 Arm+AWS實現AI定義汽車 基于Arm KleidiAI優化并由AWS提供支持
Arm+AWS實現AI定義汽車 基于Arm KleidiAI優化并由AWS提供支持
作者:Arm 工程部首席軟件工程師 Gian Marco Iodice,以及亞馬遜云科技 (AWS) Srini Raghavan 和Stefano Marzani
隨著人工智能 (AI) ,尤其是生成式 AI 的引入,汽車行業正迎來變革性轉變。麥肯錫最近對汽車和制造業高管開展的一項調查[1]表明,超過 40% 的受訪者對生成式 AI 研發的投資額高達 500 萬歐元,超過 10% 受訪者的投資額超過 2,000 萬歐元。
隨著行業向軟件定義汽車 (SDV) 不斷發展,到 2030 年,汽車中的代碼行數預計將從每輛車 1 億行增加至約 3 億行。面向汽車的生成式 AI 與 SDV 相結合,可共同實現性能和舒適性方面的車載用例,以幫助提升駕乘體驗。
本文將介紹一項由 Arm 與亞馬遜云科技 (AWS) 合作開發的車載生成式 AI 用例及其實現詳情。
用例介紹
隨著汽車愈發精密,車主已經能在交車后持續接收諸如停車輔助或車道保持等功能更新,伴隨而來的挑戰是,如何讓車主及時了解新增的更新和新功能?過往通過紙質或在線手冊等傳統方法的更新方式已證明存在不足,導致車主無法充分了解汽車的潛能。
為了應對這一挑戰,AWS 將生成式 AI、邊緣計算和物聯網 (IoT) 的強大功能相結合,開發了一項車載生成式 AI 的演示。這項演示所展現的解決方案是由小語言模型 (SLM) 所支持的車載應用,旨在使駕駛員能夠通過自然語音交互獲取最新的車輛信息。該演示應用能夠在部署后離線運行,確保駕駛員在沒有互聯網連接的情況下,也能訪問有關車輛的重要信息。
該解決方案集成了多項先進技術,為用戶打造出更無縫、更高效的產品體驗。這項演示的應用部署在車內本地的小語言模型,該模型利用經 Arm KleidiAI 優化的例程對性能進行提升。未經 KleidiAI 優化的系統的響應時間為 8 至 19 秒左右,相比之下,經 KleidiAI 優化的小語言模型的推理響應時間為 1 至 3 秒。通過使用 KleidiAI,應用開發時間縮短了 6 周,而且開發者在開發期間無需關注底層軟件的優化。
Arm 虛擬硬件 (Arm Virtual Hardware) 支持訪問許多 AWS 上的熱門物聯網開發套件。當物理設備不可用,或者全球各地的團隊無法訪問物理設備時,在 Arm 虛擬硬件上進行開發和測試可節省嵌入式應用的開發時間。AWS 在汽車虛擬平臺上成功測試了該演示應用,在演示中,Arm 虛擬硬件提供了樹莓派設備的虛擬實例。同樣的 KleidiAI 優化也可用于 Arm 虛擬硬件。
這個在邊緣側設備上運行的生成式 AI 應用所具備的關鍵特性之一是,它能夠接收 OTA 無線更新,其中部分更新使用 AWS IoT Greengrass Lite 接收,從而確保始終向駕駛員提供最新信息。AWS IoT Greengrass Lite 在邊緣側設備上僅占用 5 MB 的 RAM,因此具有很高的內存效率。此外,該解決方案包含自動質量監控和反饋循環,用于持續評估小語言模型響應的相關性和準確性。其中采用了一個比較系統,對超出預期質量閾值的響應進行標記,以進行審核。然后,通過 AWS 上的儀表板,以近乎實時的速度對收集到的反饋數據進行可視化,使整車廠的質保團隊能夠審核和確定需要改進的方面,并根據需要發起更新。
