") 佐思汽研發(fā)布《2024年端到端自動(dòng)駕駛研究報(bào)告》
佐思汽研發(fā)布《2024年端到端自動(dòng)駕駛研究報(bào)告》
佐思汽研發(fā)布《2024年端到端自動(dòng)駕駛研究報(bào)告》。
1
國內(nèi)端到端方案現(xiàn)狀
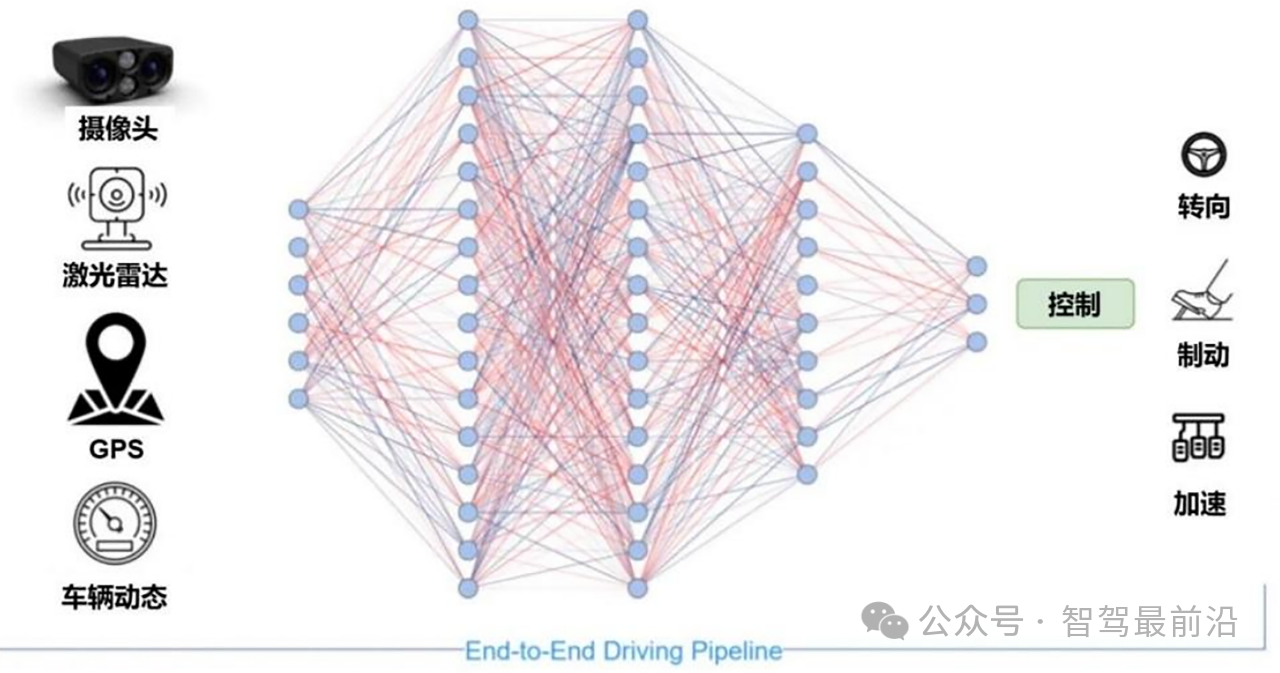
端到端自動(dòng)駕駛是直接從傳感器信息輸入(如攝像頭圖像、LiDAR等)到控制命令輸出(如轉(zhuǎn)向、加減速等)映射的一套系統(tǒng),最早出現(xiàn)在1988年的ALVINN項(xiàng)目,通過相機(jī)和激光測距儀進(jìn)行輸入和一個(gè)簡單的神經(jīng)網(wǎng)絡(luò)生成的轉(zhuǎn)向進(jìn)行輸出。
2024年初,特斯拉FSD V12.3版本發(fā)布,智駕水平讓人驚艷,端到端自動(dòng)駕駛方案受到國內(nèi)主機(jī)廠和自動(dòng)駕駛方案企業(yè)的廣泛關(guān)注。
與傳統(tǒng)的多模塊方案相比,端到端自動(dòng)駕駛方案將感知、預(yù)測和規(guī)劃整合到單一模型中,簡化了方案結(jié)構(gòu),可模擬人類駕駛員直接從視覺輸入做出駕駛決策,以數(shù)據(jù)和算力為主導(dǎo),能夠有效解決模塊化方案的長尾場景,提升模型的訓(xùn)練效率和性能上限。
