 谷歌如何利用深度學習來實現智能郵件助手
谷歌如何利用深度學習來實現智能郵件助手
谷歌在不久前的I/O大會上推出了輔助人們高效撰寫郵件的智能寫作助手。在深度神經網絡的幫助下,它可以根據用戶很少的輸入信息就推斷出接下來想要寫入文本,就如知心好友一般默契無間了!我們先來感受一下在它的幫助下寫郵件多么暢快:
智能寫作是基于一年前谷歌發布的智能回復功能進一步研發而成的。先前的智能回復功能通過分析郵件內容來幫助用戶快速撰寫回復郵件使用戶在移動端處理郵件的效率有了大幅的提升。
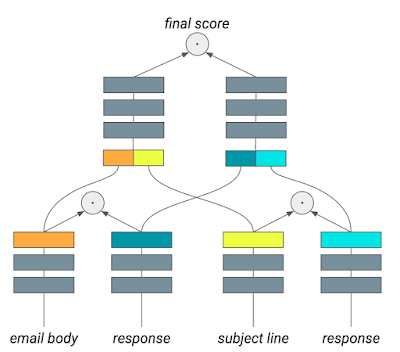
它基于人類語言中的層級結構,從字母到單詞、從短語到句子、從段落到章節和整篇完整表達的內容。研究人員們訓練出了了一系列層級模塊用于學習、記憶和識別一種特定的模式。在足夠多樣本的訓練下層級模型取得了比LSTM更好的效果,并具有了一定的語音表達能力。下圖中藍色字體就是模型分析郵件后為用戶生成出備選的恢復內容。
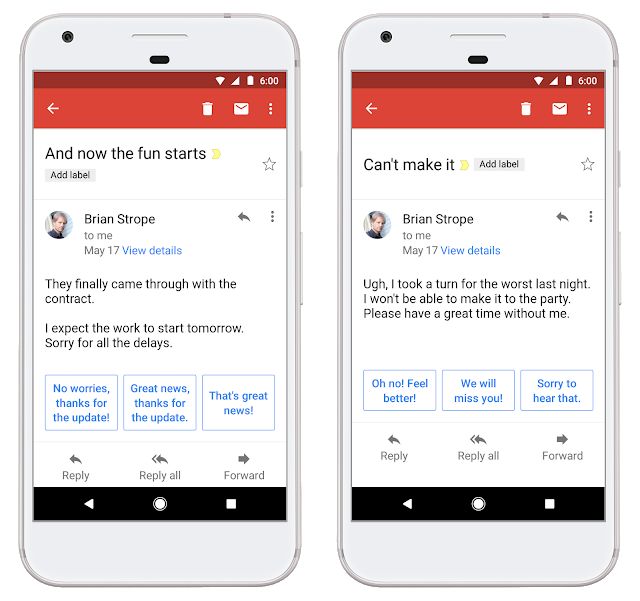
但從智能回復到智能寫作助手的研發過程中,除了迅速響應大規模用戶的需求、還需要兼顧公平和用戶的隱私。
首先在用戶撰寫郵件時,為了不使用戶感受到明顯的延遲,其響應需要在100ms以內,這要求在模型的效率和復雜度上做有效的權衡;目前Gmail擁有14億以上的用戶,所以模型需要有足夠的容量滿足各種不同用戶的個性化需求;除了速度和規模外,還需要防止這一功能由于訓練數據產生偏見,并且也要符合嚴格的隱私規定,防止用戶的隱私信息泄露。由于研究人員不可以進入email中,所以所有的機器學習系統都是運行在他們不可讀的數據集上的。
尋找合適的模型
典型的語言生成模型包括N-Gram、神經詞袋和循環神經網絡語言模型,它們通過先前詞匯預測后續詞匯或者句子。然而在郵件中,模型只有當前郵件對話這一單一的信號來預測后續的詞匯。為了更好的理解用戶想要表達的內容,模型同時還會分析郵件標題和之前郵件的內容。
這種需要疊加上下文的文本分析會帶來一個seq2seq機器翻譯同樣的問題,其中源序列是主題和先前郵件內容的組合、目標序列則是目前用戶正在撰寫的郵件。它雖然在但是卻無法滿足嚴格的時間要求。為了改進這一點,研究人員們將詞袋模型和循環神經網絡語言模型結合起來,實現了比seq2seq更快的的速度,但只在預測質量上做出了輕微的犧牲。
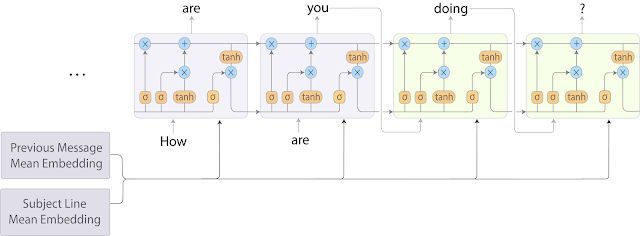
如上圖所示,在這一混合模型中標題和先前的郵件先用詞向量平均處理,而后將他們輸入到接下來的循環神經網絡中去解碼。
加速模型訓練和服務
為了加速模型的訓練和調參,研究人員們使用了自家的大殺器TPU,只需要不到一年就能在幾十億的樣本上實現收斂。
雖然訓練速度提高了,但在實際使用時候的速度才是用戶最為關心的指標。通過將CPU的計算請求分配到TPU上得到了迅速的推理結果,同時由于CPU的算力得到了釋放,使得單機可以提供服務的用戶數量大幅增加。
公平性和隱私
對于機器學習來說,公平性和隱私是至關重要的問題。語言模型可以折射出人類的認知偏見,這樣會生成一系列不希望的句子補全。這些偏見和聯系主要來自于語言數據,這對于構建一個無偏模式是巨大的挑戰。于是研究人員們通過各種方式不斷減弱訓練過程中潛在的偏見。同時智能寫作助手是構建于數十一個樣本上的訓練結果,只有同時被多個用戶確認的通用結果才會被模型記住。
語言模型中一種常見的性別偏見
在未來這一模型會被持續改進,并嘗試著加入一些先進的模型架構(例如transformer和RNMT+等)和先進的訓練技術,同時在生產中部署更多的先進模型來滿足實時性和要求。個人語言模型會在隨后加入以更精確的滿足個人的寫作風格和表達習慣。
-
谷歌
+關注
關注
27文章
6210瀏覽量
106237 -
深度學習
+關注
關注
73文章
5523瀏覽量
121699
原文標題:谷歌如何利用深度學習來實現智能郵件助手,知你所想想你所寫?
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
FPGA加速深度學習模型的案例
利用Matlab函數實現深度學習算法
深度學習在視覺檢測中的應用
深度學習與nlp的區別在哪
人工智能、機器學習和深度學習是什么
人工智能深度學習的五大模型及其應用領域
深度學習常用的Python庫
深度學習與傳統機器學習的對比
谷歌呼吁減少企業“釣魚郵件測試”,其負面影響大于潛在收益
谷歌Gmail將支持Gemini總結電子郵件內容
FPGA在深度學習應用中或將取代GPU
為什么深度學習的效果更好?






 工商網監
工商網監
評論