這個由生成式 AI 提供支持的解決方案,所具備的優勢不僅僅在于為駕駛員提供準確的信息。它還體現了 SDV 生命周期管理的范式轉變,實現了更持續的改進周期,整車廠可以根據用戶交互來添加新內容,而小語言模型可以使用通過無線網絡無縫部署的更新信息進行微調。這樣一來,通過保證最新的車輛信息,用戶體驗得以提升,此外整車廠也有機會向用戶介紹和指導新特性或可購買的附加功能。通過利用生成式 AI、物聯網和邊緣計算的強大功能,這個生成式 AI 應用可以起到汽車用戶向導的作用,其中展示的方法有助于在 SDV 時代實現更具連接性、信息化和適應性的駕駛體驗。
端到端的上層實現方案
下圖所示的解決方案架構用于對模型進行微調、在 Arm 虛擬硬件上測試模型,以及將小語言模型部署到邊緣側設備,并且其中包含反饋收集機制。
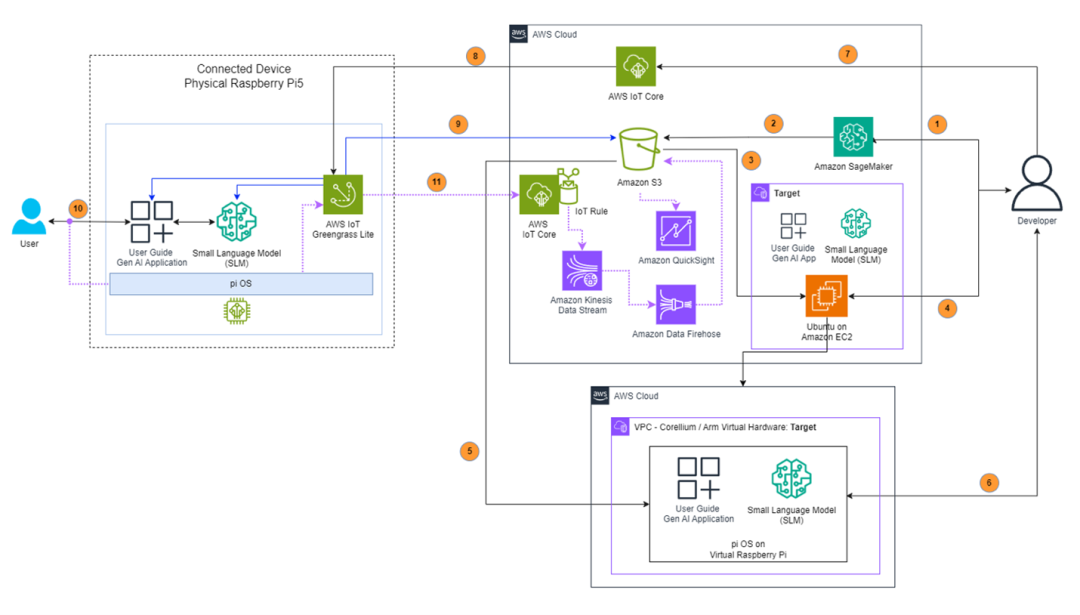
圖:基于生成式 AI 的汽車用戶向導的解決方案架構圖
上圖中的編號對應以下內容:
1.
模型微調:AWS 演示應用開發團隊選擇 TinyLlama-1.1B-Chat-v1.0 作為其基礎模型,該模型已針對會話任務進行了預訓練。為了優化駕駛員的汽車用戶向導聊天界面,團隊設計了言簡意賅、重點突出的回復,以便適應駕駛員在行車時僅可騰出有限注意力的情況。團隊創建了一個包含 1,000 組問答的自定義數據集,并使用 Amazon SageMaker Studio 進行了微調。
2.
存儲:經過調優的小語言模型存儲在 Amazon Simple Storage Service (Amazon S3) 中。
3.
初始部署:小語言模型最初部署到基于 Ubuntu 的 Amazon EC2 實例。
4.
開發和優化:團隊在 EC2 實例上開發并測試了生成式 AI 應用,使用 llama.cpp 進行小語言模型量化,并應用了 Q4_0 方案。KleidiAI 優化預先集成了 llama.cpp。與此同時,模型還實現了大幅壓縮,將文件大小從 3.8 GB 減少至 607 MB。
5.
虛擬測試:將應用和小語言模型傳輸到 Arm 虛擬硬件的虛擬樹莓派環境進行初始測試。
6.
虛擬驗證:在虛擬樹莓派設備中進行全面測試,以確保功能正常。
7.
邊緣側部署:通過使用 AWS IoT Greengrass Lite,將生成式 AI 應用和小語言模型部署到物理樹莓派設備,并利用 AWS IoT Core 作業進行部署管理。
8.
部署編排:AWS IoT Core 負責管理部署到邊緣側樹莓派設備的任務。
9.
安裝過程:AWS IoT Greengrass Lite 處理從 Amazon S3 下載的軟件包,并自動完成安裝。
10.
用戶界面:已部署的應用在邊緣側樹莓派設備上為最終用戶提供基于語音的交互功能。
11.
