 新書《解析深度學習:卷積神經網絡原理與視覺實踐》試讀
新書《解析深度學習:卷積神經網絡原理與視覺實踐》試讀
“市面上深度學習書籍已不少,但專門針對卷積神經網絡展開,側重實踐又不失論釋者尚不多見。本書基本覆蓋了卷積神經網絡實踐所涉之環節,作者交代的若干心得技巧亦可一觀,讀者在實踐中或有見益。”
這是周志華教授對他的學生、南京大學LAMDA研究所博士魏秀參所著新書《解析深度學習:卷積神經網絡原理與視覺實踐》的高度評價。
魏秀參專注于卷積神經網絡及其視覺應用,先后師從周志華教授和吳建鑫教授,在相關領域重要國際期刊和國際會議發表論文十余篇,并兩次獲得國際計算機視覺相關競賽冠、亞軍,博士未畢業即被曠視科技聘為南京研究院負責人。
機器學習領域專業、實用的好書很多,但多是英文翻譯而來,中文書籍委實不多,魏秀參的新書是其中令人眼前一亮的一本。正如作者所說,“這是一本面向中文讀者的輕量級、偏實用的深度學習工具書”,向讀者剖析了卷積神經網絡的基本部件與工作機理,更重要的是系統性地介紹了深度卷積神經網絡在實踐應用方面的細節配置與工程經驗。
周志華推薦序
卷積神經網絡乃機器學習領域中深度學習技術最著名內容之一。魏秀參博士在LAMDA 求學數年,對卷積神經網絡及其視覺應用頗有所長,博士未畢業即被曠視科技聘為南京研究院負責人,畢業之際將心得材料轉撰成書請愚致序。師生之誼,盛情難卻。
在國內計算機領域,寫書乃吃力不討好之事。且不論寫一本耐讀、令讀者每閱皆有所獲之書何等不易,更不消說眾口難調出一本令各型讀者皆贊之書何等無望,僅認真寫書所耗時間精力之巨、提職時不若期刊論文之效、收入不比同等精力兼差打工之得,已令人生畏,何況稍有不慎就有誤人子弟之嫌,令一線學者若不狠心苛己,實難著手。
然有志求學本領域之士漸增,母語優良讀物之不足實礙科學技術乃至產業發展。畢竟未必眾人皆慣閱外文書籍,亦未必盡能體會外文微妙表達變化之蘊義,更不消說母語閱讀對新入行者之輕快適意。愚曾自認四十不惑前學力不足立著,但國內科研水準日新月異,青年才俊茁然成長,以旺盛之精力分享所學,誠堪嘉勉。
市面上深度學習書籍已不少,但專門針對卷積神經網絡展開,側重實踐又不失論釋者尚不多見。本書基本覆蓋了卷積神經網絡實踐所涉之環節,作者交代的若干心得技巧亦可一觀,讀者在實踐中或有見益。望本書之出版能有助于讀者更好地了解和掌握卷積神經網絡,進一步促進深度學習技術之推廣。
周志華
2018 年10 月于南京
小而精,為中文讀者打造偏實用深度學習工具書
作者簡介
魏秀參
曠視科技(Face++)南京研究院負責人。南京大學LAMDA研究所博士,主要研究領域為計算機視覺和機器學習。在相關領域重要國際期刊和國際會議發表論文十余篇,并兩次獲得國際計算機視覺相關競賽冠、亞軍。曾獲CVPR 2017最佳審稿人、南京大學博士生校長特別獎學金等榮譽,擔任ICCV、CVPR、ECCV、NIPS、IJCAI、AAAI等國際會議PC member。
前言
人工智能,一個聽起來熟悉但卻始終讓人備感陌生的詞匯。讓人熟悉的是科幻作家艾薩克·阿西莫夫筆下的《機械公敵》和《機器管家》,令人陌生的卻是到底如何讓現有的機器人咿呀學語、邯鄲學步;讓人熟悉的是計算機科學與人工智能之父圖靈設想的“圖靈測試”,令人陌生的卻是如何使如此的高級智能在現實生活中不再子虛烏有;讓人熟悉的是2016 年初阿爾法狗與李世乭在圍棋上的五番對決,令人陌生的卻是阿爾法狗究竟是如何打通了“任督二脈”的……不可否認,人工智能就是人類為了滿足自身強大好奇心而腦洞大開的產物。現在提及人工智能,就不得不提阿爾法狗,提起阿爾法狗就不得不提到深度學習。那么,深度學習究竟為何物?
