") 用于實(shí)例分割的Mask R-CNN框架
用于實(shí)例分割的Mask R-CNN框架
一、介紹
我們的方法稱為 Mask R-CNN,擴(kuò)展了 Faster RCNN ,方法是在每個(gè)感興趣區(qū)域 (RoI) 上添加一個(gè)用于預(yù)測分割掩碼的分支,與用于分類和邊界框回歸的現(xiàn)有分支并行(圖 1)。掩碼分支是應(yīng)用于每個(gè) RoI 的小型 FCN,以像素到像素的方式預(yù)測分割掩碼。鑒于 Faster R-CNN 框架,Mask R-CNN 易于實(shí)現(xiàn)和訓(xùn)練,這有助于廣泛的靈活架構(gòu)設(shè)計(jì)。此外,掩碼分支僅增加了少量計(jì)算開銷,從而實(shí)現(xiàn)了快速系統(tǒng)和快速實(shí)驗(yàn)。原則上,Mask R-CNN 是 Faster R-CNN 的直觀擴(kuò)展,但正確構(gòu)建 mask 分支對于獲得良好結(jié)果至關(guān)重要。最重要的是,F(xiàn)aster R-CNN 并不是為網(wǎng)絡(luò)輸入和輸出之間的像素到像素對齊而設(shè)計(jì)的。這在 RoIPool(處理實(shí)例的事實(shí)上的核心操作)如何為特征提取執(zhí)行粗略空間量化時(shí)最為明顯。為了解決錯(cuò)位問題,我們提出了一個(gè)簡單的、無量化的層,稱為 RoIAlign,它忠實(shí)地保留了精確的空間位置。盡管是一個(gè)看似很小的變化,但 RoIAlign 具有很大的影響:它將掩模準(zhǔn)確度提高了 10% 到 50%,在更嚴(yán)格的定位指標(biāo)下顯示出更大的收益。其次,我們發(fā)現(xiàn)解耦掩碼和類別預(yù)測至關(guān)重要:我們獨(dú)立地為每個(gè)類別預(yù)測一個(gè)二進(jìn)制掩碼,沒有類別之間的競爭,并依靠網(wǎng)絡(luò)的 RoI 分類分支來預(yù)測類別。相比之下,F(xiàn)CN 通常執(zhí)行逐像素多類分類,將分割和分類結(jié)合起來,并且根據(jù)我們的實(shí)驗(yàn),實(shí)例分割效果不佳。
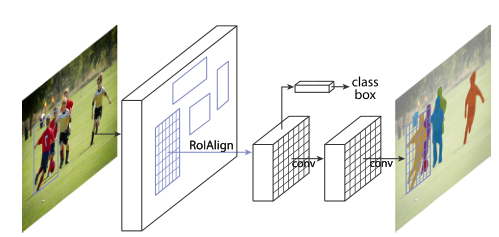
圖 1. 用于實(shí)例分割的 Mask R-CNN 框架

