") 一文詳解基于以太網(wǎng)的GPU Scale-UP網(wǎng)絡(luò)
一文詳解基于以太網(wǎng)的GPU Scale-UP網(wǎng)絡(luò)
最近Intel Gaudi-3的發(fā)布,基于RoCE的Scale-UP互聯(lián),再加上Jim Keller也在談?dòng)?a target="_blank">以太網(wǎng)替代NVLink。而Jim所在的Tenstorrent就是很巧妙地用Ethernet實(shí)現(xiàn)了片上網(wǎng)絡(luò)之間的互聯(lián)。所以今天有必要來講講這個(gè)問題。
實(shí)現(xiàn)以太網(wǎng)替代NVLink需要什么手段,不只是一個(gè)傳輸協(xié)議的問題,還涉及到GPU架構(gòu)的一系列修改,本質(zhì)上這個(gè)問題等價(jià)于如何把HBM掛在以太網(wǎng)上,并實(shí)現(xiàn)Scale-Out和滿足計(jì)算需求的一系列通信優(yōu)化,例如SHARP這類In-Network-Computing等, 全球來看能同時(shí)搞定這個(gè)問題的人也就那么幾個(gè),至少明確的說UltraEthernet壓根就沒想明白。
有必要回答以下幾個(gè)問題,或者說博通要搞個(gè)NVLink一樣的東西出來,必須解決如下幾個(gè)問題:
1.Latency Boundary是多少?高吞吐高速Serdes FEC和超過萬(wàn)卡規(guī)模的互聯(lián)帶來的鏈路延遲都是不可抗的,這些并不是說改一個(gè)包協(xié)議,弄一個(gè)HPC-Ethernet就能搞定的。
2.傳輸?shù)恼Z(yǔ)義是什么?做網(wǎng)絡(luò)的這群人大概只懂個(gè)SEND/RECV。舉個(gè)例子,UEC定義的Reliable Unordered Delivery for Idempotent operations(RUDI)其實(shí)就是一個(gè)典型的技術(shù)上的錯(cuò)誤,一方面它滿足了交換律和冪等律,但是針對(duì)一些算子,例如Reduction的加法如何實(shí)現(xiàn)冪等?顯然這群人也沒做過,還有針對(duì)NVLink上那種細(xì)顆粒度的訪存,基于結(jié)合律的優(yōu)化也是不支持的。更一般來說,它必須演進(jìn)到Semi-Lattice的語(yǔ)義才行。
3.更大內(nèi)存在NVLINK上池化的問題? 解決計(jì)算問題中Compute Bound算子的部分時(shí)間/空間折中,例如KV Cache等。
4.動(dòng)態(tài)路由和擁塞控制能力1:1無收斂的Lossless組網(wǎng)對(duì)于萬(wàn)卡集群通過一些hardcode的調(diào)優(yōu)沒什么太大的問題,而對(duì)于十萬(wàn)卡和百萬(wàn)卡規(guī)模集群來看,甚至需要RDMA進(jìn)行長(zhǎng)傳,這些問題目前來看沒有一個(gè)商業(yè)廠商能解決的。
