 一文解析機器學習常用35大算法
一文解析機器學習常用35大算法

本文將帶你遍歷機器學習領域最受歡迎的算法系統地了解這些算法有助于進一步掌握機器學習當然,本文收錄的算法并不完全,分類的方式也不唯一不過,看完這篇文章后,下次再有算法提起,你想不起它長處和用處的可能性就很低了本文還附有兩張算法思維導圖供學習使用
在本文中,我將提供兩種分類機器學習算法的方法一是根據學習方式分類,二是根據類似的形式或功能分類這兩種方法都很有用,不過,本文將側重后者,也就是根據類似的形式或功能分類在閱讀完本文以后,你將會對監督學習中最受歡迎的機器學習算法,以及它們彼此之間的關系有一個比較深刻的了解
事先說明一點,我沒有涵蓋機器學習特殊子領域的算法,比如計算智能(進化算法等)、計算機視覺(CV)、自然語言處理(NLP)、推薦系統、強化學習和圖模型
下面是一張算法思維導圖,點擊放大查看

從學習方式分類
算法對一個問題建模的方式很多,可以基于經歷、環境,或者任何我們稱之為輸入數據的東西機器學習和人工智能的教科書通常會讓你首先考慮算法能夠采用什么方式學習實際上,算法能夠采取的學習方式或者說學習模型只有幾種,下面我會一一說明對機器學習算法進行分類是很有必要的事情,因為這迫使你思考輸入數據的作用以及模型準備過程,從而選擇一個最適用于你手頭問題的算法
監督學習
輸入數據被稱為訓練數據,并且每一個都帶有標簽,比如“廣告/非廣告”,或者當時的股票價格通過訓練過程建模,模型需要做出預測,如果預測出錯會被修正直到模型輸出準確的結果,訓練過程會一直持續常用于解決的問題有分類和回歸常用的算法包括邏輯回歸和BP神經網絡
無監督學習
輸入數據沒有標簽,輸出沒有標準答案,就是一系列的樣本無監督學習通過推斷輸入數據中的結構建模這可能是提取一般規律,可以是通過數學處理系統地減少冗余,或者根據相似性組織數據常用于解決的問題有聚類、降維和關聯規則的學習常用的算法包括 Apriori 算法和 K 均值算法
半監督學習
半監督學習的輸入數據包含帶標簽和不帶標簽的樣本半監督學習的情形是,有一個預期中的預測,但模型必須通過學習結構整理數據從而做出預測常用于解決的問題是分類和回歸常用的算法是所有對無標簽數據建模進行預測的算法(即無監督學習)的延伸
從功能角度分類
研究人員常常通過功能相似對算法進行分類例如,基于樹的方法和基于神經網絡的方法這種方法也是我個人認為最有用的分類方法不過,這種方法也并非完美,比如學習矢量量化(LVQ),就既可以被歸為神經網絡方法,也可以被歸為基于實例的方法此外,像回歸和聚類,就既可以形容算法,也可以指代問題
為了避免重復,本文將只在最適合的地方列舉一次下面的算法和分類都不齊備,但有助于你了解整個領域大概(說明:用于分類和回歸的算法帶有很大的個人主觀傾向;歡迎補充我遺漏的條目)
回歸算法
回歸分析是研究自變量和因變量之間關系的一種預測模型技術這些技術應用于預測時間序列模型和找到變量之間關系回歸分析也是一種常用的統計學方法,經由統計機器學習融入機器學習領域“回歸”既可以指算法也可以指問題,因此在指代的時候容易混淆實際上,回歸就是一個過程而已常用的回歸算法包括:
普通最小二乘回歸(OLSR)
線性回歸
邏輯回歸
逐步回歸
多元自適應回歸樣條法(MARS)
局部估計平滑散點圖(LOESS)
基于實例的學習算法
基于實例的學習通過訓練數據的樣本或事例建模,這些樣本或事例也被視為建模所必需的這類模型通常會建一個樣本數據庫,比較新的數據和數據庫里的數據,通過這種方式找到最佳匹配并做出預測換句話說,這類算法在做預測時,一般會使用相似度準則,比對待預測的樣本和原始樣本之間的相似度,再做出預測因此,基于實例的方法也被稱之為贏家通吃的方法(winner-take-all)和基于記憶的學習(memory-based learning)常用的基于實例的學習算法包括:
k-鄰近算法(kNN)
學習矢量量化算法(LVQ)
自組織映射算法(SOM)
局部加權學習算法(LWL)
正則化算法
正則化算法背后的思路是,參數值比較小的時候模型更加簡單對模型的復雜度會有一個懲罰值,偏好簡單的、更容易泛化的模型,正則化算法可以說是這種方法的延伸我把正則化算法單獨列出來,原因就是我聽說它們十分受歡迎、功能強大,而且能夠對其他方法進行簡單的修飾常用的正則化算法包括:
嶺回歸
LASSO 算法
Elastic Net