圖 2. 在 COCO 測試集上的 Mask R-CNN 結(jié)果。這些結(jié)果基于 ResNet-101,實(shí)現(xiàn)了 35.7 的掩碼 AP 并以 5 fps 運(yùn)行。掩碼以顏色顯示,并且還顯示了邊界框、類別和置信度.
作為一個(gè)通用框架,Mask R-CNN 與為檢測/分割開發(fā)的互補(bǔ)技術(shù)兼容,正如過去幾年在 Fast/Faster R-CNN 和 FCN 中廣泛見證的那樣。這份手稿還描述了一些改進(jìn)了我們在 中發(fā)表的原始結(jié)果的技術(shù)。由于其通用性和靈活性,Mask R-CNN 被 COCO 2017 實(shí)例分割競賽的三個(gè)獲勝團(tuán)隊(duì)用作框架(圖2),均顯著優(yōu)于之前的最新技術(shù)。我們已經(jīng)發(fā)布了代碼以促進(jìn)未來的研究。
二、MASK R-CNN
Mask R-CNN 在概念上很簡單:Faster R-CNN 對每個(gè)候選對象有兩個(gè)輸出,一個(gè)類標(biāo)簽和一個(gè)邊界框偏移量;為此,我們添加了輸出對象掩碼的第三個(gè)分支。因此,Mask R-CNN 是一個(gè)自然而直觀的想法。但是額外的掩碼輸出與類和框輸出不同,需要提取更精細(xì)的對象空間布局。接下來,我們介紹 Mask R-CNN 的關(guān)鍵元素,包括像素到像素對齊,這是 Fast/Faster R-CNN 的主要缺失部分。更快的 R-CNN。我們首先簡要回顧一下 Faster R-CNN 檢測器 。Faster R-CNN 由兩個(gè)階段組成。第一階段,稱為區(qū)域提議網(wǎng)絡(luò),提出候選對象邊界框。第二階段,本質(zhì)上是 Fast R-CNN,使用 RoIPool 從每個(gè)候選框中提取特征,并執(zhí)行分類和邊界框回歸。兩個(gè)階段使用的特征可以共享以加快推理速度。掩碼 R-CNN。Mask R-CNN 采用相同的兩階段程序,具有相同的第一階段(即 RPN)。在第二階段,在預(yù)測類和框偏移的同時(shí),Mask R-CNN 還為每個(gè) RoI 輸出一個(gè)二進(jìn)制掩碼。這與最近的系統(tǒng)形成對比,其中分類取決于掩碼預(yù)測。我們的方法遵循了 Fast R-CNN 的原則,它并行應(yīng)用邊界框分類和回歸(結(jié)果證明這在很大程度上簡化了原始 R-CNN的多階段管道)。
為了解決量化時(shí)引入 RoI 和提取的特征之間的錯(cuò)位,我們提出了一個(gè) RoIAlign 層,它消除了 RoIPool 的苛刻量化,將提取的特征與輸入正確對齊。我們提出的改變很簡單:我們避免對 RoI 邊界或 bin 進(jìn)行任何量化(即,我們使用 x/16 而不是 [x/16])。我們使用雙線性插值來計(jì)算每個(gè) RoI 箱中四個(gè)定期采樣位置的輸入特征的精確值,并聚合結(jié)果(使用最大值或平均值)。請參見圖 3 了解我們的實(shí)現(xiàn)細(xì)節(jié)。我們注意到,只要沒有對所涉及的任何坐標(biāo)進(jìn)行量化,結(jié)果對四個(gè)采樣點(diǎn)在 bin 中的位置或采樣的點(diǎn)數(shù)不敏感。
