") 基于Arm Neoverse平臺(tái)的處理器革新生成式AI體驗(yàn)
基于Arm Neoverse平臺(tái)的處理器革新生成式AI體驗(yàn)

作者:Arm 基礎(chǔ)設(shè)施事業(yè)部 AI 解決方案架構(gòu)師 Na Li
(Arm 工程部技術(shù)總監(jiān) Milos Puzovic 和 Arm 基礎(chǔ)設(shè)施事業(yè)部軟件工程師 Nobel Chowdary Mandepudi 參與了本文撰寫)
Llama 是一個(gè)專為開發(fā)者、研究人員和企業(yè)打造的開源大語(yǔ)言模型 (LLM) 庫(kù),旨在推動(dòng)生成式 AI 的創(chuàng)新、實(shí)驗(yàn)及可靠地?cái)U(kuò)展。Llama 3.1 405B 是 Llama 系列中性能領(lǐng)先的模型之一,然而部署和使用如此大型的模型對(duì)缺乏足夠計(jì)算資源的個(gè)人或企業(yè)機(jī)構(gòu)來(lái)說(shuō)具有相當(dāng)大的挑戰(zhàn)。為了解決上述挑戰(zhàn),Meta 推出了 Llama 3.3 70B 模型。該模型在保持 Llama 3.1 70B 模型架構(gòu)的同時(shí),應(yīng)用了最新的后訓(xùn)練技術(shù)以提升模型評(píng)估性能。同時(shí),在推理、數(shù)學(xué)計(jì)算、常識(shí)理解、指令遵循和工具使用方面都有顯著改進(jìn)。盡管 Llama 3.3 70B 模型的體量顯著減小,其性能卻與 Llama 3.1 405B 模型相當(dāng)。
Arm 工程團(tuán)隊(duì)與 Meta 緊密協(xié)作,在 Google Axion 上對(duì) Llama 3.3 70B 模型進(jìn)行了推理性能評(píng)估。Google Axion 是基于 Arm Neoverse V2 平臺(tái)構(gòu)建的定制 AArch64 處理器系列,通過 Google Cloud 提供。與傳統(tǒng)的現(xiàn)成處理器相比,Google Axion 具備更高的性能、更低的能耗以及更強(qiáng)的可擴(kuò)展性,充分滿足了數(shù)據(jù)中心在 AI 時(shí)代的需求。
基準(zhǔn)測(cè)試結(jié)果顯示,在運(yùn)行 Llama 3.3 70B 模型時(shí),基于 Axion 處理器的 C4A 虛擬機(jī) (VM) 可提供順暢的 AI 體驗(yàn),并在不同的用戶批次大小下均達(dá)到了人類可讀性水平,即人們閱讀文本的平均速度,從而使開發(fā)者在基于文本的應(yīng)用中,在獲得與使用 Llama 3.1 405B 模型結(jié)果相當(dāng)?shù)母哔|(zhì)量輸出的同時(shí),顯著降低了對(duì)大量算力資源的需求。
Google Axion 處理器上運(yùn)行
Llama 3.3 70B 的 CPU 推理性能
Google Cloud 提供的基于 Axion 的 C4A 虛擬機(jī),最多可配備 72 個(gè)虛擬 CPU (vCPU) 和 576 GB RAM。在這些測(cè)試中,我們使用了中檔高性價(jià)比的 c4a-standard-32 機(jī)器類型來(lái)部署 4 位量化的 Llama 3.3 70B 模型。為了運(yùn)行我們的性能測(cè)試,我們使用了流行的 Llama.cpp 框架,該框架從 b4265 版本開始,已通過 Arm Kleidi 進(jìn)行了優(yōu)化。Kleidi 集成提供了優(yōu)化的內(nèi)核,以確保 AI 框架可以充分發(fā)揮 Arm CPU 的 AI 功能和性能。下面,我們來(lái)看看具體結(jié)果。
