 一文讀懂RAG基礎以及基于langchain的RAG實戰
一文讀懂RAG基礎以及基于langchain的RAG實戰

作者:京東科技 蔡欣彤
本文參與神燈創作者計劃 - 前沿技術探索與應用賽道
內容背景
隨著大模型應用不斷落地,知識庫,RAG是現在繞不開的話題,但是相信有些小伙伴和我一樣,可能會一直存在一些問題,例如:
?什么是RAG
?上傳的文檔怎么就能檢索了,中間是什么過程
?有的知道中間會進行向量化,會向量存儲,那他們具體的含義和實際過程產生效果是什么
?還有RAG = 向量化 + 向量存儲 + 檢索 么?
?向量化 + 向量存儲 就只是RAG 么?
為了解決這些困惑,我查找了langchain的官方文檔,并利用文檔中提供的方法進行了實際操作。這篇文章是我的學習筆記,也希望為同樣存在相同困惑的伙伴們能提供一些幫助。
最后代碼都上傳到coding了,地址是: https://github.com/XingtongCai/langchain_project/tree/main/translatorAssistant/basic_knowledge
一. RAG的基本概念
檢索增強生成(Retrieval Augmented Generation, RAG) 通過將語言模型與外部知識庫結合來增強模型的能力。RAG 解決了模型的一個關鍵限制:模型依賴于固定的訓練數據集,這可能導致信息過時或不完整。
審核編輯 黃宇
??
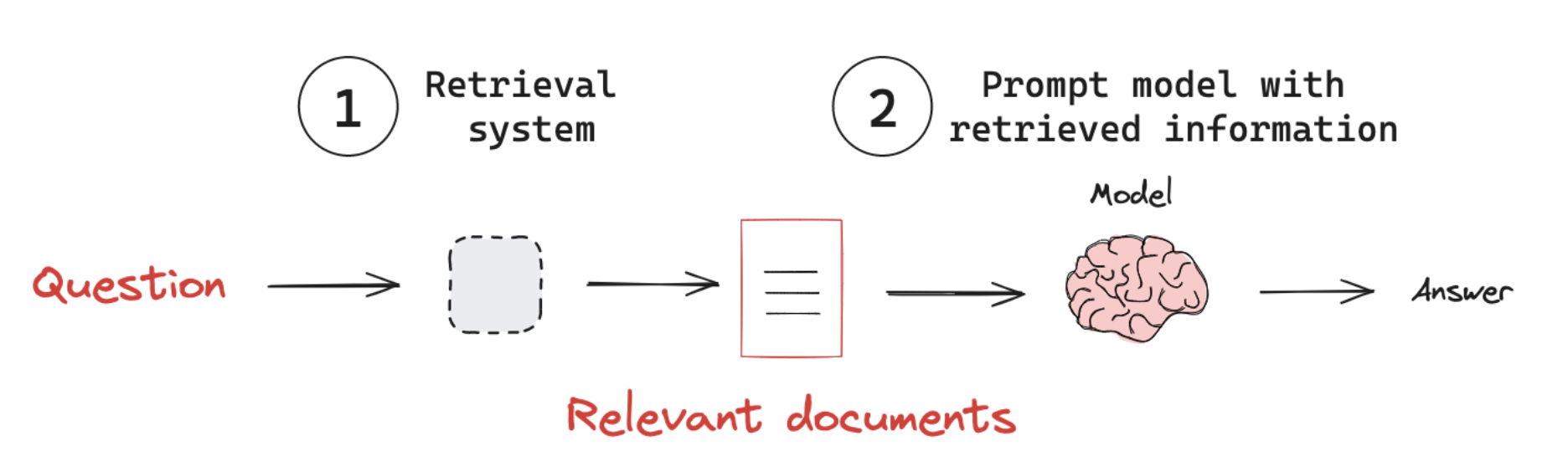
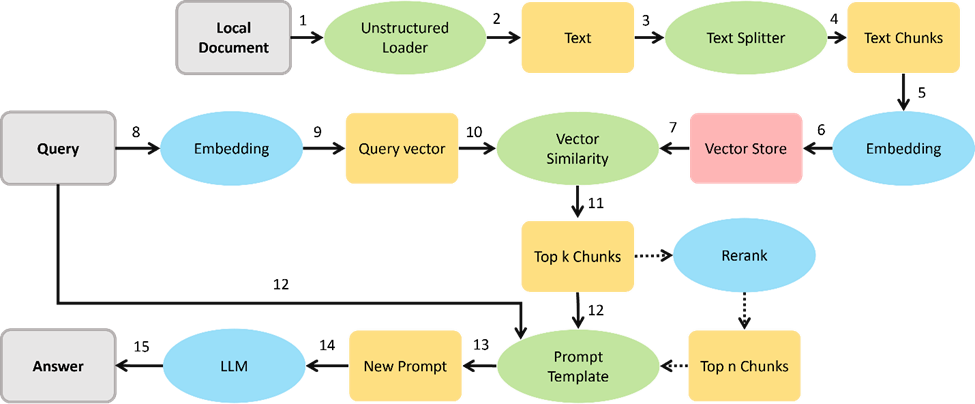
RAG大致過程如圖:
?接收用戶查詢 (Receive an input query)
?使用檢索系統根據查詢尋找相關信息 (Use the retrieval system to search for relevant information based on the query.)
?將檢索到的信息合并到提示詞,然后發送給LLM(Incorporate the retrieved information into the prompt sent to the LLM.)
?模型利用提供的上下文生成對查詢的響應(Generate a response that leverages the retrieved context.)