傳統(tǒng)多模塊方案與端到端方案的對(duì)比(部分)
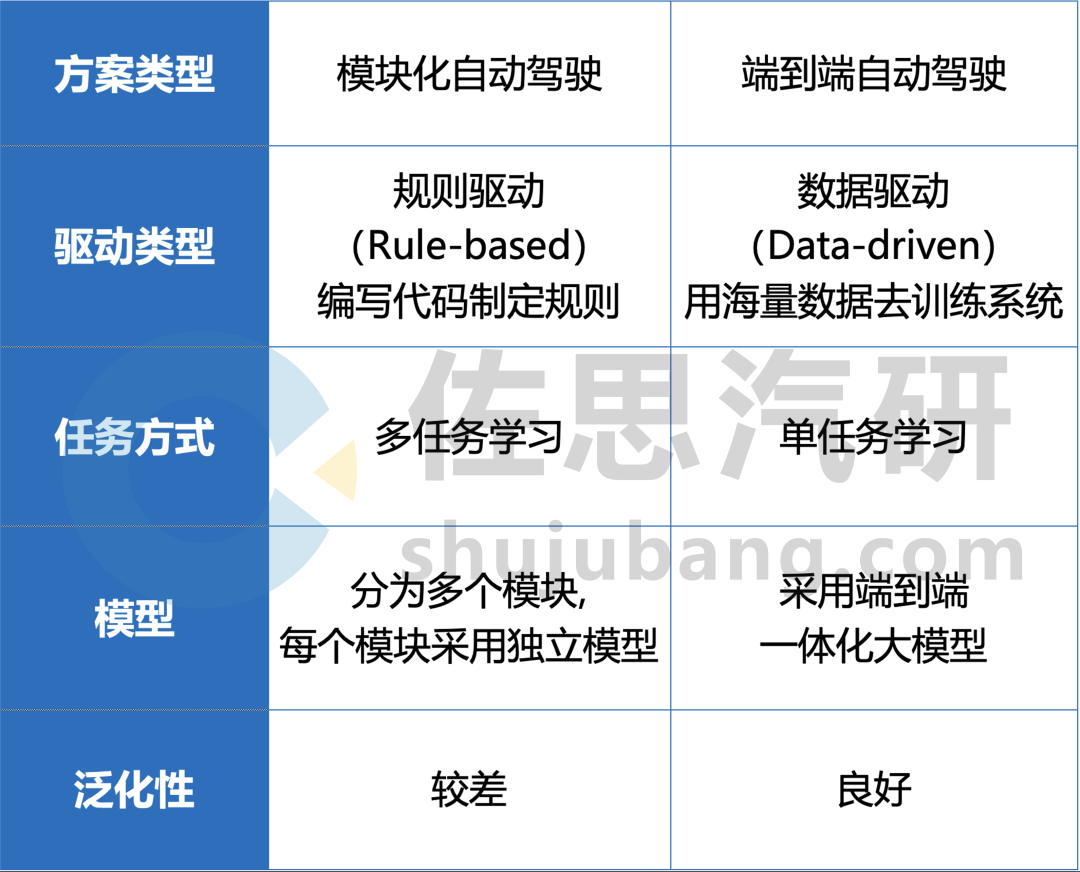
來源:佐思汽研《2024年端到端自動(dòng)駕駛研究報(bào)告》
FSD V12.3版本實(shí)測圖

來源:公開渠道
部分主機(jī)廠對(duì)端到端方案落地量產(chǎn)的規(guī)劃
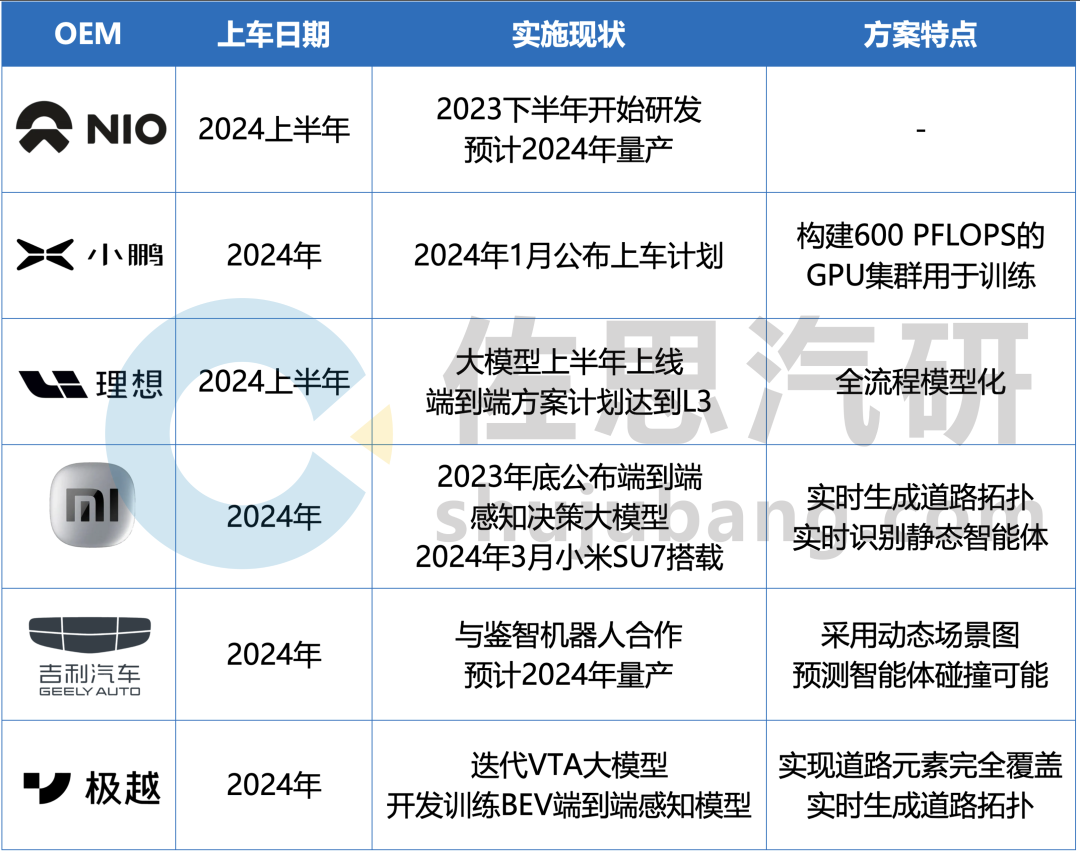
來源:佐思汽研《2024年端到端自動(dòng)駕駛研究報(bào)告》
理想端到端方案
理想認(rèn)為,完整的端到端需要完成感知、跟蹤、預(yù)測、決策、規(guī)劃整個(gè)過程的模型化,是實(shí)現(xiàn)L3級(jí)別自動(dòng)駕駛的最佳方案。2023年,理想推送AD Max3.0,其整體框架已經(jīng)具備端到端的理念,但距離完整的端到端尚有一定差距,2024年理想預(yù)計(jì)以此為基礎(chǔ),推進(jìn)該系統(tǒng)成為一個(gè)徹底的端到端方案。
理想構(gòu)建的自動(dòng)駕駛框架如下圖,分為兩個(gè)系統(tǒng):
快系統(tǒng):System1,感知周圍環(huán)境后直接執(zhí)行,為理想現(xiàn)行的端到端方案。
慢系統(tǒng):System2,多模態(tài)大語言模型,針對(duì)未知環(huán)境進(jìn)行邏輯思考與探索,以解決L4未知場景下的問題。