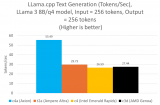
提示詞編碼速度是指語(yǔ)言模型處理和解釋用戶輸入的速度。如圖 1 所示,由于提示詞編碼利用了多核并行處理技術(shù),因此在不同批次大小的測(cè)試中,其性能始終穩(wěn)定在每秒約 50 個(gè)詞元左右。此外,不同提示詞規(guī)模測(cè)得的速度也相當(dāng)。
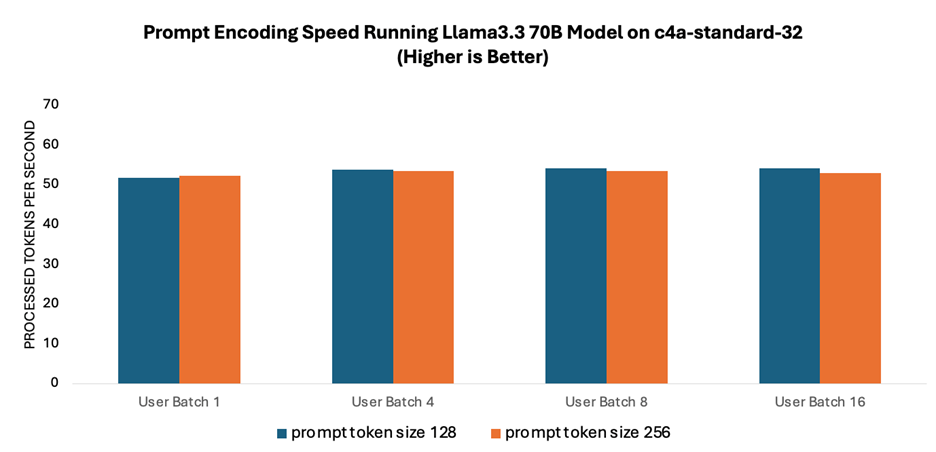
圖 1:運(yùn)行 Llama 3.3 70B 模型時(shí)的提示詞編碼速度
詞元生成速度衡量的是運(yùn)行 Llama 3.3 70B 模型時(shí)模型生成響應(yīng)的速度。Arm Neoverse CPU 利用先進(jìn)的 SIMD 指令(如 Neon 和 SVE)優(yōu)化機(jī)器學(xué)習(xí) (ML) 工作流,可加速通用矩陣乘法 (GEMM)。為了進(jìn)一步提高吞吐量,尤其是在處理更大批次時(shí),Arm 引入了專門的優(yōu)化指令,如有符號(hào)點(diǎn)積 (SDOT) 和矩陣乘法累加 (MMLA)。
如圖 2 所示,隨著用戶批次大小的增加,詞元生成的速度相應(yīng)提升,而在不同詞元生成規(guī)模下測(cè)得的速度保持相對(duì)一致。這種在更大批次下實(shí)現(xiàn)更高吞吐量的能力,對(duì)于構(gòu)建高效服務(wù)多用戶的可擴(kuò)展系統(tǒng)至關(guān)重要。
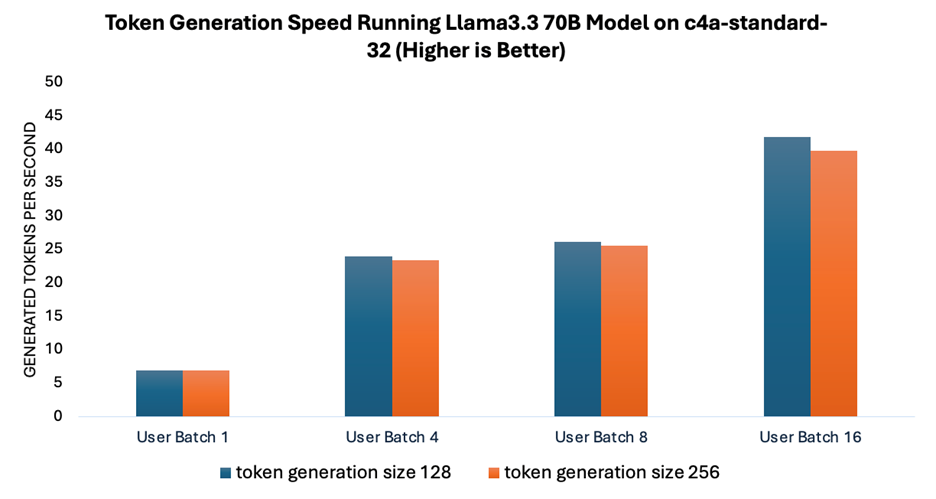
圖 2:運(yùn)行 Llama 3.3 70B 模型時(shí)的詞元生成速度
為了評(píng)估多用戶同時(shí)與模型交互時(shí)每個(gè)用戶所感受到的性能,我們測(cè)量了每批次詞元的生成速度。每批次詞元的生成速度至關(guān)重要,因?yàn)檫@直接影響用戶與模型交互時(shí)的實(shí)時(shí)體驗(yàn)。
如圖 3 所示,當(dāng)批次大小最多 4 時(shí),詞元生成速度可實(shí)現(xiàn)人類可讀性的平均水平。這表明,隨著系統(tǒng)擴(kuò)展以滿足多用戶需求,其性能仍然保持穩(wěn)定。為應(yīng)對(duì)更多并發(fā)用戶的需求,可以采用 vLLM 等服務(wù)框架。這些框架通過優(yōu)化 KV 緩存管理顯著提高了系統(tǒng)的可擴(kuò)展性。
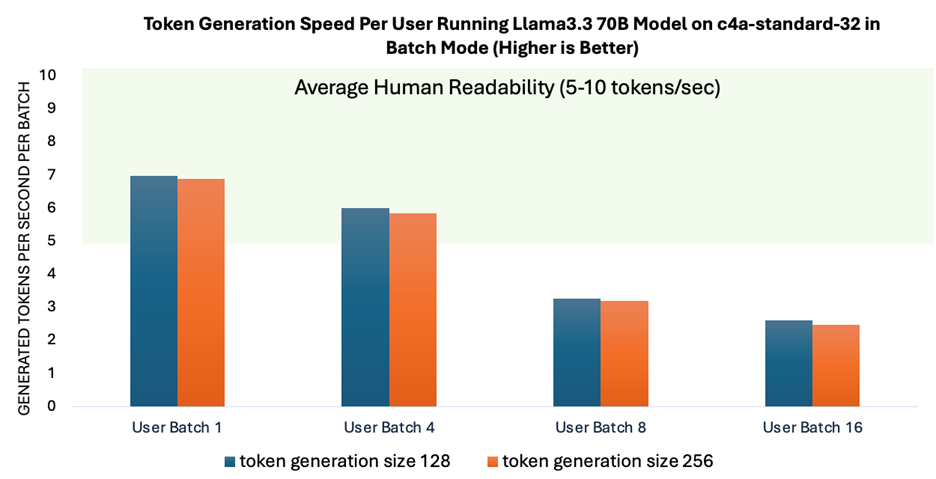
圖 3:不同批次大小下,以批次模式運(yùn)行 Llama 3.3 70B 模型時(shí)每個(gè)用戶的提示詞生成速度與人類可讀性的平均水平的對(duì)比
革新生成式 AI 體驗(yàn)