考慮到超大規(guī)模模型訓(xùn)練的一系列需求,把HBM直接掛載在以太網(wǎng)上并實(shí)現(xiàn)了一系列集合通信卸載的,放眼全球現(xiàn)在也就只有少數(shù)幾個(gè)團(tuán)隊(duì)干過,前三個(gè)問題我是在四年前做NetDAM項(xiàng)目時(shí)就已經(jīng)完全解決干凈了,第四個(gè)去年也在某個(gè)云的團(tuán)隊(duì)一起解決干凈了。
下面我們將介紹一些Gaudi3/Maia100/TPU等多個(gè)廠商的互聯(lián),然后再分析一下NVLink的演進(jìn),最后再來談?wù)勅绾文軌蛘嬲亟鉀Q這些問題 at Scale, 再?gòu)?qiáng)調(diào)(Diss)一下at Scale這事沒做好就別瞎叫。
1. 當(dāng)前ScaleUP互聯(lián)方案概述
1.1 Intel Gaudi3
從Gaudi3 whitepaper[1]來看,Gaudi的Die如下圖所示: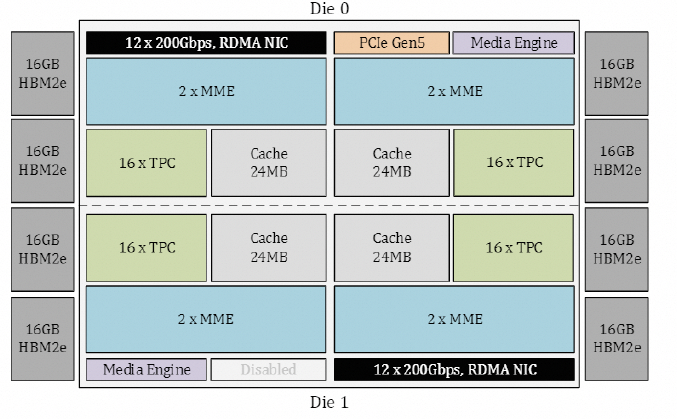
內(nèi)置了24個(gè)RoCE 200Gbps的鏈路,其中21個(gè)用于內(nèi)部FullMesh,三個(gè)用于外部鏈接。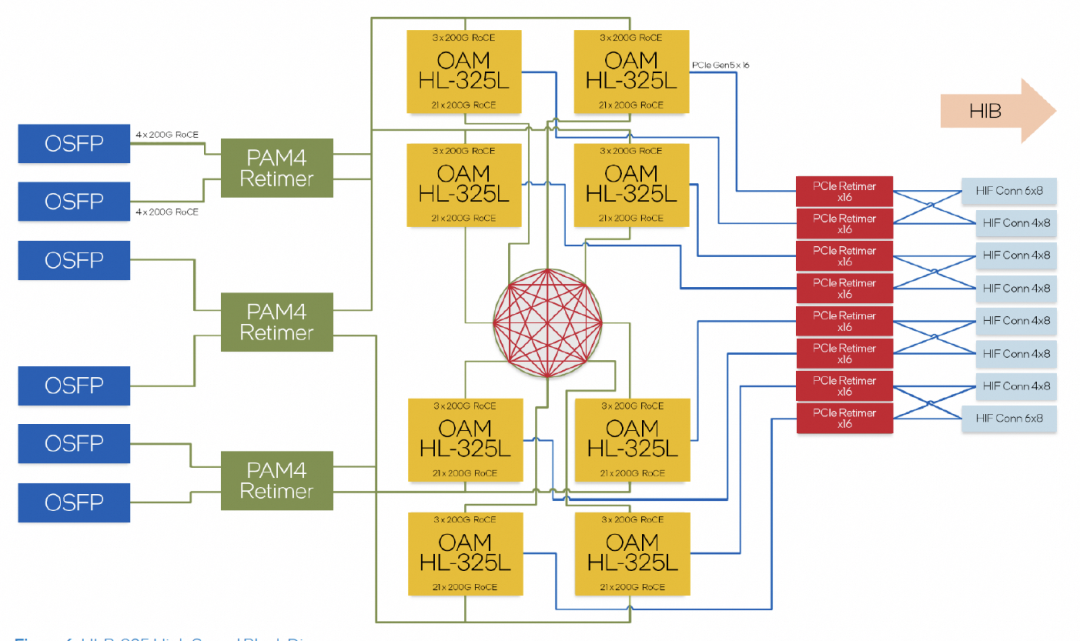
超大規(guī)模組網(wǎng)的拓?fù)洌?jì)算了一下Leaf交換機(jī)的帶寬是一片25.6T的交換機(jī)。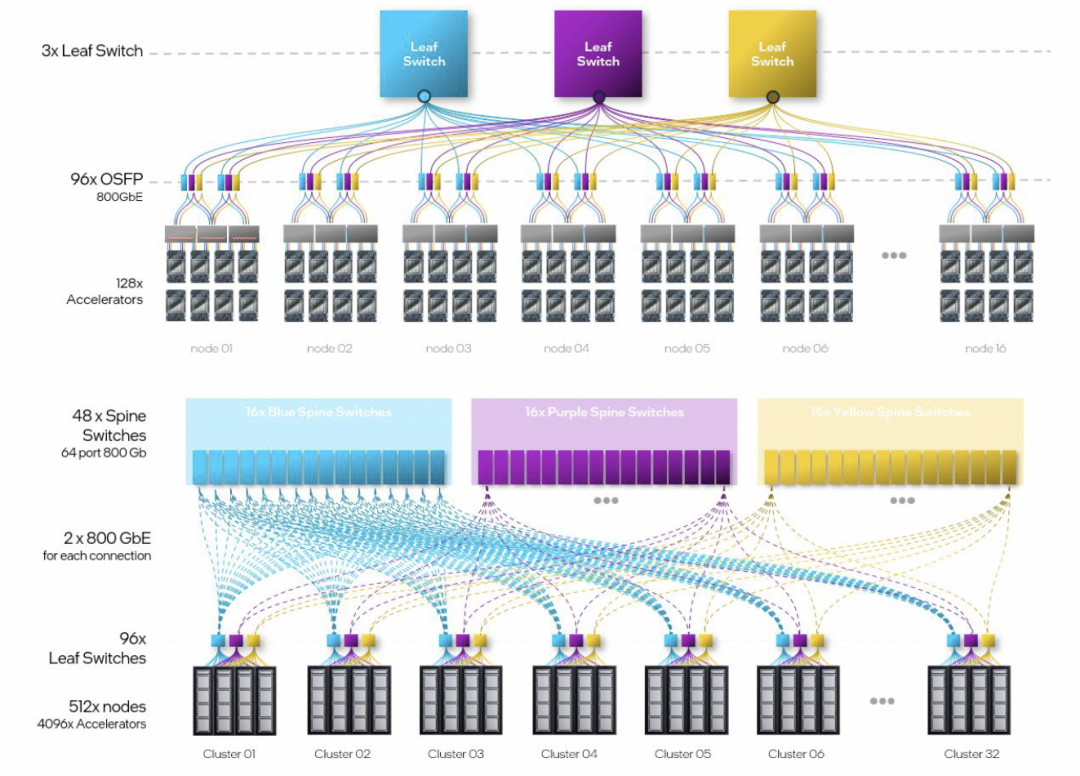
但是Intel WhitePaper有一系列的問題值得去仔細(xì)爬一下。
1.1.1 擁塞控制
Intel的白皮書闡述的是沒有使用PFC,而是采用了Selective ACK機(jī)制。同時(shí)采用了SWIFT來做CC算法避免使用ECN,基本上明眼人一看,這就是復(fù)用了Google Falcon在Intel IPU上做的Reliable Transport Engine。
1.1.2 多路徑和In-Network Reduction
Intel宣稱支持Packet Spraying,但是交換機(jī)用的哪家的呢,一定不是自己家的Tofino。那么只能是博通了。另外In-Network Reduction支持了FP8/BF16等, Operator只支持Sum/Min/Max,再加上UEC有一些關(guān)于In-Network-Computing(INC)的工作組,應(yīng)該基本上就清楚了。
1.2 Microsoft Maia100
沒有太多的信息,只有4800Gbps單芯片的帶寬,然后單個(gè)服務(wù)器機(jī)框4張Maia100,整個(gè)機(jī)柜8個(gè)服務(wù)器構(gòu)成一個(gè)32卡的集群。
放大交換機(jī)和互聯(lián)的線纜來看,有三個(gè)交換機(jī),每個(gè)服務(wù)器有24個(gè)400Gbps網(wǎng)絡(luò)接口,網(wǎng)口間有回環(huán)的連接線(圖中黑色),以及對(duì)外互聯(lián)線(紫色)。
