") 計(jì)算機(jī)架構(gòu)的新黃金十年開(kāi)啟
計(jì)算機(jī)架構(gòu)的新黃金十年開(kāi)啟
近幾年來(lái),不論是普通消費(fèi)者還是科研人員們都可以感受到兩種浪潮,一種是CPU速度的提升越來(lái)越不顯著了,我們說(shuō)CPU制造商又在“擠牙膏”;另一方面,在深度學(xué)習(xí)的刺激下,各個(gè)半導(dǎo)體巨頭和一群 AI 初創(chuàng)企業(yè)都開(kāi)始宣傳自己的 AI 芯片。我們仿佛看到一類(lèi)芯片逐漸走向慢車(chē)道,另一類(lèi)芯片則準(zhǔn)備搭臺(tái)唱戲、躍躍欲試。
這種柳暗花明的背后,顯示的正是計(jì)算機(jī)計(jì)算架構(gòu)的時(shí)代變革;新的方法、新的思維、新的目標(biāo)引領(lǐng)了新的浪潮。2017 年圖靈獎(jiǎng)的兩位得主 John L. Hennessy 和 David A. Patterson 就是這個(gè)新浪潮的見(jiàn)證者和引領(lǐng)者。近日他們?cè)?a target="_blank">ACM 通訊(Communications of the ACM)發(fā)表了一篇長(zhǎng)報(bào)告《A New Golden Age for Computer Architecture》,詳細(xì)描述了引發(fā)計(jì)算機(jī)架構(gòu)新時(shí)代到來(lái)的種種變化,他們也展望未來(lái)的十年將是計(jì)算機(jī)體系架構(gòu)領(lǐng)域的“新的黃金十年”。
ISCA 2018 ,2017 圖靈獎(jiǎng)?lì)C獎(jiǎng)現(xiàn)場(chǎng),John L. Hennessy(左) 和 David A. Patterson(右)與 Alan Turing 的半身像合影
2018年6月4日,我們回顧了自20世紀(jì)60年代以來(lái)計(jì)算機(jī)架構(gòu)的發(fā)展,并以此開(kāi)始了我們的圖靈講座。除了那個(gè)回顧,我們還在講座中介紹了當(dāng)前的難題和未來(lái)機(jī)遇。計(jì)算機(jī)體系結(jié)構(gòu)領(lǐng)域?qū)⒂瓉?lái)又一個(gè)黃金十年,就像20世紀(jì)80年代我們做研究那時(shí)一樣,新的架構(gòu)設(shè)計(jì)將會(huì)帶來(lái)更低的成本,更優(yōu)的能耗、安全和性能。
“不能銘記過(guò)去的人注定要重蹈覆轍”
——George Santayana,1905
軟件與硬件的對(duì)話(huà),是通過(guò)一種稱(chēng)為指令集的體系結(jié)構(gòu)進(jìn)行來(lái)的。在20世紀(jì)60年代初,IBM擁有四條互不兼容的計(jì)算機(jī)系列,分別針對(duì)小型企業(yè),大型企業(yè),科研單位和即時(shí)運(yùn)算,每個(gè)系列都有自己的指令集、軟件棧和I/O系統(tǒng)。
IBM的工程師們,也包括ACM圖靈獎(jiǎng)獲獎(jiǎng)?wù)逨red Brooks在內(nèi),希望能夠創(chuàng)建一套新的ISA,將這四套指令集有效統(tǒng)一起來(lái),為此他們需要一種可以讓低端的8位計(jì)算機(jī)和高端的64位計(jì)算機(jī)共享一套指令集的解決方案。
實(shí)際上,數(shù)據(jù)通路的加寬和縮小相對(duì)是比較容易的,當(dāng)時(shí)的工程師們面臨的最大挑戰(zhàn)是處理器中的控制器部分。受軟件編程的啟發(fā),計(jì)算機(jī)先驅(qū)人物、圖靈獎(jiǎng)獲得者M(jìn)aurice Wilkes提出了簡(jiǎn)化控制流程的思路,即將控制器部分定義為一個(gè)被稱(chēng)為“控制存儲(chǔ)器”的二維數(shù)組,可通過(guò)內(nèi)存實(shí)現(xiàn),比使用邏輯門(mén)的成本要低得多。數(shù)組的每一列對(duì)應(yīng)一條控制線(xiàn),每一行對(duì)應(yīng)一條微指令,寫(xiě)微指令的操作稱(chēng)為微編程,控制存儲(chǔ)器包含使用微指令編寫(xiě)的指令集解釋器,因此執(zhí)行一條傳統(tǒng)指令需要多個(gè)微指令完成。
下圖列出了IBM在1964年4月7日發(fā)布的新System/360系列計(jì)算機(jī)的指令集,四種型號(hào)之間的數(shù)據(jù)通路寬度相差8倍,內(nèi)存容量相差16倍,頻率相差近4倍,最終性能相差50倍。其中M65機(jī)型的控制存儲(chǔ)器容量最大,成本和售價(jià)也最昂貴,而最低端M30機(jī)型的控制存儲(chǔ)器容量最小,因此也需要有更多的微指令來(lái)執(zhí)行System/360的指令。
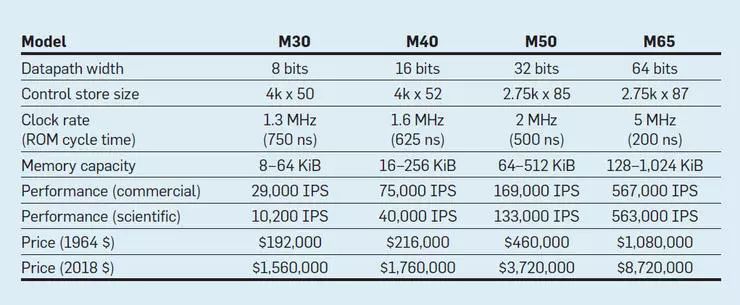
IBM將公司的未來(lái)押在了這套新指令集上,寄希望其能革新計(jì)算行業(yè),贏得未來(lái)。而最終IBM也如愿以?xún)敚晒χ髟琢诉@一市場(chǎng),并將其影響力延續(xù)至今,這些55年前機(jī)型的后代產(chǎn)品現(xiàn)在仍能為IBM帶來(lái)每年100億美元的收入。
現(xiàn)在看來(lái),盡管市場(chǎng)對(duì)技術(shù)問(wèn)題做出的評(píng)判還不夠完善,但由于硬件系統(tǒng)架構(gòu)與商用計(jì)算機(jī)之間的密切聯(lián)系,市場(chǎng)最終成為計(jì)算機(jī)架構(gòu)創(chuàng)新的是否成功的關(guān)鍵性因素,這些創(chuàng)新往往需要工程人員方面的大量投入。
