") FPGA和SoC將成為機器學(xué)習(xí)發(fā)展的2大助力
FPGA和SoC將成為機器學(xué)習(xí)發(fā)展的2大助力
一系列機器學(xué)習(xí)優(yōu)化芯片預(yù)計將在未來幾個月內(nèi)開始出貨,但數(shù)據(jù)中心需要一段時間才能決定這些新的加速器是否值得采用,以及它們是否真的能在性能上獲得大幅提升。
有大量的報道稱,為機器學(xué)習(xí)設(shè)計的定制芯片將提供100倍于現(xiàn)有選擇的性能,但它們在要求嚴(yán)格的商業(yè)用途的實際測試中的功能尚未得到證實,數(shù)據(jù)中心是新技術(shù)最保守的采用者之一。不過,Graphcore、Habana、ThinCI和Wave Computing等知名初創(chuàng)公司表示,它們已經(jīng)將早期芯片提供給客戶進行測試。但還沒有一家公司開始發(fā)貨,甚至沒有展示這些芯片。
這些新設(shè)備有兩個主要市場。機器學(xué)習(xí)中的神經(jīng)網(wǎng)絡(luò)將數(shù)據(jù)分為兩個主要階段:訓(xùn)練和推理,并且在每個階段中使用不同的芯片。雖然神經(jīng)網(wǎng)絡(luò)本身通常駐留在訓(xùn)練階段的數(shù)據(jù)中心中,但它可能具有用于推理階段的邊緣組件。現(xiàn)在的問題是什么類型的芯片以及哪種配置能夠產(chǎn)生最快、最高效的深度學(xué)習(xí)。
看來FPGAs和SoCs正在獲得更多的吸引力。Tirias Research總裁吉姆·麥格雷戈(Jim McGregor)說,這些數(shù)據(jù)中心需要可編程芯片的靈活性和高I/O能力,這有助于FPGA在訓(xùn)練和推理的高數(shù)據(jù)量、低處理能力需求中發(fā)揮作用。
與幾年前相比,F(xiàn)PGA的設(shè)置現(xiàn)在用于訓(xùn)練的頻率更低了,但它們在其他任何事情上的使用頻率都要高得多,而且它們很可能在明年繼續(xù)增長。即使大約50家致力于神經(jīng)網(wǎng)絡(luò)優(yōu)化處理器迭代開發(fā)的初創(chuàng)公司今天都交付了成品,在任何規(guī)模可觀的數(shù)據(jù)中心的生產(chǎn)流程中,也需要9到18個月的時間。
McGregor說:“沒有人會買現(xiàn)成的數(shù)據(jù)中心,然后把它放到生產(chǎn)機器上。”“您必須確保它滿足可靠性和性能要求,然后才能將其全部部署。”
圖1:不同類型深度學(xué)習(xí)芯片占比
對于新的架構(gòu)和微體系架構(gòu),仍然有機會。ML工作負載正在迅速擴展。OpenAI 5月份的一份報告顯示,用于最大AI/ML訓(xùn)練的計算能力每3.5個月就增加一倍,自2012年以來,計算能力的總量增加了30萬倍。相比之下,按照摩爾定律,可用資源每18個月增加一倍,最終總?cè)萘績H增加12倍。
Open.AI指出,用于最大規(guī)模訓(xùn)練的系統(tǒng)(其中一些需要幾天或幾周的時間才能完成)需要花費數(shù)百萬美元購買,但它預(yù)計,用于機器學(xué)習(xí)硬件的大部分資金將用于推理。
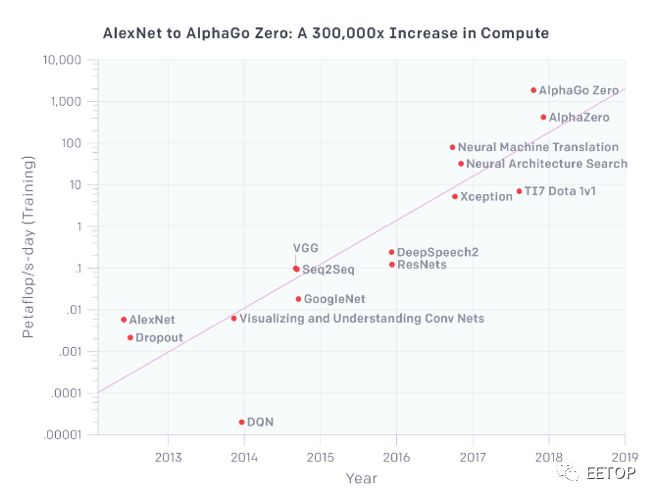
圖2:計算需求正在增加
這是一個巨大的全新的機遇。Tractica在5月30日的一份報告中預(yù)測,到2025年,深度學(xué)習(xí)芯片組的市場規(guī)模將從2017年的16億美元增至663億美元,其中包括CPU,GPU,F(xiàn)PGA,ASIC,SoC加速器和其他芯片組。其中很大一部分將來自于非芯片公司,它們正在發(fā)布自己的深度學(xué)習(xí)加速器芯片組。谷歌的TPU就是這么做的,業(yè)內(nèi)人士表示,亞馬遜和Facebook正在走同樣的道路。