理想自動(dòng)駕駛框架
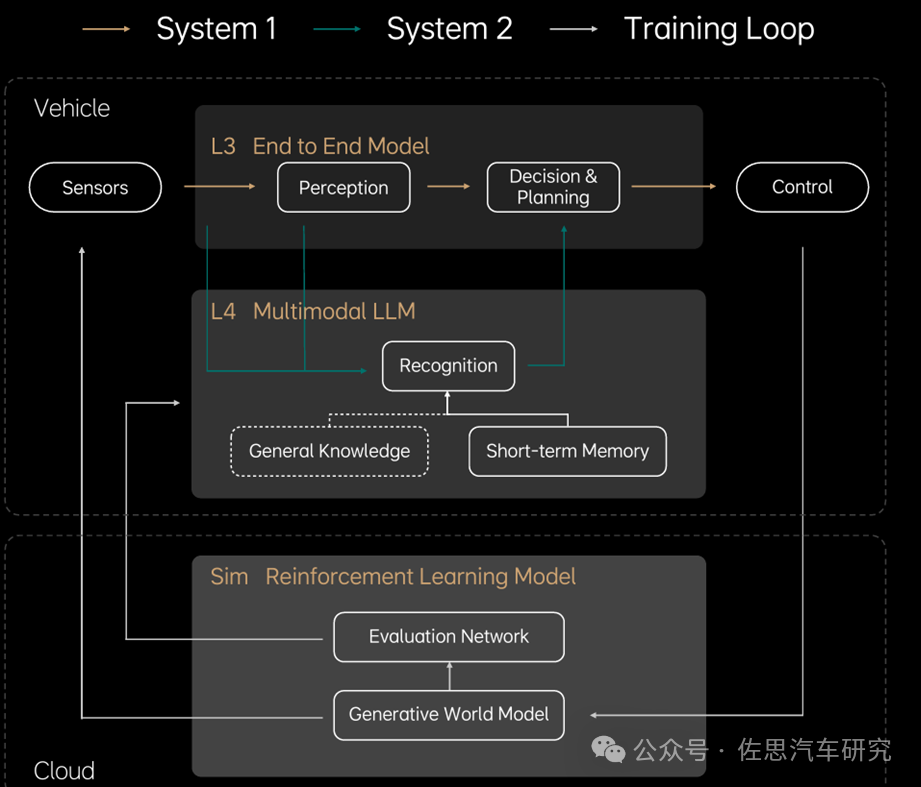
來源:理想汽車
在端到端方案推進(jìn)的過程中,理想計(jì)劃把規(guī)劃/預(yù)測模型與感知模型進(jìn)行統(tǒng)一,并在原基礎(chǔ)上完成Temporal Planner的端到端,實(shí)現(xiàn)泊車/行車一體化。
2
數(shù)據(jù)成為端到端落地的關(guān)鍵
端到端方案的落地需要經(jīng)歷構(gòu)建研發(fā)團(tuán)隊(duì)、配置硬件設(shè)施、數(shù)據(jù)收集處理、算法訓(xùn)練與策略定制、驗(yàn)證評(píng)估、推廣量產(chǎn)等流程,部分場景痛點(diǎn)如表中所示:
端到端方案的部分場景痛點(diǎn)
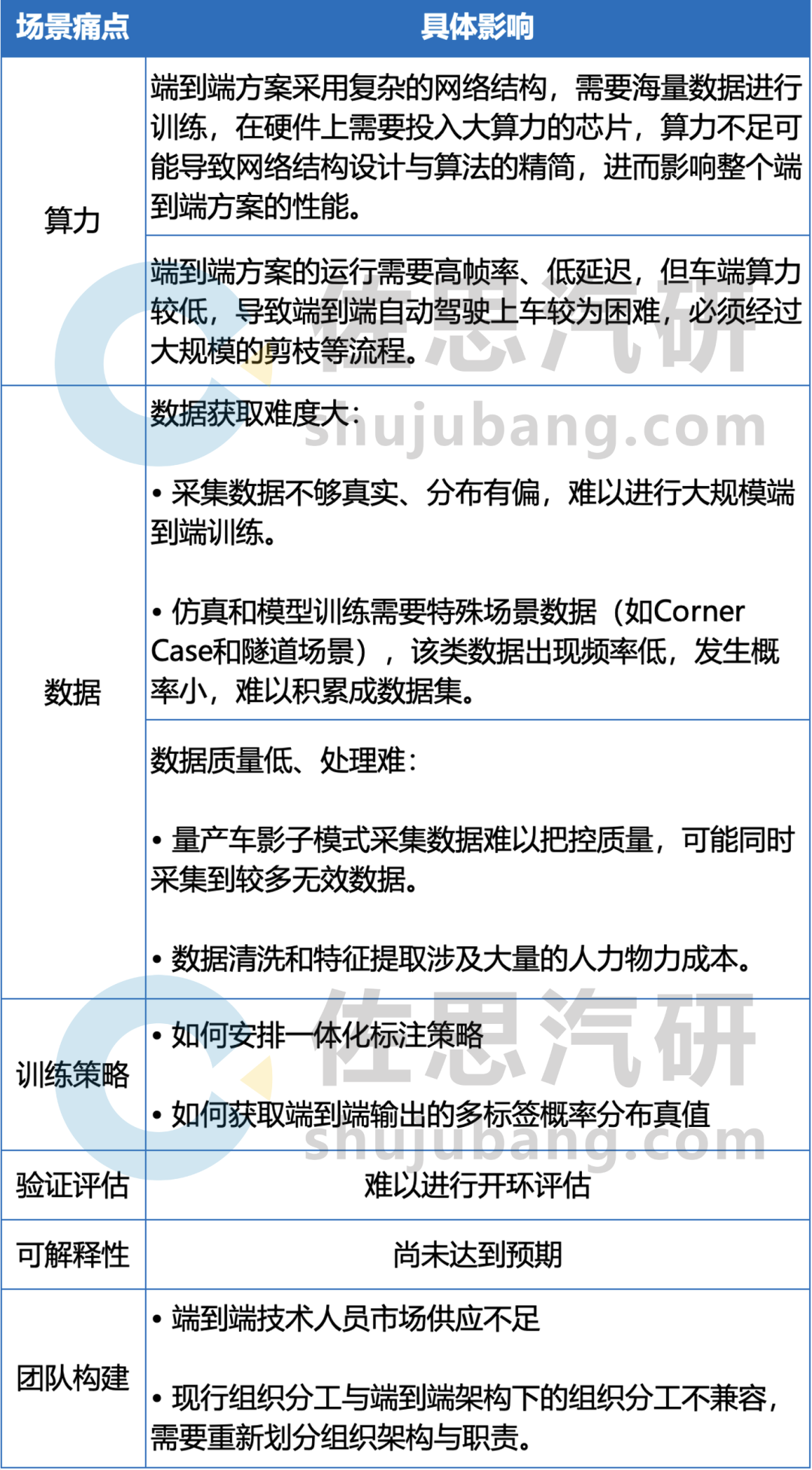
來源:佐思汽研《2024年端到端自動(dòng)駕駛研究報(bào)告》
其中,端到端自動(dòng)駕駛方案中的一體化訓(xùn)練需要大量的數(shù)據(jù),因此其面臨的難點(diǎn)之一在于數(shù)據(jù)的收集和處理。
首先,數(shù)據(jù)的收集需要大量的時(shí)間和渠道,數(shù)據(jù)類型除了駕駛數(shù)據(jù)外還包括各種不同的道路、天氣和交通情況等場景數(shù)據(jù),其中在實(shí)際駕駛中駕駛員前方視野的駕駛數(shù)據(jù)相對(duì)便于收集,周圍方位的信息收集則難以保證。