集成電路,CISC,432,8086,IBM PC
當(dāng)計(jì)算機(jī)進(jìn)入集成電路時(shí)代,摩爾定律的力量可以使控制存儲(chǔ)器被設(shè)計(jì)的更大,而這反過(guò)來(lái)又催生了更復(fù)雜的指令集,如Digital Equipment公司于1977年發(fā)布的VAX-11/780機(jī)型,其控制存儲(chǔ)器容量就達(dá)到了5120指令字*96bit,而其前代型號(hào)僅為256指令字*56bit。
于此同時(shí),一些制造商開(kāi)始設(shè)計(jì)可記錄控制存儲(chǔ)器(WCS),放開(kāi)微編程功能以使客戶(hù)可以自行定制功能,其中最有名的機(jī)型是圖靈獎(jiǎng)得主Chuck Thacker和Butler Lampson 和他的同事在1973年為施樂(lè)公司Palo Alto研究中心開(kāi)發(fā)的Alto計(jì)算機(jī)。這是第一臺(tái)個(gè)人計(jì)算機(jī),配備有首款點(diǎn)陣顯示器和首個(gè)以太網(wǎng)局域網(wǎng),其控制器存儲(chǔ)在一個(gè)容量為4096指令字*32bit的WCS中。
另一邊,20世紀(jì)70年代的微處理器仍處于8位時(shí)代(如Intel的8080處理器),主要采用匯編語(yǔ)言編程,各家公司的設(shè)計(jì)師會(huì)不斷加入新的指令來(lái)超越競(jìng)爭(zhēng)對(duì)手,并通過(guò)匯編語(yǔ)言展示他們的優(yōu)勢(shì)。
戈登·摩爾認(rèn)為,Intel的下一代指令集將會(huì)伴隨Intel的一生,他聘請(qǐng)了大批聰明的計(jì)算機(jī)科學(xué)博士,并將他們送到波特蘭的一個(gè)新工廠(chǎng),以打造下一個(gè)偉大的指令集架構(gòu)。這個(gè)被Intel最初命名為8800的計(jì)算機(jī)架構(gòu)項(xiàng)目雄心勃勃,它具有32位尋址能力、面向?qū)ο蟮捏w系結(jié)構(gòu),可變位長(zhǎng)的指令以及用當(dāng)時(shí)最新編程語(yǔ)言Ada編寫(xiě)的操作系統(tǒng),是20世紀(jì)80年代最具挑戰(zhàn)性的一個(gè)項(xiàng)目。
可惜天不遂愿,這個(gè)項(xiàng)目在幾年間再三延期,迫使Intel在圣克拉拉啟動(dòng)了一項(xiàng)緊急更換計(jì)劃,要在1979年推出一款16位處理器,也就是后來(lái)的8086。Intel給了新團(tuán)隊(duì)52周時(shí)間來(lái)開(kāi)發(fā)新的指令集以及設(shè)計(jì)和構(gòu)建芯片。由于時(shí)間緊迫,這個(gè)團(tuán)隊(duì)實(shí)際上是把 8080 的 8 位寄存器和指令集擴(kuò)展成了 16 位,設(shè)計(jì)ISA部分僅僅花了10個(gè)人3周時(shí)間。最終8086如期完成,但在發(fā)布時(shí)卻沒(méi)引起什么關(guān)注。
這一次Intel很走運(yùn),當(dāng)時(shí)IBM正在開(kāi)發(fā)一款對(duì)位Apple II的個(gè)人計(jì)算機(jī),正需要16位處理器。IBM一度對(duì)Motorola 68000處理器很感興趣,它擁有類(lèi)似于IBM 360的指令集,但性能表現(xiàn)卻無(wú)法滿(mǎn)足IBM激進(jìn)的需求,故轉(zhuǎn)而使用Intel 8086的8位總線(xiàn)版。IBM于1981年8月12日宣布推出該機(jī)型,全球銷(xiāo)量高達(dá)1億臺(tái),為Intel這套指令集鋪墊了一個(gè)非常光明的未來(lái)。
Intel原本的8800項(xiàng)目更名了為iAPX-432,并最終在1981年推出,但它需要多塊芯片并且存在嚴(yán)重的性能問(wèn)題,最終于1986年終止。同樣在這一年,Intel推出了80386處理器,將8086指令集的寄存器從16位擴(kuò)展到了32位。戈登?摩爾的預(yù)言成為了現(xiàn)實(shí),Intel的下一代指令集確實(shí)一直存續(xù)下來(lái),但市場(chǎng)做出的選擇是臨危上馬的8086,而不是被寄予厚望的iAPX-432,這對(duì)摩托羅拉68000和iAPX-432的架構(gòu)師來(lái)講,都是個(gè)現(xiàn)實(shí)的教訓(xùn),市場(chǎng)永遠(yuǎn)是沒(méi)有耐心的。
從CISC到RISC
20世紀(jì)80年代初,人們開(kāi)始研究CISC(復(fù)雜指令集計(jì)算機(jī))控制存儲(chǔ)器中的大型微程序,而Unix系統(tǒng)的誕生則證明了可以使用高級(jí)語(yǔ)言來(lái)編寫(xiě)操作系統(tǒng),因此隨后問(wèn)題的關(guān)鍵從“編程者會(huì)使用什么匯編語(yǔ)言”變成了“編譯器會(huì)生成什么指令”,軟硬件接口的顯著改進(jìn)為架構(gòu)創(chuàng)新帶來(lái)了機(jī)會(huì)。
圖靈獎(jiǎng)得主John Cocke和他的同事為小型計(jì)算機(jī)開(kāi)發(fā)了更簡(jiǎn)單的指令集和編譯器,并將編譯器的目標(biāo)設(shè)定為“僅使用 IBM 360指令集中簡(jiǎn)單的寄存器到寄存器操作,只以簡(jiǎn)單的Load和Store操作訪(fǎng)問(wèn)內(nèi)存”。他們發(fā)現(xiàn),這樣簡(jiǎn)化的流程可以讓程序運(yùn)行速度快上3倍。Emer和Clark發(fā)現(xiàn),VAX指令中有20%的常用指令需要60%的微代碼(microcode),但僅占據(jù)0.2%的執(zhí)行時(shí)間。