質量監控:生成式 AI 應用實現對用戶交互的質量監控。數據通過 AWS IoT Core 收集,并通過 Amazon Kinesis Data Streams 和 Amazon Data Firehose 處理,然后存儲到 Amazon S3。整車廠可通過 Amazon QuickSight 儀表板來監控和分析數據,及時發現并解決任何小語言模型質量問題。
接下來將深入探討 KleidiAI 及該演示采用的量化方案。
Arm KleidiAI
Arm KleidiAI 是專為 AI 框架開發者設計的開源庫。它為 Arm CPU 提供經過優化的性能關鍵例程。該開源庫最初于 2024 年 5 月推出,現在可為各種數據類型的矩陣乘法提供優化,包括 32 位浮點、Bfloat16 和 4 位定點等超低精度格式。這些優化支持多項 Arm CPU 技術,比如用于 8 位計算的 SDOT 和 i8mm,以及用于 32 位浮點運算的 MLA。
憑借四個 Arm Cortex-A76 核心,樹莓派 5 演示使用了 KleidiAI 的 SDOT 優化,SDOT 是最早為基于 Arm CPU 的 AI 工作負載設計的指令之一,它在 2016 年發布的 Armv8.2-A 中推出。
SDOT 指令也顯示了 Arm 持續致力于提高 CPU 上的 AI 性能。繼 SDOT 之后,Arm 針對 CPU 上運行 AI 逐步推出了新指令,比如用于更高效 8 位矩陣乘法的 i8mm 和 Bfloat16 支持,以期提高 32 位浮點性能,同時減半內存使用。
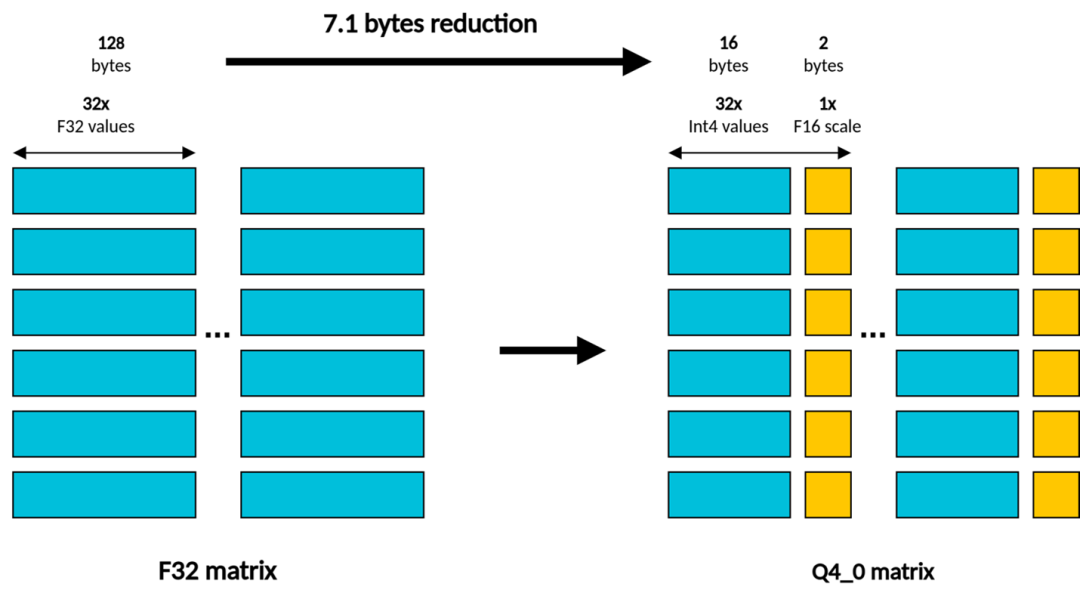
對于使用樹莓派 5 進行的演示,通過按塊量化方案,利用整數 4 位量化(也稱為 llama.cpp 中的 Q4_0)來加速矩陣乘法,KleidiAI 扮演關鍵作用。
llama.cpp 中的 Q4_0 量化格式
llama.cpp 中的 Q4_0 矩陣乘法包含以下組成部分:
左側 (LHS) 矩陣,以 32 位浮點值的形式存儲激活內容。
右側 (RHS) 矩陣,包含 4 位定點格式的權重。在該格式中,量化尺度應用于由 32 個連續整數 4 位值構成的數據塊,并使用 16 位浮點值進行編碼。
因此,當提到 4 位整數矩陣乘法時,它特指用于權重的格式,如下圖所示:
在這個階段,LHS 和 RHS 矩陣均不是 8 位格式,KleidiAI 如何利用專為 8 位整數點積設計的 SDOT 指令?這兩個輸入矩陣都必須轉換為 8 位整數值。
對于 LHS 矩陣,在矩陣乘法例程之前,還需要一個額外的步驟:動態量化為 8 位定點格式。該過程使用按塊量化方案將 LHS 矩陣動態量化為 8 位,其中,量化尺度應用于由 32 個連續 8 位整數值構成的數據塊,并以 16 位浮點值的形式存儲,這與 4 位量化方法類似。
動態量化可最大限度降低準確性下降的風險,因為量化尺度因子是在推理時根據每個數據塊中的最小值和最大值計算得出的。與該方法形成對比的是,靜態量化的尺度因子是預先確定的,保持不變。
對于 RHS 矩陣,在矩陣乘法例程之前,無需額外步驟。事實上,4 位量化充當壓縮格式,而實際計算是以 8 位進行的。因此,在將 4 位值傳遞給點積指令之前,首先將其轉換為 8 位。從 4 位轉換為 8 位的計算成本并不高,因為只需進行簡單的移位/掩碼運算即可。
既然轉換效率如此高,為什么不直接使用 8 位,省去轉換的麻煩?