二. 關鍵技術
示例代碼地址: rag.ipynb ,用jupyter工具可以直接看并且調試
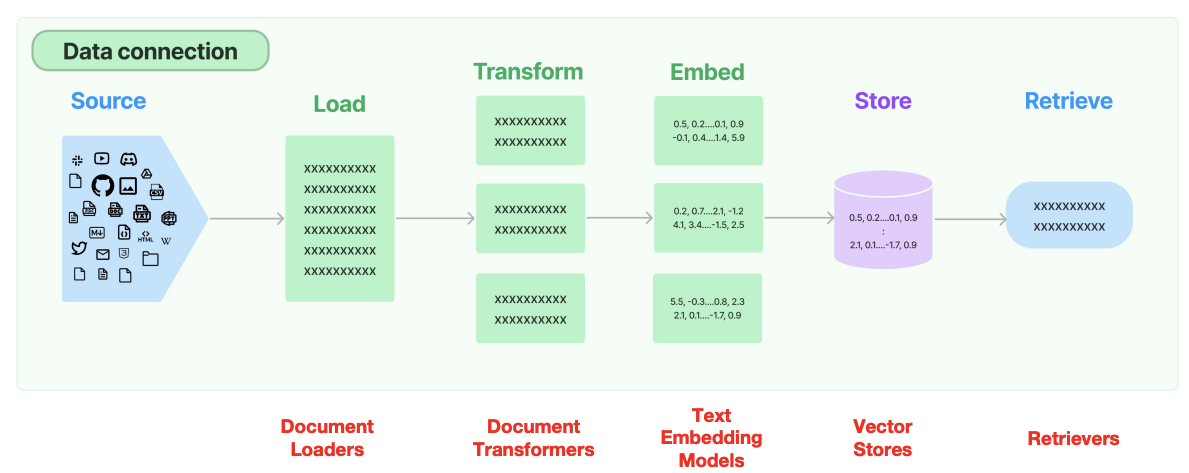
一個完整的 RAG流程 通常包含以下核心環節,每個環節都有明確的技術目標和實現方法:
?文檔加載和預處理
?文本分割
?數據向量化
?向量存儲與索引構建
?內容檢索
具體文檔: document_loaders?
整個langchain支持多種形式的數據源加載,這里面以加載pdf為例嘗試:
# document loader
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./DeepSeek_R1.pdf")
pages = []
# 異步加載前 11 頁
i = 0 # 手動維護計數器
async for page in loader.alazy_load():
if i >= 11: # 只加載前 11 頁
break
pages.append(page)
i+=1
print(f"{pages[0].metadata}n") // pdf的信息
print(pages[0].page_content) // 第一頁的內容
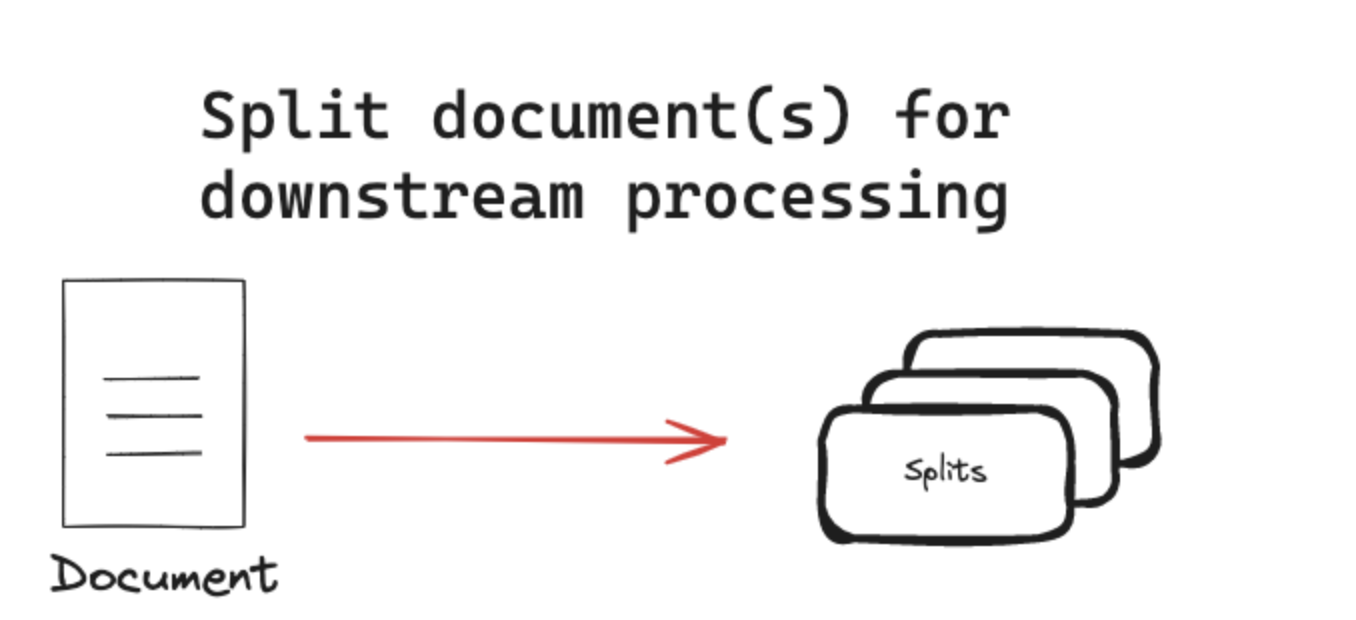
2.2 Text splitters 文本分割
參考文檔: Text splitters
文本分割器將文檔分割成更小的塊以供下游應用程序使用。
2.2.1 分割策略 - 基于長度(Length-based)
基于長度的分割是最直觀的策略是根據文檔的長度進行拆分。它的分割類型如下:
?Token-based :Splits text based on the number of tokens, which is useful when working with language models.
?Character-based: Splits text based on the number of characters, which can be more consistent across different types of text
常見CharacterTextSplitter用法,
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=20, chunk_overlap=0
)
texts = text_splitter.split_text(pages[0].page_content)
print(texts[0])
擴展補充: token和character的區別: token 是語言模型處理文本時的基本單位,通常是一個詞、子詞或符號。 Character 是文本的最小單位,例如英文字母、中文字符、標點符號等。 # 示例 from transformers import GPT2Tokenizer tokenizer = GPT2Tokenizer.from_pretrained("gpt2") text = "Hello,world!" tokens = tokenizer.tokenize(text) print(tokens) # ['Hello', ',', 'world', '!'] chunk_size = 5 chunks = [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)] print(chunks) # ['Hello', ',worl', 'd!']