David Patterson把在DEC一次學(xué)術(shù)休假投入到了研究減少VAX指令中的漏洞上。他認(rèn)為,如果處理器制造商想要設(shè)計(jì)更龐大的復(fù)雜指令集,就免不了需要一種修復(fù)微代碼漏洞的方法。Patterson就此問(wèn)題寫(xiě)了一篇論文,但《Computer》期刊卻拒絕刊登,審稿人認(rèn)為,使用如此復(fù)雜以至于需要修補(bǔ)的指令集來(lái)設(shè)計(jì)處理器是很糟糕的。
雖然現(xiàn)在來(lái)看,現(xiàn)代的CISC處理器確實(shí)包含微代碼修復(fù)機(jī)制,但當(dāng)時(shí)的這次拒稿卻讓人們懷疑復(fù)雜指令集在處理器方面的價(jià)值,這也啟發(fā)了他去開(kāi)發(fā)更簡(jiǎn)單的精簡(jiǎn)指令集,以及RISC(精簡(jiǎn)指令集計(jì)算機(jī))。
這些觀點(diǎn)的產(chǎn)生,以及由匯編語(yǔ)言向高級(jí)語(yǔ)言的轉(zhuǎn)變,為CISC向RISC的過(guò)渡創(chuàng)造了條件。首先,精簡(jiǎn)指令集是經(jīng)過(guò)簡(jiǎn)化的,其指令通常和微指令一樣簡(jiǎn)單,硬件可以直接執(zhí)行,因此無(wú)需微代碼解釋器;第二,之前用于微代碼解釋器的快速存儲(chǔ)器被用作了RISC的指令緩存;第三,基于Gregory Chaitin圖染色法的寄存器分配器,使編譯器能夠更簡(jiǎn)易、高效地使用寄存器,這指令集中那些寄存器到寄存器的操作有很大好處;最后,集成電路規(guī)模的發(fā)展,使20世紀(jì)80年代的單塊芯片足以包含完整的32位數(shù)據(jù)路徑以及相應(yīng)的指令和數(shù)據(jù)緩存。
下圖是加州大學(xué)伯克利分校1982年研發(fā)的RISC-I處理器和斯坦福大學(xué)1983年研發(fā)的MIPS處理器,兩顆芯片充分展示了RISC的優(yōu)勢(shì),并最終發(fā)表在1984年IEEE國(guó)際固態(tài)電路會(huì)議上。加州大學(xué)和斯坦福大小的研究生研發(fā)出了比行業(yè)內(nèi)現(xiàn)有產(chǎn)品更優(yōu)秀處理器,這是非常了不起的時(shí)刻。
這些由學(xué)術(shù)機(jī)構(gòu)開(kāi)發(fā)的芯片,激勵(lì)了許多企業(yè)開(kāi)始發(fā)力RISC處理器,并成為此后15年中發(fā)展最快的領(lǐng)域。其原因是處理器的性能公式:
時(shí)間/程序=操作數(shù)/程序*(時(shí)鐘周期)/指令*時(shí)間/(時(shí)鐘周期)
DEC公司的工程師后來(lái)表明,CISC處理器執(zhí)行每個(gè)程序的操作數(shù)大約為RISC處理器的75%(上式第一項(xiàng)),在使用類(lèi)似的技術(shù)時(shí),CISC處理器執(zhí)行每個(gè)指令要多消耗5到6個(gè)時(shí)鐘周期(上式第二項(xiàng)),使得RISC處理器的速度大約快了3倍。
這樣的公式在20世紀(jì)80年代還沒(méi)有進(jìn)入計(jì)算機(jī)體系結(jié)構(gòu)的書(shū)中,所以我們?cè)?989年編寫(xiě)了《Computer Architecture: A Quantitative Approach》一書(shū),使用測(cè)量和基準(zhǔn)測(cè)試來(lái)對(duì)計(jì)算機(jī)架構(gòu)進(jìn)行量化評(píng)估,而不是更多地依賴(lài)于架構(gòu)師的直覺(jué)和經(jīng)驗(yàn),使用的量化方法也受到了圖靈獎(jiǎng)得主Donald Knuth關(guān)于算法的書(shū)的啟發(fā)。
VLIW、EPIC、Itanium
指令集架構(gòu)的下一次創(chuàng)新試圖同時(shí)惠及RISC和CISC,即超長(zhǎng)指令字(VLIW)和顯式并行指令計(jì)算機(jī)(EPIC)的誕生。這兩項(xiàng)發(fā)明由Intel和惠普共同命名,在每條指令中使用捆綁在一起的多個(gè)獨(dú)立操作的寬指令。與RISC一樣,VLIW和EPIC的目的是將工作負(fù)載從硬件轉(zhuǎn)移到編譯器上,它們的擁護(hù)者認(rèn)為,如果用一條指令可以指定六個(gè)獨(dú)立的操作(兩次數(shù)據(jù)傳輸,兩次整數(shù)操作和兩次浮點(diǎn)操作),并且編譯器技術(shù)可以有效地將操作分配到六個(gè)指令槽,則硬件可以變得更簡(jiǎn)單。
Intel和惠普合作設(shè)計(jì)了一款基于EPIC理念的64位處理器Itanium(安騰),想用其取代32位x86處理器。Intel和惠普對(duì)Itanium抱有很高的期望,但實(shí)際情況卻與他們的預(yù)期并不相符,EPIC雖然適用于高度結(jié)構(gòu)化的浮點(diǎn)程序,但卻很難在可預(yù)測(cè)性較低的緩存丟失或難以預(yù)測(cè)分支的整型程序上實(shí)現(xiàn)高性能。
