 中國電提出大模型推理加速新范式Falcon
中國電提出大模型推理加速新范式Falcon
近日,中國電信翼支付針對大模型推理加速的最新研究成果《Falcon: Faster and Parallel Inference of Large Language Models through Enhanced Semi-Autoregressive Drafting and Custom-Designed Decoding Tree》已被 AAAI 2025 接收。
論文中提出的 Falcon 方法是一種增強半自回歸投機解碼框架,旨在增強 draft model 的并行性和輸出質量,以有效提升大模型的推理速度。Falcon 可以實現約 2.91-3.51 倍的加速比,在多種數據集上獲得了很好的結果,并已應用到翼支付多個實際業務中。

論文標題: https://longbench2.github.io
論文鏈接:
https://arxiv.org/pdf/2412.12639
研究背景
大型語言模型 (LLMs) 在各種基準測試中展現了卓越的表現,然而由于自回歸 (AR) 解碼方式,LLMs 在推理過程中也面臨著顯著的計算開銷和延遲瓶頸。
為此,研究學者提出 Speculative Decoding (投機采樣) 方法。Speculative Decoding 會選擇一個比原始模型 (Target Model) 輕量的 LLM 作為 Draft Model,在 Draft 階段使用 Draft Model 連續生成若干個候選 Token。
在 Verify 階段,將得到的候選 Token 序列放入到原始 LLM 做驗證 & Next Token 生成,實現并行解碼。通過將計算資源導向于驗證預先生成的 token,Speculative Decoding 大大減少了訪問 LLM 參數所需的內存操作,從而提升了整體推理效率。
現有的投機采樣主要采用兩種 Draft 策略:自回歸 (AR) 和半自回歸 (SAR) draft。AR draft 順序生成 token,每個 token 依賴于前面的 token。這種順序依賴性限制了 draft 模型的并行性,導致顯著的時間開銷。