本書從實用角度著重解析了深度學習中的一類神經網絡模型——卷積神經網絡,向讀者剖析了卷積神經網絡的基本部件與工作機理,更重要的是系統性地介紹了深度卷積神經網絡在實踐應用方面的細節配置與工程經驗。
筆者希望本書“小而精”,避免像某些國外相關教材一樣淺嘗輒止的“大而空”。
寫作本書的主因源自筆者曾于2015 年10 月在個人主頁(http://lamda.nju.edu.cn/weixs)上開放的一個深度學習的英文學習資料“深度神經網絡之必會技巧”(Must Know Tips/Tricks in Deep Neural Networks)。該資料隨后被轉帖至新浪微博,受到不少學術界和工業界朋友的好評,至今已有逾36 萬的閱讀量,后又被國際知名論壇 KDnuggets 和 Data Science Central 特邀轉載。在此期間,筆者頻繁接收到國內外讀過此學習資料的朋友微博私信或郵件來信表示感謝,其中多人提到希望開放一個中文版本以方便國人閱讀學習。另一方面,隨著深度學習領域發展的日新月異,當時總結整理的學習資料現在看來已略顯滯后,不少最新研究成果并未涵蓋其中,同時加上國內至今尚沒有一本側重實踐的深度學習方面的中文書籍。因此,筆者筆耕不輟,希望將自己些許的所學所知所得所感及所悟匯總于本書中,分享給大家學習和查閱。
這是一本面向中文讀者的輕量級、偏實用的深度學習工具書,本書內容側重深度卷積神經網絡的基礎知識和實踐應用。為了使盡可能多的讀者通過本書對卷積神經網絡和深度學習有所了解,筆者試圖盡可能少地使用晦澀的數學公式,而盡可能多地使用具體的圖表形象表達。本書的讀者對象為對卷積神經網絡和深度學習感興趣的入門者,以及沒有機器學習背景但希望能快速掌握該方面知識并將其應用于實際問題的各行從業者。為方便讀者閱讀,本書附錄給出了一些相關數學基礎知識簡介。
全書共有14 章,除“緒論”外可分為兩個部分:第一部分“基礎理論篇”包括第1~4 章,介紹卷積神經網絡的基礎知識、基本部件、經典結構和模型壓縮等基礎理論內容;第二部分“實踐應用篇”包括第5~14 章,介紹深度卷積神經網絡自數據準備開始,到模型參數初始化、不同網絡部件的選擇、網絡配置、網絡模型訓練、不平衡數據處理,最終到模型集成等實踐應用技巧和經驗。另外,本書基本在每章結束均有對應小結,讀者在閱讀完每章內容后不妨掩卷回憶,看是否完全掌握了此章重點。對卷積神經網絡和深度學習感興趣的讀者可通讀全書,做到“理論結合實踐”;對希望迅速應用深度卷積神經網絡來解決實際問題的讀者,也可直接參考第二部分的有關內容,做到“有的放矢”。
筆者在本書寫作過程中得到很多同學和學術界、工業界朋友的支持與幫助,在此謹列出他們的姓名以致謝意(按姓氏拼音序):高斌斌、高如如、羅建豪、屈偉洋、謝晨偉、楊世才、張晨麟等。感謝高斌斌和羅建豪幫助起草本書第3.2.4節和第4章的有關內容。此外,特別感謝南京大學周志華教授、吳建鑫教授和澳大利亞阿德萊德大學沈春華教授等眾多師長在筆者求學科研過程中不厭其煩細致入微的指導、教育和關懷。同時,感謝電子工業出版社的劉皎老師為本書出版所做的努力。最后非常感謝筆者的父母,感謝他們的養育和一直以來的理解、體貼與照顧。寫就本書,筆者自認才疏學淺,僅略知皮毛,更兼時間和精力有限,書中錯謬之處在所難免,若蒙讀者不棄,還望不吝賜教,筆者將不勝感激!