2.1.2 分割策略 - 基于文本結構(Text-structured based )
文本自然地被組織成層次化的單元,例如段落、句子和單詞。可以利用這種固有結構來指導分割策略,創建能夠保持自然語言流暢性、在分割中保持語義連貫性并適應不同文本粒度級別的分割。RecursiveCharacterTextSplitter 支持這個方式。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每個片段的最大字符數
chunk_overlap=100, # 片段之間的重疊字符數
separators=["nn", "n"] # 分割符(按段落、句子、標點等)
)
chunks = text_splitter.split_documents(pages)
print(f"文檔被分割成 {len(chunks)} 個塊") # 文檔被分割成 37 個塊
2.1.3 分割策略 - 基于文檔結構(Document-structured based)
某些文檔具有固有的結構,例如 HTML、Markdown 或 JSON 文件。在這些情況下,基于文檔結構進行分割是有益的,因為它通常自然地分組了語義相關的文本。
# Markdown 文檔的分割 from langchain_community.document_loaders import UnstructuredMarkdownLoader from langchain.text_splitter import MarkdownHeaderTextSplitter # 加載 Markdown 文檔 loader = UnstructuredMarkdownLoader("example.md") documents = loader.load() # 使用 MarkdownHeaderTextSplitter 分割 splitter = MarkdownHeaderTextSplitter(headers_to_split_on=["#", "##", "###"]) chunks = splitter.split_text(documents[0].page_content) # 打印分割結果 for chunk in chunks: print(chunk)
2.1.4 分割策略 - 基于語義的分割(semantic-based splitting)
與之前的方法不同,基于語義的分割實際上考慮了文本的內容。雖然其他方法使用文檔或文本結構作為語義的代理,但這種方法直接分析文本的語義。核心方法是基于NLP模型,使用句子嵌入(Sentence-BERT)計算語義邊界,通過文本相似度突變檢測分割點
2.3 Embedding 向量化
參考文檔: Embedding models
嵌入模型(embedding models)是許多檢索系統的核心。嵌入模型將人類語言轉換為機器能夠理解并快速準確比較的格式。這些模型以文本作為輸入,生成一個固定長度的數字數組。嵌入使搜索系統不僅能夠基于關鍵詞匹配找到相關文檔,還能夠基于語義理解進行檢索。主要應用之一是rag.
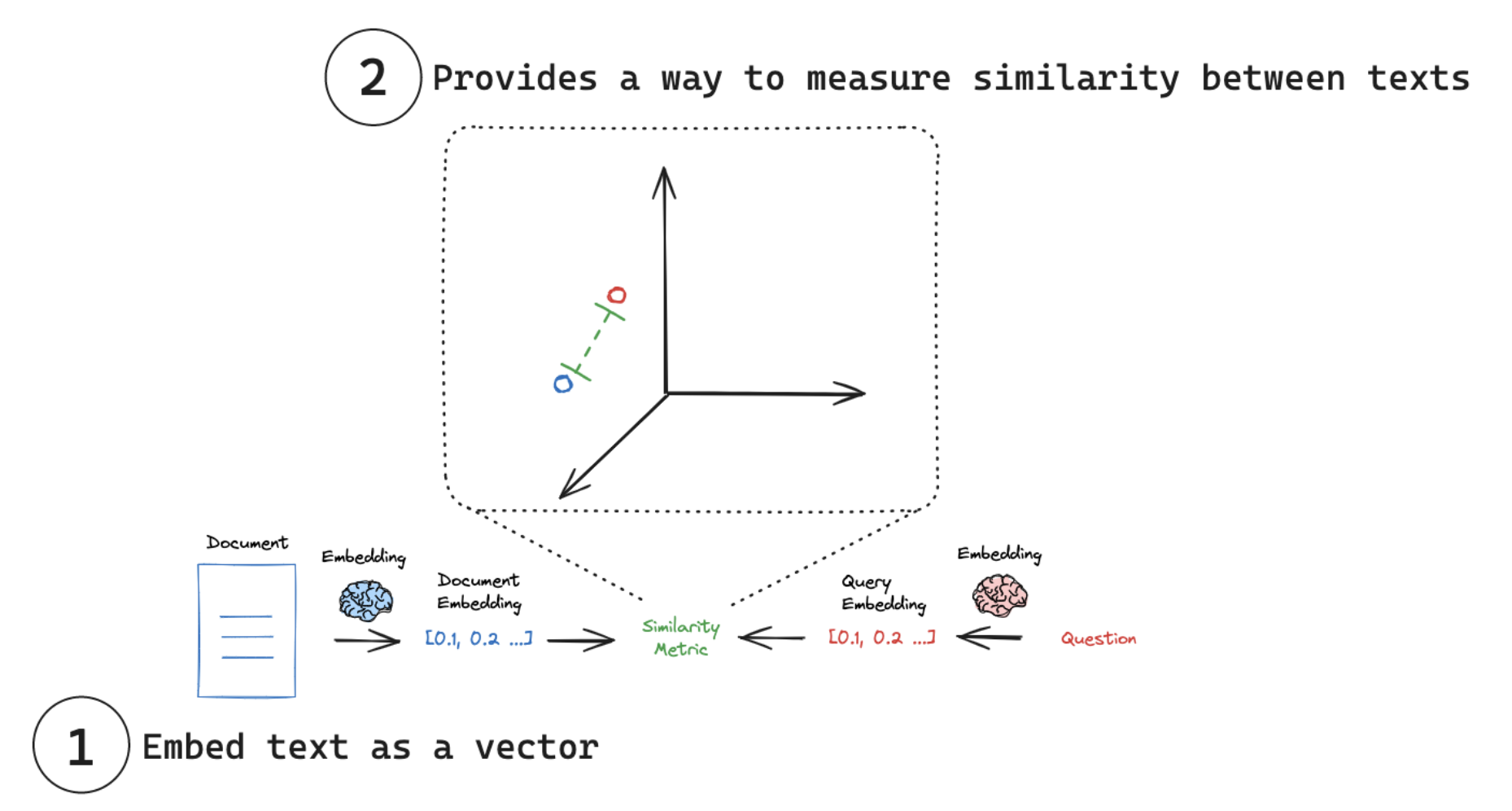
LangChain 提供了一個通用接口,用于與嵌入模型交互,并為常見操作提供了標準方法。這個通用接口通過兩個核心方法簡化了與各種嵌入提供商的交互:
?embed_documents:用于嵌入多個文本(文檔)。
?embed_query:用于嵌入單個文本(查詢)。
from langchain_openai import OpenAIEmbeddings # 初始化 OpenAI 嵌入模型 embeddings = OpenAIEmbeddings(model="text-embedding-ada-002") # 這里取第一個片段進行embedding,省token document_embeddings = embeddings.embed_documents(chunks[0].page_content) print("文檔嵌入:", document_embeddings[0]) # 文檔嵌入: [0.0063153719529509544, -0.00667550228536129,...] print(len(document_embeddings)) # 935
# 單個查詢
query = "這篇文章介紹DeepSeek的什么版本"
# 使用 embed_query 嵌入單個查詢
query_embedding = embeddings.embed_query(query)
print("查詢嵌入:", query_embedding)