相比之下,SAR draft 同時生成多個 token,增強了 draft 過程的并行化。然而,SAR draft 的一個重要局限是它無法完全捕捉相同 block 內 draft tokens 之間的相互依賴關系,可能導致生成的 token 接受率較低。
因此,在投機采樣中,平衡低 draft 延遲與高推測準確性以加速 LLMs 的推理速度,是一個重大挑戰。
為此,翼支付提出了 Falcon,一個增強的半自回歸(SAR)投機解碼框架,旨在增強 draft model 的并行性和輸出質量,從而提升 LLMs 的推理效率。Falcon 集成了 Coupled Sequential Glancing Distillation(CSGD)方法,提高了 SAR draft model 的 token 接受率。
此外,Falcon還設計了一種專門的 decoding tree 來支持 SAR 采樣,使得 draft model 可以在一次前向傳播中生成多個 token,并且也能夠支持多次前向傳播。這種設計有效提升 LLMs 對 token 的接受率,進一步加快了推理速度。
研究方法
Falcon的架構如圖 1 所示,可以看到,該半自回歸解碼框架主要由三個組件構成:Embedding Layer、LM-Head和半自回歸解碼 Head。
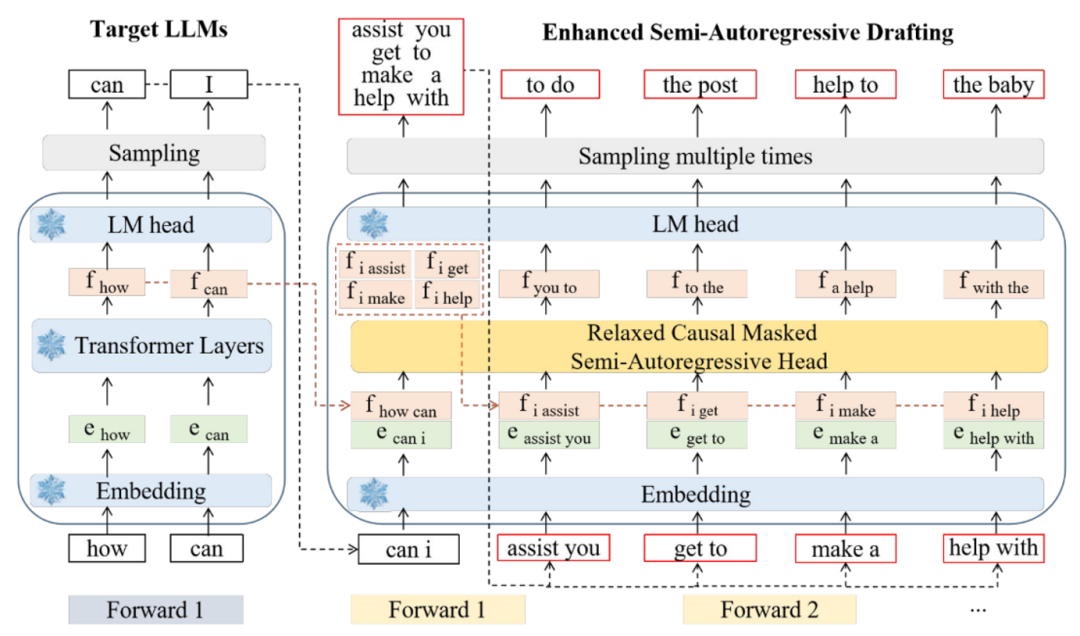
▲圖1.Falcon框架圖
具體來講,Falcon 將一個時間步長之前的連續特征序列和當前 token 序列連接起來,以同時預測接下來的 k 個標記。例如,當 k = 2 時,Falcon 使用初始特征序列 (f1, f2) 和提前一個時間步長的標記序列 (t2, t3) 來預測特征序列 (f3, f4)。
隨后,將預測得到的特征 (f3, f4) 與下一個標記序列 (t4, t5) 連接,形成新的輸入序列。這個新輸入序列用于預測后續的特征序列 (f5, f6) 和標記序列 (t6, t7),從而促進 draft 過程的繼續。Draft model 多次 forward 之后生成的 token 被組織成樹結構,輸入到大模型中進行 verify,通過 verify 的 token 被大模型接收,并基于此基礎開始下一個循環。
2.1 Coupled Sequential Glancing Distillation
