 未來已來,多傳感器融合感知是自動駕駛破局的關鍵
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
美國加州議會的公共事務委員會做出宣判:允許谷歌旗下Waymo和通用旗下Cruise的Robotaxi在舊金山不受限制地載客,即24×7全天候的、城區范圍不受限制、主駕無人的、且可以向乘客收費的Robotaxi運營。這標志著L4級自動駕駛迎來了新的里程碑,朝著商業化落地邁進了一大步。中國的車企也不甘落后:4月7日,廣汽埃安與滴滴自動駕駛宣布合資公司——廣州安滴科技有限公司獲批工商執照。廣汽埃安方面表示,這是L4級自動駕駛公司和車企為了打造Robotaxi量產車,在國內成立的首個合資公司。首款車型已完成產品定義,正在進行設計造型的聯合評審,計劃明年實現量產。未來已來,2024年是全球L3/L4級自動駕駛賽跑的元年。
馬斯克評論FSD 12.3版本的左轉彎操作就像人類司機一樣。如果FSD 12.3版本成功,將基本顛覆目前市場上的智能駕駛技術路線。基于“數據/算法/算力”的無人駕駛技術有著基本的判斷:在中短期內無法解決corner case長尾安全問題,十年內不太可能實現量產落地。隨著GPT大模型和特斯拉FSD端到端的出現,基于“數據-算力”的方法拋棄了傳統的算法和編程CODING,取得了巨大的進展;自動駕駛開始摒棄手動編碼規則和機器學習模型的方法,轉向全面采用端到端的神經網絡AI系統,它能模仿學習人類司機的駕駛,遇到場景直接輸入傳感器數據,再直接輸出轉向、制動和加速信號。模仿學習人類駕駛的關鍵的是具備人類的感知能力,多傳感器融合感知正是自動駕駛破局的關鍵。昱感微的雷視一體多傳感器融合方案就好像一雙比人眼更敏銳的眼睛,可以為自動駕駛系統提供更豐富更精準的視覺語言——目標與環境的多模態精準感知信息,使自動駕駛系統可以實時精準地感知道路上的各種狀況。
