 什么是Mask R-CNN?Mask R-CNN的工作原理
什么是Mask R-CNN?Mask R-CNN的工作原理
編者按:發展至今,計算機視覺已經產生了不少令人驚嘆的應用,但一提到它,人們首先想到的總是人臉檢測、物品識別……除去已經發展得很成熟的人臉識別技術,我們難道只能用檢測室內物品來練習技巧嗎?作為一個極具工程價值的領域,也許大家應當擴張技術應用的廣度,把它和現實場景結合起來,真正做一些更接地氣的嘗試。
本文旨在構建一個自定義Mask R-CNN模型,它可以檢測汽車車身的損壞區域(如下圖所示)。這背后的應用理念是,購買二手車時,消費者首先會關注車身刮擦情況,有了這個模型,他們足不出戶就能大致了解車子情況,避免被坑。而對于日常生活中的小事故,如果用戶只需上傳圖片就能完成車輛破損鑒定,保險公司的索賠效率也會大幅提高。
什么是Mask R-CNN?
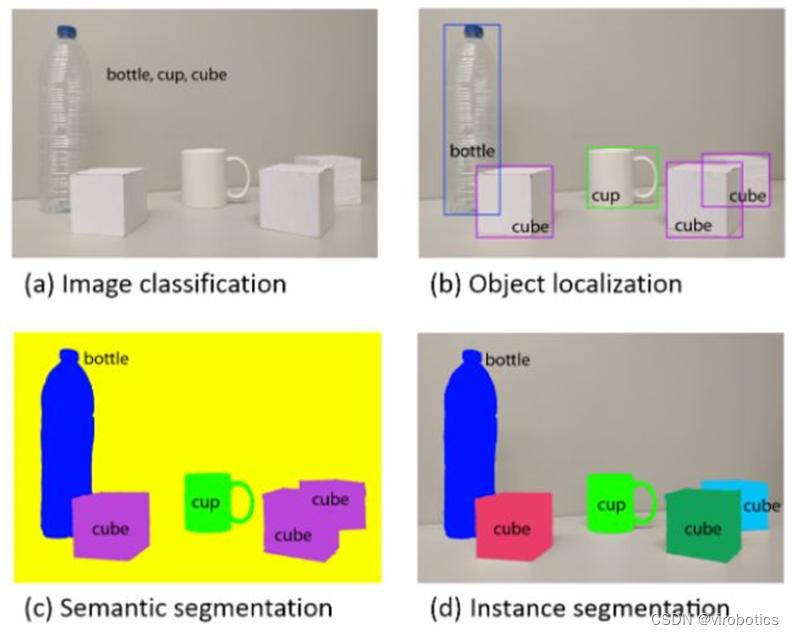
Mask R-CNN是一個實例分割模型,它能確定圖片中各個目標的位置和類別,給出像素級預測。所謂“實例分割”,指的是對場景內的每種興趣對象進行分割,無論它們是否屬于同一類別——比如模型可以從街景視頻中識別車輛、人員等單個目標。下圖是在COCO數據集上訓練好的Mask R-CNN,如圖所示,大到每一輛車,小到單根香蕉,它都能用窗口標出目標物品在畫面中的像素位置。
不同于Faster R-CNN這樣的經典對象檢測模型,Mask R-CNN的一個特點是可以給窗口內表示對象輪廓的像素著色。可能有人會覺得這是個雞肋功能,但它對自動駕駛汽車和機器人控制意義非凡:
著色可以幫助汽車明確道路上各目標的具體像素位置,從而避免發生碰撞;
如果機器人想抓取某個目標物品,它就需要知道位置信息(如亞馬遜的無人機)。
如果只是單純想在COCO上訓練Mask R-CNN模型,最簡單的方法是調用Tensorflow Object Detection API,具體內容Github都有,此處不再詳談。
Mask R-CNN的工作原理
在構建Mask R-CNN模型之前,我們首先來了解一下它的工作機制。
事實上,Mask R-CNN是Faster R-CNN和FCN的結合,前者負責物體檢測(分類標簽+窗口),后者負責確定目標輪廓。如下圖所示:
它的概念很簡單:對于每個目標對象,Faster R-CNN都有兩個輸出,一是分類標簽,二是候選窗口;為了分割目標像素,我們可以在前兩個輸出的基礎上增加第三個輸出——指示對象在窗口中像素位置的二進制掩模(mask)。和前兩個輸出不同,這個新輸出需要提取更精細的空間布局,為此,Mask R-CNN在Faster-RCNN上添加一個分支網絡:Fully Convolution Networ(FCN)。
FCN是一種流行的語義分割算法,所謂語義分割,就是機器自動從圖像中分割出對象區域,并識別其中的內容。該模型首先通過卷積和最大池化層把輸入圖像壓縮到原始大小的1/32,然后在這個細粒度級別進行分類預測。最后,它再用上采樣和deconvolution層把圖還原成原始大小。
因此簡而言之,我們可以說Mask R-CNN結合了兩個網絡——把Faster R-CNN和FCN納入同一巨型架構。模型的損失函數計算的是分類、生成窗口、生成掩模的總損失。
此外,Mask R-CNN還做了一些基礎改進,使其比FCN更精確,具體可以閱讀論文。
構建用于檢測汽車漆面情況的Mask R-CNN模型
GitHub:github.com/matterport/Mask_RCNN
這是一個在Python 3、Keras和TensorFlow上實現Mask R-CNN的現成資源。雖然最近TensorFlow目標檢測庫也更新了和Mask R-CNN相關的資源,但如果想一帆風順地搭建模型,我們還是推薦這個,用TensorFlow太容易出bug了。
當然,這不是不鼓勵大家去勇敢試錯,畢竟熟悉了這些錯誤,我們才能更好地理解整個過程。但這個實現絕對值得收藏。
收集數據
考慮到本文只是演示,這里我們只Google了66張受損車輛圖像(50張訓練集,16張驗證集)。如果想做個大點的數據集,建議把搜索關鍵詞設為“damaged car painting”,用中文容易出現一大堆補漆廣告,搜車禍則是大量引擎蓋變形圖。下面是一些圖像樣本
注釋數據
為了構建Mask R-CNN模型,首先我們要對圖像進行注釋,標出其中的損壞區域。我們使用的注釋工具是VGG Image Annotator?—?v 1.0.6,它有一個在線版本。除了常規圖形,它也允許我們繪制多邊形蒙版:
注釋完后,記得把它們下載下來,保存為.json格式。這里是注釋好的66幅圖。
訓練模型
完成上述步驟,現在我們就可以訓練模型了。首先,把GitHub里的東西復制下來,然后加載我們的圖像和注釋。
classCustomDataset(utils.Dataset):
def load_custom(self, dataset_dir, subset):
"""Load a subset of the Balloon dataset.