當前推測解碼方法的準確性相對較低,主要原因是 token 之間的上下文信息不足。CSGD 通過用真實 token 和 hidden states 替換一些初始預測來改善這一點,將正確信息重新注入解碼過程中,從而提高后續預測的準確性和連貫性。模型結構及訓練流程如下圖:
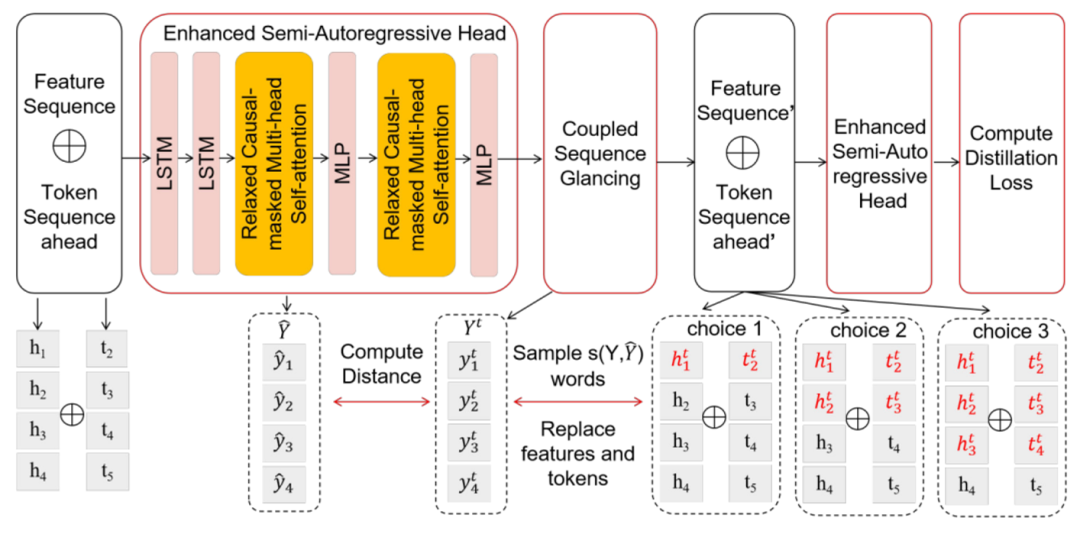
▲圖2. CGSD方法示意圖
在訓練過程中,一個時間步長之前的連續特征序列和當前 token 序列連接起來,并輸入到 draft model 中,形成一個融合序列,其維度為 (bs, seq_len, 2 * hidden_dim)。
draft model 由一個混合 Transformer 網絡組成,該網絡包括兩層 LSTM、Relaxed Causal-Masked 多頭注意力機制,以及 MLP 網絡。其中 LSTM 網絡將融合序列的維度減少到 (bs, seq_len, hidden_dim),并保留關于過去 token 的信息,從而提高模型的準確性。
Relaxed Causal-Masked 多頭注意力機制能夠在保持因果關系的同時,專注于輸入序列的相關部分。MLP 層進一步處理這些信息,以做出最終預測。
當序列首次通過 draft model 后,會生成初始的 token 預測 。然后,我們計算 draft model 的預測與真實 token Y 之間的漢明距離,以此來衡量預測的準確性。接下來,我們將一定數量連續預測的 token 序列
。然后,我們計算 draft model 的預測與真實 token Y 之間的漢明距離,以此來衡量預測的準確性。接下來,我們將一定數量連續預測的 token 序列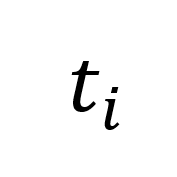 和特征序列
和特征序列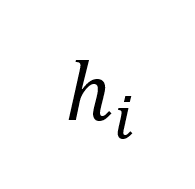 替換為來自 LLMs 的正確 token 序列
替換為來自 LLMs 的正確 token 序列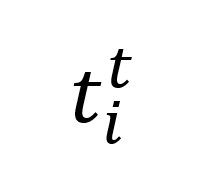 和特征序列
和特征序列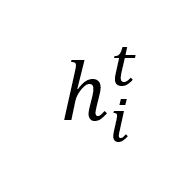 。
。
CSGD 與傳統的 glancing 方法不同,后者僅隨機替換 token。相反,CSGD 選擇性地同時替換預測之前的連續 token 和特征序列,如圖 2 中虛線框標注的 choice 1、choice 2、choice3 所示。