# 查詢嵌入:[-0.0036168822553008795, 0.0056339893490076065,...]
?
2.4 Vector stores 向量存儲
參考文檔: Vector stores
其實langchain支持embedding和vector 的種類有很多,具體支持類型見 full list of LangChain vectorstore integrations.
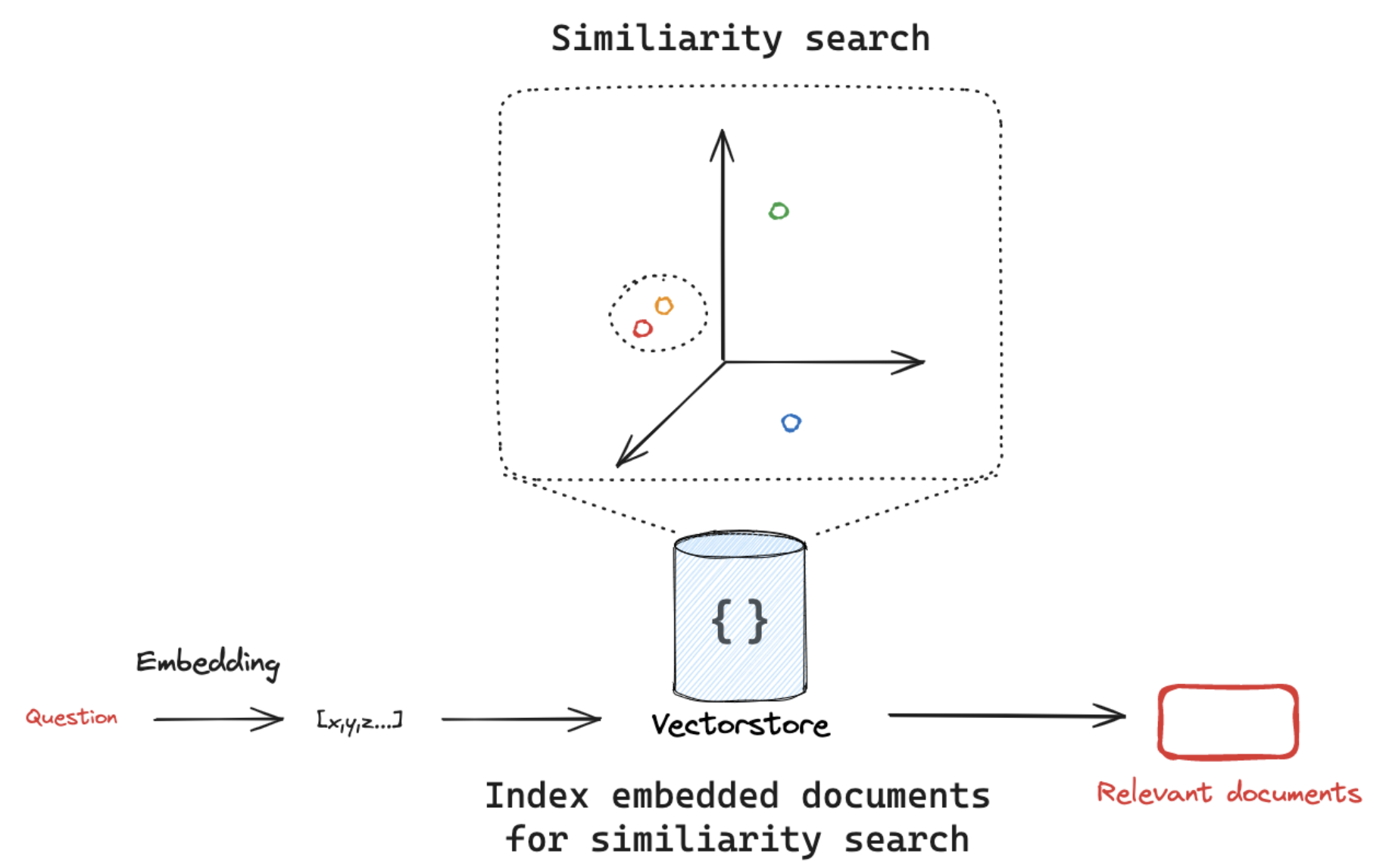
其中, 向量存儲(Vector Stores) 是一種專門的數據存儲,支持基于向量表示的索引和檢索。這些向量捕捉了被嵌入數據的語義意義。
向量存儲通常用于搜索非結構化數據(如文本、圖像和音頻),以基于語義相似性而非精確的關鍵詞匹配來檢索相關信息。主要應用場景之一是rag。
??
