建一個(gè)類似于NBeats的神經(jīng)“basis”(例如,為基于多項(xiàng)式的函數(shù)學(xué)習(xí)趨勢、季節(jié)性等的系數(shù))。該模型分為三個(gè)部分:基礎(chǔ)模塊、系數(shù)模塊和預(yù)測模塊。基模塊試圖以自監(jiān)督的方式確定一組適用于歷史和未來時(shí)間序列數(shù)據(jù)的數(shù)據(jù)基礎(chǔ)趨勢。basis模塊通過對比學(xué)習(xí)和一個(gè)名為InfoNCE loss的特定損失函數(shù)(該函數(shù)試圖學(xué)習(xí)未來和過去時(shí)間序列之間的聯(lián)系)。coef模型試圖“模擬時(shí)間序列和一組基礎(chǔ)趨勢之間的相似性”。對于coef模型,作者使用了一個(gè)交叉注意力模塊,該模塊將basis和時(shí)間序列作為輸入。然后將輸出輸入到包含多個(gè)MLP的預(yù)測模塊中。作者在典型的時(shí)間序列預(yù)測數(shù)據(jù)集(ETH1, ETH, weather, exchange)上評估他們的論文。發(fā)現(xiàn)BasisFormer比其他模型(Fedformer、Informer等)的性能提高了11-15%。BasisFormer還沒有被拿來和Inverted Transformer比較,因?yàn)樗€沒有發(fā)布。似乎Inverted Transformer和可能的Crossformer 可能會略優(yōu)于BasisFormer。還記的去年我們看到了“Are Transformers Effective for Time Series Forecasting?”這篇論文批評了許多Transformers 模型,并展示了一個(gè)簡單的模型“D-Linear”如何超越它們。在2023年從BasisFromer開始,已經(jīng)開始緩慢的解決這些問題,并超越上面提到的基準(zhǔn)模型。這篇論文模型的技術(shù)是可靠的,但這篇論文優(yōu)點(diǎn)難理解。因?yàn)樽髡呓榻B了學(xué)習(xí)“basis”的概念,但并沒有真正解釋這種方法的新穎性以及它與其他模型的不同之處。
3、Improving day-ahead Solar Irradiance Time Series Forecasting by Leveraging Spatio-Temporal Context論文提出了一種基于混合(視覺和時(shí)間序列)深度學(xué)習(xí)的架構(gòu),用于預(yù)測第二天的太陽能產(chǎn)量。太陽能的生產(chǎn)經(jīng)常受到云層覆蓋的影響,這在衛(wèi)星圖像數(shù)據(jù)中可以看到,但在數(shù)值數(shù)據(jù)中沒有很好地體現(xiàn)出來。除了模型本身外,論文的另外貢獻(xiàn)是研究人員構(gòu)建并開源的多模態(tài)衛(wèi)星圖像數(shù)據(jù)集。作者描述了一個(gè)多級Transformers 架構(gòu),同時(shí)關(guān)注數(shù)值時(shí)間序列和圖像數(shù)據(jù)。時(shí)間序列數(shù)據(jù)通過時(shí)間Transformers 圖像通過視覺Transformers 。然后,交叉注意力模塊將前兩個(gè)模塊的圖像數(shù)據(jù)綜合起來。最后數(shù)據(jù)進(jìn)入一個(gè)輸出預(yù)測的最終時(shí)態(tài)Transformers 。作者在論文中提到的另一個(gè)有用的想法被稱為ROPE或旋轉(zhuǎn)位置編碼。這將在編碼/位置嵌入中創(chuàng)建坐標(biāo)對。這是用來描述從云層到太陽能站的距離。作者對他們的新數(shù)據(jù)集進(jìn)行評估和基準(zhǔn)測試,比較了Informer、Reformer、Crossformer和其他深度時(shí)間序列模型的性能。作者還在整合圖像數(shù)據(jù)方面區(qū)分了困難和容易的任務(wù),他們的方法優(yōu)于其他模型。這篇論文提供了一個(gè)有趣的框架,ROPE的概念也很有趣,對于任何使用坐標(biāo)形式的地理數(shù)據(jù)的人都有潛在的幫助。數(shù)據(jù)集本身對于多模態(tài)預(yù)測的持續(xù)工作非常有用,這是一項(xiàng)非常有益的貢獻(xiàn)。
