 Summit系統創造性能新記錄,突破了每秒100千萬億的次浮點運算!
Summit系統創造性能新記錄,突破了每秒100千萬億的次浮點運算!
近日,橡樹嶺國家實驗室的Summit系統呈獻了又一場超級計算盛宴,創造了又一項性能記錄,該系統首次突破了每秒100千萬億次浮點運算性能的壁壘。
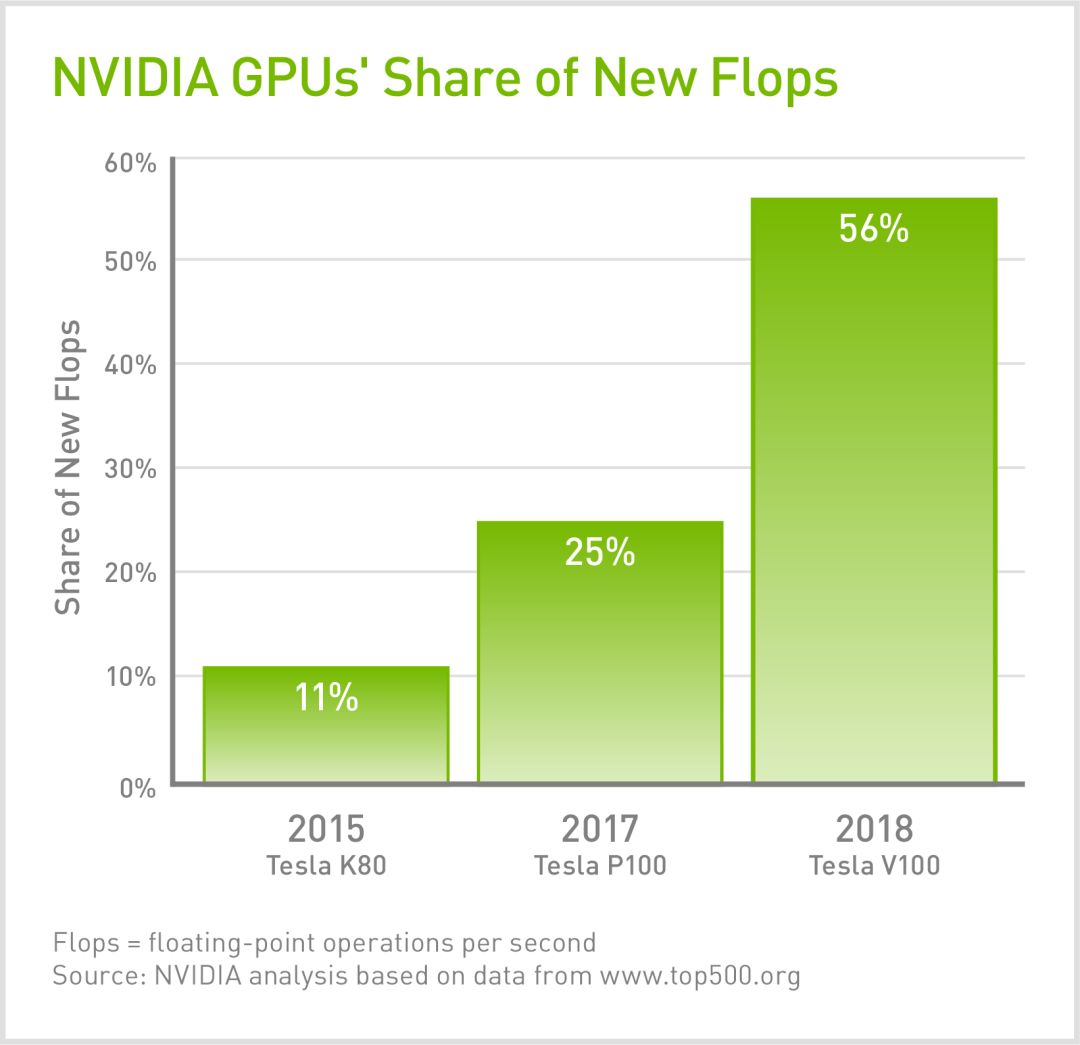
在最新發布的Top500榜單中,大部分系統的新處理能力均來自GPU。目前世界七大超級計算機中有五款都在采用GPU,包括美國、歐洲和日本的頂尖系統。
而對于Summit,GPU滿足了其95%的浮點運算性能要求。隨著摩爾定律的不斷放緩,加速計算顯然已經成為助推器,將很快推動我們進入百億億次級計算時代。
這樣的計算性能由NVIDIA Volta Tensor Core GPU提供,其多精度計算能力將能同時應對高性能計算所需的高精度計算挑戰,以及深度學習所需的高效處理的要求。
加速計算登峰造極
每年兩次的超級計算展見證了加速計算近年來的飛速發展。在ISC 2018上,這一領域再次實現了突破。
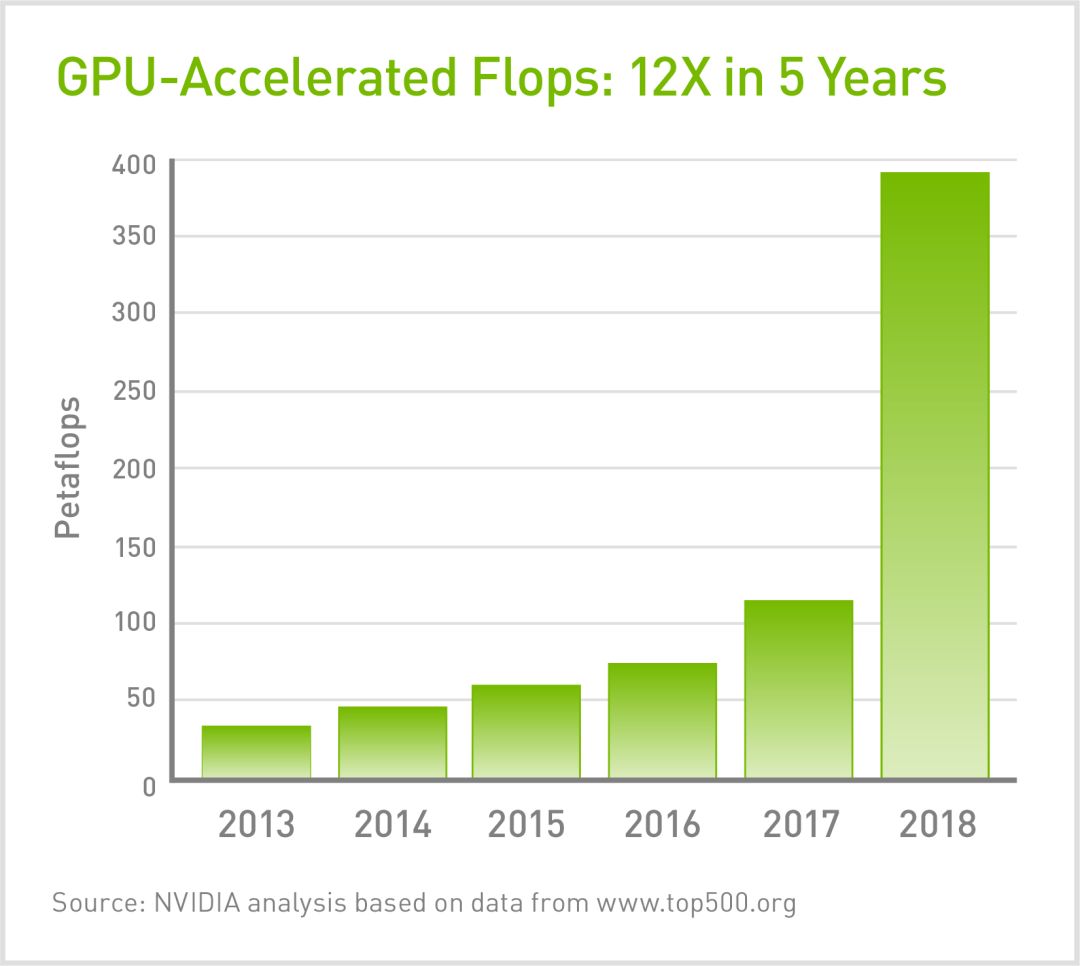
Summit顯然是最有力的證據。該系統采用27648塊Volta Tensor Core GPU,其測得的雙精度性能達到每秒122千萬億次浮點運算。它每秒的性能相當于地球上所有人以每秒執行一次計算的速度執行一整年的任務。
其AI性能更加令人矚目,運算速度可達到300億億次。這相當于整個地球上的人在15年內每秒進行一次計算。
至省與至簡
多精度計算開辟了新的可能性。但是,如果GPU無法提供非凡的效率,相應的效用將受限。
在最新的Green500榜單,GPU為全球20個最具環保效益的系統中的17個提供支持。Summit不僅是世界上速度最快的系統,而且在新確立的“三級”類別(Green500 榜單中最嚴格的級別)中是世界上最高效的系統。
在過去10年中,GPU已經幫助美國橡樹嶺國家實驗室將其超級計算機的能源效率提高了50倍,這些計算機包括僅支持CPU的Jaguar及由GPU加速的Titan和Summit。