??
LangChain 提供了一個標準接口,用于與向量存儲交互,使用戶能夠輕松切換不同的向量存儲實現。
該接口包含用于在向量存儲中寫入、刪除和搜索文檔的基本方法。
關鍵方法包括:
1.add_documents:將一組文本添加到向量存儲中。
2.delete:從向量存儲中刪除一組文檔。
3.similarity_search:搜索與給定查詢相似的文檔。
# vector store
from langchain_core.vectorstores import InMemoryVectorStore
# 實例化向量存儲
vector_store = InMemoryVectorStore(embeddings)
# 將已經轉為向量的文檔存儲到向量存儲中
ids =vector_store.add_documents(documents=chunks)
print(ids) # ['b5b11014-7702-45f6-aa0d-7272042c5d4d', '93ed319a-5110-40ac-8bf4-117a220ed0cb', '63b92a2f-bf47-4a10-b66b-cd39776995f7',...]
vector_store.delete(ids=["93ed319a-5110-40ac-8bf4-117a220ed0cb"])
vector_store.similarity_search('What is the model introduced in this paper?',k=4)
額外補充一句:
向量化嵌入和向量存儲不僅限于檢索增強生成(RAG)系統,它們有更廣泛的應用場景: 其他應用領域包括: 1.語義搜索系統 - 基于內容含義而非關鍵詞匹配的搜索 2.推薦系統 - 根據內容或用戶行為的相似性推薦項目 3.文檔聚類 - 自動組織和分類大量文檔 4.異常檢測 - 識別與正常模式偏離的數據點 5.多模態系統 - 連接文本、圖像、音頻等不同模態的內容 6.內容去重 - 識別相似或重復的內容 7.知識圖譜 - 構建實體之間的語義關聯 8.情感分析 - 捕捉文本的情感特征 RAG是向量嵌入技術的一個重要應用,但這些技術的價值遠不止于此,它們為各種需要理解內容語義關系的AI系統提供了基礎。
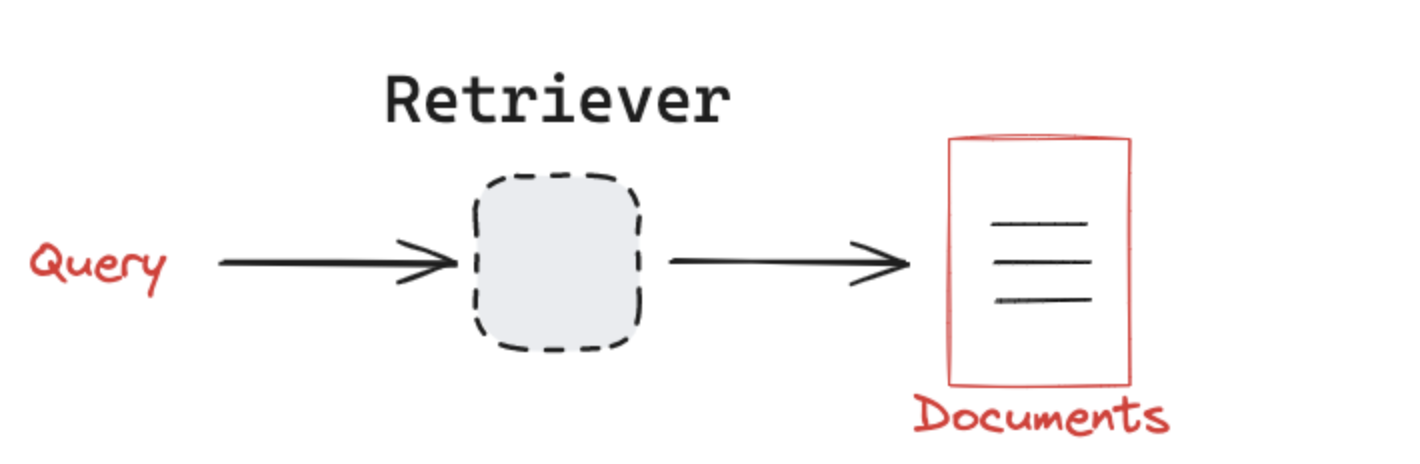
2.5 Retriever 檢索
參考文檔: retrievers
目前存在許多不同類型的檢索系統,包括 向量存儲(vectorstores)、圖數據庫(graph databases) 和 關系數據庫(relational databases)。
??
LangChain 提供了一個統一的接口,用于與不同類型的檢索系統交互。LangChain 的檢索器接口非常簡單:
?輸入:一個查詢(字符串)。
?輸出:一組文檔(標準化的 LangChain Document 對象)。
而且LangChain的retriever是runnable類型,runnable可用方法他都可以調用,比如:
docs = retriever.invoke(query)
2.5.1 基礎檢索器的幾種類型說明
在 LangChain 中,as_retriever() 方法的 search_type 參數決定了向量檢索的具體算法和行為。以下是三種搜索類型的詳細解釋和對比:
retriever = vector_store.as_retriever(
search_type="similarity", # 可選 "similarity"|"mmr"|"similarity_score_threshold"
search_kwargs={
"k": 5, # 返回結果數量
"score_threshold": 0.7, # 僅當search_type="similarity_score_threshold"時有效
"filter": {"source": "重要文檔.pdf"}, # 元數據過濾
"lambda_mult": 0.25 # 僅MMR搜索有效(控制多樣性)
}
)
search_kwargs: 搜索條件
search_type可選 "similarity"|"mmr"|"similarity_score_threshold"
?similarity(默認)-標準相似度搜索
原理:直接返回與查詢向量最相似的 k 個文檔(基于余弦相似度或L2距離)
特點:
?結果完全按相似度排序
?適合精確匹配場景
?