也就是說很有可能構(gòu)成如下的拓?fù)?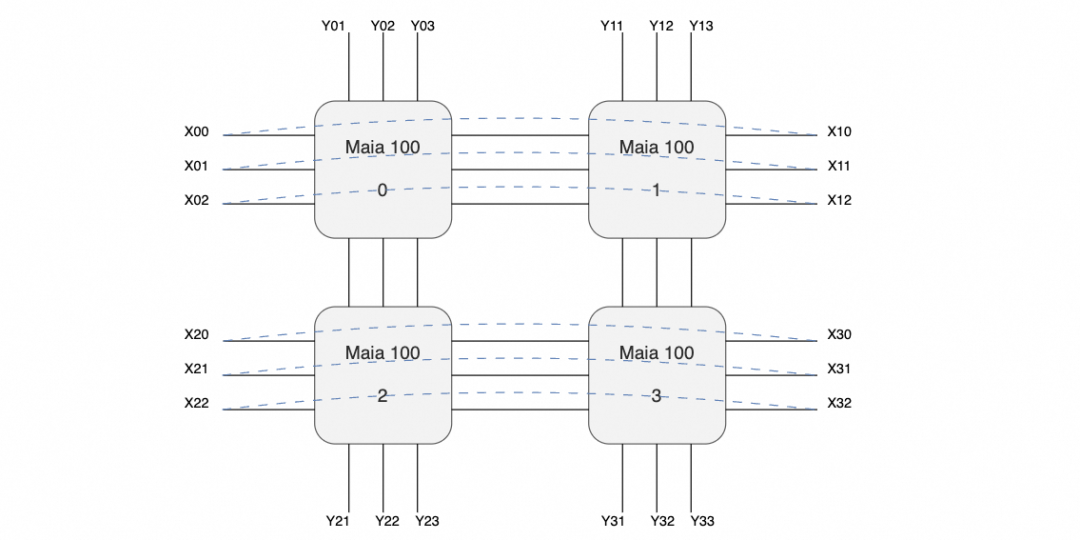
即在主板內(nèi)部構(gòu)成一個(gè)口字形的互聯(lián),然后在X方向構(gòu)成一個(gè)環(huán),而在Y方向則是分別構(gòu)成三個(gè)平面連接到三個(gè)交換機(jī)。
交換機(jī)上行進(jìn)行機(jī)柜間的Scale-Out連接,每個(gè)機(jī)柜每個(gè)平面總共有32個(gè)400G接口, 再加上1:1收斂,上行交換機(jī)鏈路算在一起正好一個(gè)25.6T的交換機(jī),這樣搭幾層擴(kuò)展理論應(yīng)該可行,算是一個(gè)Scale-Up和Scale-Out兩張網(wǎng)絡(luò)合并的代表。至于協(xié)議對(duì)于Torus Ring來看,簡(jiǎn)單的點(diǎn)到點(diǎn)RoCE應(yīng)該問題不大,互聯(lián)到Scale-Out交換機(jī)時(shí)就需要多路徑的能力了。
缺點(diǎn)是延遲可能有點(diǎn)大,不過這類自定義的芯片如果不是和CUDA那樣走SIMT,而是走脈動(dòng)陣列的方式,延遲也不是太大的問題。另外Torus整個(gè)組就4塊,集合通信延遲影響也不大。但是個(gè)人覺得這東西可能還是用于做推理為主的,一般CSP都會(huì)先做一塊推理用的芯片,再做訓(xùn)練的。另外兩家CSP也有明確的訓(xùn)練推理區(qū)分AWS Trainium/Inferentia, Google也是V5p/V5e。
1.3 Google TPU
TPU互聯(lián)大家已經(jīng)很清楚了,Torus Ring的拓?fù)浣Y(jié)構(gòu)和光交換機(jī)來做鏈路切換。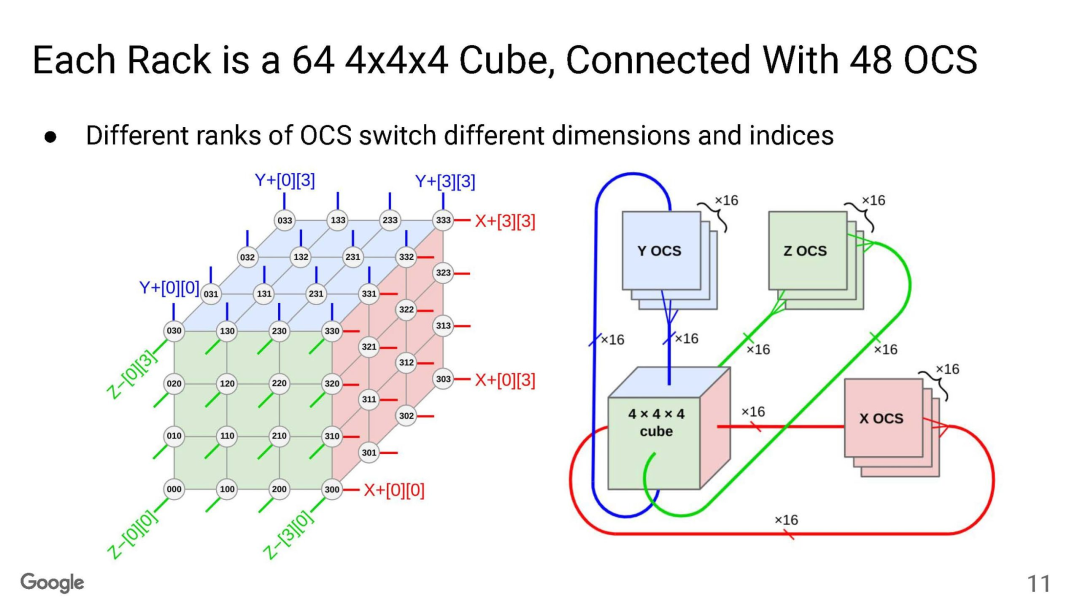
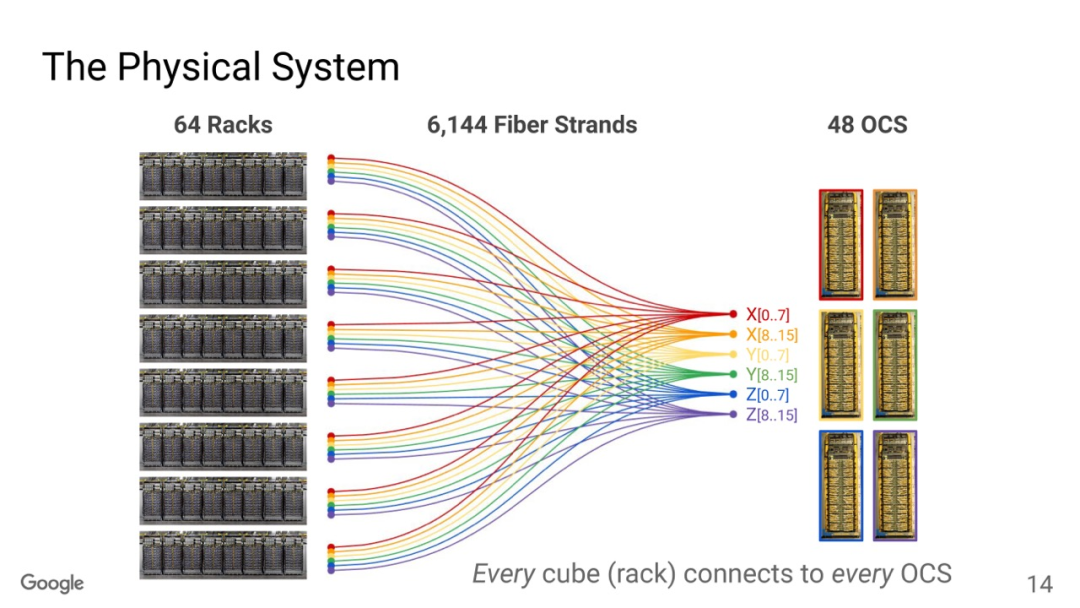
OCS有兩個(gè)目的,一個(gè)是按照售賣的規(guī)模進(jìn)行動(dòng)態(tài)切分,例如TPUv5p 單芯片支持4800Gbps的ICI(Inter-Chip Interconnect)連接,拓?fù)錇?D-Torus,整個(gè)集群8960塊TPUv5p 最大售賣規(guī)模為6144塊構(gòu)成一個(gè)3D-Torus。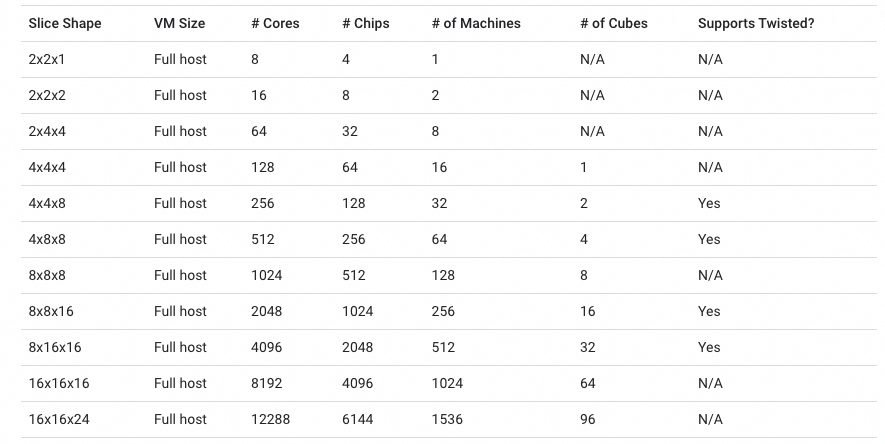
通過OCS可以切分這些接口進(jìn)行不同尺度的售賣, 另一個(gè)是針對(duì)MoE這些AlltoAll的通信做擴(kuò)展bisection 帶寬的優(yōu)化。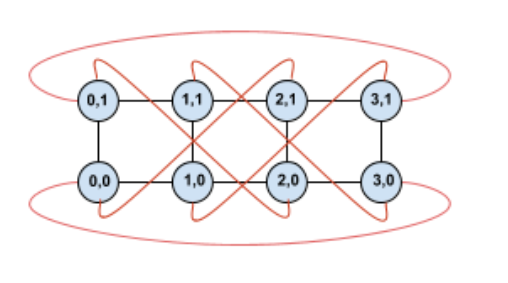