Donald Knuth后來(lái)指出,Itanium的設(shè)想非常棒,但事實(shí)證明滿(mǎn)足這種設(shè)想的編譯器基本上不可能寫(xiě)出來(lái)。開(kāi)發(fā)人員注意到Itanium的延遲和性能表現(xiàn)不佳,并借鑒泰坦尼克號(hào)事件重新將其命名為“Itanic”。不過(guò)正如前面所提到的,市場(chǎng)永遠(yuǎn)是沒(méi)有耐心的,最終64位的x86-64成為了繼承者,沒(méi)有輪到Itanium。
不過(guò)一個(gè)好消息是,VLIW仍然小范圍應(yīng)用于數(shù)字信號(hào)處理等對(duì)分支預(yù)測(cè)和緩存要求不高的領(lǐng)域。
RISC vs. CISC,PC和后PC時(shí)代的宿命對(duì)決
Intel和AMD依靠500人的設(shè)計(jì)團(tuán)隊(duì)和卓越的半導(dǎo)體技術(shù)來(lái)縮小x86和RISC之間的性能差距,而受到精簡(jiǎn)指令相對(duì)于復(fù)雜指令性能優(yōu)勢(shì)的啟發(fā),Intel和AMD將RISC微指令的執(zhí)行流程化,使指令解碼器在運(yùn)行中將復(fù)雜的x86指令轉(zhuǎn)換成類(lèi)似RISC的內(nèi)部微指令,從而讓x86處理器可以吸收RISC在性能分離指令、數(shù)據(jù)緩存、芯片二級(jí)緩存、深度流水線(xiàn)以及同時(shí)獲取和執(zhí)行多個(gè)指令等許多優(yōu)秀的設(shè)計(jì)。在2011年P(guān)C時(shí)代的巔峰時(shí)期,Intel和AMD每年大約出貨3.5億顆x86處理器。PC行業(yè)的高產(chǎn)量和低利潤(rùn)率也意味著價(jià)格低于RISC計(jì)算機(jī)。
在Unix市場(chǎng)中,軟件供應(yīng)商會(huì)為不同的復(fù)雜指令集(Alpha、HP-PA、MIPS、Power和SPARC)提供不同的軟件版本,而PC市場(chǎng)上絕對(duì)主流的指令集只有一套,軟件開(kāi)發(fā)人員只需兼容x86指令集即可。全球每年出貨數(shù)億臺(tái)PC,軟件就成為了一個(gè)巨大的市場(chǎng)。更大的軟件基礎(chǔ)、相似的性能和更低的價(jià)格使得x86處理器在2000年之前同時(shí)統(tǒng)治了臺(tái)式機(jī)和小型服務(wù)器市場(chǎng)。
蘋(píng)果公司在2007年推出了iPhone,開(kāi)創(chuàng)了后PC時(shí)代。智能手機(jī)公司不再購(gòu)買(mǎi)處理器,而是使用其他公司的設(shè)計(jì)來(lái)構(gòu)建自己的SoC。移動(dòng)設(shè)備設(shè)計(jì)人員需要對(duì)芯片面積和能效以及性能進(jìn)行綜合評(píng)估,CISC處理器在這一點(diǎn)上處于劣勢(shì)。此外,物聯(lián)網(wǎng)的到來(lái)需要海量的處理器,更加需要在芯片尺寸、功率、成本和性能上做權(quán)衡。這種趨勢(shì)增加了設(shè)計(jì)時(shí)間和成本的重要性,進(jìn)一步使CISC處理器處于不利地位。在今天這個(gè)“后PC時(shí)代”,x86處理器的出貨量自2011年達(dá)到峰值以來(lái),每年下降近10%,而RISC處理器的出貨量則飆升至200億。如今,99%的32位和64位處理器都是RISC處理器。
總結(jié)這些歷史,可以說(shuō)市場(chǎng)已經(jīng)解決了RISC和CISC宿命之爭(zhēng)。CISC贏得了PC時(shí)代的后期階段,但RISC正在后PC時(shí)代占據(jù)主導(dǎo)。復(fù)雜指令集領(lǐng)域已經(jīng)幾十年沒(méi)有新的指令集出現(xiàn)了,對(duì)于今天的通用處理器來(lái)說(shuō),最佳的選擇仍然是精簡(jiǎn)指令集。
處理器架構(gòu)當(dāng)前面臨的挑戰(zhàn)
“如果一個(gè)問(wèn)題無(wú)解,那它可能不是一個(gè)問(wèn)題,而是一個(gè)事實(shí),我們不需要解決,而是隨著時(shí)間的推移來(lái)處理。”
——Shimon Peres
雖然前面的部分聚焦在指令集架構(gòu)的設(shè)計(jì)上,但大部分計(jì)算機(jī)架構(gòu)師并不設(shè)計(jì)新的指令集,而是利用當(dāng)前的實(shí)現(xiàn)技術(shù)來(lái)實(shí)現(xiàn)現(xiàn)有的ISA。自20世紀(jì)70年代后期以來(lái),選擇的技術(shù)一直是基于MOS(金屬氧化物半導(dǎo)體)的集成電路,首先是 nMOS(n型金屬氧化物半導(dǎo)體),然后是CMOS(互補(bǔ)金屬氧化物半導(dǎo)體)。
戈登·摩爾在1965年預(yù)測(cè),集成電路的晶體管密度會(huì)每年翻一番,1975年又改為每?jī)赡攴环@一預(yù)測(cè)最終被稱(chēng)為摩爾定律。在這一預(yù)測(cè)中,晶體管密度呈二次增長(zhǎng),驚人的進(jìn)化速度使架構(gòu)師可以用更多晶體管來(lái)提高性能。
摩爾定律和登納德縮放定律的失效
如圖2所示,摩爾定律已經(jīng)持續(xù)了幾十年,但它在2000年左右開(kāi)始放緩,到了 2018 年,實(shí)際結(jié)果與摩爾定律的預(yù)測(cè)相差了15倍,但摩爾在2003年做的判斷已不可避免(可參考GE Moore 的《No exponential is forever: But 'forever' can be delayed!》論文)。基于當(dāng)前的情況,這一差距還將持續(xù)增大,因?yàn)镃MOS已經(jīng)接近極限。