McGregor說,現(xiàn)在主要轉(zhuǎn)向SoC而不是獨立的組件,并且SoC、ASIC和FPGA供應(yīng)商的策略和封裝的多樣性日益增加。
Xilinx、Inetel和其他公司正試圖通過向FPGA陣列添加處理器和其他組件來擴大FPGA的規(guī)模。其他的,如Flex Logix、Achronix和Menta,將FPGA資源嵌入到靠近SoC特定功能區(qū)域的小塊中,并依賴高帶寬互連來保持?jǐn)?shù)據(jù)的移動和高性能。
McGregor說:“你可以在任何你想要可編程I/O的地方使用FPGA,人們會將它們用于推理,有時還會進行訓(xùn)練,但是你會發(fā)現(xiàn)它們會更多地用于處理大數(shù)據(jù)任務(wù)而不是訓(xùn)練,這需要大量的矩陣乘法,更適合于GPU。”
然而,GPU并不是瀕臨滅絕的物種。根據(jù)MoorInsights & Strategy分析師Karl Freund在一篇博客文章中所說。
英偉達本月早些時候公布了NVIDIA TensorRT超大尺寸推理平臺的聲明,其中包括提供65TFLOPS用于訓(xùn)練的Tesla T4 GPU和每秒260萬億次4位整數(shù)運算(TOPS)的推理 - 足以同時處理60個視頻流速度為每秒30幀。它包括320“Turing Tensorcores”,針對推理所需的整數(shù)計算進行了優(yōu)化。
新的架構(gòu)
Graphcore是最著名的初創(chuàng)公司之一,正在開發(fā)一款236億晶體管的“智能處理單元”(IPU),具有300MB的片上存儲器,1216個核心,每個核心可以達到11GFlops,內(nèi)部存儲器帶寬為30TB/s。其中兩個采用單個PCIe卡,每個卡都設(shè)計用于在單個芯片上保存整個神經(jīng)網(wǎng)絡(luò)模型。
GraphCore即將推出的芯片基于圖形架構(gòu),該架構(gòu)依賴于其軟件將數(shù)據(jù)轉(zhuǎn)換為頂點,其中數(shù)字輸入,應(yīng)用于它們的函數(shù)(加,減,乘,除)和結(jié)果是單獨定義的,可以是并行處理。其他幾家ML初創(chuàng)公司也使用類似的方法。
Wave Computing沒有透露何時發(fā)貨,但在上周的人工智能硬件會議上透露了更多關(guān)于其架構(gòu)的信息。該公司計劃銷售系統(tǒng)而不是芯片或電路板,使用帶有15 Gbyte /秒端口的16nm處理器和HMC存儲器和互連,這種選擇旨在快速推送圖形通過處理器集群而無需通過處理器發(fā)送數(shù)據(jù)超過瓶頸一個PCIe總線。該公司正在探索轉(zhuǎn)向HBM內(nèi)存以獲得更快的吞吐量。
圖3:Wave計算的第一代數(shù)據(jù)流處理單元
機器學(xué)習(xí)的異構(gòu)未來和支持的硅片的最佳指標(biāo)之一來自微軟 - 這是FPGA,GPU和其他深度學(xué)習(xí)的巨大買家。
“雖然面向吞吐量的架構(gòu),如GPGPUs和面向批處理的NPU,在離線訓(xùn)練和服務(wù)中很受歡迎,但對于DNN模型的在線、低延遲的服務(wù),它們的效率并不高,”2018年5月發(fā)表的一篇論文描述了Brainwave 項目,這是微軟在deep neural networking (DNN)中高效FPGA的最新版本。
微軟率先將FPGA廣泛用作大規(guī)模數(shù)據(jù)中心DNN推理的神經(jīng)網(wǎng)絡(luò)推理加速器。 Rambus的杰出發(fā)明人兼企業(yè)解決方案技術(shù)副總裁Steven Woo表示,該公司不是將它們用作簡單的協(xié)處理器,而是“更靈活,一流的計算引擎”。