?mmr-最大邊際相關性
原理:在相似度的基礎上增加多樣性控制,避免返回內容重復的結果
核心參數:
?lambda_mult:0-1之間的值,越小結果越多樣
?接近1:更偏向相似度(類似similarity)
?接近0:更偏向多樣性
特點:
?檢索結果需要覆蓋不同子主題時
?避免返回內容雷同的文檔
?
similarity_score_threshold-帶分數閾值的相似度搜索
?原理:只返回相似度超過設定閾值的文檔
?關鍵參數:
?score_threshold:相似度閾值(余弦相似度范圍0-1)
?k:最大返回數量(但實際數量可能少于k)
?特點:
?適合質量優先的場景
?結果數量不固定(可能返回0個或多個)
?
| 類型 | 核心目標 | 結果數量 | 是否控制多樣性 | 典型應用場景 |
|---|---|---|---|---|
| similarity | 精確匹配 | 固定k個 | ? | 事實性問題回答 |
| mmr | 平衡相關性與多樣性 | 固定k個 | ? | 生成綜合性報告 |
| similarity_score_threshold | 質量過濾 | 動態數量 | ? | 高精度篩選 |
2.5.2 高級檢索工具
1.MultiQueryRetriever - 提升模糊查詢召回率
設計目標:通過查詢擴展提升檢索質量 核心思想:
?對用戶輸入問題生成多個相關查詢(如同義改寫、子問題拆解)
?合并多查詢結果并去重
關鍵特點:
?提升模糊查詢的召回率
?依賴LLM生成優質擴展查詢(需控制生成成本)
?
2.MultiVectorRetriever -多向量檢索
設計目標:處理單個文檔的多種向量表示形式 核心思想:
?對同一文檔生成多組向量(如全文向量、摘要向量、關鍵詞向量等)
?通過多角度表征提升召回率
關鍵特點:
?適用于文檔結構復雜場景(如技術論文含正文/圖表/代碼)
?存儲開銷較大(需存多組向量)
?
3.RetrievalQA
設計目標:端到端的問答系統構建 核心思想:
?將檢索器與LLM答案生成模塊管道化
?支持多種鏈類型(stuff/map_reduce/refine等)
使用方法:
# 構建一個高性能問答系統 from langchain.chains import RetrievalQA from langchain.retrievers.multi_query import MultiQueryRetriever from langchain.retrievers.multi_vector import MultiVectorRetriever
# 1. 多向量存儲
# 假設已生成不同視角的向量
vectorstore = FAISS.from_texts(documents, embeddings)
mv_retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=standard_docstore, # 存儲原始文檔
id_key="doc_id" # 關聯不同向量與原始文檔
)
# 2. 多查詢擴展
mq_retriever = MultiQueryRetriever.from_llm(
retriever=mv_retriever,
llm=ChatOpenAI(temperature=0.3)
)
# 3. 問答鏈
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0),
chain_type="refine",
retriever=mq_retriever,
chain_type_kwargs={"verbose": True}
)
# 執行
answer = qa.run("請對比Transformer和CNN的優缺點")
?
4.TimeWeightedVectorStoreRetriever - 時間加權檢索
?設計目標:專門用于在向量檢索中引入時間衰減因子,使系統更傾向于返回近期文檔
? 典型使用場景
1. 新聞/社交媒體應用 -優先展示最新報道而非歷史文章
2. 技術文檔系統 - 優先推薦最新API文檔版本
3. 實時監控告警 - 使最近的事件告警排名更高
?
2.5.3 混合檢索
EnsembleRetriever - 集合檢索器
?場景:結合語義+關鍵詞搜索
ContextualCompressionRetriever-上下文壓縮
?場景:過濾低相關性片段
三. 代碼實戰
說完了技術,接下來就真正嘗試兩個個例子,走一遍RAG全流程。
3.1 構建一個簡單的員工工作指南檢索系統
需求背景:我現在要給一個企業做員工工作指南的檢索系統,方便員工查閱最新資訊。里面包含.pdf,.docx,.txt三種文件。
技術點:
?使用FAISS做向量存儲,MultiQueryRetriever和RetrievalQA做增強檢索
?構建一個chain做問答
代碼地址: https://github.com/XingtongCai/langchain_project/tree/main/translatorAssistant/basic_knowledge/%E5%91%98%E5%B7%A5%E6%89%8B%E5%86%8C%E7%9A%84%E6%A3%80%E7%B4%A2%E7%B3%BB%E7%BB%9F
目錄結構:
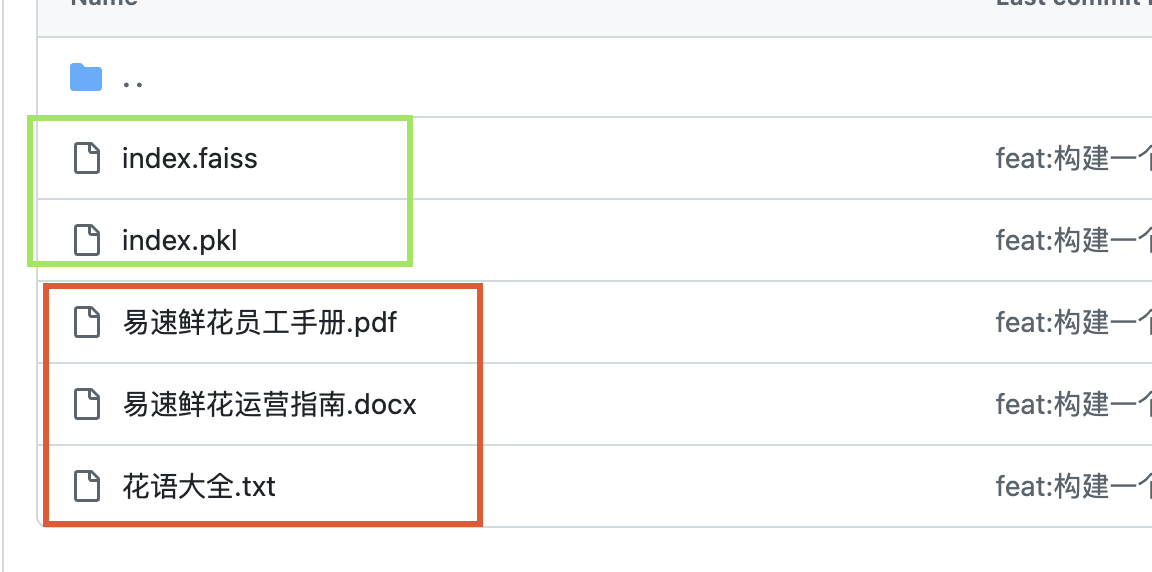
??