4、Large Language Models Are Zero-Shot Time Series Forecasters這篇論文探討了預(yù)訓(xùn)練的llm能否直接以整數(shù)形式輸入時(shí)間序列數(shù)據(jù),并以零樣本的方式預(yù)測未來數(shù)據(jù)。作者描述了使用GPT-3和GPT-4和開源LLMs不進(jìn)一步修改結(jié)構(gòu)直接與時(shí)間序列值交互的情況。最后還描述了他們對模型零樣本訓(xùn)練行為起源的思考。作者假設(shè),這種行為是提取知識的預(yù)訓(xùn)練的普遍通用性的結(jié)果。在上面提到的標(biāo)準(zhǔn)時(shí)間序列基準(zhǔn)數(shù)據(jù)集評估他們的模型。雖然模型沒有達(dá)到SOTA性能,但考慮到它完全是零樣本并且沒有額外的微調(diào),所以表現(xiàn)還是很好的。
llm可以開箱即用地進(jìn)行TS預(yù)測,因?yàn)樗鼈兌际窃谖谋緮?shù)據(jù)上訓(xùn)練的。這一領(lǐng)域可能值得未來進(jìn)一步探索,這篇論文是一個(gè)很好的一步。但是該模型目前只能處理單變量時(shí)間序列
ICML 、ICLR 2023
除了Neurips之外,ICML和ICLR 2023還重點(diǎn)介紹了幾篇關(guān)于時(shí)間序列預(yù)測/分析的深度學(xué)習(xí)的論文。以下是一些我覺得很有趣的,并且對未來一年仍有意義的建議:1、Crossformer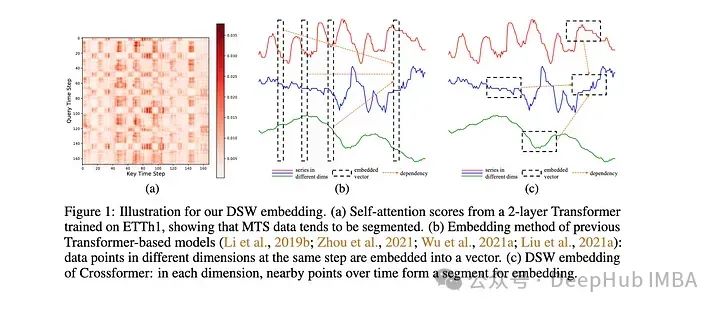
該模型是專門為多元時(shí)間序列預(yù)測(MTS)開發(fā)的。該模型采用維度分段嵌入(DSW)機(jī)制。DSW嵌入與傳統(tǒng)嵌入的不同之處在于它采用二維格式的數(shù)據(jù)。并且跨變量和時(shí)間維度顯式地從MTS數(shù)據(jù)生成段。該模型在標(biāo)準(zhǔn)MTS數(shù)據(jù)集(ETH, exchange等)上進(jìn)行了評估:在發(fā)布時(shí)時(shí)優(yōu)于大多數(shù)其他模型,例如Informer和DLinear。作者還對dSW進(jìn)行了消融研究。這篇來自ICLR的關(guān)于的論文在預(yù)測河流流量時(shí)表現(xiàn)不錯(cuò),但是是在一次預(yù)測多個(gè)目標(biāo)時(shí),性能似乎會下降很多。也就是說,它的表現(xiàn)肯定比Informer和相關(guān)的Transformers 模型要好。
2、Learning Perturbations to Explain Time Series Predictions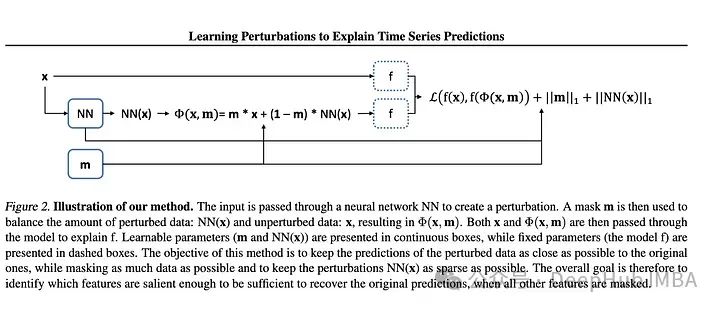
大多數(shù)用于深度學(xué)習(xí)解釋的擾動(dòng)技術(shù)都是面向靜態(tài)數(shù)據(jù)(圖像和文本)的。但是對于時(shí)間序列特別是多元TS需要更大范圍的擾動(dòng)來學(xué)習(xí)隨機(jī)影響。作者提出了一種基于深度學(xué)習(xí)的方法,可以學(xué)習(xí)數(shù)據(jù)的掩碼和相關(guān)的擾動(dòng),更好地解釋特征的重要性。然后將掩碼和擾動(dòng)的輸入傳遞給模型,并將輸出與未擾動(dòng)數(shù)據(jù)的輸出進(jìn)行比較。