根據(jù)微軟的說法,Brainwave項目可以使用英特爾Stratix 10 FPGA池提供39.5 TFLOPS的有效性能,這些FPGA可以被共享網(wǎng)絡(luò)上的任何CPU軟件調(diào)用。框架無關(guān)系統(tǒng)導(dǎo)出深度神經(jīng)網(wǎng)絡(luò)模型,將它們轉(zhuǎn)換為微服務(wù),為Bing搜索和其他Azure服務(wù)提供“實時”推理。
圖4:微軟的Brainwave項目將DNN模型轉(zhuǎn)換為可部署硬件微服務(wù),將任何DNN框架導(dǎo)出為通用圖形表示,并將子圖分配給CPU或FPGA
Brainwave是德勤全球(DeloitteGlobal)所稱的“戲劇性轉(zhuǎn)變”的一部分,這一轉(zhuǎn)變將強調(diào)FPGA和ASIC,到2018年,它們將占據(jù)機器學(xué)習(xí)加速器25%的市場份額。2016年,CPU和GPU占據(jù)了不到20萬臺的市場份額。德勤預(yù)測,到2018年,CPU和GPU將繼續(xù)占據(jù)主導(dǎo)地位,銷量將超過50萬部,但隨著ML項目數(shù)量在2017年至2018年翻一番、在2018年至2020年再翻一番,總市場將包括20萬FPGA和10萬ASIC。
德勤(Deloitte)表示,F(xiàn)PGA和ASIC的耗電量遠低于GPU、CPU,甚至比谷歌每小時75瓦的TPU耗電量還要低。它們還可以提高客戶選擇的特定功能的性能,這可以隨著編程的變化而改變。
Achronix的營銷副總裁SteveMensor說:“如果人們有他們的選擇,他們會在硬件層面上用ASIC構(gòu)建東西,但是FPGA比GPU有更好的功耗/性能,而且他們在定點或可變精度架構(gòu)方面非常擅長。”
ArterisIP的董事長兼首席執(zhí)行官CharlieJanac說:“有很多很多的內(nèi)存子系統(tǒng),你必須考慮低功耗和物聯(lián)網(wǎng)應(yīng)用,網(wǎng)格和環(huán)路。”“所以你可以把所有這些都放到一個芯片中,這是你決策物聯(lián)網(wǎng)芯片所需要的,或者你可以添加高吞吐量的HBM子系統(tǒng)。但是工作負載非常特殊,每個芯片有多個工作負載。因此,數(shù)據(jù)輸入是巨大的,尤其是如果你要處理雷達和激光雷達之類的東西,而這些東西沒有先進的互連是不可能存在的。
由于應(yīng)用程序的特殊性,連接到該互連的處理器或加速器的類型可能會有很大的不同。
NetSpeed Systems負責(zé)營銷和業(yè)務(wù)開發(fā)的副總裁阿努什?莫罕達斯(Anush Mohandass)表示:“在核心領(lǐng)域,迫切需要大規(guī)模提高效率。”““我們可以放置ASIC和FPGA以及SoC,我們的預(yù)算越多,我們就可以放入機架。”但最終你必須高效;你必須能夠進行可配置或可編程的多任務(wù)處理。如果你能將多播應(yīng)用到向量處理工作負載上,而向量處理工作負載是大部分訓(xùn)練階段的內(nèi)容,那么您能夠做的事情就會大大擴展。“
FPGA并不是特別容易編程,也不像樂高積木那樣容易插入設(shè)計,盡管它們正在朝著這個方向快速發(fā)展,SoC比FPGA更容易使用計算核心、DSP核心和其他IP模塊。
但是,從類似SoC的嵌入式FPGA芯片轉(zhuǎn)變?yōu)榫哂嗅槍C器學(xué)習(xí)應(yīng)用優(yōu)化的數(shù)據(jù)背板的芯片上的完整系統(tǒng)并不像聽起來那么容易。
