 Mask R-CNN:自動從視頻中制作目標物體的GIF動圖
Mask R-CNN:自動從視頻中制作目標物體的GIF動圖

在上一篇文章中,我們介紹了用深度學習結合攝像機的方法自動檢測并拍攝小鳥的照片。今天,我們用另一種新穎的深度學習模型——Mask R-CNN,自動從視頻中制作目標物體的GIF動圖。
Mask R-CNN已經有很多應用了,論智君此前還介紹過Facebook利用這一模型實現全身AR的項目。不過在這個項目中,作者Kirk Kaiser使用的是MatterPort版本。它支持Python 3,擁有超棒的樣本代碼,也許是最容易安裝的版本了。
第一步,輸入正確的內容
在開始制作gif自動生成器時,我選擇先做一件最蠢的事,這種模式在有創意性編碼項目中表現得很好。
首先,輸入的視頻中只能含有一個人,不要嘗試跟蹤監測視頻中的多個人。這樣我們就可以將目標物體與其他對象隔離開,同時更容易評估模型掩蓋目標對象的程度如何。如果目標對象不見了,我們就能發現,同時還能看到模型識別邊框的噪聲。
我選用的是自己在后院拍攝的視頻。
用Python處理視頻
盡管用Python處理視頻有其他方法,但我更喜歡將視頻轉換為圖像序列,然后再使用ffmpeg將其轉換回來。
使用以下命令,我們就能從輸入的視頻中獲取一系列圖像。根據輸入的視頻來源,它可能在每秒24到60幀之間。你需要跟蹤每秒輸入的視頻幀數,以便在轉換后保持同步。
$ ffmpeg -i FILENAME.mp4 -qscale:v 2 %05d.jpg
這將創建一個5位、0填充的圖像序列,如果您輸入的視頻長度超過5位,則可以將%05d改成%09d。
數字序列將與視頻持續的時間一樣長(以秒為單位),乘以每秒的幀數。所以一個時長為三秒、每秒24幀的視頻,將有72幀。
由此,我們得到了一系列靜止的圖像,可以使用我們的靜態掩碼R-CNN代碼輸入。
完成了對圖像的處理后,稍后將使用以下命令把它們重新放回視頻中:
$ ffmpeg -r 60 -f image2 -i %05d.jpg OUTPUT.mp4
參數-r規定了每秒中我們需要使用構建輸出視頻的幀數。如果我們想放慢視頻,可以降低參數的值,如果想加快速度,可以增加參數的值。
按照順序,讓我們先用Mask R-CNN來檢測并處理圖像。
檢測并標記圖像
Matterport版的Mask R-CNN附帶了Jupyter Notebook,幫助深入了解Mask R-CNN的工作原理。
一旦你在本地設置好了repo,我建議在demo筆記本上運行,并評估圖像檢測工作的水平。
通常掩碼是無符號的8位整數,形狀與輸入的圖像一致。當沒有檢測到目標對象時,掩碼是0或者黑色。當檢測到對象時,掩碼是255或白色。
為了處理蒙版,我們需要把它作為一個通道,復制或粘貼另一張圖像。用類似下面的代碼,可以從每個視頻的圖像中將單個人物摳出來,生成一張透明底的圖像:
import numpy as np
import os
import coco
import model as modellib
import glob
import imageio
import cv2
# Root directory to project
ROOT_DIR = os.getcwd()
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Path to trained weights file
# Download this file and place in the root of your
# project (See README file for details)
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
classInferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
numFiles = len(glob.glob('extractGif/*.jpg'))
counter = 0
for i in range(1, numFiles):
filename = 'extractGif/%05d.jpg' % i
print("doing frame %s" % filename)
frame = cv2.imread(filename)
results = model.detect([frame], verbose=0)
r = results[0]
masky = np.zeros((frame.shape[0], frame.shape[1]), dtype='uint8')
humans = []
if r['rois'].shape[0] >= 1:
for b in range(r['rois'].shape[0]):
if r['class_ids'][b] == class_names.index('person'):
masky += r['masks'][:,:,b] * 255
humansM = r['masks'][:,:,b] * 255
y1, x1, y2, x2 = r['rois'][b]
humansCut = frame[y1:y2, x1:x2]
humansCut = cv2.cvtColor(humansCut.astype(np.uint8), cv2.COLOR_BGR2RGBA)
humansCut[:,:,3] = humansM[y1:y2, x1:x2]
humans.append(humansCut)
if len(humans) >= 1:
counter += 1
for j, human in enumerate(humans):
fileout = 'giffer%i/%05d.png' % (j, counter)
ifnot os.path.exists('giffer%i' % j):
os.makedirs('giffer%i' % j)
print(fileout)
#frame = cv2.cvtColor(frame.astype('uint8'), cv2.COLOR_BGRA2BGR)
imageio.imwrite(fileout, human)