再次,數(shù)據(jù)處理時(shí)需要設(shè)計(jì)數(shù)據(jù)提取維度、從海量的視頻片段中提取有效的特征、統(tǒng)計(jì)數(shù)據(jù)分布等,以支持大規(guī)模的數(shù)據(jù)訓(xùn)練。
元戎啟行
截至2024年3月,元戎啟行端到端自動(dòng)駕駛方案已經(jīng)獲得長城汽車的定點(diǎn)項(xiàng)目,并與英偉達(dá)開展合作,預(yù)計(jì)2025年適配英偉達(dá)Thor芯片;在元戎啟行的規(guī)劃中,從傳統(tǒng)方案過渡到“端到端”自動(dòng)駕駛方案,經(jīng)歷傳感器前融合、去高精度地圖、感知決策控制三個(gè)模型一體化等環(huán)節(jié)。
元戎啟行在數(shù)據(jù)環(huán)節(jié)的布局

來源:佐思汽研《2024年端到端自動(dòng)駕駛研究報(bào)告》
極佳科技
極佳科技的自動(dòng)駕駛世界模型DriveDreamer,具備場景生成、數(shù)據(jù)生成、駕駛動(dòng)作預(yù)測等功能;在場景/數(shù)據(jù)生成上,分為兩個(gè)步驟:
涉及單幀結(jié)構(gòu)化條件,引導(dǎo)DriveDreamer生成駕駛場景圖像,便于其理解結(jié)構(gòu)交通約束。