還有一個(gè)是容錯(cuò),這是3D Torus拓?fù)浔仨氁紤]的一個(gè)問題,有一些更新是這周NSDI‘24 講到一個(gè)《Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer》[2] 后面我們將專門介紹。 另一方面Google還支持通過數(shù)據(jù)中心網(wǎng)絡(luò)擴(kuò)展兩個(gè)Pod構(gòu)建Multislice的訓(xùn)練,Pod間做DP并行。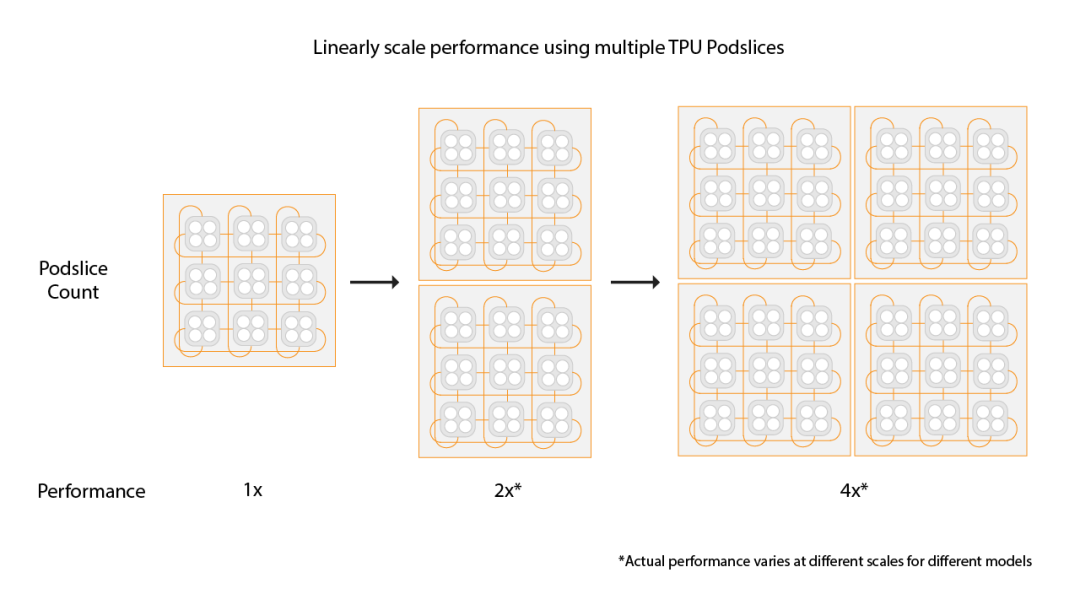
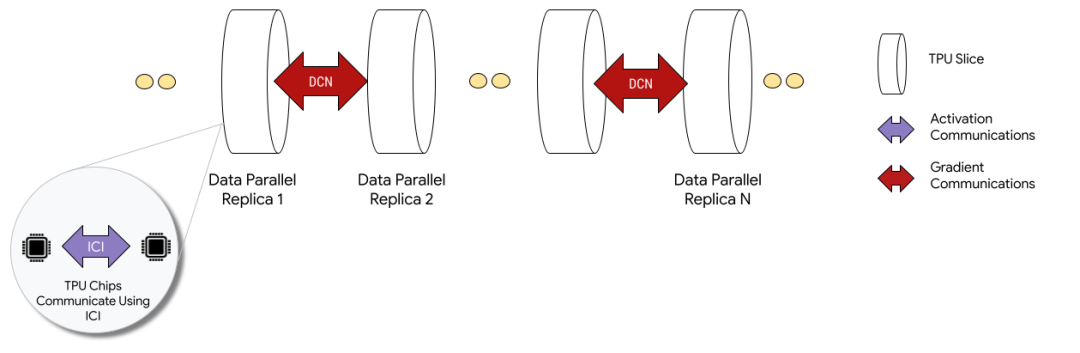
1.4 AWS Trainium
Trainium架構(gòu)如下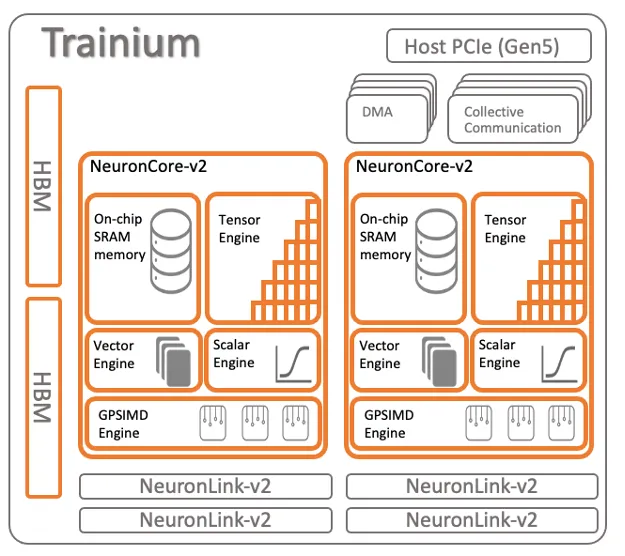
16片構(gòu)成一個(gè)小的Cluster,片間互聯(lián)如下: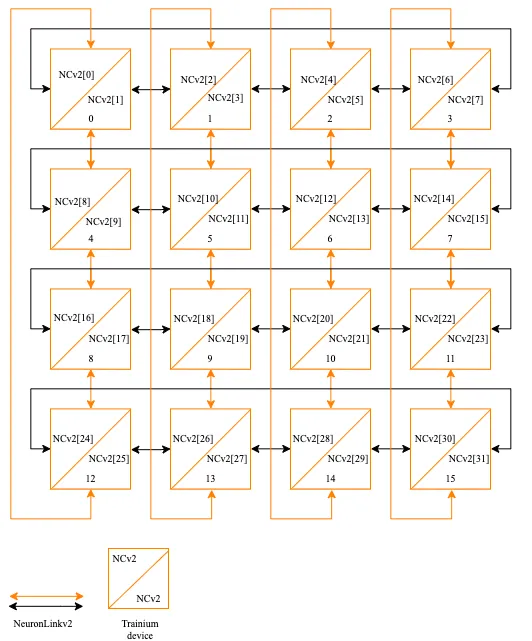
也是一個(gè)2D Torus Ring的結(jié)構(gòu)。
1.5 Tesla Dojo
它搞了一個(gè)自己的Tesla Transport Protocol,統(tǒng)一Wafer/NOC和外部以太網(wǎng)擴(kuò)展。
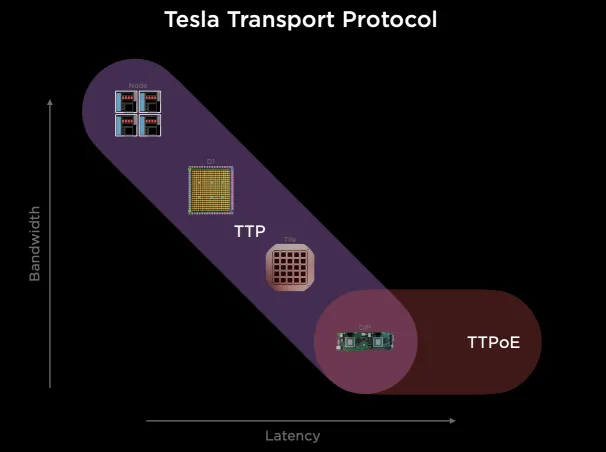
它通過臺(tái)積電的System-on-Wafer將25個(gè)D1計(jì)算單元封裝在一個(gè)晶圓上, 并采用5x5的方式構(gòu)建2D Mesh網(wǎng)絡(luò)互聯(lián)所有的計(jì)算單元, 單個(gè)晶圓構(gòu)成一個(gè)Tile.每個(gè)Tile有40個(gè)I/O Die。
Tile之間采用9TB/s互聯(lián)。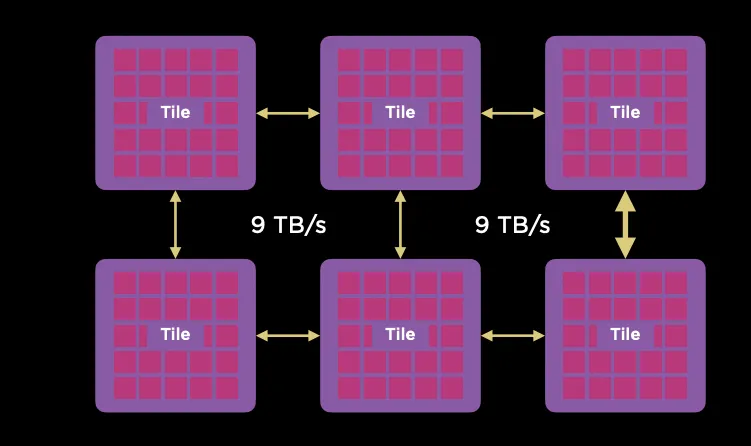
可以通過片上網(wǎng)絡(luò)路由繞開失效的D1核或者Tile。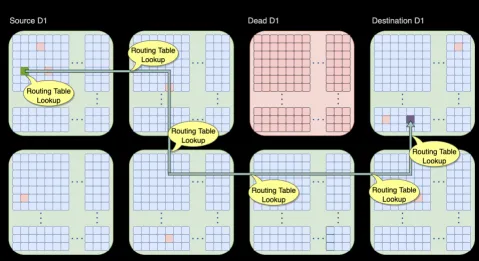
對(duì)外Scale-Out的以太網(wǎng)有一塊DIP,每個(gè)D1計(jì)算引擎有自己的SRAM, 而其它內(nèi)存放置在帶HBM的Dojo接口卡(DIP)上。
每個(gè)網(wǎng)卡通過頂部的900GB/s特殊總線TTP(Tesla Transport Protocol)連接到Dojo的I/O Die上, 正好對(duì)應(yīng)800GB HBM的帶寬, 每個(gè)I/O Die可以連接5個(gè)Dojo接口卡(DIP)。

由于內(nèi)部通信為一個(gè)2D Mesh網(wǎng)絡(luò), 長(zhǎng)距離通信代價(jià)很大, 針對(duì)片上路由做了一些特殊的設(shè)計(jì)。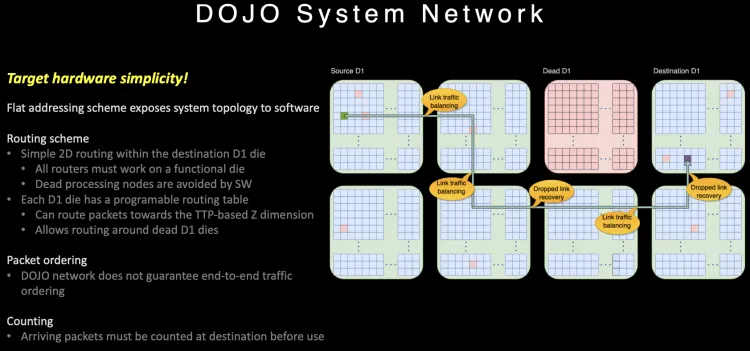
路由在片上提供多路徑,并且不保序, 同時(shí)針對(duì)大范圍長(zhǎng)路徑的通信, 它很巧妙的利用Dojo接口卡構(gòu)建了一個(gè)400Gbps的以太網(wǎng)TTPoE總線來做shortcut。