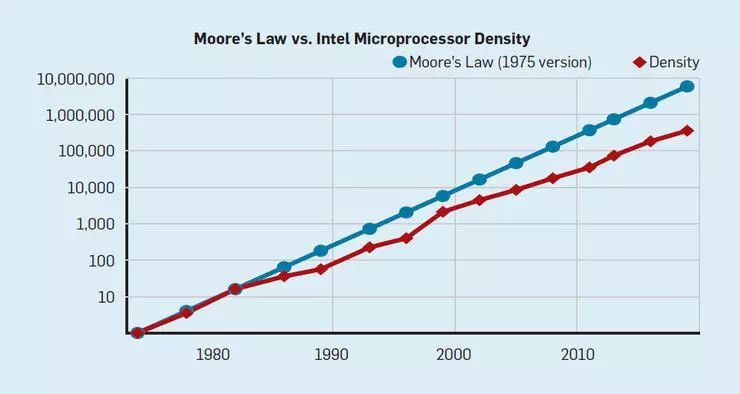
圖2 單個(gè)英特爾微處理器上的晶體管數(shù)量 vs. 摩爾定律
與摩爾定律相伴的是由羅伯特·登納德(Robert Dennard)預(yù)測(cè)的登納德縮放定律(Dennard scaling;又稱(chēng)作MOSFET縮放定律)。Robert Dennard 在 1974 年提出,晶體管不斷變小,但芯片的功率密度不變。隨著晶體管密度的增加,每個(gè)晶體管的能耗將降低,因此硅芯片上每平方毫米上的能耗幾乎保持恒定。由于每平方毫米硅芯片的計(jì)算能力隨著技術(shù)的迭代而不斷增強(qiáng),計(jì)算機(jī)將變得更加節(jié)能。不過(guò),登納德縮放定律從 2007 年開(kāi)始大幅放緩,大概在2012 年接近失效(見(jiàn)圖 3)。
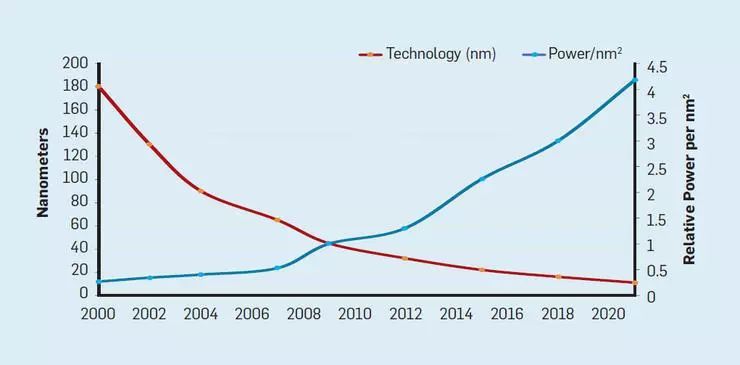
圖3每個(gè)芯片上的晶體管及每平方毫米的功率
1986 年至 2002 年間,利用指令級(jí)并行(ILP)是提高架構(gòu)性能的主要方法,伴隨著晶體管速度的提高,其性能每年能提高約50%。登納德縮放定律的終結(jié)意味著架構(gòu)師必須找到更有高效的方法利用并行性。
要理解增加ILP 所帶來(lái)高效率,可以看一看當(dāng)前的處理器核心比如ARM、英特爾、AMD。假設(shè)該芯片有15級(jí)流水線(xiàn)(管線(xiàn)),每個(gè)時(shí)鐘周期可以發(fā)送 4 條指令,那么它在任何時(shí)刻都有多達(dá)60條指令,包括大約15個(gè)分支,它們占執(zhí)行指令的大約25%。為了能夠充分利用流水線(xiàn),需要預(yù)測(cè)分支,并根據(jù)推測(cè)將代碼放入流水線(xiàn)以便執(zhí)行。推測(cè)的使用同時(shí)是 ILP高性能和低能效的源頭。如果分支預(yù)測(cè)達(dá)到完美,推測(cè)就能提高 ILP 性能,但能耗會(huì)增加一些(也可能節(jié)約能耗),但如果分支預(yù)測(cè)出現(xiàn)失誤,處理器就必須放棄錯(cuò)誤的推測(cè)指令,計(jì)算所耗能量就會(huì)被浪費(fèi)。處理器的內(nèi)部狀態(tài)也必須恢復(fù)到錯(cuò)誤預(yù)測(cè)分支之前的狀態(tài),這將消耗額外的能量和時(shí)間。
要理解這種設(shè)計(jì)的挑戰(zhàn)性,想一想正確預(yù)測(cè)15個(gè)分支就可知道其中的難度。如果處理器架構(gòu)想把性能的浪費(fèi)控制在10%以?xún)?nèi),那么它必須在 99.3%的時(shí)間里正確預(yù)測(cè)每個(gè)分支。很少有通用程序能夠如此準(zhǔn)確地預(yù)測(cè)。
要理解性能浪費(fèi)疊加的結(jié)果,可以參見(jiàn)圖4中,圖中顯示了有效執(zhí)行的指令,但由于處理器推測(cè)錯(cuò)誤而被浪費(fèi)。對(duì)英特爾酷睿 i7 基準(zhǔn)測(cè)試上,19%的指令都被浪費(fèi)了,但能量的浪費(fèi)情況更加嚴(yán)重,因?yàn)樘幚砥鞅仨毷褂妙~外的能量才能恢復(fù)到推測(cè)失誤前的狀態(tài)。這樣的測(cè)試導(dǎo)致許多人得出結(jié)論,架構(gòu)師需要一種不同的方法來(lái)實(shí)現(xiàn)性能改進(jìn)。于是迎來(lái)了多核時(shí)代的誕生。
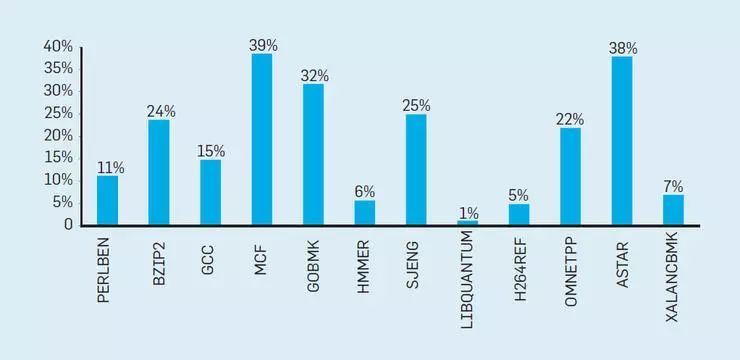
圖4 不同的SPEC整型數(shù)基準(zhǔn)測(cè)試,英特爾酷睿 i7 浪費(fèi)的指令占完成指令總數(shù)的百分比
多核將識(shí)別并行性和決定如何利用并行性的任務(wù)轉(zhuǎn)移給程序員和編程語(yǔ)言。多核并未解決節(jié)能的挑戰(zhàn),而這種挑戰(zhàn)因登納德縮放定律終結(jié)更加嚴(yán)峻。每個(gè)活躍的核都會(huì)消耗能量,無(wú)論其對(duì)計(jì)算是否有有效貢獻(xiàn)。一個(gè)主要的障礙可以用阿姆達(dá)爾定律(Amdahl's Law)表述,該定理認(rèn)為,在并行計(jì)算中用多處理器的應(yīng)用加速受限于程序所需的串行時(shí)間百分比。這一定律的重要性參見(jiàn)圖5,與單核相比,多達(dá)64個(gè)核執(zhí)行應(yīng)用程序速度的差別,假設(shè)串行執(zhí)行的不同部分只有一個(gè)處理器處于活動(dòng)狀態(tài)。例如,如果只有1%的時(shí)間是串行的,那么 64核的配置可加速大約35倍,當(dāng)然能量也與64個(gè)處理器成正比,大約有45% 的能量被浪費(fèi)。
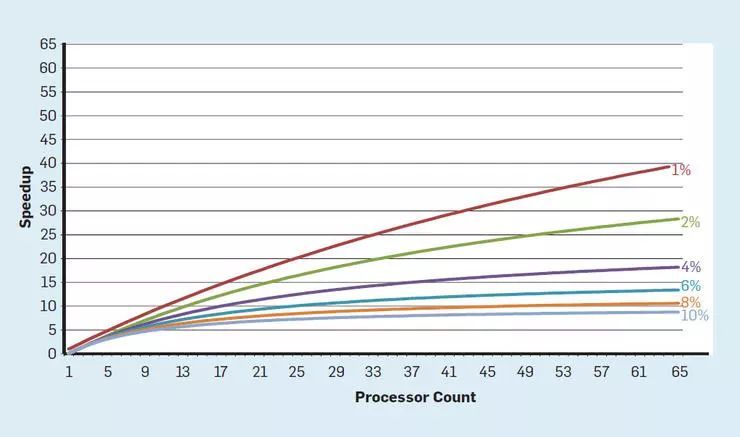
圖5 阿姆達(dá)爾定律對(duì)程序加速的影響
真實(shí)的程序當(dāng)然會(huì)更加復(fù)雜,部分組件允許在給定時(shí)刻使用不同數(shù)量的處理器。然而,需要定期性通信和同步意味著大部分應(yīng)用僅可高效使用一部分處理器。盡管阿姆達(dá)爾定律已經(jīng)出現(xiàn) 50 多年了,這仍然是一個(gè)很大的困難。