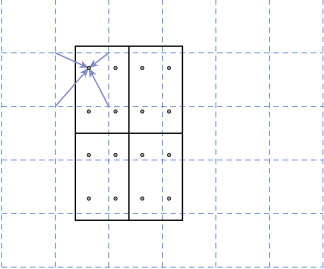
圖3.RoIAlign 的實(shí)現(xiàn):虛線網(wǎng)格是在其上執(zhí)行 RoIAlign 的特征圖,實(shí)線表示 RoI(在此示例中具有 2?2 個(gè) bin),點(diǎn)表示每個(gè) bin 內(nèi)的 4 個(gè)采樣點(diǎn)。每個(gè)采樣點(diǎn)的值是通過特征圖上附近網(wǎng)格點(diǎn)的雙線性插值計(jì)算的。不對任何涉及 RoI、其 bin 或采樣點(diǎn)的坐標(biāo)執(zhí)行量化。.使用原始輸出反饋(RF)和模式相似性生物反饋(PSB)進(jìn)行訓(xùn)練的假設(shè)效果。聚類表示與投影到2D子空間(即,在步驟1中創(chuàng)建的訓(xùn)練空間)上的運(yùn)動(dòng)類相關(guān)聯(lián)的多維數(shù)據(jù)(特征)集合。C1已經(jīng)用這兩種方法進(jìn)行了再培訓(xùn)(結(jié)果是C1Rf和C1OB)。
對于網(wǎng)絡(luò)頭,我們密切遵循之前工作中提出的架構(gòu),我們在其中添加了一個(gè)完全卷積的掩碼預(yù)測分支。具體來說,我們從 ResNet 和 FPN 論文中擴(kuò)展了 Faster R-CNN 盒頭。詳細(xì)信息如圖 4 所示。ResNetC4 主干上的頭部包括 ResNet 的第 5 階段(即 9 層“res5”),這是計(jì)算密集型的。對于 FPN,主干已經(jīng)包含 res5,因此允許使用更少過濾器的更高效的頭部。
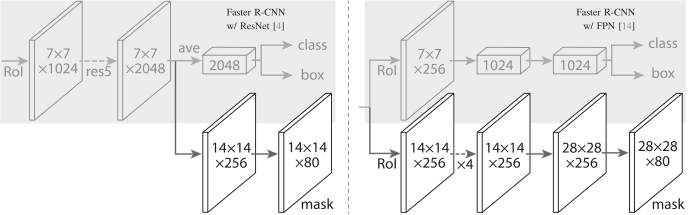
圖4. 頭部架構(gòu)
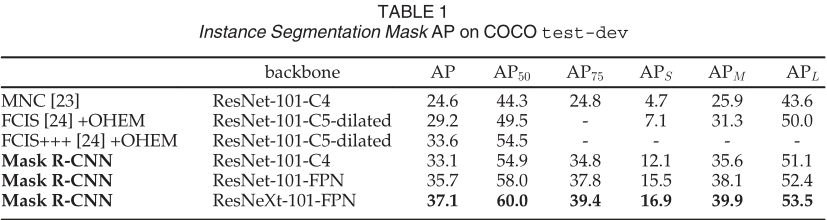
MNC 和 FCIS分別是 COCO 2015 和 2016 細(xì)分挑戰(zhàn)賽的獲勝者。沒有花里胡哨的東西,Mask R-CNN 優(yōu)于更復(fù)雜的 FCIS+++,其中包括多尺度訓(xùn)練/測試、水平翻轉(zhuǎn)測試和 OHEM。所有條目都是單模型結(jié)果。
我們將 Mask R-CNN 與表 1 中實(shí)例分割中的最先進(jìn)方法進(jìn)行了比較。我們模型的所有實(shí)例都優(yōu)于先前最先進(jìn)模型的基線變體。
Mask R-CNN 輸出在圖 2 和圖 5 中可視化。即使在具有挑戰(zhàn)性的條件下,Mask R-CNN 也能取得良好的效果。在圖 6 中,我們比較了我們的 Mask R-CNN 基線和 FCIS+++ 。FCIS+++ 在重疊實(shí)例上表現(xiàn)出系統(tǒng)性偽影,這表明它受到實(shí)例分割基本困難的挑戰(zhàn)。Mask R-CNN 沒有顯示出這樣的偽影。