而所有這些僅僅是一個開始。實現百億億次級計算需要在能源效率方面實現更大突破。以Green500榜單中系統的平均效率計算,為百億億次級計算提供動力將需要超過3億瓦的電能,這相當于25萬個美國家庭的電力需求。需要將能效提高10倍才能使百億億次級計算在3千萬瓦條件下運行。
GPU正在幫助Summit實現這一目標。
破解難題
最新頂尖系統具備的處理能力曾經令人無法想象,但現在的研究人員將能夠借助這些系統解決一些科學上最棘手的難題。
比如,遺傳學。帕金森癥和阿爾茨海默癥等可以稱得上是“毀滅性”疾病,而GPU的計算能力將可以破解這樣的難題,找出人類基因組的數十億個AGCT DNA對與諸如此類疾病之間的聯系。Summit已在梳理個人基因,以實現在阿片成癮(美國人的主要致死原因之一)研究方面的進展。
又如,材料。超導材料可用于為MRI設備、粒子加速器或磁聚變裝置開發功能強大的科學磁體。然而,目前的材料十分易碎、難以制造,并且只能在非常低的溫度下工作。Summit正在幫助模擬和發現具有類金屬特性且可在室溫下工作的新型超導材料。
再如,癌癥研究。對抗癌癥的關鍵在于開發可以自動提取、分析和分類健康數據的工具,以便揭示各種疾病因素(例如基因、生物學標記和環境)之間隱藏的關系。通過與基于文本的報告和醫學影像等非結構化數據配合使用,在Summit上擴展的深度學習算法將有助于醫學研究人員全面了解美國癌癥患者的整體情況。
繼續前進
每個國家/地區都在競相構建百億億次級計算系統。2025年的Top500榜單可能會看到十多款這樣的系統,而且多精度加速計算成為平臺首選。相比之下,本次Top500榜單上的所有系統加在一起才勉強實現一百億億次級的總計算能力。這足以說明未來蘊藏著巨大機遇。
加速計算的一大吸引力在于它屬于全棧創新:從架構一直到系統、加速堆棧、開發人員和半導體工藝,無一不體現著創新精神。
NVIDIA已經投入了超過10年的時間來加速整個HPC堆棧的開發。
當我們發布第一款支持CUDA的GPU時,它無法運行任何應用程序。我們需要為全新的加速環境重新設計所有的應用程序、算法、庫、工具、編譯器、操作系統和系統設計。打造一種能夠處理數學處理器的芯片很容易,而要使全球高性能計算開發人員可以使用和編程這些處理器,則需要在整個堆棧上實現非凡的創新。