Dojo通過System-on-wafer的方式構(gòu)建了基于晶圓尺度的高密度的片上網(wǎng)絡(luò), 同時(shí)通過私有的片間高速短距離總線構(gòu)建了9TB/s的wafer間的通信網(wǎng)絡(luò). 然后將I/O和內(nèi)存整合在DIP卡上,提供每卡900GB/s連接到晶圓片上網(wǎng)絡(luò)的能力,構(gòu)建了一個(gè)超大規(guī)模的2D Mesh網(wǎng)絡(luò), 但是考慮到片上網(wǎng)絡(luò)通信距離過長(zhǎng)帶來的擁塞控制, 又設(shè)計(jì)了基于DIP卡的400Gbps逃生通道,通過片外的以太網(wǎng)交換機(jī)送到目的晶圓上。
1.6 Tenstorrent
Jim keller在Tenstorrent的片上網(wǎng)絡(luò)設(shè)計(jì)就是使用的以太網(wǎng),結(jié)構(gòu)很簡(jiǎn)單, Tensor+控制頭構(gòu)成一個(gè)以太網(wǎng)報(bào)文并可以觸發(fā)條件執(zhí)行等能力,如下所示: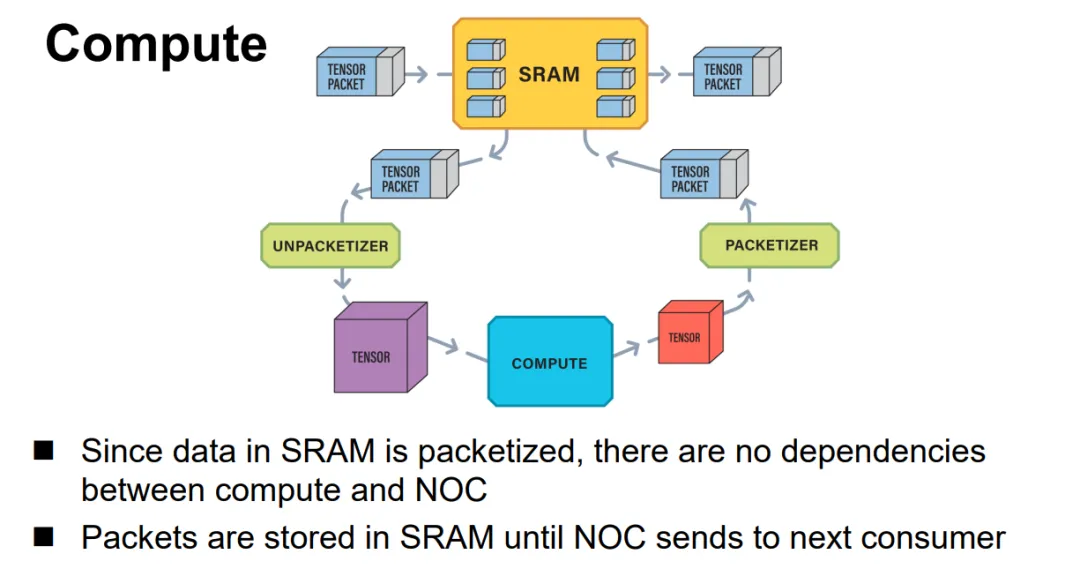
片間互聯(lián)全以太網(wǎng):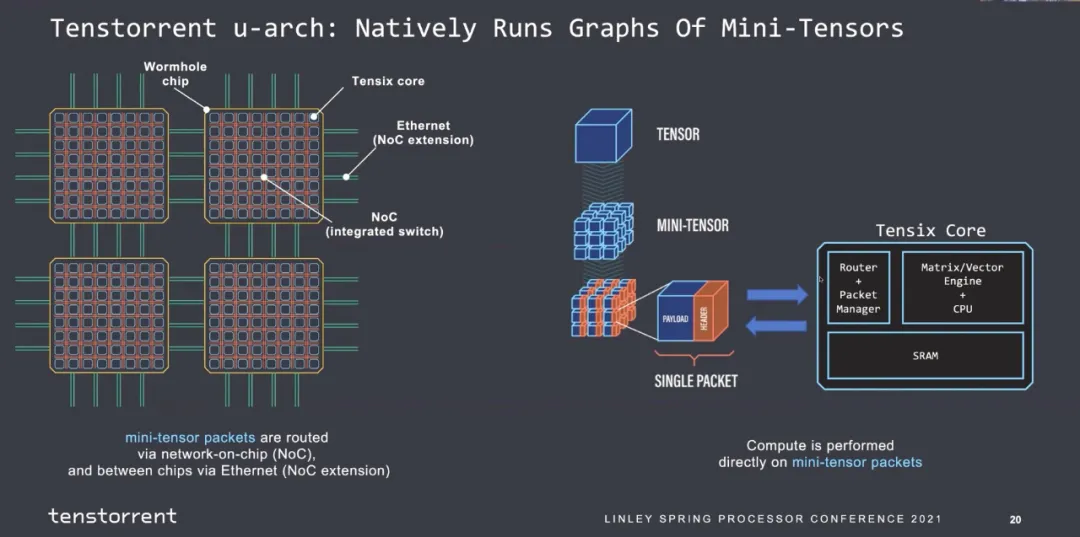
并且支持多種功能通信源語(yǔ)。
然后就是圖的劃分,主觀覺得每個(gè)stage的指令數(shù)是可以估計(jì)的,算子進(jìn)出的帶寬是可以估計(jì)的。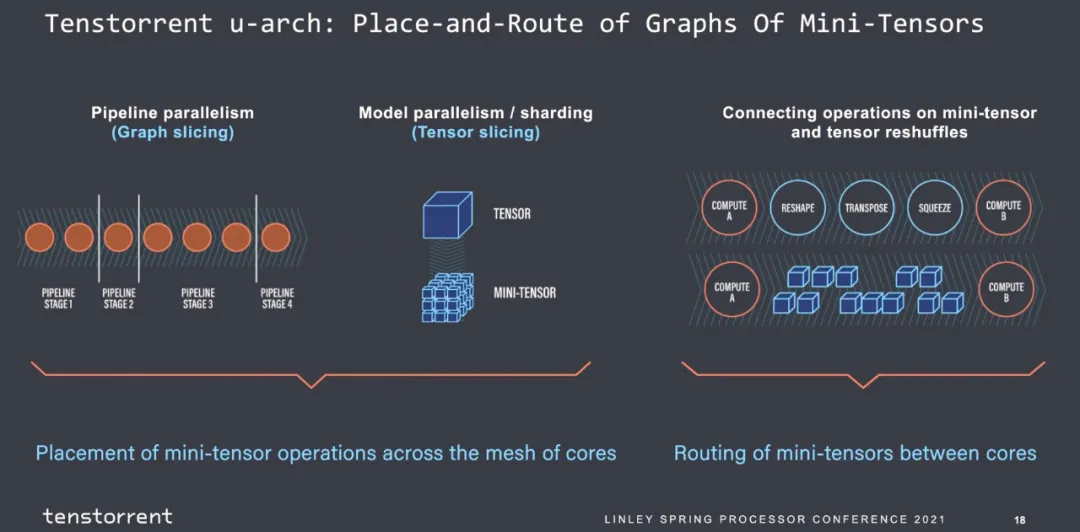
那么最后mapping到核上的約束也似乎好做: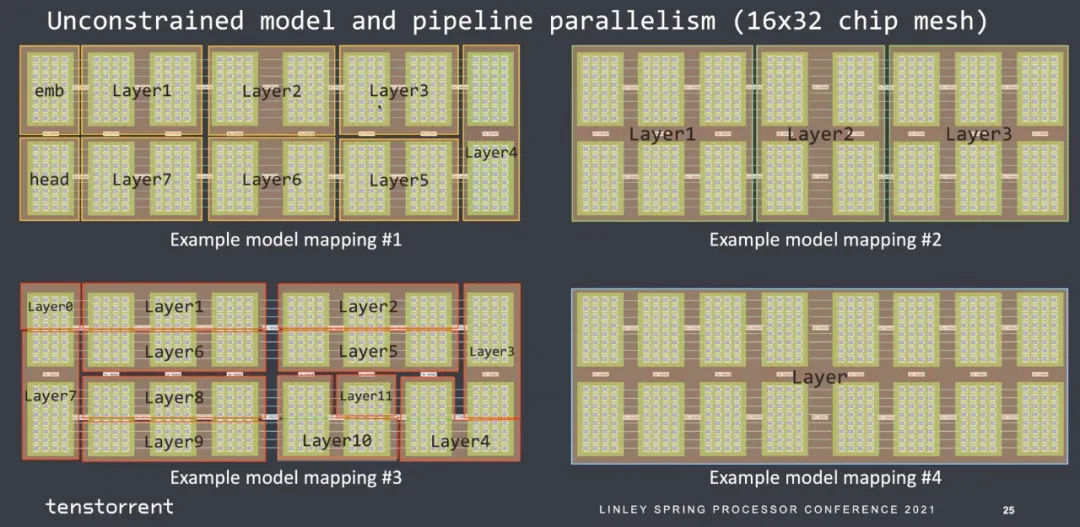
也是很簡(jiǎn)單的一個(gè)2D Mesh結(jié)構(gòu):
可以擴(kuò)展到40960個(gè)core的大規(guī)模互聯(lián)。
2. Scale-UP的技術(shù)需求
2.1 拓?fù)溥x擇
我們可以注意到在ScaleUp網(wǎng)絡(luò)選擇中,Nvidia當(dāng)前是1:1收斂的FatTree構(gòu)建,而其它幾家基本上都是Torus Ring或者2D Mesh,而Nvidia后續(xù)會(huì)演進(jìn)到DragonFly。
背后的邏輯我們可以在hammingMesh的論文中看到的選擇如下: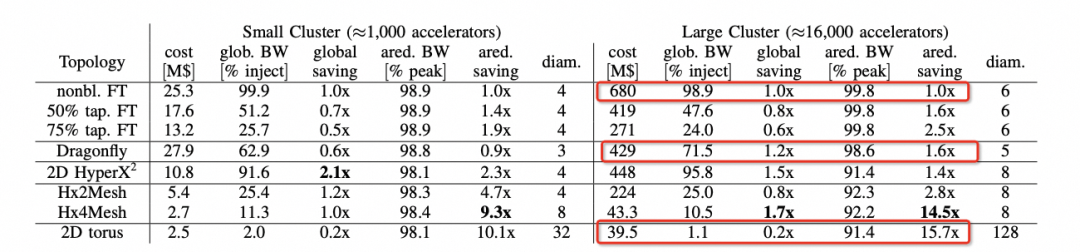
可以看到對(duì)于Allreduce帶寬來看,Torus是最便宜的,性能也能夠基本跑到峰值。但是針對(duì)MoE這類模型的AlltoAll就要考察bisection帶寬了,而DragonFly無論是在布線復(fù)雜度還是GlobBW以及網(wǎng)絡(luò)直徑上都還不錯(cuò),所以明白了Bill Dally的選擇了吧?