圖 5. Mask R-CNN 在 COCO 測試圖像上的更多結(jié)果,使用 ResNet-101-FPN,以 5 fps 運(yùn)行,具有 35.7 mask AP

圖 6. FCIS+++(上)與 Mask R-CNN(下,ResNet-101-FPN)。FCIS 在重疊對象上展示系統(tǒng)偽影。
三、 實(shí)驗(yàn):實(shí)例分割

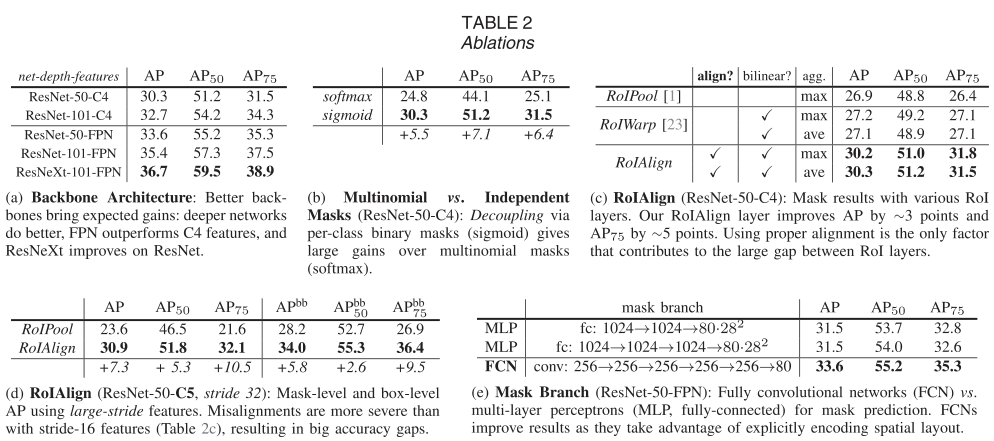
我們在 trainval35k 上進(jìn)行訓(xùn)練,在 minival 上進(jìn)行測試,并報(bào)告 mask AP,除非另有說明
表 2a 顯示了具有各種主干的 Mask R-CNN。在表 2b 中,我們將其與使用每像素 softmax 和多項(xiàng)損失(如 FCN 中常用的)進(jìn)行比較。這種替代方案將掩碼和類別預(yù)測的任務(wù)結(jié)合起來,并導(dǎo)致掩碼 AP 的嚴(yán)重?fù)p失(5.5 分)。這表明,一旦實(shí)例被分類為一個(gè)整體(通過框分支),就足以預(yù)測二進(jìn)制掩碼而無需考慮類別,這使得模型更容易訓(xùn)練。 我們提出的 RoIAlign 層的評估如表 2c 所示。對于這個(gè)實(shí)驗(yàn),我們使用 ResNet50-C4 主干,步長為 16。
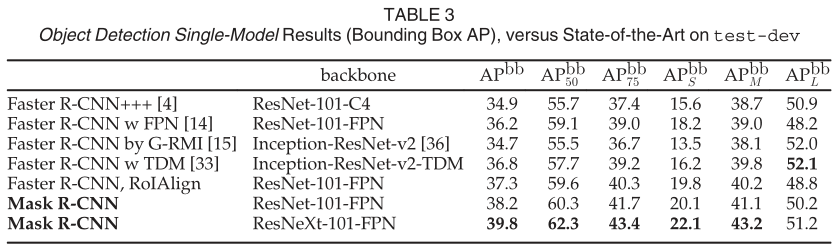
我們將 Mask R-CNN 與表 3 中最先進(jìn)的 COCO 邊界框目標(biāo)檢測進(jìn)行了比較。對于這個(gè)結(jié)果,即使訓(xùn)練了完整的 Mask R-CNN 模型,也只使用了分類和框輸出推理(掩碼輸出被忽略)。使用 ResNet-101-FPN 的 Mask R-CNN 優(yōu)于所有先前最先進(jìn)模型的基本變體,包括 G-RMI 的單模型變體,它是 COCO 2016 檢測挑戰(zhàn)賽的獲勝者。使用 ResNeXt-101-FPN,Mask R-CNN 進(jìn)一步改進(jìn)了結(jié)果,與 (使用 Inception-ResNetv2-TDM)的最佳先前單個(gè)模型條目相比,框 AP 的邊距為 3.0 點(diǎn)。
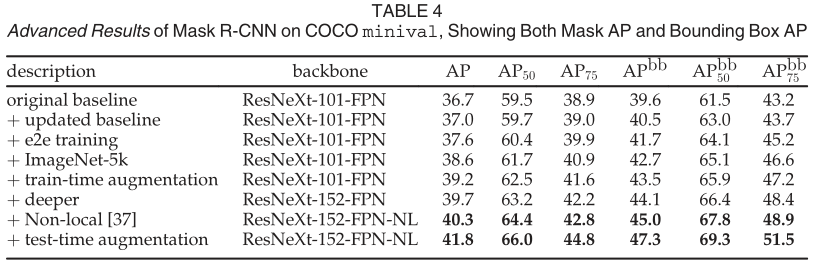
每行顯示一個(gè)額外的組件遞增到上面的行
Mask R-CNN 是一個(gè)通用框架,并且與在許多其他檢測/分割系統(tǒng)中看到的正交改進(jìn)兼容。為了完整起見,我們在表 4 中報(bào)告了 Mask RCNN 的一些高級結(jié)果。此表中的結(jié)果可以通過我們發(fā)布的代碼 (https://github.com/facebookresearch/Detectron) 重現(xiàn),這可以作為未來研究的更高基線。
總體而言,我們實(shí)現(xiàn)的改進(jìn)總共實(shí)現(xiàn)了 5.1 點(diǎn)掩碼 AP(從 36.7 到 41.8)和 7.7 點(diǎn)盒子 AP(從 39.6 到 47.3)增加。通常,改進(jìn)的每個(gè)組件都一致地增加了 mask AP 和 box AP,顯示了 Mask RCNN 作為框架的良好泛化。我們從具有不同超參數(shù)集的更新基線開始。我們將訓(xùn)練延長到 180k 次迭代,其中在 120k 和 160k 次迭代時(shí)學(xué)習(xí)率降低了 10。我們還將 NMS 閾值更改為 0.5(默認(rèn)值為 0.3)。更新后的基線有 37.0 mask AP 和 40.5 box AP。
四、 關(guān)鍵點(diǎn)估計(jì)與實(shí)景監(jiān)測
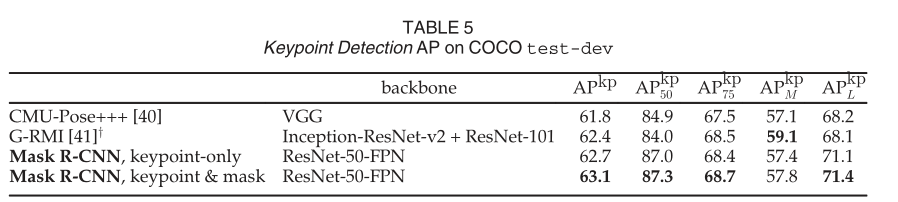
我們的 (ResNet-50-FPN) 是一個(gè)以 5 fps 運(yùn)行的單一模型。CMU-Pose+++ 是 2016 年競賽的獲勝者,它使用多尺度測試、使用 CPM 進(jìn)行后處理,并使用對象檢測器進(jìn)行過濾,增加了累積的 5 分(在個(gè)人交流中澄清)。y:G-RMI 在 COCO plus MPII (25k 圖像)上進(jìn)行訓(xùn)練,使用兩個(gè)模型(Inception-ResNet-v2 用于邊界框檢測,ResNet-101 用于關(guān)鍵點(diǎn))。