隨著登納德縮放定律的終結(jié),芯片內(nèi)核數(shù)量的增加意味著能耗也隨之增加。不幸的是,進(jìn)入處理器的電能有一部分會(huì)轉(zhuǎn)化為熱能,因此多核處理器受限于熱耗散功率(TDP),即封裝和冷卻系統(tǒng)在最大負(fù)載時(shí)的驅(qū)散熱量的最大限度。盡管一些高端數(shù)據(jù)中心可能使用更先進(jìn)的封裝和冷卻技術(shù),但沒(méi)有一個(gè)計(jì)算機(jī)用戶(hù)想要在自己桌子上放置小型熱交換器,或者為手機(jī)增加散熱器。TDP 的限制性直接導(dǎo)致了暗硅時(shí)代,也就是處理器通過(guò)降低時(shí)鐘頻率或關(guān)閉空閑內(nèi)核來(lái)防止處理器過(guò)熱。這種方法的另一種解釋是:一些芯片可將其寶貴的能量從空閑內(nèi)核轉(zhuǎn)移到活躍內(nèi)核。
登納德縮放定律的結(jié)束,摩爾定律放緩以及阿姆達(dá)爾定律正當(dāng)其時(shí),意味著低效性將每年的性能改進(jìn)限制在幾個(gè)百分點(diǎn)(如6所示)。想獲得高的性能改進(jìn)(像 20 世紀(jì)八九十年代那樣)需要新的架構(gòu)方法,新方法應(yīng)能更加高效地利用集成電路。接下來(lái)我們將討論現(xiàn)代計(jì)算機(jī)的另一個(gè)主要缺陷——計(jì)算機(jī)安全的支持以及缺乏,之后再繼續(xù)探討有效利用集成電路的新方法。
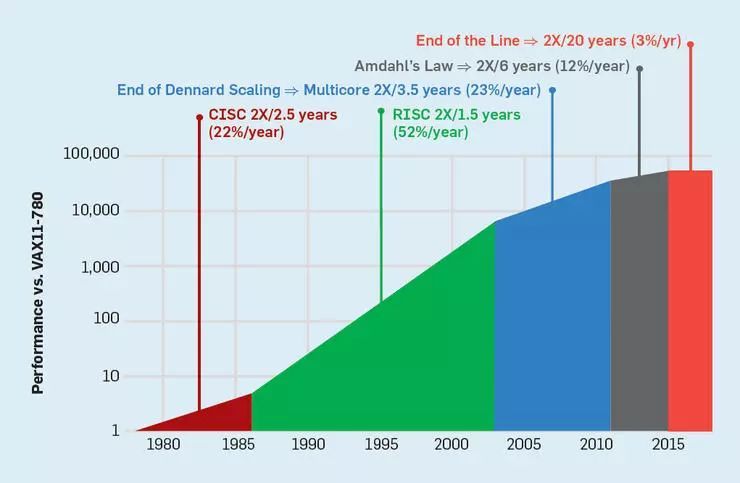
圖6 計(jì)算機(jī)性能的提升(SPECintCPU)
被忽略的計(jì)算機(jī)安全
20 世紀(jì) 70 年代,處理器架構(gòu)師主要專(zhuān)注于計(jì)算機(jī)安全,涉及保護(hù)環(huán)和功能安全。架構(gòu)師們意識(shí)到,大部分漏洞都存在于軟件中,但他們認(rèn)為架構(gòu)能會(huì)有所幫助。這些功能大部分未被操作系統(tǒng)使用,這些操作系統(tǒng)有意專(zhuān)注于所謂的良性環(huán)境(如個(gè)人電腦),并且這些功能涉及大量消耗,因此被淘汰。在軟件社區(qū)中,很多人認(rèn)為正式驗(yàn)證技術(shù)如微內(nèi)核等技術(shù)會(huì)為構(gòu)建高度安全的軟件提供有效保障。不幸的是,我們的軟件系統(tǒng)規(guī)模和性能驅(qū)動(dòng)器意味著此類(lèi)技術(shù)無(wú)法跟上處理器性能。結(jié)果就是大型軟件系統(tǒng)仍然有很多安全漏洞,且由于海量在線(xiàn)個(gè)人信息和云計(jì)算的使用,其影響被放大。
登納德縮放定律的終結(jié)意味著架構(gòu)師必須找到利用并行化的更高效方式。
架構(gòu)師們和其他人很晚才意識(shí)到安全的重要性,但他們已經(jīng)開(kāi)始對(duì)虛擬機(jī)和加密提供硬件支持。不幸的是,推測(cè)給許多處理器帶來(lái)了未知但明顯的安全缺陷。特別是,Meltdown和Spectre安全漏洞導(dǎo)致新漏洞利用位體系結(jié)構(gòu)中的漏洞,使受保護(hù)信息較快地遭到泄露,這兩種漏洞都使用了旁路攻擊。2018 年,研究者展示了在攻擊者不將代碼加載到目標(biāo)處理器的情況下,如何利用 Spectre 變體導(dǎo)致網(wǎng)絡(luò)信息泄露。盡管這次名為NetSpectre的攻擊泄露信息速度較慢,但它會(huì)使同一局域網(wǎng)(或云中同一集群)中的所有機(jī)器都受到攻擊,這會(huì)產(chǎn)生許多新的漏洞。還有兩個(gè)被報(bào)告的漏洞存在于虛擬機(jī)架構(gòu),其中一個(gè)叫Foreshadow,會(huì)影響專(zhuān)門(mén)保護(hù)高風(fēng)險(xiǎn)數(shù)據(jù)(如加密密鑰)的英特爾SGX 安全機(jī)制。現(xiàn)在,每個(gè)月都會(huì)發(fā)現(xiàn)新的漏洞。
旁路攻擊并非新鮮事,但在最早期的大多數(shù)情況,軟件漏洞是攻擊成功的關(guān)鍵。但在Meltdown、Spectre 等攻擊中,硬件的缺陷導(dǎo)致受保護(hù)信息泄露。處理器架構(gòu)師如何定義什么是正確的ISA是一個(gè)源頭的難題,因?yàn)闃?biāo)準(zhǔn)中并未說(shuō)明執(zhí)行指令序列的性能影響,而僅僅涉及 ISA-visible 執(zhí)行架構(gòu)狀態(tài)。架構(gòu)師需要重新思考ISA正確實(shí)現(xiàn)的定義,以避免類(lèi)似的安全漏洞。與此同時(shí),他們還應(yīng)該重新思考對(duì)計(jì)算機(jī)安全關(guān)注的側(cè)重點(diǎn),以及架構(gòu)師如何與軟件設(shè)計(jì)師一起實(shí)現(xiàn)更加安全的系統(tǒng)。架構(gòu)師(以及所有人)都過(guò)于依賴(lài)信息系統(tǒng),以至于對(duì)安全的重視程度不如對(duì)一流設(shè)計(jì)的關(guān)注。
計(jì)算機(jī)架構(gòu)的未來(lái)機(jī)遇
「我們面前有一些令人目瞪口呆的機(jī)會(huì),不過(guò)它們把自己偽裝成了看似無(wú)法解決的困難」。 -John Gardner
不論是對(duì)于 ILP 的技術(shù)或者多核心處理器,由于為通用計(jì)算設(shè)計(jì)的微處理器注定了效率較低,再加上Dennard Scaling定律和摩爾定律走向終結(jié),所以在我們看來(lái),處理器架構(gòu)師和設(shè)計(jì)師們很有可能再也無(wú)法讓通用處理器的性能以之前那樣的速度繼續(xù)大幅提高。但是我們?nèi)匀恍枰朕k法繼續(xù)提升硬件性能、為未來(lái)的新的軟件功能留下發(fā)展空間,我們就必須仔細(xì)思考這個(gè)問(wèn)題:有沒(méi)有其他的有潛力的方案?