2.2 動(dòng)態(tài)路由和可靠傳輸
雖然所有的人都在扯RoCE有缺陷,BF3+Spectrum-4有Adaptive Routing,博通有DLB/GLB來演進(jìn)Packet Spraying還有和思科一樣的VoQ的技術(shù),當(dāng)然還有Meta的多軌道靜態(tài)路由做流量工程,或者管控平面去調(diào)度親和性。但簡(jiǎn)單來說,這些都是在萬(wàn)卡規(guī)模可以解決一部分問題的,而at Scale這個(gè)難題現(xiàn)在要到十萬(wàn)卡以上規(guī)模,怎么做?
從算法上解決Burst是一件很難的事情,而更難的是所有的人不去想Burst怎么造成的,天天屎上雕花的去測(cè)交換機(jī)buffer來壓burst,據(jù)說還有人搞確定性網(wǎng)絡(luò)和傅立葉分析來搞?想啥呢?
這是一個(gè)非常難的問題,就看工業(yè)界其它幾個(gè)廠什么時(shí)候能想明白吧?另一方面是系統(tǒng)失效和彈性售賣,Google在NSDI24的文章里面提到會(huì)產(chǎn)生碎片的原因: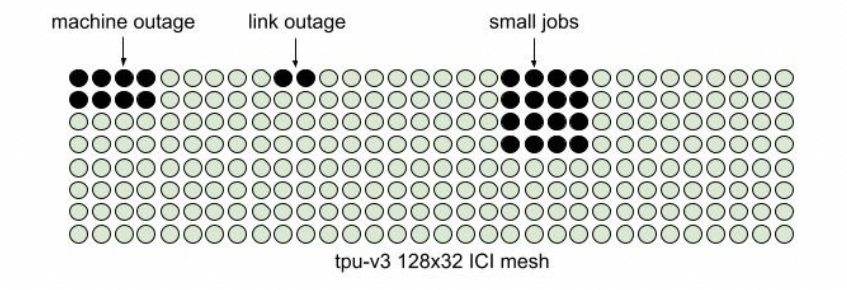
如果不考慮這些問題會(huì)導(dǎo)致調(diào)度難題。ICI內(nèi)部的路由表實(shí)現(xiàn)配合OCS交換機(jī)是一個(gè)不錯(cuò)的選擇。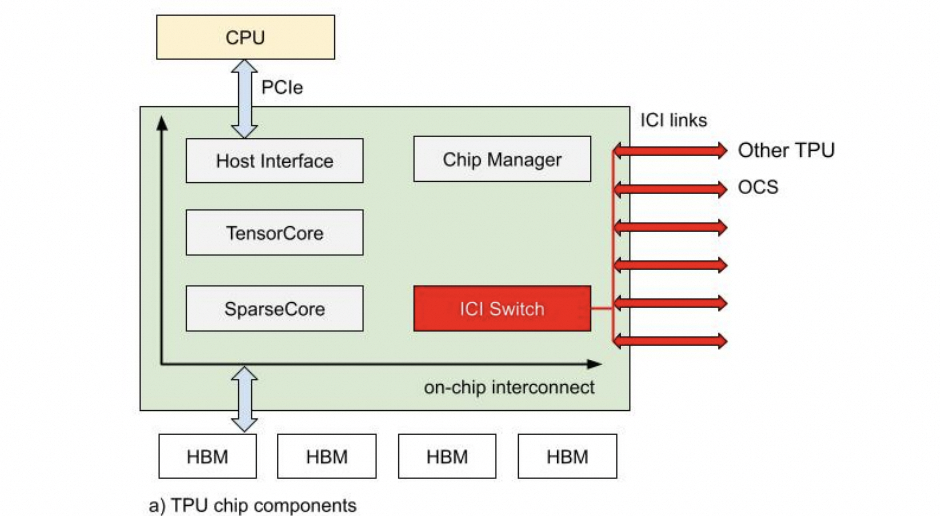
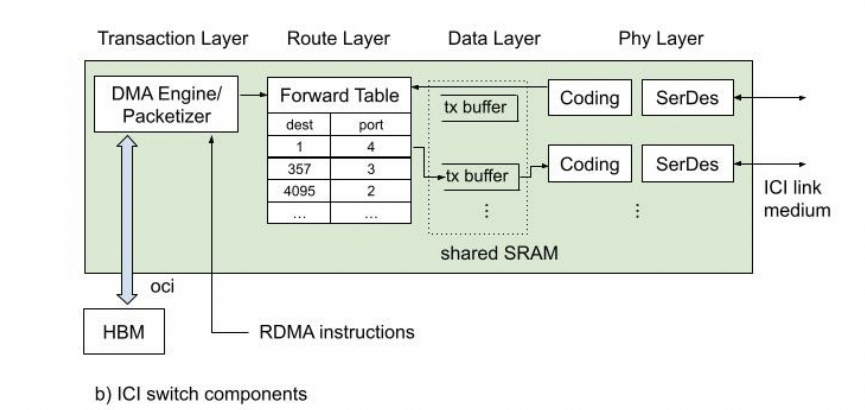
這篇論文詳細(xì)地公開了ICI的物理層/可靠傳輸層/路由層和事務(wù)層,后面會(huì)詳細(xì)講解一下這篇論文。
為什么這個(gè)事情對(duì)以太網(wǎng)支持ScaleUP很重要呢?因?yàn)橐蕴W(wǎng)一定需要在這里實(shí)現(xiàn)一個(gè)路由層支撐DragonFly和失效鏈路切換的能力。
3. Scale UP延遲重要么? 其實(shí)回答這個(gè)問題本質(zhì)是GPU如何做Latency Hidding,以及Latency上NVLink和RDMA之間的差異。需要注意的是本來GPU就是一個(gè)Throughput Optimized處理器,又極致的追求低延遲那么一定是實(shí)現(xiàn)上有問題。而本質(zhì)上的問題是NVLink是內(nèi)存語(yǔ)義,而RDMA是消息語(yǔ)義,另一方面是RDMA在異構(gòu)計(jì)算實(shí)現(xiàn)的問題。
3.1 RDMA實(shí)現(xiàn)的缺陷
RDMA相對(duì)于NVLink延遲大的關(guān)鍵因素在CPU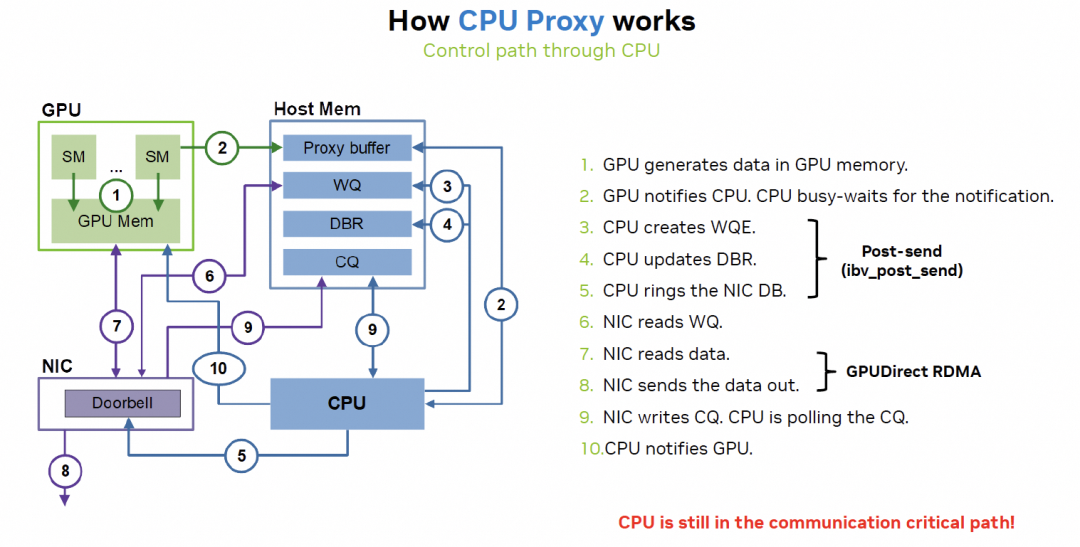
英偉達(dá)在通過GDA-KI來解決: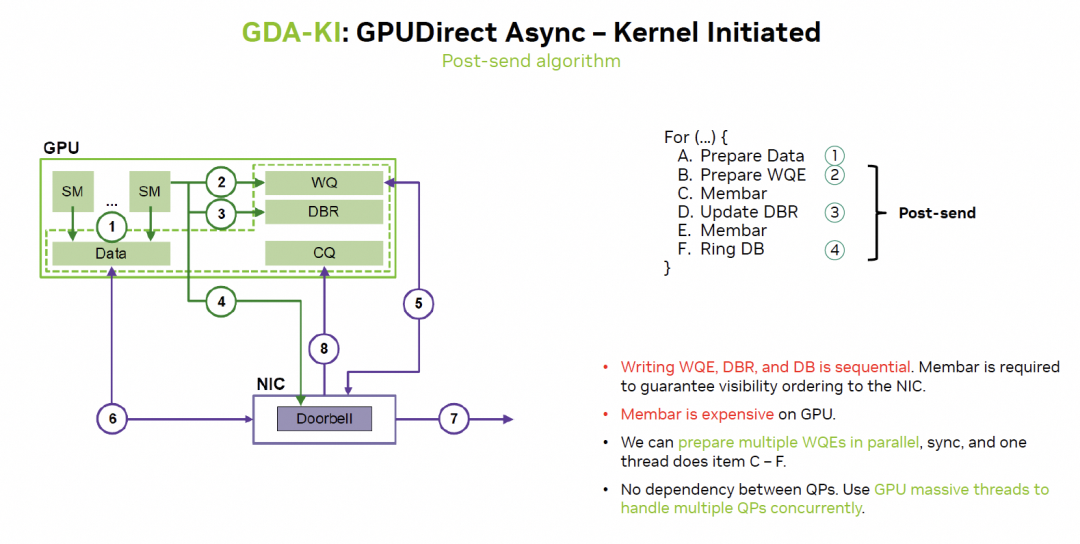
這樣來看實(shí)際上很多訪存延遲都更容易隱藏了。
3.2 細(xì)粒度的內(nèi)存訪問
另一個(gè)問題是NVLink基于內(nèi)存語(yǔ)義,有大量細(xì)粒度的Load/Store訪問,因此對(duì)傳輸效率和延遲非常重要,但如果用以太網(wǎng)RDMA替換該怎么做呢?一來肯定就要說這個(gè)事情,包太長(zhǎng)了,需要HPC Ethernet。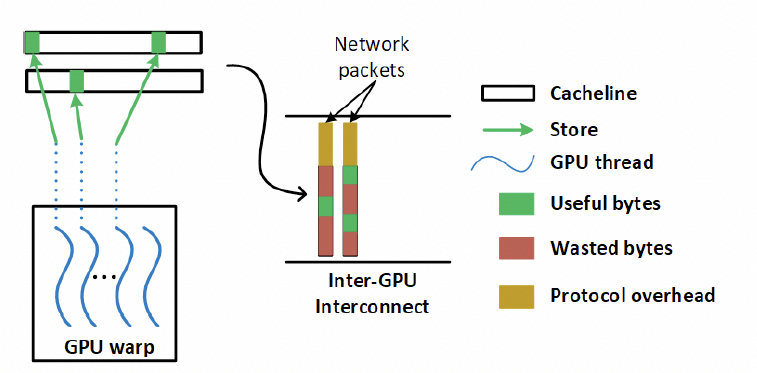