圖 7. 使用 Mask R-CNN (ResNet-50-FPN) 在 COCO 測試中的關(guān)鍵點(diǎn)檢測結(jié)果,以及從同一模型預(yù)測的人分割掩碼。該模型的關(guān)鍵點(diǎn) AP 為 63.1,運(yùn)行速度為 5 fps
更重要的是,我們有一個(gè)統(tǒng)一的模型,可以同時(shí)預(yù)測框、段和關(guān)鍵點(diǎn),同時(shí)以 5 fps 運(yùn)行。添加一個(gè)段分支(針對人員類別)在 test-dev 上將 APkp 提高到 63.1(表 5)。更多關(guān)于 minival 的多任務(wù)學(xué)習(xí)消融在表 6 中。將掩碼分支添加到僅盒子(即 Faster R-CNN)或僅關(guān)鍵點(diǎn)版本持續(xù)改進(jìn)了這些任務(wù)。然而,添加關(guān)鍵點(diǎn)分支會(huì)略微減少框/掩碼 AP,這表明雖然關(guān)鍵點(diǎn)檢測受益于多任務(wù)訓(xùn)練,但它反過來并不能幫助其他任務(wù)。然而,聯(lián)合學(xué)習(xí)所有三個(gè)任務(wù)使統(tǒng)一系統(tǒng)能夠同時(shí)有效地預(yù)測所有輸出(圖 7)。Cityscapes 的示例結(jié)果如圖 8 所示。