最小角回歸算法(LARS)
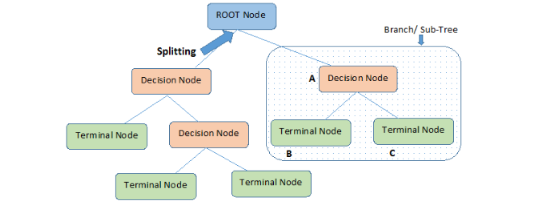
決策樹算法
決策樹算法的目標是根據數據屬性的實際值,創建一個預測樣本目標值的模型訓練時,樹狀的結構會不斷分叉,直到作出最終的決策也就是說,預測階段模型會選擇路徑進行決策決策樹常被用于分類和回歸決策樹一般速度快,結果準,因此也屬于最受歡迎的機器學習算法之一常用的決策樹算法包括:
分類和回歸樹(CART)
ID3 算法
C4.5 算法和 C5.0 算法(它們是一種算法的兩種不同版本)
CHAID 算法
單層決策樹
M5 算法
條件決策樹
貝葉斯算法
貝葉斯方法指的是那些明確使用貝葉斯定理解決分類或回歸等問題的算法常用的貝葉斯算法包括:
樸素貝葉斯算法
高斯樸素貝葉斯算法
多項式樸素貝葉斯算法
AODE 算法
貝葉斯信念網絡(BBN)
貝葉斯網絡(BN)
聚類算法
聚類跟回歸一樣,既可以用來形容一類問題,也可以指代一組方法聚類方法通常涉及質心(centroid-based)或層次(hierarchal)等建模方式,所有的方法都與數據固有的結構有關,目標是將數據按照它們之間共性最大的組織方式分成幾組換句話說,算法將輸入樣本聚成圍繞一些中心的數據團,通過這樣的方式發現數據分布結構中的規律常用的聚類算法包括:
K-均值
K-中位數
EM 算法
分層聚類算法
關聯規則學習
關聯規則學習在數據不同變量之間觀察到了一些關聯,算法要做的就是找出最能描述這些關系的規則,也就是獲取一個事件和其他事件之間依賴或關聯的知識常用的關聯規則算法有:
Apriori 算法
Eclat 算法
人工神經網絡
人工神經網絡是一類受生物神經網絡的結構及/或功能啟發而來的模型它們是一類常用于解決回歸和分類等問題的模式匹配,不過,實際上是一個含有成百上千種算法及各種問題變化的子集注意這里我將深度學習從人工神經網絡算法中分離了出去,因為深度學習實在太受歡迎人工神經網絡指的是更加經典的感知方法常用的人工神經網絡包括:
感知機
反向傳播算法(BP 神經網絡)
Hopfield網絡
徑向基函數網絡(RBFN)
深度學習算法
深度學習算法是人工神經網絡的升級版,充分利用廉價的計算力近年來,深度學習得到廣泛應用,尤其是語音識別、圖像識別深度學習算法會搭建規模更大、結構更復雜的神經網絡,正如上文所說,很多深度學習方法都涉及半監督學習問題,這種問題的數據一般量極大,而且只有很少部分帶有標簽常用的深度學習算法包括:
深度玻爾茲曼機(DBM)
深度信念網絡(DBN)
卷積神經網絡(CNN)
棧式自編碼算法(Stacked Auto-Encoder)
降維算法
降維算法和聚類有些類似,也是試圖發現數據的固有結構但是,降維算法采用的是無監督學習的方式,用更少(更低維)的信息進行總結和描述降維算法可以監督學習的方式,被用于多維數據的可視化或對數據進行簡化處理很多降維算法經過修改后,也被用于分類和回歸的問題常用的降維算法包括:
主成分分析法(PCA)
主成分回歸(PCR)
偏最小二乘回歸(PLSR)
薩蒙映射
多維尺度分析法(MDS)
投影尋蹤法(PP)
線性判別分析法(LDA)
混合判別分析法(MDA)
二次判別分析法(QDA)
靈活判別分析法(Flexible Discriminant Analysis,FDA)
模型融合算法
模型融合算法將多個簡單的、分別單獨訓練的弱機器學習算法結合在一起,這些弱機器學習算法的預測以某種方式整合成一個預測通常這個整合后的預測會比單獨的預測要好一些構建模型融合算法的主要精力一般用于決定將哪些弱機器學習算法以什么樣的方式結合在一起模型融合算法是一類非常強大的算法,因此也很受歡迎常用的模型融合增強方法包括:
Boosting
Bagging
AdaBoost
堆疊泛化(混合)
GBM 算法
GBRT 算法
隨機森林
其他
還有很多算法都沒有涉及例如,支持向量機(SVM)應該被歸為哪一組?還是說它自己單獨成一組?我還沒有提到的機器學習算法包括:
特征選擇算法
Algorithm accuracy evaluation
Performance measures
再附一張思維導圖

-
機器學習
+關注
關注
66文章
8510瀏覽量
134839
發布評論請先 登錄
常用python機器學習庫盤點

17個機器學習的常用算法!






 工商網監
工商網監
評論