其實(shí)這就是我在NetDAM里面一直闡述的一個(gè)問題,對(duì)于RDMA的消息,需要實(shí)現(xiàn)對(duì)內(nèi)的Semi-Lattice語(yǔ)義。
交換律可以保證數(shù)據(jù)可以用UnOrder方式提交。
冪等保證了丟包重傳的二意性問題,但是需要注意的是對(duì)于Reduce這樣的加法操作有副作用時(shí),需要基于事務(wù)或者數(shù)據(jù)的冪等處理,當(dāng)然我在做NetDAM的時(shí)候也解決了。
結(jié)合律針對(duì)細(xì)粒度的內(nèi)存訪問,通過結(jié)合律編排,提升傳輸效率。
對(duì)于訪存的需求,在主機(jī)內(nèi)的協(xié)議如下: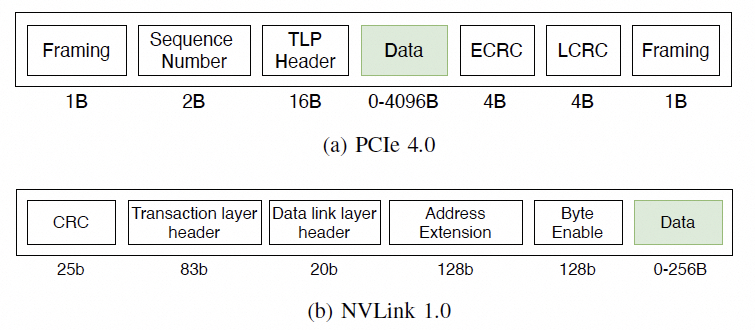
通常是一個(gè)FLIT的大小,而在這個(gè)基礎(chǔ)上要支持超大規(guī)模的ScaleUP互聯(lián)和支撐可靠性又要加一些路由頭,還有以太網(wǎng)頭,還有如果超大規(guī)模集群要多租戶隔離還有VPC頭,這些其實(shí)支持起來都沒有太大問題的,因?yàn)楫?dāng)你考慮到了 結(jié)合律即可。但是UEC似乎完全沒理解到,提供了RUDI的支持交換律和冪等律支持了,結(jié)合律忘了,真是一個(gè)失誤。 而英偉達(dá)針對(duì)這個(gè)問題怎么解的呢?結(jié)合律編碼: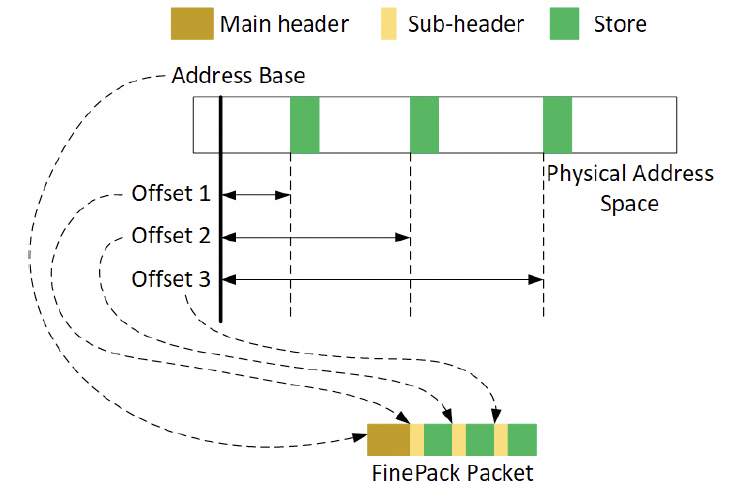
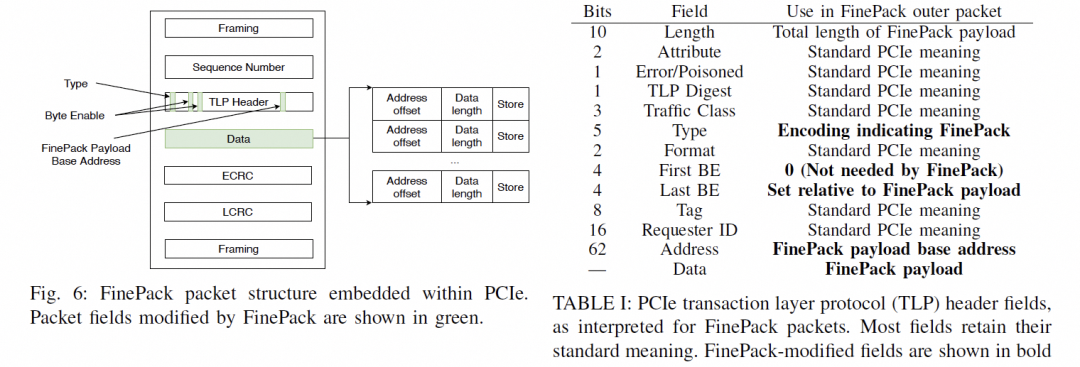
最終細(xì)顆粒度訪存的問題解決了。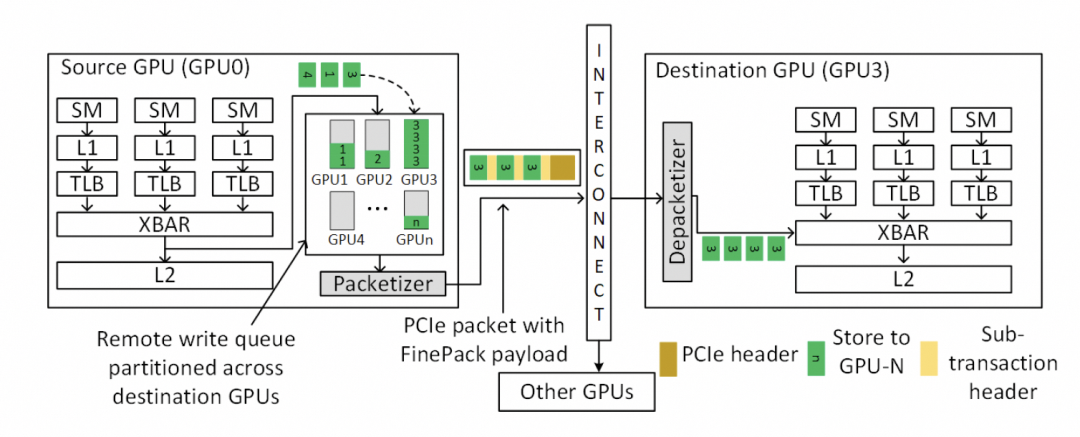
下一代的NVLink一定會(huì)走到這條路里面來Infiniband和NVLink這兩張ScaleOut和ScaleUP網(wǎng)絡(luò)一定會(huì)融合。
3.2 ScaleUP的內(nèi)存池化
現(xiàn)在很多大模型的問題都在于HBM容量不夠,當(dāng)然英偉達(dá)通過拉個(gè)Grace和NVLink C2C擴(kuò)展,本質(zhì)上是ScaleUP網(wǎng)絡(luò)需要池化內(nèi)存。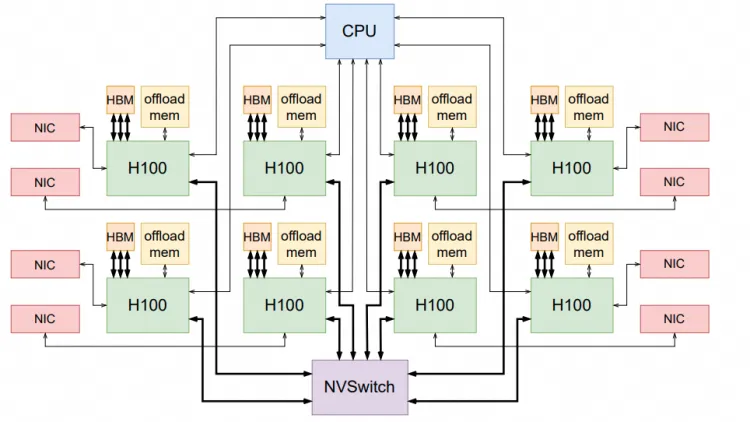
是否還有別的方式呢?英偉達(dá)其實(shí)已經(jīng)在干了,附送一篇論文的截圖,后面詳細(xì)會(huì)講。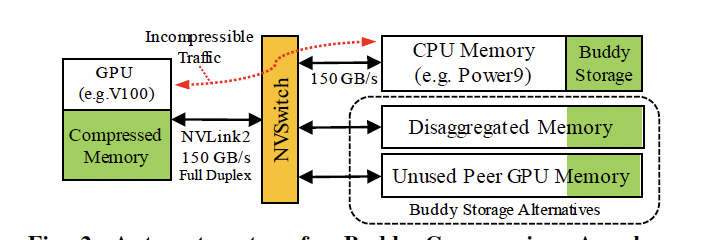
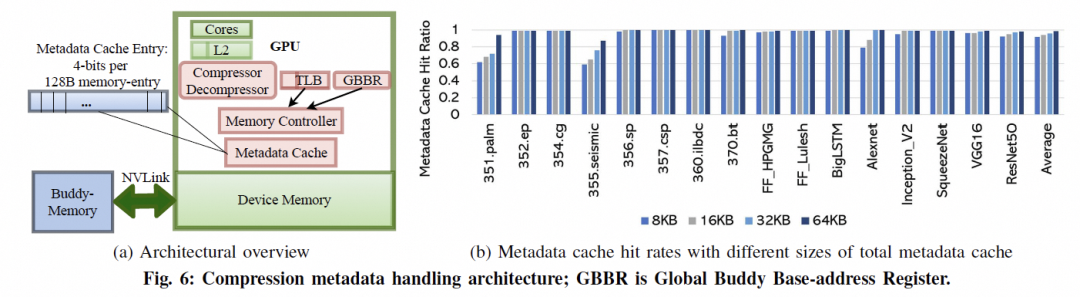
3. 結(jié)論 任何一家公司如果想做Ethernet的Scale UP,需要考慮以下大量的問題:
延遲并不是那么重要,配合GPU做一些訪存的修改FinePack成Message語(yǔ)義,然后再Cache上處理一下隱藏延遲即可;