將其理解擴(kuò)展到視頻生成。利用連續(xù)的交通結(jié)構(gòu)條件,DriveDreamer輸出駕駛場景視頻,進(jìn)一步增強(qiáng)其對(duì)運(yùn)動(dòng)轉(zhuǎn)換的理解。
DriveDreamer的功能包括可連續(xù)駕駛視頻生成、與文本提示和結(jié)構(gòu)化交通限制無縫對(duì)齊

來源:極佳科技
3
端到端方案加快具身機(jī)器人落地
除了自動(dòng)駕駛汽車,具身機(jī)器人是端到端方案另一個(gè)主流場景。從端到端自動(dòng)駕駛到機(jī)器人,需要構(gòu)建更加通用的世界模型,來適應(yīng)更加復(fù)雜、多元的現(xiàn)實(shí)使用場景,主流AGI(通用人工智能)發(fā)展的框架分為兩個(gè)階段:
階段一:基礎(chǔ)大模型理解和生成實(shí)現(xiàn)統(tǒng)一,進(jìn)一步與具身智能結(jié)合,形成統(tǒng)一世界模型;
階段二:世界模型+復(fù)雜任務(wù)的規(guī)控能力和抽象概念的歸納能力,逐步演化進(jìn)入交互AGI 1.0時(shí)代。
在世界模型落地的過程中,構(gòu)建端到端的VLA(Vision-Language-Action) 自主系統(tǒng)成為關(guān)鍵一環(huán)。