比較明顯的方案有兩種,以及把這兩種方案合并在一起的話(huà)我們還可以得到第三種方案。
執(zhí)行性能優(yōu)化
第一種方案是,現(xiàn)代軟件的編寫(xiě)中大量使用了高級(jí)語(yǔ)言,其中有動(dòng)態(tài)類(lèi)型和動(dòng)態(tài)存儲(chǔ)管理。然而不幸的是,這些語(yǔ)言的編譯和執(zhí)行是非常低效的。Leiserson 等人用矩陣乘法的小例子說(shuō)明了這種低效性。
Python 是一種當(dāng)前火熱的編程語(yǔ)言,也是一種典型的高級(jí)、動(dòng)態(tài)類(lèi)型語(yǔ)言。如下面圖 7,僅僅是把本來(lái)用 Python 編寫(xiě)的程序用 C 語(yǔ)言重新寫(xiě)一遍,就可以把程序的性能提高 47 倍。在多核心處理器上并行運(yùn)行多個(gè)循環(huán)可以繼續(xù)得到大約 7 倍的性能提升。優(yōu)化程序的存儲(chǔ)布局,讓程序使用處理器中的緩存(而不是外部安裝的內(nèi)存)可以提升 20 倍性能,最后,如果加入拓展的計(jì)算硬件,用能夠在每個(gè)指令周期內(nèi)計(jì)算 16 次 32 位運(yùn)算的單指令多數(shù)據(jù)并行(SIMD)計(jì)算單元進(jìn)行運(yùn)算的話(huà),我們還可以再把性能提高9倍。把以上這些改進(jìn)全部用起來(lái)的話(huà),
一個(gè)運(yùn)行在英特爾多核處理器上的、經(jīng)過(guò)高度優(yōu)化過(guò)的程序可以比最初的 Python 版本快超過(guò) 6 萬(wàn)倍。
這當(dāng)然只是一個(gè)很小的例子,一般的程序員可能自己就會(huì)使用一個(gè)有優(yōu)化作用的庫(kù)來(lái)享受這種提升。雖然這個(gè)例子把性能的變化展現(xiàn)得很夸張,但是在許許多多的程序中,提升 100 倍或者 1000 倍的性能還是完全可以實(shí)現(xiàn)的。
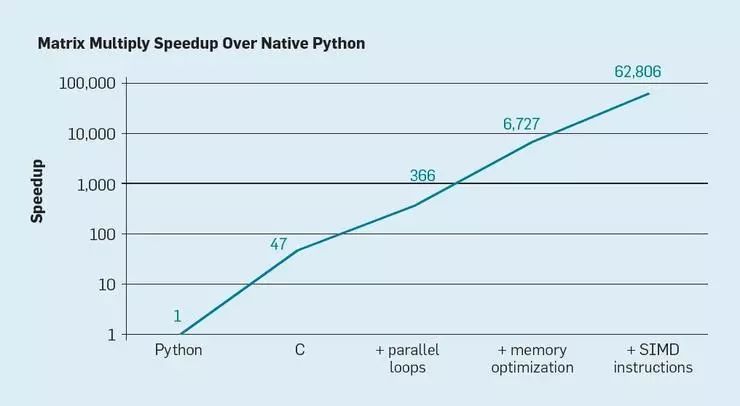
圖 7
有一個(gè)有趣的研究方向是,考慮其中的一些性能差距是否可以用更好的編譯器技術(shù)來(lái)補(bǔ)上,當(dāng)然了也可以同時(shí)搭配一些計(jì)算架構(gòu)的改進(jìn)。雖然高效的語(yǔ)言翻譯、以及高效實(shí)現(xiàn) Python 這類(lèi)的高級(jí)腳本語(yǔ)言確實(shí)有很大困難,但潛在的性能收益也是巨大的。即便我們只實(shí)現(xiàn)了這些潛力中的 25% 就已經(jīng)可以讓 Python 程序的運(yùn)行速度提高數(shù)十倍甚至一百倍。這個(gè)簡(jiǎn)單的例子就清晰地展示了關(guān)注軟件工程師的生產(chǎn)力的現(xiàn)代編程語(yǔ)言和關(guān)注程序性能表現(xiàn)的傳統(tǒng)方法之間的巨大鴻溝。
設(shè)計(jì)專(zhuān)用硬件
領(lǐng)域?qū)S玫挠?jì)算架構(gòu)。除了改進(jìn)軟件執(zhí)行效率的第一種方案之外,第二種方案更加以硬件為中心,那就是為某個(gè)特定的領(lǐng)域問(wèn)題設(shè)計(jì)專(zhuān)用的計(jì)算架構(gòu),從而為這些問(wèn)題帶來(lái)顯著的性能(和效率)提升。這種方案的名字,DSA,「domain-specific architectures」,描述的就是這種為特定的領(lǐng)域問(wèn)題而專(zhuān)門(mén)定制設(shè)計(jì)的處理器,它們可編程,同樣也是圖靈完備的,但只適用于特定的某一類(lèi)問(wèn)題。從這個(gè)角度來(lái)講,它們和專(zhuān)用集成電路 ASIC 之間也有所不同,ASIC 只執(zhí)行單一的功能,對(duì)應(yīng)的程序代碼幾乎從不變化。DSA 則常被稱(chēng)為加速器,相比于把程序的所有功能都在為通用計(jì)算的 CPU 上執(zhí)行,DSA 可以讓程序中的一部分計(jì)算運(yùn)行得更快。更重要的是,DSA 可以讓一些程序得到明顯更高的性能,因?yàn)樗鼈兙褪菫榱速N近這些程序的計(jì)算需求而設(shè)計(jì)的。圖像處理單元 GPU、深度學(xué)習(xí)中使用的神經(jīng)網(wǎng)絡(luò)芯片、軟件定義網(wǎng)絡(luò)處理器 SDN 都是典型的例子。DSA 可以達(dá)到高得多的性能表現(xiàn)和高得多的能量效率,是由于以下四個(gè)原因:
第一點(diǎn),也是最重要的一點(diǎn),DSA 可以為具體的領(lǐng)域問(wèn)題采用更為高效的并行計(jì)算設(shè)計(jì)。比如,單指令多數(shù)據(jù)并行(SIMD)就比多指令多數(shù)據(jù)并行(MIMD)的效率高得多,因?yàn)樗恍枰@取一條指令流就可以讓處理單元在鎖定步驟內(nèi)執(zhí)行運(yùn)算。SIMD 的靈活性固然不如 MIMD 高,但是它很符合許多 DSA 的需求。DSA 中還有可能使用 VLIW 方案來(lái)實(shí)現(xiàn) ILP,而不是使用更復(fù)雜的亂序執(zhí)行機(jī)制。正如前面提到的,VLIW 無(wú)力與通用計(jì)算代碼競(jìng)爭(zhēng),但是在有限制條件的領(lǐng)域中它就可以高效得多,因?yàn)樗目刂茩C(jī)制簡(jiǎn)單得多。尤其是,多數(shù)的高端通用計(jì)算處理器都是亂序執(zhí)行的超標(biāo)量處理器,對(duì)于指令初始化和指令完成都需要復(fù)雜的控制邏輯。相比之下,VLIW 在編譯的時(shí)候就已經(jīng)執(zhí)行好了必需的分析和流程規(guī)劃,在顯示并行的程序中就可以起到很好的效果。