這種方法增強了對 token 間的關系的理解,并確保 draft model 能夠有效利用提前時間步長的 token 序列,這在 SAR 解碼中尤為重要。隨后,修正后的 token 和特征序列被重新輸入到 draft model 中以計算訓練損失。
在訓練過程中,我們采用了知識蒸餾,損失函數包括 draft model 的輸出特征與真實特征之間的回歸損失以及蒸餾損失,具體的損失函數如下:
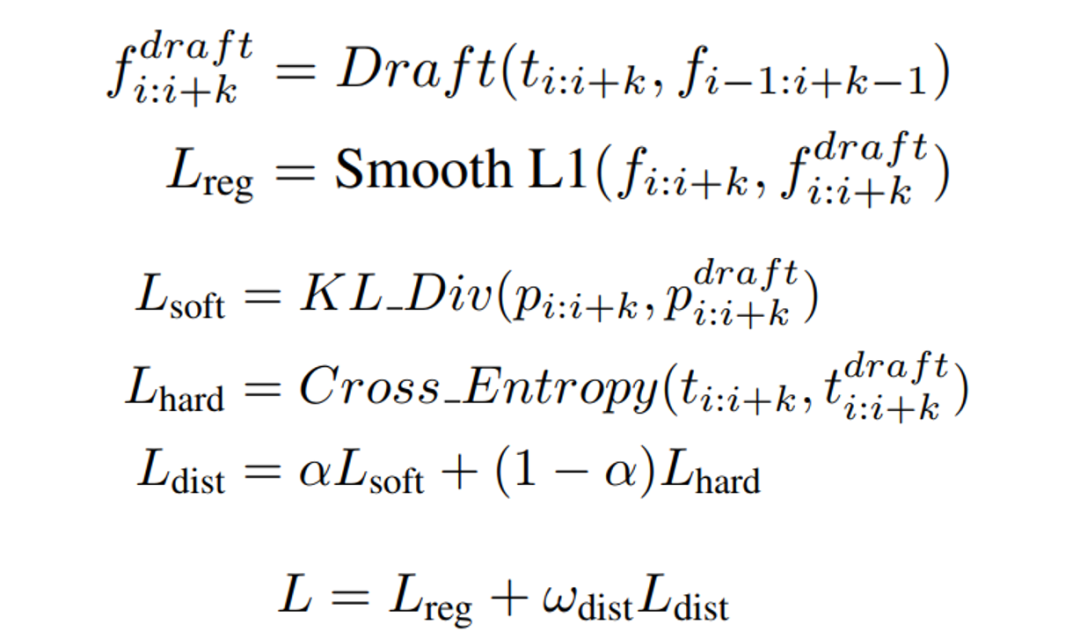
2.2 Custom-Designed Decoding Tree
當前基于樹的推測解碼方法通過在每個起草步驟生成多個 draft token 來提升推測效率。然而,這些方法仍然需要 draft model 按順序生成 token,這限制了推測效率的進一步提高。
為了解決這一局限性,CDT (Custom-Designed Decoding Tree) 支持 draft model 在一次前向傳遞中生成多個 token (k 個),并且在每個 draft 步驟中支持多次前向傳遞。因此,與現有方法相比,CDT 生成的草稿標記數量是其 k 倍。
Draft model 多次 forward 之后,生成的 token 被組織成樹結構,輸入到大模型中進行 verify。LLM 使用基于樹的并行解碼機制來驗證候選 token 序列的正確性,被接受的 token 及其相應的特征序列會在后續繼續進行前向傳遞。在傳統的自回歸(AR)解碼中,使用因果掩碼,其結構為下三角矩陣。它確保了前面的 token 不能訪問后面的信息。
相比之下,Falcon 采用了一種 causal 因果掩碼 (如圖 3 所示),允許模型訪問同一 k*k 的 block 內的 token 以及相應的之前的連續 token。這一增強顯著提高了 drafter 生成 token 的效率,使 LLM 能夠同時驗證更多的 token,從而加快了 LLM 的整體推理速度。
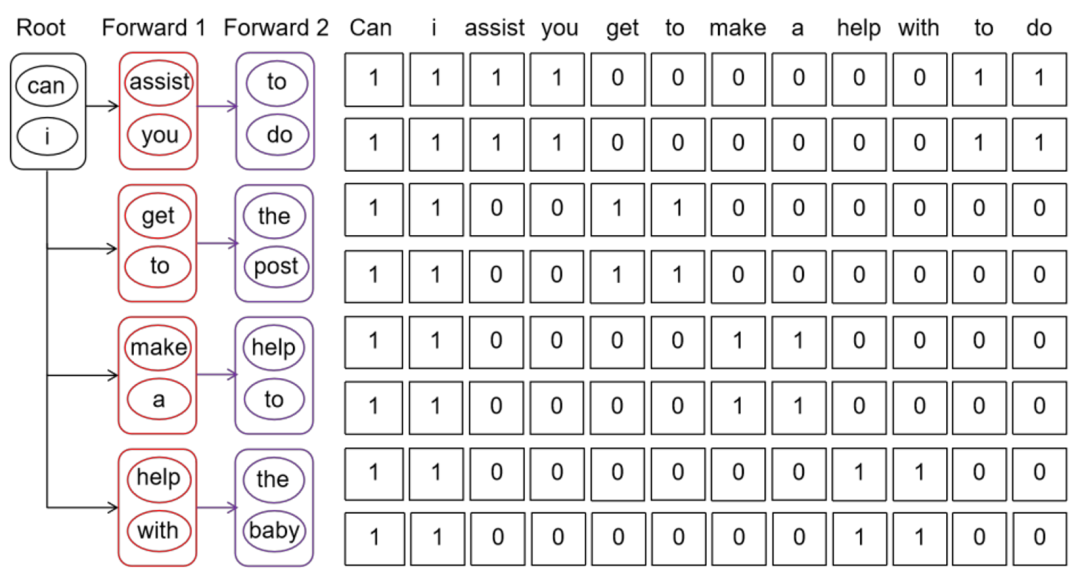
▲圖3. Custom-Designed Decoding Tree方法示意圖

實驗結果