三個需要加載的文檔, index.faiss和index.pkl是我已經做好向量化的文件,如果不想自己做向量化或者想省一些token,可以直接讀取這兩個文件。代碼段如下:
# 如果已經有embedding文件,直接加載,不要重新處理了,節省token
embedding = OpenAIEmbeddings(model="text-embedding-ada-002",chunk_size=1000)
vector_store_1 = FAISS.load_local(
folder_path="./docs", # 存放index.faiss和index.pkl的目錄路徑
embeddings=embedding, # 必須與創建時相同的嵌入模型
index_name="index", # 可選:若文件名不是默認的"index",需指定前綴
allow_dangerous_deserialization=True # 顯式聲明信任
)
print(f"已加載 {len(vector_store_1.docstore._dict)} 個文檔塊")
print(vector_store_1)
運行方式2種:
1.用 jupyter工具,直接運行Langchain_QA.ipynb 這個文件,可以單步調試。我運行的結果也可以直接看到
2.用python腳本,直接運行Langchain_QA.py這個文件
cd translatorAssistant/basic_knowledge/員工手冊的檢索系統 python Langchain_QA.py 示例問題可以嘗試: "應聘人員須提供什么資料" "Rose的花語是什么"
結果界面:

??

??
3.2 讀取網頁的blog并進行多輪對話來查詢
需求背景:我現在要讀取 https://lilianweng.github.io/posts/2023-06-23-agent/ 這個blog的內容,并對里面內容進行多輪對話的檢索
技術點:
?使用WebBaseLoader來加載網頁內容
?使用rlm/rag-prompt來構建rag的prompt提示詞模版
?使用ConversationBufferMemory來做記憶存儲,進行多輪對話
?構建stream_generator支持流式輸出
代碼地址: https://github.com/XingtongCai/langchain_project/tree/main/translatorAssistant/basic_knowledge/%E5%A4%9A%E8%BD%AE%E5%AF%B9%E8%AF%9D%E7%9A%84%E6%A3%80%E7%B4%A2%E7%B3%BB%E7%BB%9F
目錄結構:
和上面結構差不多,docs里面是向量化好的文件,.ipynb可以單步調試并且能看我運行的每一步結果,.py是最后整個python文件
運行方式:和上面示例一樣
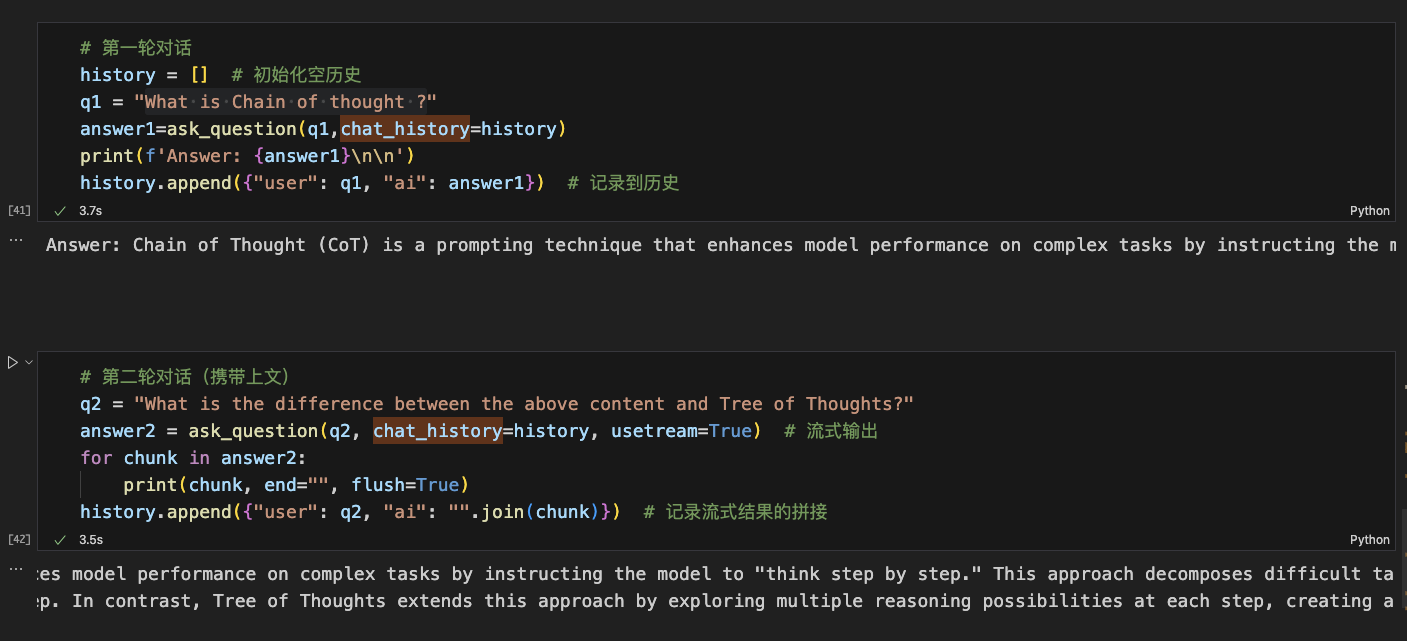
運行結果:
多輪對話的的prompt:
最后結果:
??
?