圖 8. 在 Cityscapes 測試(32.0 AP)上的 Mask R-CNN 結(jié)果。右下角的圖像顯示了故障預(yù)測。
五、結(jié)論
我們提出了一個(gè)簡單而有效的實(shí)例分割框架,該框架在邊界框檢測方面也顯示出良好的結(jié)果,并且可以擴(kuò)展到姿態(tài)估計(jì)。我們希望這個(gè)框架的簡單性和通用性將有助于未來對這些和其他實(shí)例級視覺識別任務(wù)的研究。
原文標(biāo)題:【AI+機(jī)器人】Mask-CNN 一種目標(biāo)識別與實(shí)例分割算法
文章出處:【微信公眾號:機(jī)器視覺智能檢測】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
審核編輯:湯梓紅
-
框架
+關(guān)注
關(guān)注
0文章
404瀏覽量
17808 -
分割
+關(guān)注
關(guān)注
0文章
17瀏覽量
12013 -
mask
+關(guān)注
關(guān)注
0文章
10瀏覽量
3060
原文標(biāo)題:【AI+機(jī)器人】Mask-CNN 一種目標(biāo)識別與實(shí)例分割算法
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
手把手教你使用LabVIEW實(shí)現(xiàn)Mask R-CNN圖像實(shí)例分割(含源碼)
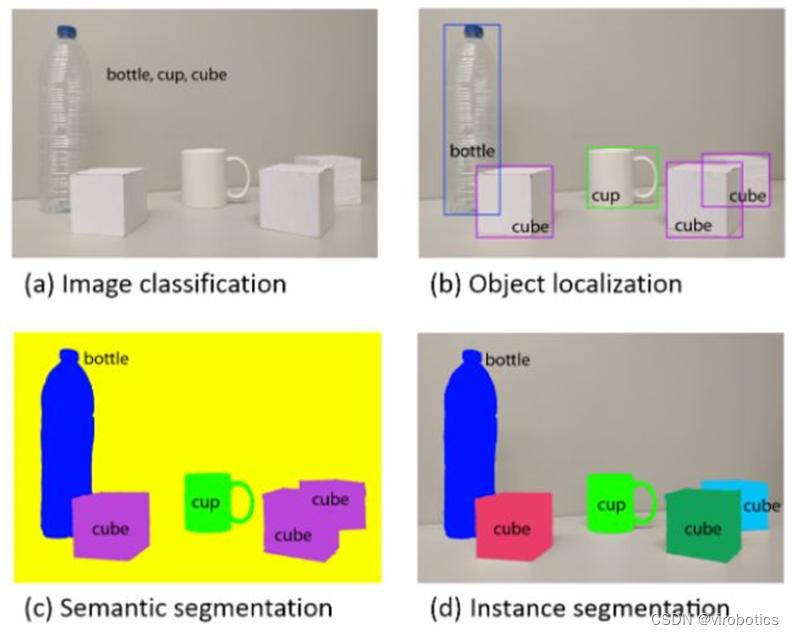
介紹目標(biāo)檢測工具Faster R-CNN,包括它的構(gòu)造及實(shí)現(xiàn)原理

Mask R-CNN:自動(dòng)從視頻中制作目標(biāo)物體的GIF動(dòng)圖
分享下Kaiming大神在CVPR‘18 又有了什么新成果?

什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通過語義分割進(jìn)行任意形狀文本檢測與識別
手把手教你操作Faster R-CNN和Mask R-CNN
FAIR何愷明、Ross等人最新提出實(shí)例分割的通用框架TensorMask
Facebook AI使用單一神經(jīng)網(wǎng)絡(luò)架構(gòu)來同時(shí)完成實(shí)例分割和語義分割

一種基于Mask R-CNN的人臉檢測及分割方法

基于Mask R-CNN的遙感圖像處理技術(shù)綜述
深度學(xué)習(xí)部分監(jiān)督的實(shí)例分割環(huán)境
3D視覺技術(shù)內(nèi)容理解領(lǐng)域的研究進(jìn)展
PyTorch教程14.8之基于區(qū)域的CNN(R-CNN)

PyTorch教程-14.8。基于區(qū)域的 CNN (R-CNN)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論