據(jù)兩個(gè)輸出之間的差值計(jì)算損失。越來越多的研究人員正在深入研究解釋深度學(xué)習(xí)模型這是件好事。本文概述了現(xiàn)有的方法及其不足,并提出了一種改進(jìn)的方法。我認(rèn)為使用額外的神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)擾動(dòng)的想法增加了不必要的復(fù)雜性,因?yàn)槊慨?dāng)我們增加更多的層和額外的網(wǎng)絡(luò)時(shí),就會增加發(fā)生問題的概率,特別是在已經(jīng)很大的網(wǎng)絡(luò)上。別忘了奧卡姆剃刀定律如無必要,勿增實(shí)體
3、Learning Deep Time Index Models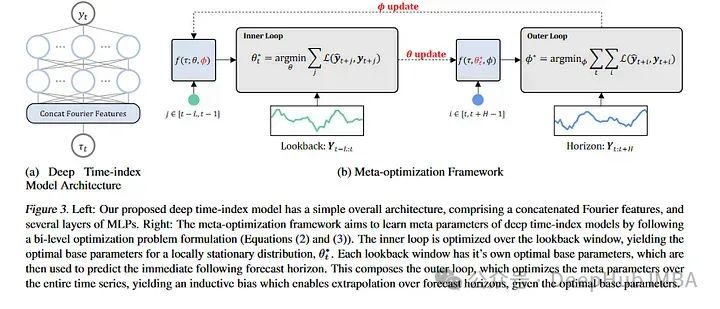
本文通過光流和元學(xué)習(xí)來討論預(yù)測,描述了學(xué)習(xí)如何預(yù)測非平穩(wěn)時(shí)間序列。對于那些不熟悉的人來說,元學(xué)習(xí)通常被應(yīng)用在計(jì)算機(jī)視覺數(shù)據(jù)集上,像MAML這樣的論文可以對新的圖像類進(jìn)行少量的學(xué)習(xí)。MAML和其他模型都有一個(gè)內(nèi)部循環(huán)和一個(gè)外部循環(huán),其中外部循環(huán)教模型如何學(xué)習(xí),內(nèi)部循環(huán)對其進(jìn)行微調(diào)以適應(yīng)特定的任務(wù)。論文的作者采用了這一思想,并將其應(yīng)用于幾乎將每個(gè)非平穩(wěn)性視為一個(gè)新的學(xué)習(xí)任務(wù)。新的“任務(wù)”是長時(shí)間序列序列的塊。作者在ETH,temperature和exchange 數(shù)據(jù)集上測試了他們的模型。盡管他們的模型沒有達(dá)到SOTA的結(jié)果,但它與當(dāng)前的SOTA體系結(jié)構(gòu)具有競爭力。這篇論文為時(shí)間序列預(yù)測提供了一個(gè)有趣的角度,相對于常規(guī)方法有了一個(gè)新的突破,我想就是他雖然沒有超過SOTA但是還是被錄用的原因之一吧。
4、Inverted Transformers are Effective for Time Series Forecasting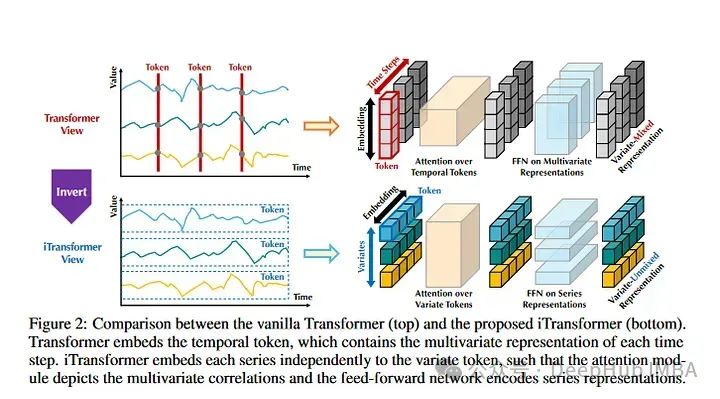
《Inverted Transformers》是2024年發(fā)表的一篇論文。這也是目前時(shí)間序列預(yù)測數(shù)據(jù)集上的SOTA。基本上,Inverted Transformers采用時(shí)間序列的Transformers架構(gòu)并進(jìn)行了翻轉(zhuǎn)。整個(gè)時(shí)間序列序列用于創(chuàng)建令牌。然后,時(shí)間序列彼此獨(dú)立進(jìn)行嵌入表示。注意力對多個(gè)時(shí)間序列嵌入進(jìn)行操作。它有點(diǎn)類似于Crossformer,但它的不同之處在于,它遵循標(biāo)準(zhǔn)Transformers架構(gòu)。作者在標(biāo)準(zhǔn)時(shí)間序列數(shù)據(jù)集上評估模型目前優(yōu)于所有其他模型,包括Informer, Reformer, Crossformer等。
這是一篇強(qiáng)大的論文,因?yàn)槟P偷谋憩F(xiàn)優(yōu)于現(xiàn)有的模型。但是在某些情況下,它優(yōu)于模型的數(shù)值并不是那么顯著。所以可以優(yōu)先看看這篇論文并且進(jìn)行測試。
TimeGPT
最后說說TimeGPT,它沒有在任何主要會議上被接受,而且它的評估方法也優(yōu)點(diǎn)可疑,由于它不幸地在互聯(lián)網(wǎng)上獲得了相當(dāng)多的介紹,所以我們要再提一下:
1、作者沒有將他們的結(jié)果與其他SOTA類型模型進(jìn)行比較,只是引用“測試集包括來自多個(gè)領(lǐng)域的30多萬個(gè)時(shí)間序列,包括金融、網(wǎng)絡(luò)流量、物聯(lián)網(wǎng)、天氣、需求和電力。”并且沒有提供測試集的鏈接,也沒有在他們的論文中說明這些數(shù)據(jù)集是什么。
2、論文中架構(gòu)圖和模型體系結(jié)構(gòu)的描述非常糟糕。這看起來就像是作者復(fù)制了其他論文的圖表,強(qiáng)加上注意力的定義和LLM相關(guān)的流行詞匯。
3、作者的Nixtla公司非常小,可能是一家小型初創(chuàng)公司,它是否有足夠的計(jì)算資源來完全訓(xùn)練一個(gè)“成功的時(shí)間序列基礎(chǔ)模型”。雖然這樣說法優(yōu)點(diǎn)歧視,但是如果我說我一個(gè)人用一周訓(xùn)練了一個(gè)LLM,那估計(jì)都沒人相信,對吧。OpenAI、谷歌、亞馬遜、Meta等公司提供足夠的計(jì)算資源來創(chuàng)建龐大的模型。如果TimeGPT真的是一個(gè)簡單的Transformers 模型,并在大量的時(shí)間序列數(shù)據(jù)上訓(xùn)練它,為什么其他機(jī)構(gòu),甚至個(gè)人不能用它的大量gpu做到這一點(diǎn)呢?答案是,事情肯定沒那么簡單。時(shí)間序列創(chuàng)建“基礎(chǔ)模型”的能力目前還不夠完善。多元時(shí)間序列預(yù)測的一個(gè)重要組成部分是學(xué)習(xí)協(xié)變量之間的依賴關(guān)系。MTS的維度在不同的數(shù)據(jù)集之間差異很大。對于具有文本數(shù)據(jù)的Transformers ,我們總是將一個(gè)單詞映射到一個(gè)數(shù)字id,然后創(chuàng)建一個(gè)特定維度的嵌入。對于MTS,不僅值可以更改,而且在一個(gè)數(shù)據(jù)集上可能有100個(gè)變量,而在另一個(gè)數(shù)據(jù)集上只有10個(gè)變量。這使得幾乎不可能設(shè)計(jì)所有用途的映射層來將不同大小的MTS數(shù)據(jù)集映射到公共嵌入維度。所以還記得我們前幾天發(fā)的Lag-Llama,也只是單變量的預(yù)測。
在其他時(shí)間序列(即使是那些具有相同數(shù)量變量的時(shí)間序列)上預(yù)訓(xùn)模型不會產(chǎn)生改進(jìn)的結(jié)果(至少在當(dāng)前架構(gòu)下不會)。
總結(jié)及未來方向分析
在2023年,我們看到了Transformers 在時(shí)間序列預(yù)測中的一些持續(xù)改進(jìn),以及l(fā)lm和多模態(tài)學(xué)習(xí)的新方法。隨著2024年的進(jìn)展,我們將繼續(xù)看到在時(shí)間序列中使用Transformers 架構(gòu)的進(jìn)步和改進(jìn)。可能會看到在多模態(tài)時(shí)間序列預(yù)測和分類領(lǐng)域的進(jìn)一步發(fā)展。
作者:Isaac Godfried
-
AI
+關(guān)注
關(guān)注
88文章
34520瀏覽量
276031 -
語言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10703 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122565
發(fā)布評論請先 登錄
使用BP神經(jīng)網(wǎng)絡(luò)進(jìn)行時(shí)間序列預(yù)測
時(shí)空引導(dǎo)下的時(shí)間序列自監(jiān)督學(xué)習(xí)框架






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論