Mohandass說:“性能環(huán)境是如此的極端,需求是如此的不同,以至于AI領(lǐng)域的SoC與傳統(tǒng)的架構(gòu)完全不同。”“現(xiàn)在有更多的點對點通信。你正在做這些向量處理工作,有成千上萬的矩陣行,你有所有這些核心可用,但我們必須能夠跨越幾十萬個核心,而不是幾千個。
性能是至關(guān)重要的。設(shè)計、集成、可靠性和互操作性的便捷性也是如此——SoC供應(yīng)商將重點放在底層框架和設(shè)計/開發(fā)環(huán)境上,而不僅僅是針對機器學(xué)習(xí)項目的特定需求的芯片組。
NetSpeed推出了專門為深度學(xué)習(xí)和其他人工智能應(yīng)用程序設(shè)計的SoC集成平臺的更新版本,該服務(wù)使集成NetSpeed IP變得更容易,該設(shè)計平臺使用機器學(xué)習(xí)引擎推薦IP塊來完成設(shè)計。該公司表示,其目標(biāo)是在整個芯片上提供帶寬,而不是傳統(tǒng)設(shè)計的集中式處理和內(nèi)存。
Mohandass說:“從ASIC到神經(jīng)形態(tài)芯片,再到量子計算,一切都在進行中,但即使我們不需要改變我們當(dāng)前架構(gòu)的整體基礎(chǔ)(以適應(yīng)新的處理器),這些芯片的大規(guī)模生產(chǎn)仍遙遙無期。”但我們都在解決同樣的問題。當(dāng)他們從上到下進行工作時,我們也從下到上進行工作。
Flex Logix的CEOGeoff Tate認為,CPU仍然是數(shù)據(jù)中心中最常用的數(shù)據(jù)處理元素,其次是FPGA和GPU。但他指出,需求不太可能在短時間內(nèi)下降,因為數(shù)據(jù)中心試圖跟上對自己的機器學(xué)習(xí)應(yīng)用程序的需求。
泰特說:“現(xiàn)在人們花了很多錢來設(shè)計出一種比GPU和FPGA更好的產(chǎn)品。”“總的趨勢似乎是神經(jīng)網(wǎng)絡(luò)的硬件更加專業(yè)化,所以這就是我們可能會走向的地方。”例如,微軟表示,他們使用所有東西——CPU、GPU、TPU和FPGA——根據(jù)這些,他們可以在特定的工作負載下獲得最佳的性價比。
-
FPGA
+關(guān)注
關(guān)注
1630文章
21798瀏覽量
606054 -
微軟
+關(guān)注
關(guān)注
4文章
6630瀏覽量
104479 -
soc
+關(guān)注
關(guān)注
38文章
4204瀏覽量
219109 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8441瀏覽量
133091
原文標(biāo)題:機器學(xué)習(xí)將越來越依賴FPGA和SoC
文章出處:【微信號:eetop-1,微信公眾號:EETOP】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
SoC FPGA與MCU的優(yōu)勢對比,應(yīng)如何選擇
學(xué)習(xí)FPGA的對今后的發(fā)展有什么影響
家用服務(wù)機器人將成為機器人的下一個入口
超低功耗FPGA解決方案助力機器學(xué)習(xí)
傳感器將成為機器人無可替代的依賴之一
消費電子助力SoC發(fā)展,多核技術(shù)是焦點
FPGA將成為標(biāo)準(zhǔn)化虛擬SoC平臺
關(guān)于FPGA的學(xué)習(xí)和發(fā)展問題
FPGA、ASIC有望在機器學(xué)習(xí)領(lǐng)域中崛起
如何借助Xilinx FPGA和MATLAB技術(shù)加速機器學(xué)習(xí)應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論