ScaleUP網(wǎng)絡(luò)的動(dòng)態(tài)路由和租戶隔離能力非常關(guān)鍵,要想辦法做好路由,特別是資源受到鏈路失效產(chǎn)生的碎片問題;
RDMA語(yǔ)義不完善,而簡(jiǎn)單的抄SHARP也有一大堆坑,需要實(shí)現(xiàn)Semi-Lattice語(yǔ)義,并且支撐一系列有副作用的操作實(shí)現(xiàn)冪等;
Fabric的多路徑轉(zhuǎn)發(fā)和擁塞控制,提升整個(gè)Fabric利用率;
大規(guī)模內(nèi)存池化。
當(dāng)然我再勸你們好好讀讀NetDAM的論文,基于以太網(wǎng)ScaleUP直連HBM的實(shí)踐,消息編碼和Jim Keller做的幾乎一致,而且都是在同一時(shí)期不同出發(fā)點(diǎn)的工作,另一方面大規(guī)模池化天然就支持。還有就是原生的In-Network-Computing/Programming加速。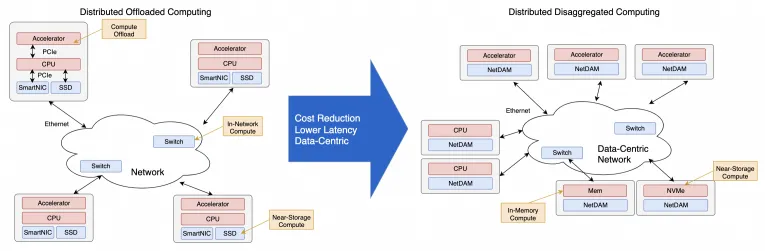
當(dāng)然擁塞控制和多路徑轉(zhuǎn)發(fā)是最近一年多和幾個(gè)團(tuán)隊(duì)一起搞的新的工作,至此基本上拼圖已經(jīng)補(bǔ)全了。
-
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5590瀏覽量
174958 -
單芯片
+關(guān)注
關(guān)注
3文章
461瀏覽量
35095 -
交換機(jī)
+關(guān)注
關(guān)注
21文章
2726瀏覽量
101452 -
Mesh網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
44瀏覽量
14545 -
HBM
+關(guān)注
關(guān)注
1文章
408瀏覽量
15133
原文標(biāo)題:談?wù)劵谝蕴W(wǎng)的GPU Scale-UP網(wǎng)絡(luò)
文章出處:【微信號(hào):SDNLAB,微信公眾號(hào):SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
一文詳解車載以太網(wǎng)

EtherCAT實(shí)時(shí)以太網(wǎng)分析儀功能詳解#以太網(wǎng)


車載以太網(wǎng)基礎(chǔ)培訓(xùn)——車載以太網(wǎng)的鏈路層#車載以太網(wǎng)

車載以太網(wǎng)基礎(chǔ)培訓(xùn)——網(wǎng)絡(luò)層#車載以太網(wǎng)
以太網(wǎng)和工業(yè)以太網(wǎng)的不同
詳解工業(yè)以太網(wǎng)
以太網(wǎng)的分類及靜態(tài)以太網(wǎng)交換和動(dòng)態(tài)以太網(wǎng)交換、介紹
一文詳解什么是實(shí)時(shí)以太網(wǎng)
工業(yè)以太網(wǎng)與傳統(tǒng)以太網(wǎng)絡(luò)的比較
一文讀懂以太網(wǎng)與CANoe的配置
以太網(wǎng)接口的類型及參數(shù)
一文詳解車載以太網(wǎng)PHY芯片
一文了解工業(yè)以太網(wǎng)交換機(jī)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論