我們在多個數據集和多個模型上進行了廣泛的實驗,驗證了本文方法的有效性。和現有的方法相比,Falcon 展現了優越的性能,具體如下圖:
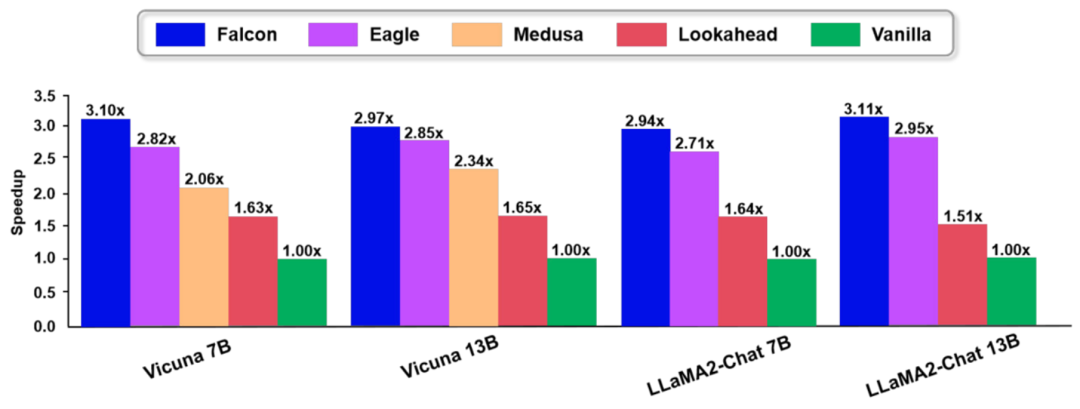
▲圖4. Falcon實驗結果圖
業務潛力
Falcon 大模型可以實現約 2.91-3.51 倍的加速比,相當于同等條件下推理成本下降至約原先的 1/3,從而大幅降低了大模型推理計算相關成本。
當前,Falcon 技術已轉化至翼支付大模型產品 InsightAI 平臺,并已服務諸如翼支付數字人客服、借錢-翼小橙、人力-翼點通、財務-翼小財等多個業務應用。
總結
投機采樣是大模型推理加速的一個核心方法。當前,主要的挑戰是如何提升 draft model 的準確率、采樣效率,并提升大模型的驗證效率。文章提出了 Falcon 方法,一種基于增強半自回歸投機解碼框架。Falcon 通過 CSGD 這種訓練方法以及半自回歸的模型設計,顯著提升了 draft model 的預測準確率以及采樣效率。
此外,為了讓大模型能驗證更多的 token,本文精心設計了一個 decoding tree,有效提升了 draft model 的效率,從而提升了驗證效率。Falcon 在多種數據集上可以實現約 2.91-3.51x 的加速比并應用到翼支付的眾多業務中,獲得了很好的效果。
-
大模型
+關注
關注
2文章
3059瀏覽量
3892
原文標題:AAAI 2025 | 加速比高達3.51倍!中國電提出大模型推理加速新范式Falcon
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何將一個FA模型開發的聲明式范式應用切換到Stage模型
谷歌新一代 TPU 芯片 Ironwood:助力大規模思考與推理的 AI 模型新引擎?
詳解 LLM 推理模型的現狀

英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
中國電信發布復雜推理大模型TeleAI-t1-preview

復旦提出大模型推理新思路:Two-Player架構打破自我反思瓶頸

阿里云開源推理大模型QwQ

高效大模型的推理綜述

FPGA和ASIC在大模型推理加速中的應用






 工商網監
工商網監
評論