 破解數據瓶頸:智能汽車合成數據架構與應用實踐
破解數據瓶頸:智能汽車合成數據架構與應用實踐

在智能汽車快速演進的過程中,數據體系正面臨深層次挑戰。過去,數據是輔助模型開發的工具;如今,它已成為限制感知系統性能上限的核心因素。尤其是在感知系統廣泛應用于自動駕駛和智能座艙場景之后,數據的廣度、深度、時效性與結構化程度,已直接決定模型是否能夠真正實現落地部署。
在數據獲取難度持續上升、標注成本不斷攀高、法規限制日益收緊的背景下,合成數據正逐步成為智能汽車感知系統開發的重要突破方向。
本文將聚焦于兩個關鍵應用場景——艙外道路感知與艙內乘員狀態識別,系統性探討合成數據體系的建設路徑、關鍵技術要素與工程落地實踐。
01 智能汽車感知系統的數據困境
智能汽車的感知能力依賴于多模態數據,包括圖像、點云、雷達信號、IMU與GPS數據,以及艙內的姿態信息、關鍵點標注與行為狀態標簽等。然而,感知系統在實際應用中面臨如下數據困境:
數據結構高度復雜:多傳感器異步采樣帶來時序對齊難題,艙外與艙內的標注維度各異;
采集與標注成本高昂:高精度3D標注和跨模態對齊需要大量人工投入,周期長、成本高;
場景覆蓋受限:真實環境下的極端天氣、稀有交通行為和邊緣行為難以采集,長尾場景缺失嚴重。
合規性與隱私風險突出:特別是在艙內數據方面,涉及面部識別、兒童狀態等隱私敏感內容,數據采集難以持續。
數據生產速度無法匹配模型迭代頻率:模型更新周期短,而數據收集與標注無法實時響應。
因此,傳統數據采集方式已難以滿足智能汽車日益增長的感知開發需求。
 一個相機和點云數據同步繪制標注框的示例
一個相機和點云數據同步繪制標注框的示例
02 合成數據體系原則
合成數據,作為一種可控、自動化、可復現的數據生成方式,正被越來越多企業納入核心研發流程。高質量的合成數據體系應具備以下技術特性:
高度可配置性:支持對場景、參與體、傳感器參數等進行參數化建模;
自動化數據生成流程:數據采集、標注與結構化處理全過程無人工干預;
標準化輸出結構:兼容主流數據格式,易于集成于訓練、驗證與回歸流程;
強可追溯性與可復現性:每組數據可通過輸入參數精確重現,保障一致性。
推薦采用分層結構設計合成數據系統:
配置層:定義場景元素、行為策略、傳感器布局;
建模層:搭建道路結構、艙內布局、交通參與者模型;
渲染執行層:驅動仿真引擎進行時序渲染與數據采樣;
標注生成層:輸出圖像、點云、關鍵點、分割圖、3D框等標簽;
數據導出層:以任務導向的數據結構輸出結果,支持格式自定義與標準接口封裝。
這一架構的優勢在于實現邏輯與工具鏈的解耦,便于后期迭代與平臺遷移。
03 艙外場景:覆蓋長尾與多模態融合
艙外感知系統面向自動駕駛和高級輔助駕駛,涵蓋目標檢測、追蹤、語義分割、路徑預測等任務。其合成數據生成流程需覆蓋:
地圖構建與拓撲建模:包括道路結構、車道線、交通信號、標識牌等。
動態體建模與行為建控:構建多類交通參與者并設定其行為模型,模擬現實中復雜交互。
環境建模與擾動注入:配置多維氣候、光照、背景動態因素,覆蓋實際采集中難以獲取的極端條件。
多模態傳感器仿真:同步輸出相機圖像、激光雷達點云、毫米波雷達信息等。
標簽與元信息輸出:自動生成與樣本一一對應的2D/3D標簽、標注屬性、坐標系信息與時間戳。
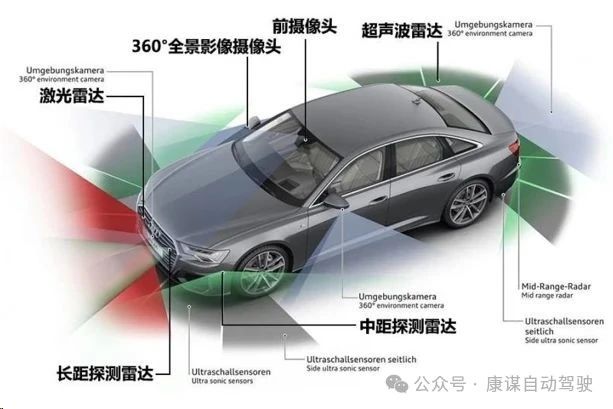 自動駕駛傳感器布局示例
自動駕駛傳感器布局示例
在數據結構方面,可參考nuScenes等主流公開數據集,輸出內容包括:
圖像與點云數據;
sample_data.json:記錄每幀傳感器輸出;
calibrated_sensor.json:定義傳感器內參與外參;
ego_pose.json:記錄自車位姿;
sample_annotation.json:包含目標類別、姿態、屬性等。
這類結構高度規范化,能夠直接對接工業級模型訓練平臺。
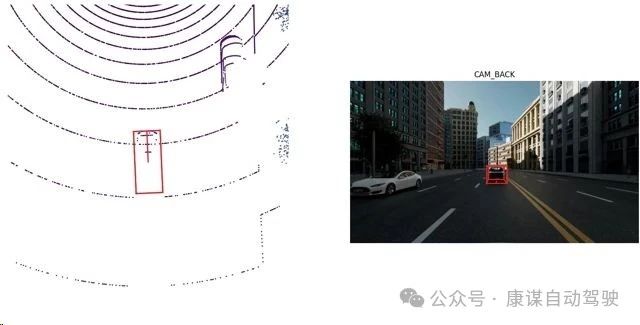 使用nuScenes工具融合繪制點云和相機標注框的示例
使用nuScenes工具融合繪制點云和相機標注框的示例
04 艙內場景:DMS/OMS場景狀態建模
艙內感知系統的發展,迫切依賴于高質量、可控、合規的數據供給。合成數據在此領域的優勢更加顯著。
艙內數據生成流程涵蓋:
人物角色建模與行為驅動:構建多樣化人群模型,并通過腳本驅動其執行如閉眼、注視、操作中控等動作。
艙內結構與光照建模:模擬不同車型、座椅布局、艙內飾件,以及多種照明干擾情況。
多攝像頭布局配置:支持模擬ADAS系統中常見布置,如A柱、后視鏡下方、方向盤攝像頭等。
多標簽同步輸出:生成RGB圖像、深度圖、語義圖、關鍵點坐標、行為狀態標簽等。
同時,艙內場景需要重點關注以下干擾要素:
遮擋情況模擬(口罩、墨鏡、靠枕);
光照擾動(反光、背光、高對比);
姿態多樣性(側臥、低頭、歪斜等復雜行為);
行為序列的時間連續性與自然性。
數據結構建議以目錄方式組織,明確劃分圖像類、幾何類與標簽類數據,保障時序一致性與跨視角同步。
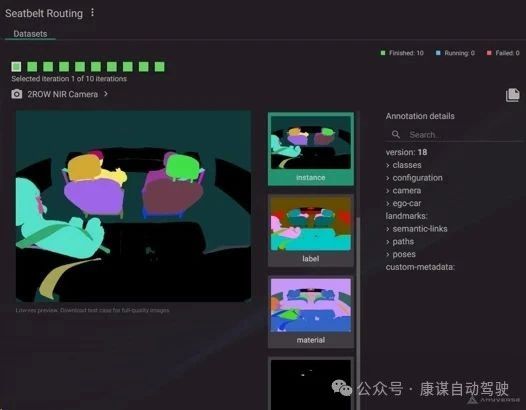 提供多種數據分割方式及標注JSON文件的艙內合成數據示例
提供多種數據分割方式及標注JSON文件的艙內合成數據示例
05 合成數據:助力感知系統開發
綜上所述,合成數據不再是數據稀缺時的權宜之計,而正在演變為智能汽車感知系統大規模、高頻率、端到端開發的關鍵支撐。通過系統性建設合成數據體系,開發團隊可以實現:
快速生成高質量訓練數據,覆蓋邊緣與稀缺場景;
標注自動化與一致性保障;
多模態融合的標準化輸出;
可追溯、可重現的驗證機制。
企業在構建合成數據平臺時,重點關注以下三點:
平臺工具鏈解耦:保持生成邏輯獨立于具體仿真平臺;
結構對齊標準數據集:如 nuScenes、COCO 等;
自動化與參數化流程完整閉環。
通過艙外與艙內雙向并進的合成數據體系,智能汽車的感知能力將具備更高的魯棒性、覆蓋性與工程實用性。????
審核編輯 黃宇
-
智能汽車
+關注
關注
30文章
3088瀏覽量
108389
發布評論請先 登錄
51Sim利用NVIDIA Cosmos提升輔助駕駛合成數據場景的泛化性
康謀分享| 揭秘C-NCAP :合成數據如何助力攻克全球安全合規難關?

CPO光電共封裝如何破解數據中心“功耗-帶寬”困局?
NVIDIA GTC巴黎亮點:全新Cosmos Predict-2世界基礎模型與CARLA集成加速智能汽車訓練
干貨分享 | 從云端到單機的數據匿名化全攻略

電信運營商如何破解數據存力瓶頸
大模型時代的新燃料:大規模擬真多風格語音合成數據集
技術分享 | 高逼真合成數據助力智駕“看得更準、學得更快”

借助OpenUSD與合成數據推動人形機器人發展

技術分享 | AVM合成數據仿真驗證方案

RTX 5880 Ada 驅動51Sim實現端到端仿真與數據合成新飛躍





 工商網監
工商網監
評論