VLA作為具身智能基礎(chǔ)大模型,能夠?qū)?D感知、推理和行動(dòng)無縫鏈接起來,形成一個(gè)生成式世界模型,并建立在基于3D的大型語言模型(LLM)之上,引入一組交互標(biāo)記以與環(huán)境進(jìn)行互動(dòng)。
3D-VLA解決方案
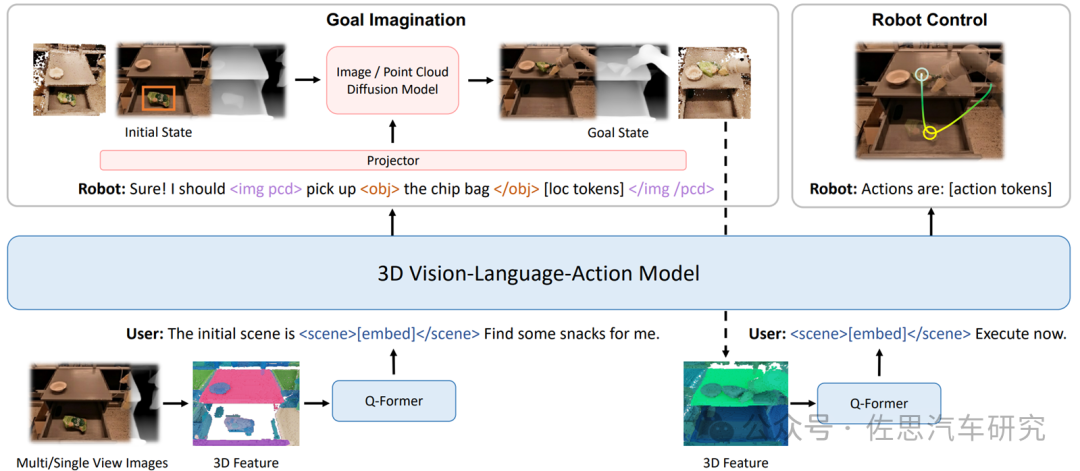
來源:University of Massachusetts Amherst、MIT-IBM Watson AI Lab等機(jī)構(gòu)
截至2024年4月,部分采用端到端方案的具身機(jī)器人廠商如下:
部分具身機(jī)器人如何應(yīng)用端到端方案
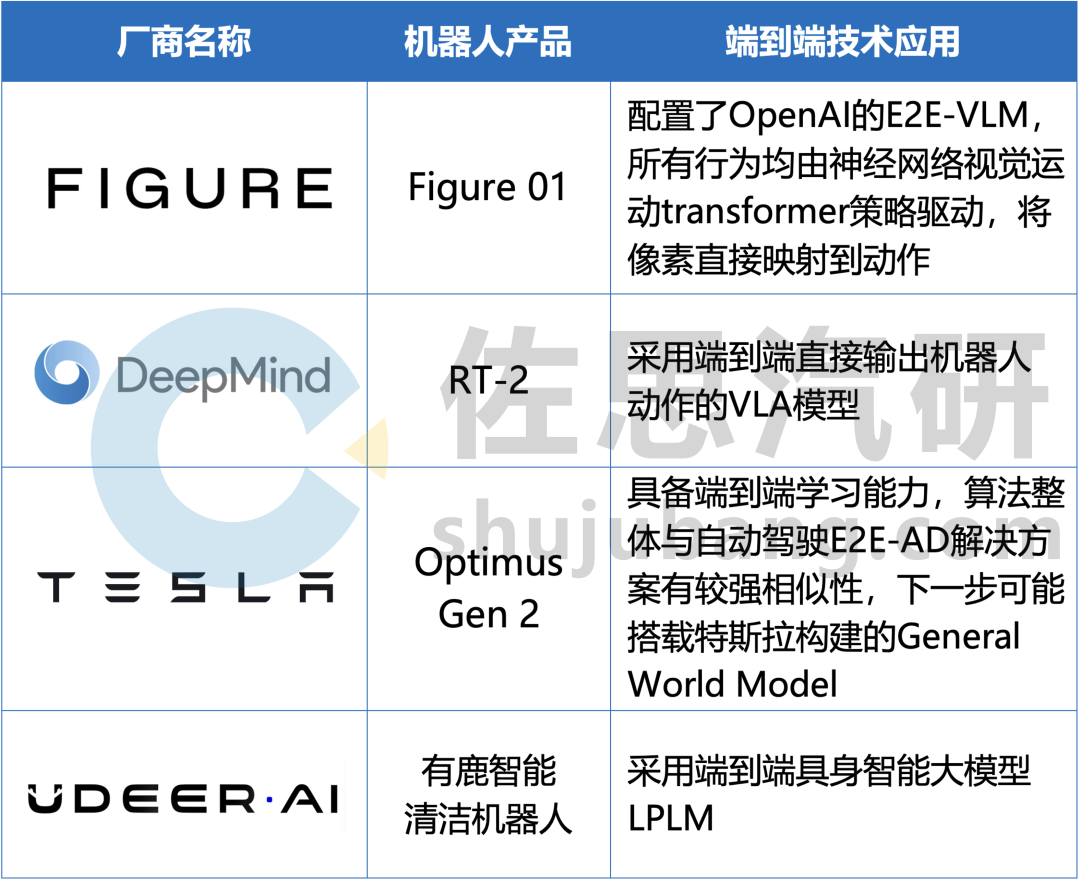
來源:佐思汽研《2024年端到端自動(dòng)駕駛研究報(bào)告》
以有鹿機(jī)器人為例,其具身智能大模型LPLM(Large Physical Language Model)為端到端的具身智能解決方案,通過自我標(biāo)注機(jī)制提升模型從未標(biāo)注數(shù)據(jù)中的學(xué)習(xí)效率和質(zhì)量,從而加深對(duì)世界的理解,進(jìn)而加強(qiáng)機(jī)器人的泛化能力與跨模態(tài)、跨場景、跨行業(yè)場景下的環(huán)境適應(yīng)性。
LPLM模型架構(gòu)
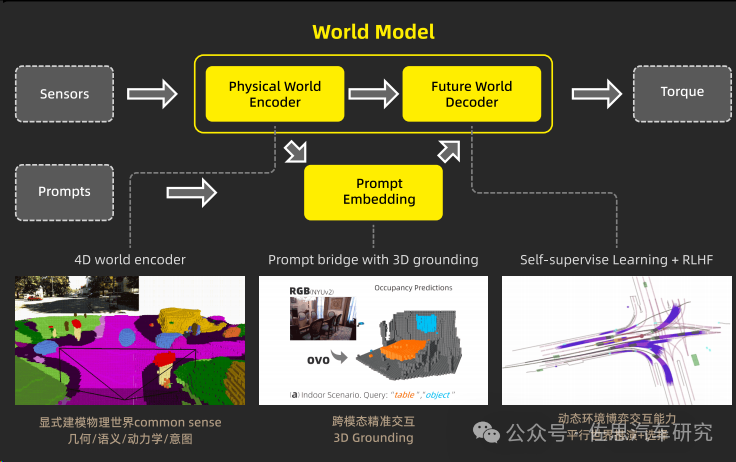