魏秀參
先睹為快:重點章節試讀——模型集成方法
模型集成方法
集成學習 (ensemble learning) 是機器學習中的一類學習算法,指訓練多個學習器并將它們組合起來使用的方法。這類算法通常在實踐中能取得比單個學習器更好的預測結果,頗有“眾人拾柴火焰高”之意。特別是歷屆國際重量級學術競賽,如 ImageNet、KDD Cup以及許多 Kaggle 競賽的冠軍做法,或簡單或復雜但最后一步必然是集成學習。盡管深度網絡模型已經擁有強大的預測能力,但集成學習方法的使用仍然能起到“錦上添花”的作用。因此有必要了解并掌握一些深度模型方面的集成方法。一般來講,深度模型的集成多從“數據層面”和“模型層面”兩方面著手。
13.1 數據層面的集成方法
13.1.1 測試階段數據擴充
本書在第5章“數據擴充”中曾提到了訓練階段的若干數據擴充策略,實際上,這些擴充策略在模型測試階段同樣適用,諸如圖像多尺度(multi-scale)、隨機摳取(random crop)等。以隨機摳取為例,對某張測試圖像可得到 n 張隨機摳取圖像,測試階段只需用訓練好的深度網絡模型對 n 張圖像分別做預測,之后將預測的各類置信度平均作為該測試圖像最終預測結果即可。
13.1.2 “簡易集成”法
“簡易集成”法 (easy ensemble) [59]是 Liu 等人提出的針對不平衡樣本問題的一種集成學習解決方案。具體來說,“簡易集成”法對于樣本較多的類別采取降采樣(undersampling),每次采樣數依照樣本數目最少的類別而定,這樣可使每類取到的樣本數保持均等。采樣結束后,針對每次采樣得到的子數據集訓練模型,如此采樣、訓練反復進行多次。最后對測試數據的預測則從對訓練得到的若干個模型的結果取平均或投票獲得(有關“多模型集成方法”內容請參見13.2.2節)。總結來說,“簡易集成”法在模型集成的同時,還能緩解數據不平衡帶來的問題,可謂一舉兩得。
13.2 模型層面的集成方法
13.2.1 單模型集成
多層特征融合
多層特征融合 (multi-layer ensemble) 是針對單模型的一種模型層面集成方法。由于深度卷積神經網絡特征具有層次性的特點(參見3.1.3節內容),不同層特征富含的語義信息可以相互補充,在圖像語義分割[31]、細粒度圖像檢索[84]、基于視頻的表象性格分析[97]等任務中常見到多層特征融合策略的使用。一般地,在進行多層特征融合操作時可直接將不同層網絡特征級聯(concatenate)。而對于特征融合應選取哪些網絡層,一個實踐經驗是,最好使用靠近目標函數的幾層卷積特征,因為愈深層特征包含的高層語義性愈強,分辨能力也愈強;相反,網絡較淺層的特征較普適,用于特征融合很可能起不到作用,有時甚至會起到相反作用。
網絡“快照”集成法
我們知道,深度神經網絡模型復雜的解空間中存在非常多的局部最優解,但經典批處理隨機梯度下降法(mini-batch SGD)只能讓網絡模型收斂到其中一個局部最優解。網絡“快照”集成法(snapshot ensemble)[43]便利用了網絡解空間中的這些局部最優解來對單個網絡做模型集成。通過循環調整網絡學習率(cyclic learning rate schedule)可使網絡依次收斂到不同的局部最優解處,如圖13-1左圖所示。
具體而言,是將網絡學習率 η 設置為隨模型迭代輪數 t(iteration,即一次批處理隨機梯度下降稱為一個迭代輪數)改變的函數,即:

其中,η0 為初始學習率,一般設為 0.1 或 0.2。t 為模型迭代輪數(即 mini- batch 批處理訓練次數)。T 為模型總的批處理訓練次數。M 為學習率“循環退火”(cyclic annealing)次數,其對應了模型將收斂到的局部最優解個數。式13.1利用余弦函數 cos() 的循環性來循環更新網絡學習率,將學習率從 0.1 隨 t 的增長逐漸減緩到 0,之后將學習率重新放大從而跳出該局部最優解,自此開始下一循環的訓練,此循環結束后可收斂到新的局部最優解處,如此循環往復......直到 M 個循環結束。因式13.1中利用余弦函數循環更新網絡參數,所以這一過程被稱為“循環余弦退火”過程 (cyclic cosine annealing)[61]。
當經過“循環余弦退火”對學習率調整后,每個循環結束可使模型收斂到一個不同的局部最優解,若將收斂到不同局部最優解的模型保存便可得到 M 個處于不同收斂狀態的模型,如圖13-1右圖中紅色曲線所示。對于每個循環結束后保存的模型,我們稱之為模型“快照” (snapshot)。測試階段在做模型集成時,由于深度網絡模型在初始訓練階段未必擁有較優性能,因此一般挑選最后 m 個模型“快照”用于集成。關于對這些模型“快照”的集成策略可采用本章后面提到的“直接平均法”。
13.2.2 多模型集成
上一節我們介紹了基于單個網絡如何進行模型集成,本節向大家介紹如何產生多個不同網絡訓練結果和一些多模型的集成方法。
多模型生成策略
同一模型不同初始化。我們知道,由于神經網絡訓練機制基于隨機梯度下降法,故不同的網絡模型參數初始化會導致不同的網絡訓練結果。在實際使用中,特別是針對小樣本(limited examples)學習的場景,首先對同一模型進行不同初始化,之后將得到的網絡模型進行結果集成會大幅緩解隨機性,提升最終任務的預測結果。
同一模型不同訓練輪數。若網絡超參數設置得當,則深度模型隨著網絡訓練的進行會逐步趨于收斂,但不同訓練輪數的結果仍有不同,無法確定到底哪一輪訓練得到的模型最適用于測試數據。針對上述問題,一種簡單的解決方式是將最后幾輪訓練模型結果做集成,這樣一方面可降低隨機誤差,另一方面也避免了訓練輪數過多帶來的過擬合風險。這樣的操作被稱為“輪數集成”(epoch fusion 或 epoch ensemble)。具體使用實例可參考 ECCV 2016 舉辦的“基于視頻的表象性格分析”競賽冠軍做法[97]。
不同目標函數。目標函數(或稱損失函數)是整個網絡訓練的“指揮棒”,選擇不同的目標函數勢必使網絡學到不同的特征表示。以分類任務為例,可將“交叉熵損失函數”、“合頁損失函數”、“大間隔交叉熵損失函數”和“中心損失函數”作為目標函數分別訓練模型。在預測階段,既可以直接對不同模型預測結果做“置信度級別”(score level)的平均或投票,也可以做“特征級別”(feature level)的模型集成:將不同網絡得到的深度特征抽出后級聯作為最終特征,之后離線訓練淺層分類器(如支持向量機)完成預測任務。
不同網絡結構。也是一種有效的產生不同網絡模型結果的方式。操作時可在如 VGG 網絡、深度殘差網絡等不同網絡架構的網絡上訓練模型,最后對從不同架構網絡得到的結果做集成。
多模型集成方法
使用上一節提到的多模型生成策略或網絡“快照”集成法均可得到若干網絡訓練結果,除特征級別直接級聯訓練離線淺層學習器外,還可以在網絡預測結果級別對得到的若干網絡結果做集成。下面介紹四種最常用的多模型集成方法。假設共有 N 個模型待集成,對某測試樣本 x,其預測結果為 N 個 C 維向量(C 為數據的標記空間大小): s1,s2,...,sN。
直接平均法(simpleaveraging) 是最簡單有效的多模型集成方法,通過直接將不同模型產生的類別置信度進行平均得到最后預測結果:
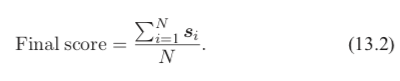
加權平均法(weighted averaging) 是在直接平均法基礎上加入權重來調節不同模型輸出的重要程度:

其中,ωi 對應第 i 個模型的權重,且須滿足:
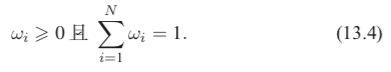
在實際使用時,關于權重 ωi 的取值可根據不同模型在驗證集上各自單獨的準確率而定,高準確率的模型權重較高,低準確率模型可設置稍小權重。
投票法(voting) 中最常用的是多數表決法 (majority voting),表決前需先將各自模型返回的預測置信度 si 轉化為預測類別,即最高置信度對應的類別標記ci ∈{1,2,...,C}作為該模型的預測結果。在多數表決法中,在得到樣本 x 的最終預測時,若某預測類別獲得一半以上模型投票,則該樣本預測結果為該類別;若對于該樣本無任何類別獲得一半以上投票,則拒絕做出預測(稱為“rejection option”)。
投票法中另一種常用方法是相對多數表決法 (plurality voting),與多數表決法會輸出“拒絕預測”不同的是,相對多數表決法一定會返回某個類別作為預測結果,因為相對多數表決是選取投票數最高的類別作為最后預測結果。
堆疊法(stacking) 又稱“二次集成法”,是一種高階的集成學習算法。在剛才的例子中,樣本 x 作為學習算法或網絡模型的輸入,si 作為第 i 個模型的類別置信度輸出,整個學習過程可記作一階學習過程 (first-level learning)。堆疊法則是以一階學習過程的輸出作為輸入開展二階學習過程 (second-level learning),有時也稱作“元學習” (meta learning)。拿剛才的例子來說,對于樣本 x,堆疊法的輸入是 N 個模型的預測置信度 [s1s2 . . . sN ],這些置信度可以級聯作為新的特征表示。之后基于這樣的“特征表示”訓練學習器將其映射到樣本原本的標記空間。注意,此時的學習器可為任何學習算法習得的模型,如支持向量機 (support vector machine)、隨機森林(random forest),當然也可以是神經網絡模型。不過在此需要指出的是,堆疊法有較大的過擬合風險。
13.3 小結
深度網絡的模型集成往往是提升網絡最終預測能力的一劑“強心針”,本章從“數據層面”和“模型層面”兩個方面介紹了一些深度網絡模型集成的方法。
數據層面常用的方法是數據擴充和“簡易集成”法,均操作簡單但效果顯著。
模型層面的模型集成方法可分為“單模型集成”和“多模型集成”。基于單一模型的集成方法可借助單個模型的多層特征的融合和網絡“快照”法進行。關于多模型集成,可通過不同參數初始化、不同訓練輪數和不同目標函數的設定產生多個網絡模型的訓練結果。最后使用平均法、投票法和堆疊法進行結果集成。
需要指出的是,第10章提到的隨機失活 (dropout) 實際上也是一種隱式的模型集成方法。有關隨機失活的具體內容請參考10.4節。更多關于集成學習的理論和算法請參考南京大學周志華的著作“Ensemble Methods: Foundations and Algorithms”[99]。
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103001 -
深度學習
+關注
關注
73文章
5557瀏覽量
122565
原文標題:周志華作序!高徒魏秀參新書《解析深度學習》試讀(評論贈書)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論