dataset_dir: Root directory of the dataset.
subset: Subset to load: train or val
"""
# 添加類別標簽,我們只有一個
self.add_class("damage", 1, "damage")
# 訓練集和驗證集
assert subset in ["train", "val"]
dataset_dir = os.path.join(dataset_dir, subset)
# 我們主要關心每個區域的x和y坐標
annotations1 = json.load(open(os.path.join(dataset_dir, "via_region_data.json")))
annotations = list(annotations1.values()) # don't need the dict keys
# 即使沒有任何注釋工具也會把圖像保存在JSON中
# 跳過未注釋圖像。
annotations = [a for a in annotations if a['regions']]
# 添加圖像
for a in annotations:
# 獲取構成每個對象實例輪廓多邊形點的x,y坐標
# 它們在shape_attributes里((參見上面的json格式))
polygons = [r['shape_attributes'] for r in a['regions'].values()]
# 輸入圖像大小后,load_mask()才能把多邊形轉成蒙版
image_path = os.path.join(dataset_dir, a['filename'])
image = skimage.io.imread(image_path)
height, width = image.shape[:2]
self.add_image(
"damage", ## 如果只有一類,只需在此處添加名稱即可
image_id=a['filename'], # use file name as a unique image id
path=image_path,
width=width, height=height,
polygons=polygons)
整段代碼在這里。我們復制了資源里的balloon.py文件,并對它做了修改。需要注意的是,這些代碼只適合包含一個類的問題。
此外,你也可以用這個筆記本內容可視化給定圖像上的蒙版。
如果要訓練,運行以下代碼:
## 如果用的是在COCO上預訓練的模型
python3 custom.py train --dataset=/path/to/datasetfolder --weights=coco
## 如果是繼續訓練您之前訓練過的模型
python3 custom.py train --dataset=/path/to/datasetfolder --weights=last
注:用一個GPU訓練10個epoch需要20-30分鐘。
驗證模型
至于模型的權重和偏差是不是正確的,大家可以參考這個筆記本
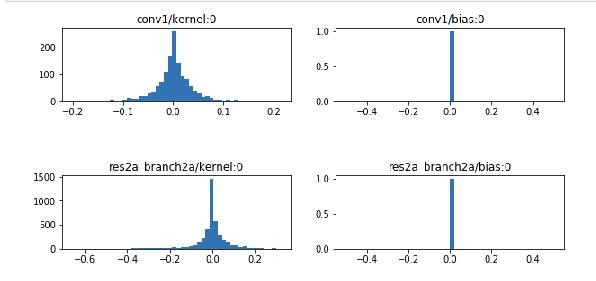
。里面列出了許多設置,可以作為輔助檢查工具。
實驗結果
如圖所示,模型準確標出了漆面損壞位置。當然,這并不是全部,我們在這個示例里只用了66幅圖,劃痕也比較明顯,所以這個模型的應用性非常有限。如果數據集夠大,我們完全可以期待一個能檢測微小傷痕的模型,當消費者在家里觀察汽車3D圖時,系統能自動標出一些不顯眼的痕跡,避免乘興而去,敗興而歸。
除了檢測車輛劃痕,你認為Mask R-CNN模型還有什么潛在應用呢?
-
機器人
+關注
關注
213文章
29537瀏覽量
211790 -
數據集
+關注
關注
4文章
1223瀏覽量
25305
原文標題:CV擁抱二手車:構建用于檢測汽車漆面破損的R-CNN模型(Python)
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
執行“mask_rcnn_demo.exe”時,無法找到帶有名稱的Blob:DetectionOutput是怎么回事?
介紹目標檢測工具Faster R-CNN,包括它的構造及實現原理

分享下Kaiming大神在CVPR‘18 又有了什么新成果?

引入Mask R-CNN思想通過語義分割進行任意形狀文本檢測與識別
手把手教你操作Faster R-CNN和Mask R-CNN
一種新的帶有不確定性的邊界框回歸損失,可用于學習更準確的目標定位

基于改進Faster R-CNN的目標檢測方法
一種基于Mask R-CNN的人臉檢測及分割方法

基于Mask R-CNN的遙感圖像處理技術綜述
用于實例分割的Mask R-CNN框架
3D視覺技術內容理解領域的研究進展
PyTorch教程14.8之基于區域的CNN(R-CNN)

PyTorch教程-14.8。基于區域的 CNN (R-CNN)






 工商網監
工商網監
評論