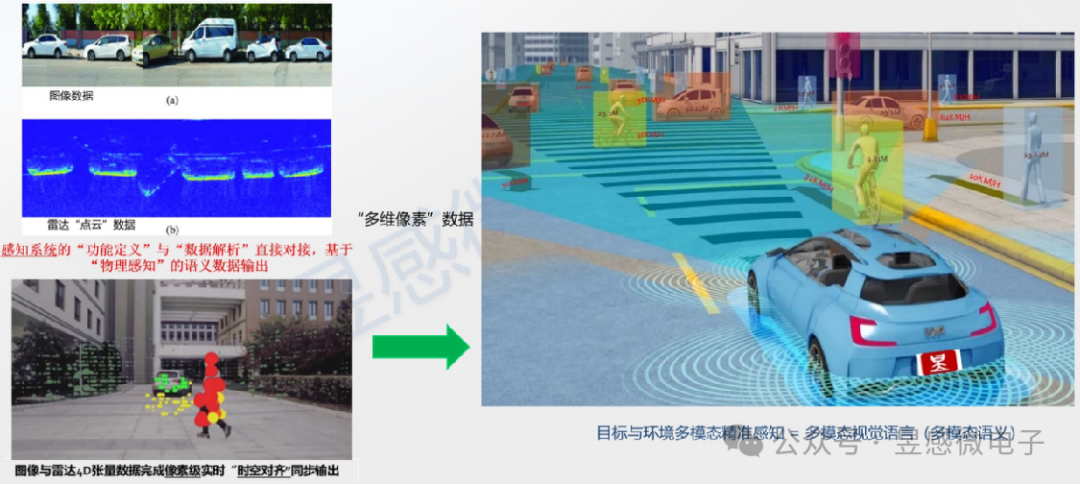
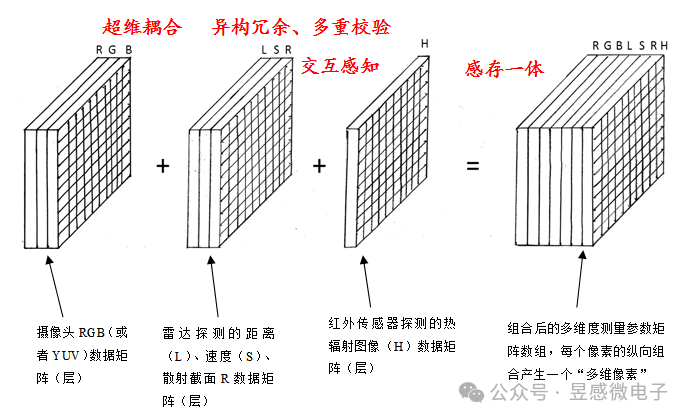
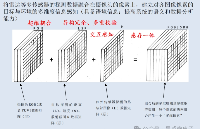
昱感微融合感知產品方案創新性地將可見光攝像頭、紅外攝像頭以及4D毫米波雷達的探測數據在前端(數據獲取時)交互,將各傳感器的探測數據“坐標統一、時序對齊”,圖像與雷達數據完成像素級實時“時空對齊同步”并以“多維像素”格式輸出。“多維像素”是昱感微的核心技術創新之一,它是指在可見光攝像頭像素信息上加上其它傳感器對于同源目標感知的信息,將感知系統的感知維度擴展以實現多維度(多模態)感知目標的完整信息。如下圖示例,芯片將攝像頭圖像數據,和雷達探測目標的距離、速度、散射截面R的感知數據,以及紅外傳感器探測的熱輻射圖像數據疊加組合到一起,以攝像頭的像素為顆粒度組合全部感知數據,每個像素不僅有視覺信息,還包含了4D毫米波雷達和紅外傳感器的探測數據,形成多維度(多模態)測量參數矩陣數組。基于圖像像素為基準+雷達數據的“多維像素”感知數據,與現有主流AI計算平臺完全兼容,它可以復用已有的圖像數據樣本,免除了產品的神經網絡訓練數據需要完全重新采集的困擾。
昱感微的融合感知技術采用最前沿的多傳感器前融合技術,攝像頭和雷達等多傳感器的探測數據在前端(數據獲取時)交互驗證,讓自動駕駛系統能感知到“看不見”的危險。例如,在反向車道有強遠光燈干擾的情況下,當雷達子系統探測到潛在運動目標時,融合感知系統可以引導本車的攝像頭針對運動目標做快速局部修正曝光(見下圖),以此實時獲取運動目標的分辨細節特征,并將局部修正曝光的圖像融合雷達數據傳輸至自動駕駛系統,避免撞擊危險發生。