四.企業級RAG
上面的內容是作為RAG的基礎知識,但是想做企業級別的RAG,尤其是要做 產品資訊助手 這種基于知識庫和用戶進行問答式的交流還遠遠不夠。總流程沒有區別,但是每一塊都有自己特殊處理地方:
我通過讀取一些企業級RAG的文章,大致整理一下這種流程,但是真實使用時候,還是需要根據我們自己業務文檔,使用的場景和對于回答準確率要求的情況來酌情處理。
4.1 文本加載和文本清洗
企業級知識庫構建在 預處理 這部分的處理是重頭戲。因為我們文檔是多樣性的,有不同類型文件,文件里面還有圖片,圖片里面內容有時候也是需要識別的。另外文檔基本都是產品或者運營來寫,里面有很多口頭語的表述,過多不合適的分段/語氣詞,多余的空格,這些問題都會影響最后分割的效果。一般文本清洗需要做一下幾步:
?去除雜音:去掉文本中的無關信息或者噪聲,比如多余的空格、HTML 標簽和特殊符號等。
?標準化格式:將文本轉換為統一的格式,如將所有字符轉為小寫,或者統一日期、數字的表示。
?處理標點符號和分詞:處理或移除不必要的標點符號,并對文本進行適當的分詞處理。
?去除停用詞:移除那些對語義沒有特別貢獻的常用詞匯,例如“的”、“在”、“而”等。
?拼寫糾錯:糾正文本中的拼寫錯誤,以確保文本的準確性和一致性。
?詞干提取和詞形還原:將詞語簡化為詞干或者詞根形式,以減少詞匯的多樣性并保持語義的一致性。
4.2 文本分割
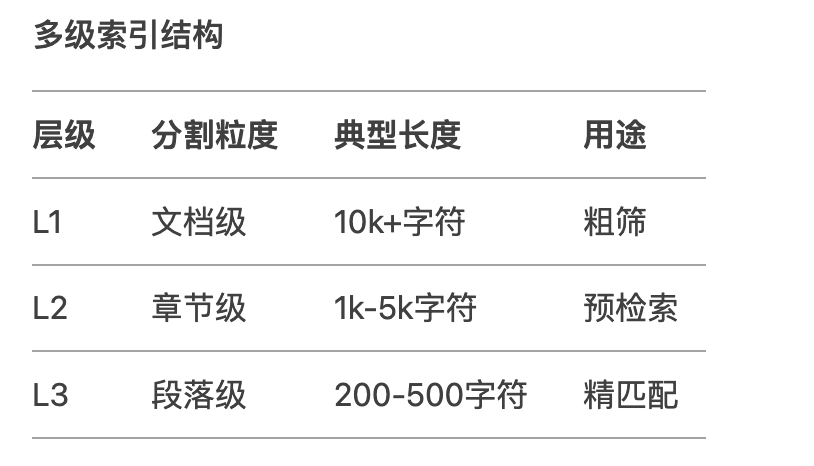
除了采取上面的基本分割方式,然后還可以結合層次分割優化不同粒度的索引結構,提高檢索匹配度。
補充一下多級索引結構:
??
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3")
]
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers)
chunks = splitter.split_text(markdown_doc)
4.3 向量存儲
在企業級存儲一般數據量都很大,用內存緩存是不現實的,基本都是需要存在數據庫中。至于用什么數據庫,怎么存也根據文本類型有變化,例如:
?向量數據庫:向量存儲庫非常適合存儲文本、圖像、音頻等非結構化數據,并根據語義相似性搜索數據。
?圖數據庫:圖數據庫以節點和邊的形式存儲數據。它適用于存儲結構化數據,如表格、文檔等,并使用數據之間的關系搜索數據。
4.4 向量檢索
在很多情況下,用戶的問題可能以口語化形式呈現,語義模糊,或包含過多無關內容。將這些模糊的問題進行向量化后,召回的內容可能無法準確反映用戶的真實意圖。此外,召回的內容對用戶提問的措辭也非常敏感,不同的提問方式可能導致不同的檢索結果。因此,如果計算能力和響應時間允許,可以先利用LLM對用戶的原始提問進行改寫和擴展,然后再進行相關內容的召回。
4.5 內容緩存
在一些特定場景中,對于用戶的問答檢索需要做緩存處理,以提高響應速度。可以以用戶id,時間順序,信息權重作為標識進行存儲。
還有一些關于將檢索信息和prompt結合時候,如何處理等其他流程,這里不多講,講多了頭疼。。。
總結
本文介紹了RAG的基礎過程,在langchain框架下如何使用,再到提供兩個個例子進行了代碼實踐,最后又簡要介紹了企業級別RAG構建的內容。最后希望大家能有所收獲。
碼字不易,如果喜歡,請給作者一個小小的贊做鼓勵吧~~
參考文獻
1. https://mp.weixin.qq.com/s/_tfc6qBIJkWXHe40lrbSbw
2. https://mp.weixin.qq.com/s/jDSSt6MB1QeQuft0ZNeGDg
審核編輯 黃宇
-
存儲
+關注
關注
13文章
4533瀏覽量
87473 -
Docs
+關注
關注
0文章
6瀏覽量
7366 -
python
+關注
關注
56文章
4827瀏覽量
86797
發布評論請先 登錄
使用 llm-agent-rag-llamaindex 筆記本時收到的 NPU 錯誤怎么解決?
軟通動力發布智慧園區RAG解決方案
《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫
利用OpenVINO和LlamaIndex工具構建多模態RAG應用

【「基于大模型的RAG應用開發與優化」閱讀體驗】RAG基本概念
【「基于大模型的RAG應用開發與優化」閱讀體驗】+第一章初體驗
【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
檢索增強型生成(RAG)系統詳解
RAG的概念及工作原理
Cloudera推出RAG Studio,助力企業快速部署聊天機器人
名單公布!【書籍評測活動NO.52】基于大模型的RAG應用開發與優化
浪潮信息發布“源”Yuan-EB助力RAG檢索精度新高
使用OpenVINO和LlamaIndex構建Agentic-RAG系統
LangChain框架關鍵組件的使用方法
英特爾軟硬件構建模塊如何幫助優化RAG應用






 工商網監
工商網監
評論