結果,550多款高性能計算和AI應用程序都由GPU加速,其中包括排名靠前的15種應用程序和所有AI框架。致力于此領域的開發人員數量在過去的五年里增加了10倍,現已接近一百萬。而且,利用我們NGC容器注冊上的最新高性能計算容器,高性能計算用戶現在可以在他們的系統或Tensor Core GPU驅動的云上輕松點擊、下載并運行最新的GPU加速應用程序。
轉折與展望
在我們快速發展加速計算的同時,一些人也正在尋找量子計算的下一個轉折點,量子計算使用量子位元(“qubits”)而不是1和0來處理信息。
這些理論十分具有吸引力。在未來的某個時候,可能會出現一些在量子計算機上運行的殺手級應用程序(特別是在密碼學或量子化學領域),只需極小的功率即可利用超強的處理能力。
但在可預見的未來,加速計算的勢頭似乎不可阻擋。NVIDIA會繼續致力于在高性能計算領域的創新,將實現百億億次級計算以及其為科學領域帶來的突破。
-
NVIDIA
+關注
關注
14文章
5258瀏覽量
105857 -
gpu
+關注
關注
28文章
4916瀏覽量
130727
原文標題:加速計算成為助推器,帶我們進入百億億次級計算時代
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
?為什么GPU性能效率比峰值性能更關鍵

驅動 AI 邊緣計算新時代!高性能 i.MX 95 應用平臺引領未來

零次方機器人完成數千萬元天使輪融資
【RA-Eco-RA4E2-64PIN-V1.0開發板試用】RA4E2的DSP浮點性能的軟件浮點測試和硬件浮點測試對比
FPGA中的浮點四則運算是什么
FPGA中浮點四則運算的實現過程
如何選擇合適的NPU型號
【RA-Eco-RA2E1-48PIN-V1.0開發板試用】在M23內核上使用qfplib浮點運算庫進行浮點運算
【AG32開發板免費試用】+數據采集存儲系統(2)-串口輸出+浮點運算驗證


解析OrangePi AIpro:什么是 TOPS,為什么它對?AI?PC很重要?

打破系統局限性:來自de next-TGU8-EZBOX的能量釋放






 工商網監
工商網監
評論