其中的class_names變量非常重要,它表示我們用COCO數據集分出的不同事物的類別。然后只需要把列表中的任意類別的名字更換成if r[class_ids][b] == class_names.index(‘person’),你就可以從視頻中獲取帶有蒙版的版本了。
把圖片轉換成GIF
現在我們有了一組透明圖像,可以打開看看它們的效果。我的結果并不是很好,人物摳的不是很精致,不過也挺有趣的。
然后我們就可以將圖像輸入進ffmpeg中制作動圖了,只需要找到圖像序列的最大寬度(width)和高度(height),然后將其粘貼到一個新的圖像序列中:
import glob
from PIL importImage
maxW = 0
maxH = 0
DIRECTORY = 'wave-input'
numFiles = len(glob.glob(DIRECTORY + '/*.png'))
for num in range(numFiles - 1):
im = Image.open(DIRECTORY + '/%05d.png' % (num + 1))
if im.width > maxW:
maxW = im.width
if im.height > maxH:
maxH = im.height
for num in range(numFiles - 1):
each_image = Image.new("RGBA", (maxW, maxH))
im = Image.open(DIRECTORY + '/%05d.png' % (num + 1))
each_image.paste(im, (0,0))
each_image.save('gifready/%05d.png' % num)
上面的代碼打開了我們的giffer0這個目錄,并在所有圖像中迭代,尋找最大尺寸圖像的width和height。然后它將這些圖像都放到一個新目錄(gifready)中,我們就能將其生成gif。
在這里,我們利用Imagemagick生成gif:
$ convert -dispose Background *.png outty.gif
但是僅僅從視頻中自動生成動圖也沒什么好激動的,讓我們繼續把它們混合起來,看看會發生什么……
在Pygame或視頻中應用生成的GIFs
最近,我直接將這些提取的圖像用在了Pygame中。我并沒有將它們轉換成gifs,而是保留了原始PNG格式。
我自創了一個創意性小編程環境,其中包括一個setup和draw功能,將圖像序列作為輸入。使用這個設置,我可以將圖像旋轉、縮放或干擾它們。以下是代碼:
import pygame
import random
import time
import math
import os
import glob
imageseq = []
def setup(screen, etc):
global imageseq
numIn = len(glob.glob('wave-input/*.png'))
for i in range(numIn):
if os.path.exists('wave-input/%05d.png' % (i + 1)):
imagey = pygame.image.load('wave-input/%05d.png' % (i + 1)).convert_alpha()
imageseq.append(imagey)
counter = 1
def draw(screen, etc):
# our current animation loop frame
global counter
current0 = imageseq[counter % len(imageseq)]
counter += 1
for i in range(0, 1920, 200):
screen.blit(current0, (i, 1080 // 2 - 230))
它將每個目錄中的圖像加載到一個alphapygame.surface中。其中的每一個都被添加到列表中,然后我們可以在循環中blit或將每張圖片畫到屏幕上。
這只是基本設置,更高級的操作請看上面的代碼,或者到我的GitHub中查看其他有趣的實驗。
用提取的Mask修改輸入視頻
為了產生上圖的效果,我記錄了視頻的前n幀,以及人物(person)和滑板(skateboard)的位置。
然后我將把之前摳出來的圖一個一個疊好,最后粘貼最后一張圖像。
除此之外我還試著將我的蒙版和其他視頻混合起來。這里就是合成的一個案例:
同時調試環境和滑板者的每一幀,然后在環境上蓋上蒙版,覆蓋在滑板視頻的頂部。這個代碼也可以在我的GitHub里找到。
結語
想將深度學習與藝術結合,這種項目只是一個開始。另外還有一個名為OpenPose的模型,能夠預測一個人的動作,并且模型十分穩定。我計劃將OpenPose合并到未來的項目中,創建更有趣的作品。
-
視頻
+關注
關注
6文章
1972瀏覽量
73936 -
python
+關注
關注
56文章
4827瀏覽量
86760 -
深度學習
+關注
關注
73文章
5561瀏覽量
122795
原文標題:用Mask R-CNN自動創建動圖
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
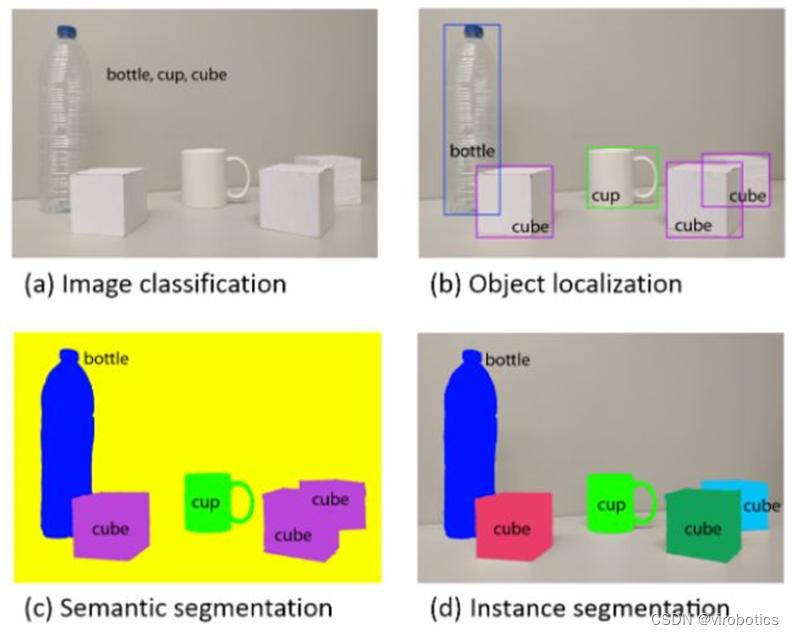
深度卷積神經網絡在目標檢測中的進展
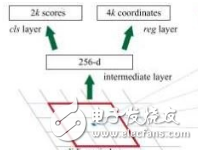
介紹目標檢測工具Faster R-CNN,包括它的構造及實現原理

什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通過語義分割進行任意形狀文本檢測與識別
手把手教你操作Faster R-CNN和Mask R-CNN
一種新的帶有不確定性的邊界框回歸損失,可用于學習更準確的目標定位

基于MASK模型的視頻問答機制設計方案

基于改進Faster R-CNN的目標檢測方法
用MATLAB制作GIF格式動圖資料下載

一種基于Mask R-CNN的人臉檢測及分割方法

基于Mask R-CNN的遙感圖像處理技術綜述
用于實例分割的Mask R-CNN框架
PyTorch教程14.8之基于區域的CNN(R-CNN)
PyTorch教程-14.8。基于區域的 CNN (R-CNN)






 工商網監
工商網監
評論