來源:有鹿機(jī)器人
LPLM 將物理世界抽象化,確保該類信息與 LLM 里特征的抽象等級(jí)對(duì)齊,將物理世界中每一個(gè)所指的實(shí)體顯式建模為 token,編碼幾何、語義、運(yùn)動(dòng)學(xué)與意圖信息。
此外,LPLM 在自然語言指令的編碼中加入了 3D grounding,一定程度上彌補(bǔ)了自然語言不夠精確的缺陷;其解碼器能夠通過不斷預(yù)測未來的方式去學(xué)習(xí),從而加強(qiáng)了模型從海量無標(biāo)簽數(shù)據(jù)中學(xué)習(xí)的能力。
審核編輯:劉清
-
傳感器
+關(guān)注
關(guān)注
2564文章
52665瀏覽量
764203 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102914 -
攝像頭
+關(guān)注
關(guān)注
61文章
4954瀏覽量
97734 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3926瀏覽量
93189 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14223瀏覽量
169688
原文標(biāo)題:端到端智駕研究:E2E自動(dòng)駕駛發(fā)展現(xiàn)狀
文章出處:【微信號(hào):zuosiqiche,微信公眾號(hào):佐思汽車研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
一文帶你厘清自動(dòng)駕駛端到端架構(gòu)差異
自動(dòng)駕駛中基于規(guī)則的決策和端到端大模型有何區(qū)別?
東風(fēng)汽車推出端到端自動(dòng)駕駛開源數(shù)據(jù)集
2025年汽車微電機(jī)及運(yùn)動(dòng)機(jī)構(gòu)行業(yè)研究報(bào)告

2026至2030年:Robotaxi趨向規(guī)模化,L3個(gè)人乘用車商業(yè)化新篇章開啟

2024年自動(dòng)駕駛行業(yè)熱點(diǎn)技術(shù)盤點(diǎn)
自動(dòng)駕駛域控研究:One board/One Chip方案將對(duì)汽車供應(yīng)鏈產(chǎn)生深遠(yuǎn)影響

端到端自動(dòng)駕駛技術(shù)研究與分析
爆火的端到端如何加速智駕落地?
連接視覺語言大模型與端到端自動(dòng)駕駛

Waymo利用谷歌Gemini大模型,研發(fā)端到端自動(dòng)駕駛系統(tǒng)
Mobileye端到端自動(dòng)駕駛解決方案的深度解析

實(shí)現(xiàn)自動(dòng)駕駛,唯有端到端?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論