Llama 3.3 70B 模型能夠高效地發(fā)揮大規(guī)模 AI 的優(yōu)勢(shì),預(yù)示著潛在的變革。由于 Llama 3.3 70B 模型使用較小的參數(shù)規(guī)模,不僅使生成式 AI 處理技術(shù)更容易被生態(tài)系統(tǒng)采用,同時(shí)也減少了所需的計(jì)算資源。此外,Llama 3.3 70B 模型有助于提高 AI 的處理效率,這對(duì)于數(shù)據(jù)中心和云計(jì)算工作負(fù)載至關(guān)重要。在模型評(píng)估基準(zhǔn)方面,Llama 3.3 70B 的性能也與 Llama 3.1 405B 模型相當(dāng)。
通過基準(zhǔn)測(cè)試工作,我們展示了基于 Arm Neoverse 平臺(tái)的 Google Axion 處理器在運(yùn)行 Llama 3.3 70B 模型時(shí)可提供流暢高效的體驗(yàn),并在多個(gè)用戶批次大小測(cè)試中實(shí)現(xiàn)了與人類可讀性水平相當(dāng)?shù)奈谋旧尚阅堋?/p>
我們很榮幸能繼續(xù)與 Meta 保持密切的合作關(guān)系,在 Arm 計(jì)算平臺(tái)上實(shí)現(xiàn)開源 AI 創(chuàng)新,從而確保 Llama LLM 跨硬件平臺(tái)順暢、高效地運(yùn)行。
-
處理器
+關(guān)注
關(guān)注
68文章
19875瀏覽量
234760 -
ARM
+關(guān)注
關(guān)注
134文章
9346瀏覽量
376925 -
Neoverse
+關(guān)注
關(guān)注
0文章
12瀏覽量
4788 -
生成式AI
+關(guān)注
關(guān)注
0文章
531瀏覽量
786
原文標(biāo)題:在基于 Arm Neoverse 平臺(tái)的處理器上實(shí)現(xiàn)更高效的生成式 AI
文章出處:【微信號(hào):Arm社區(qū),微信公眾號(hào):Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
向Intel發(fā)起重型計(jì)算挑戰(zhàn) ARM發(fā)布Neoverse 處理器
基于NXP iMX6Q ARM處理器的Apalis iMX6Q ARM嵌入式平臺(tái)
Arm Neoverse N1軟件優(yōu)化指南
ARM嵌入式處理器結(jié)構(gòu)與應(yīng)用基礎(chǔ)
ARM推出了一個(gè)名叫Neoverse的處理器家族,叫板Intel
淺談arm處理器的優(yōu)勢(shì)
Arm推出Neoverse處理器家族 大有對(duì)標(biāo)Intel之勢(shì)
ARM推出新一代Neoverse處理器平臺(tái),面向5nm及3nm工藝性能提升30%以上
Arm推出新一代平臺(tái) Neoverse V2 平臺(tái)
Arm發(fā)布新一代Neoverse數(shù)據(jù)中心計(jì)算平臺(tái),AI負(fù)載性能顯著提升
Google Cloud推出基于Arm Neoverse V2定制Google Axion處理器
Arm新Arm Neoverse計(jì)算子系統(tǒng)(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3

Arm技術(shù)助力Google Axion處理器加速AI工作負(fù)載推理
如何在基于Arm Neoverse平臺(tái)的CPU上構(gòu)建分布式Kubernetes集群





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論