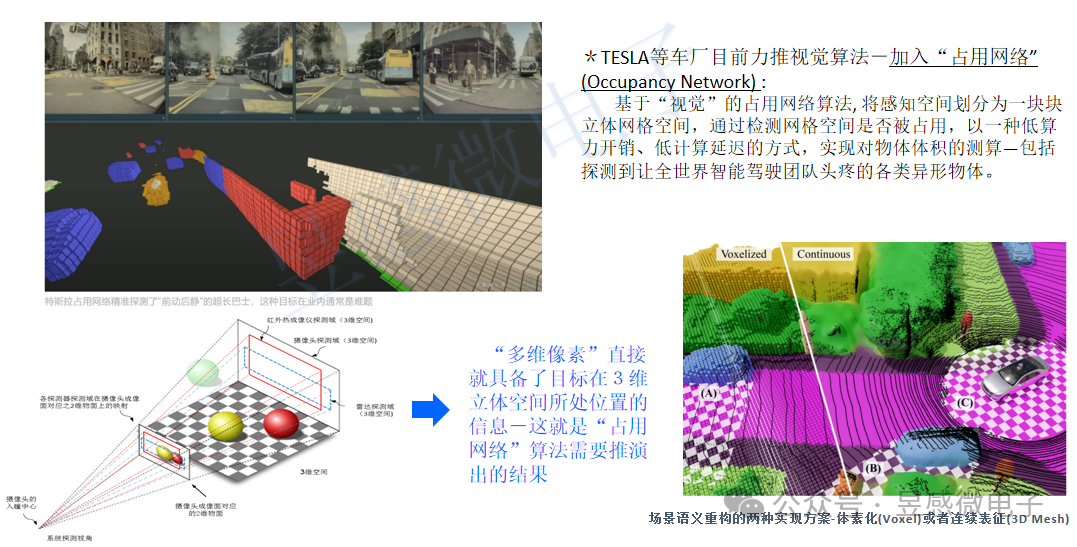
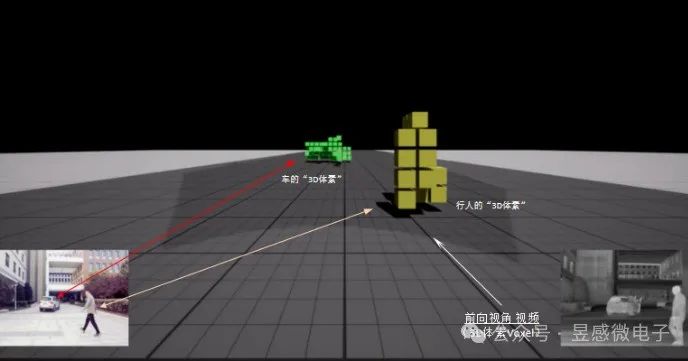
昱感微的融合感知技術方案的優勢在于1)是基于“物理感知”數據驅動,能很好地避免純視覺網絡的corner cases問題;2)傳感器前融合的方式可以最大限度地保留原始探測數據,并發揮各傳感器的優勢,使感知系統能夠不受天氣光線等場景限制,實時完成精準目標感知;3)支持目標的識別與樣本采樣同步完成,助力車廠建立數據優勢,這也是未來車廠的核心競爭力之一。特斯拉成功推出采用端到端方案的FSDV12版本,很大一個助力因素是特斯拉的巨大數據優勢,海量的視頻數據訓練使FSD越來越擬人化。不過,鑒于中國路況復雜并且與歐美道路差異較大,中國車企在數據訓練方面有望迎頭趕上,而昱感微的融合感知技術的感知數據可助力中國車企實現彎道超車:融合感知系統可同步完成目標識別與樣本采樣,也就是說車廠可以利用配備融合感知系統的汽車進行大數據采集,分析其廣大車主的駕駛數據來建立自身的數據優勢。另外,特斯拉的軟件能力現已成為差異化賣點,FSD套件的盈利模式采用一次性買斷制和按月訂閱制,且一次性購買價格經過多輪漲價,目前已升至15000美元。智能軟件差異化競爭和汽車應用付費模式很可能是未來汽車行業的趨勢。昱感微融合感知系統內含一個專用的數據獲取模塊,將目標的識別與有效樣本的獲取結合,可提供有效樣本的獲取函數,配合車廠開發。并且多維像素格輸出的感知數據在有效性和豐富度上都高于純視覺(視頻數據),可以快速提升AI神經網絡的訓練收斂率以及目標識別率,為車廠增加智能駕駛的核心競爭力。此外,多維像素還可以直接高效支持“占用網絡” (Occupancy Network)算法。占用網格是指將感知空間劃分為一個個立體網格(體素),而多維像素包含了目標的3D空間位置信息、目標的速度信息和材質信息,可以直接高效實時支持占用網格中的體素算法。Tesla目前在主推“BEV +Transformer+占用網絡”,國內華為GOD2.0和小米汽車也采用相同的架構,預計未來許多智能駕駛團隊都會引入“占用網絡”來提升系統能力。多維像素的應用前景非常廣闊。昱感微的融合感知技術+BEV +Transformer+占用網格有望成為L3/L4級自動駕駛最優的落地方案。
-
多傳感器
+關注
關注
0文章
81瀏覽量
15584 -
智能駕駛
+關注
關注
4文章
2779瀏覽量
49705 -
自動駕駛
+關注
關注
788文章
14212瀏覽量
169613
發布評論請先 登錄
技術分享 |多模態自動駕駛混合渲染HRMAD:將NeRF和3DGS進行感知驗證和端到端AD測試

激光雷達技術:自動駕駛的應用與發展趨勢

BEVFusion —面向自動駕駛的多任務多傳感器高效融合框架技術詳解

多傳感器融合在自動駕駛中的應用趨勢探究
一文聊聊自動駕駛測試技術的挑戰與創新

感知融合為自動駕駛與機器視覺解開當前無解場景之困
聊聊自動駕駛離不開的感知硬件
FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
自動駕駛汽車如何識別障礙物
自動駕駛識別技術有哪些
XV7181BB 陀螺儀傳感器在自動駕駛設備中的應用






 工商網監
工商網監
評論