 算力網絡的“神經突觸”:AI互聯技術如何重構分布式訓練范式
算力網絡的“神經突觸”:AI互聯技術如何重構分布式訓練范式
電子發燒友網綜合報道 隨著AI技術迅猛發展,尤其是大型語言模型的興起,對于算力的需求呈現出爆炸性增長。這不僅推動了智算中心的建設,還對網絡互聯技術提出了新的挑戰。
在AI大模型訓練過程中,由于單個AI芯片的算力提升速度無法跟上模型參數的增長速率,再加上龐大的模型參數和訓練數據,已遠遠超出單個AI芯片甚至單臺服務器的能力范圍。因此,需要將數據樣本和模型結構分散到多個計算設備上,這導致了設備間的頻繁通信需求。為了適應這一變化,智算中心服務器內部的網絡互聯技術變得至關重要。
芯片間互聯技術
AI服務器的互聯技術是保障其高性能計算能力的關鍵,涉及芯片間、服務器內以及服務器間等多個層面的高速數據傳輸。
芯片間互聯技術方面,英偉達、AMD、英特爾都推出了相關技術,分別是NVLink、Infinity Fabric、CXL(Compute Express Link)等。NVLink是由NVIDIA開發的GPU之間的高速互連技術,能加快CPU與GPU、GPU與GPU之間的數據傳輸速度,提高系統性能。從2016年到2022年,NVLink歷經多次迭代更新,例如基于Hopper架構的第四代NVLink,單鏈可實現50GB/s的雙向帶寬,單芯片可支持18鏈路,即900GB/s的總雙向帶寬。在NVIDIA的DGX H100服務器中,GPU(H100)之間互聯主要通過NV Switch芯片來實現,而NV Switch芯片與GPU之間的數據傳輸就依賴于NVLink。
AMD推出的Infinity Fabric,由傳輸數據的Infinity Scalable Data Fabric(SDF)和負責控制的Infinity Scalable Control Fabric(SCF)兩個系統組成,連接了on-die和off-die以及多路CPU間的通信。最新的AMD Instinct MI300X GPU采用5nm制程,支持客戶將8個GPU整合為一個性能主導型節點,并且具有全互聯式點對點環形設計,使用了第4代Infinity Fabric高速總線互聯,總線帶寬達到896GB/s(與英偉達H100的900GB/s帶寬相當)。
CXL(Compute Express Link)是英特爾提出的一種開放性互聯協議,CXL是建立在PCIe物理層之上的協議,可以實現設備之間的緩存和內存一致性。利用廣泛存在的PCIe接口,CXL允許內存在各種硬件上共享:CPU、NIC和DPU、GPU和其它加速器、SSD和內存設備,從而滿足高性能異構計算的要求。
服務器內互聯技術有PCIe Switch、Retimer芯片。PCIe Switch,即PCIe開關或PCIe交換機,主要作用是實現PCIe設備互聯。由于PCIe的鏈路通信是一種端對端的數據傳輸,需要Switch提供擴展或聚合能力,從而允許更多的設備連接到一個PCIe端口,以解決PCIe通道數量不夠的問題。例如在AI服務器中,GPU與CPU連接時可能需要用到PCIe Switch,并且隨著PCIe總線技術的升級,PCIe Switch每代速率提升,能提高數據傳輸的速度。
在AI服務器中,GPU與CPU連接時至少需要一顆Retimer芯片來保證信號質量,很多AI服務器都會配置多顆Retimer芯片。例如Astera Labs在AI加速器中配置了4顆Retimer芯片。
AI服務器間互聯技術
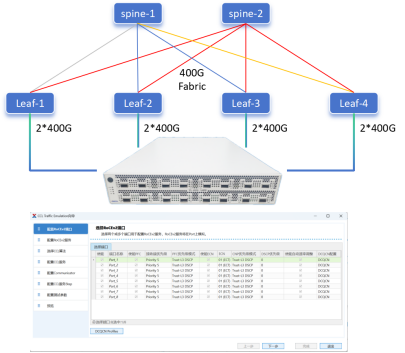
服務器間互聯技術有InfiniBand、RoCE、高速以太網。InfiniBand是一種高性能的網絡互聯技術,具有低延遲、高帶寬的特點,能夠滿足AI服務器之間超低延遲、超高帶寬的通信需求,適用于大規模AI模型訓練時服務器之間的高效通信和數據同步。例如訓練超大模型往往需要成百上千臺服務器組成集群,服務器之間就需要InfiniBand這樣的網絡進行高效通信。
RoCE(RDMA over Converged Ethernet),基于以太網的RDMA(遠程直接內存訪問)技術,它允許數據在網絡中直接從一臺計算機的內存傳輸到另一臺計算機的內存,而無需操作系統內核的介入,從而降低了延遲,提高了帶寬利用率,可用于AI服務器間的互聯,提升數據傳輸效率。
高速以太網,如400Gbps甚至800Gbps以太網適配器,能為AI服務器間提供高速的網絡連接,保障大規模集群部署時服務器之間的數據傳輸性能。例如昆侖芯超節點結合百度智能云自研的基于導軌優化的HPN(High Performance Network)架構,可支撐從數百卡到上萬卡的XPU集群構建,其中就涉及到高速以太網技術的應用。
小結
在AI服務器中,互聯技術的作用已從數據傳輸通道升級為算力釋放引擎。通過高帶寬、低延遲、可擴展的互聯架構,AI服務器能夠突破單節點算力瓶頸,實現萬億參數模型的分布式訓練;降低推理延遲,支撐實時AI應用的商業化落地;優化能效比,應對超大規模數據中心的能耗挑戰。
-
AI
+關注
關注
88文章
34405瀏覽量
275679 -
算力
+關注
關注
2文章
1153瀏覽量
15476
發布評論請先 登錄
潤和軟件發布StackRUNS異構分布式推理框架

華為AI WAN智算IP廣域網助力算力互聯網建設
上海電信攜手華為打造分布式云邊協同訓推方案
AI原生架構升級:RAKsmart服務器在超大規模模型訓練中的算力突破
RAKsmart智能算力架構:異構計算+低時延網絡驅動企業AI訓練范式升級
信而泰CCL仿真:解鎖AI算力極限,智算中心網絡性能躍升之道
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
AI網絡物理層底座: 大算力芯片先進封裝技術





 工商網監
工商網監
評論