使用 4 位量化有兩個關鍵優勢:
縮小模型尺寸:由于 4 位值所需的內存只有 8 位值的一半,因此這對可用 RAM 有限的平臺尤其有益。
提升文本生成性能:文本生成過程依賴于一系列矩陣向量運算,這些運算通常受內存限制。也就是說,性能受限于內存和處理器之間的數據傳輸速度,而不是處理器的計算能力。由于內存帶寬是一個限制因素,縮小數據大小可最大限度減少內存流量,從而顯著提高性能。
如何結合使用 KleidiAI 與 llama.cpp?
非常簡單,KleidiAI 已集成到 llama.cpp 中。因此,開發者不需要額外的依賴項就能充分發揮 Armv8.2 及更新架構版本的 Arm CPU 性能。
兩者的集成意味著,在移動設備、嵌入式計算平臺和基于 Arm 架構處理器的服務器上運行 llama.cpp 的開發者,現在可以體驗到更好的性能。
除了 llama.cpp,還有其他選擇嗎?
對于在 Arm CPU 上運行大語言模型,雖然 llama.cpp 是一個很好的選擇,但開發者也可以使用其他采用了 KleidiAI 優化的高性能生成式 AI 框架。例如(按首字母順序排列):ExecuTorch、MediaPipe、MNN和 PyTorch。只需選擇最新版本的框架即可。
因此,如果你正考慮在 Arm CPU 上部署生成式 AI 模型,探索以上框架有助于實現性能和效率的優化。
總結
SDV 和生成式 AI 的融合,正在共同開創一個新的汽車創新時代,使得未來的汽車變得更加智能化,更加以用戶為中心。文中介紹的車載生成式 AI 應用演示由 Arm KleidiAI 進行優化并由 AWS 所提供的服務進行支持,展示了新興技術如何幫助解決汽車行業的實際挑戰。該解決方案可實現 1 至 3 秒的響應時間并將開發時間縮短數周,證明更高效且離線可用的生成式 AI 應用不僅能夠實現,而且非常適合車載部署。
汽車技術的未來在于打造無縫融合邊緣計算、物聯網功能和 AI 的解決方案。隨著汽車不斷演變且軟件越來越復雜,潛在解決方案(比如本文介紹的解決方案)將成為彌合先進汽車功能與用戶理解間差距的關鍵。
* Arm 原創文章
-
ARM
+關注
關注
134文章
9242瀏覽量
372191 -
AI
+關注
關注
87文章
33025瀏覽量
272825 -
AWS
+關注
關注
0文章
435瀏覽量
24797
原文標題:Arm 攜手 AWS 助力實現 AI 定義汽車
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于Qualcomm QCA4020配置AWS服務(一)
如何安裝和升級了AWS CLI
ARM Neoverse IP的AWS實例上etcd分布式鍵對值存儲性能提升
Arm Neoverse V1的AWS Graviton3在深度學習推理工作負載方面的作用
在AWS云中使用Arm處理器設計Arm處理器
討論使用Terraform在AWS上部署Arm EC2實例
亞馬遜AWS面向云服務開發全新ARM處理器 最多可達32核心
Arm將利用AWS為其云計算使用
AWS Arm 架構處理器首次落地中國區域:比同配置 X86 實例性價比提高 40%
專用處理能力驅動基于Arm架構的云計算時代并支持AWS Graviton不斷創新


AWS的使命——劍指x86,扶Arm上位





 工商網監
工商網監
評論