第二,DSA 可以更高效地利用不同層次的存儲(chǔ)器。Horowitz 指出,讀寫(xiě)存儲(chǔ)器的成本已經(jīng)變得高于數(shù)學(xué)運(yùn)算的成本了。比如,從一個(gè) 32KB 容量的緩存里讀取一個(gè)塊需要消耗的能量差不多要比執(zhí)行一次 32 位整型加法高 200 倍。正因?yàn)檫@種差別的存在,想要達(dá)到高的能源效率,優(yōu)化存儲(chǔ)器的讀寫(xiě)就至關(guān)重要。通用計(jì)算處理器執(zhí)行代碼的方式是,一般來(lái)說(shuō)存儲(chǔ)器的讀寫(xiě)都具有時(shí)間和空間上的局部性,但是其他狀況是在程序編譯時(shí)很難預(yù)測(cè)的。所以 CPU 會(huì)配合使用多級(jí)緩存,以便增加存儲(chǔ)器帶寬,同時(shí)緩解相對(duì)較慢的片外存儲(chǔ)(內(nèi)存,DRAM)的高延遲問(wèn)題。CPU 消耗的電能里,常常有一半都是花在了這些多級(jí)緩存上面,不過(guò)它們的作用也就是避免了大多數(shù)對(duì)片外 DRAM 的訪(fǎng)問(wèn),要知道,讀寫(xiě) DRAM 消耗的能源要比讀寫(xiě)最后一級(jí)緩存還要高差不多 10 倍。
緩存的缺點(diǎn)會(huì)在這兩種情況下暴露出來(lái):
當(dāng)數(shù)據(jù)集非常大的時(shí)候,緩存的時(shí)間和空間局部性都很差;
當(dāng)緩存表現(xiàn)得非常好的時(shí)候,也就是說(shuō)局部性非常高的時(shí)候,這其實(shí)說(shuō)明大多數(shù)緩存都是空閑的。
在那些存儲(chǔ)器的讀寫(xiě)模式有良好定義、在編譯時(shí)就可以發(fā)現(xiàn)的應(yīng)用中(典型的 DSL 都符合),程序員和程序的編譯器都可以?xún)?yōu)化存儲(chǔ)器的使用,效果要比動(dòng)態(tài)分配緩存更好。所以 DSA 通常會(huì)使用一個(gè)層次式的存儲(chǔ)器,它的操作也是由軟件明確定義的,這和向量處理器的運(yùn)行方式很類(lèi)似。對(duì)于適合的應(yīng)用,用戶(hù)控制的存儲(chǔ)器消耗的能源要比緩存低多了。
第三,在適當(dāng)?shù)臅r(shí)候,DSA 可以用更低的精度做運(yùn)算。通用計(jì)算 CPU 一般支持 32 位和 64 位整型以及浮點(diǎn)數(shù)據(jù)運(yùn)算。不過(guò)對(duì)于機(jī)器學(xué)習(xí)和圖形領(lǐng)域的許多應(yīng)用來(lái)說(shuō),這樣的精度都高于實(shí)際需求了。比如在深度神經(jīng)網(wǎng)絡(luò)中,推理任務(wù)經(jīng)常使用 4 位、8 位或者 16 位的整型,以獲取更高的數(shù)據(jù)吞吐量、更高的計(jì)算吞吐量。類(lèi)似地,在深度神經(jīng)網(wǎng)絡(luò)的訓(xùn)練中需要使用浮點(diǎn)類(lèi)型,32 位就已經(jīng)夠用了,16 位很多時(shí)候都可以。
第四,如果程序是用領(lǐng)域?qū)S谜Z(yǔ)言(DSL)編寫(xiě)的,由于語(yǔ)言本身對(duì)并行化有更好的支持,DSA 也就可以從中受益。這改進(jìn)了存儲(chǔ)器讀取的結(jié)構(gòu)和表示,也可以更容易地把應(yīng)用程序映射到一個(gè)領(lǐng)域?qū)S玫奶幚砥魃先ァ?/p>
領(lǐng)域?qū)S谜Z(yǔ)言
DSA 需要把編程語(yǔ)言中的高級(jí)操作對(duì)應(yīng)到硬件架構(gòu)上去,但是想要從 Python、Java、C、Fortan 這樣的為通用型計(jì)算設(shè)計(jì)的語(yǔ)言中提取這樣的結(jié)構(gòu)和信息實(shí)在是太難了。領(lǐng)域?qū)S谜Z(yǔ)言(DSL)讓這個(gè)過(guò)程變得可以實(shí)現(xiàn),而且也讓我們有機(jī)會(huì)高效地為 DSA 編程。比如,DSL 中可以定義顯式的向量、稠密矩陣、稀疏矩陣操作,這樣 DSL 的編譯器就可以高效地把這些操作映射到處理器中。許多語(yǔ)言屬于 DSL,比如矩陣運(yùn)算語(yǔ)言 Matlab,深度神經(jīng)網(wǎng)絡(luò)編程用的數(shù)據(jù)流語(yǔ)言 TensorFlow,DSN 編程語(yǔ)言 P4,以及描述圖像處理中高級(jí)變換操作的 Halide。
使用 DSL 的時(shí)候也有一個(gè)挑戰(zhàn),就是如何讓硬件架構(gòu)設(shè)計(jì)保持足夠的獨(dú)立性,這樣在一種 DSL 中編寫(xiě)的軟件可以遷移到不同的硬件架構(gòu),同時(shí)在把軟件映射到下方的 DSA 的時(shí)候還能過(guò)保持足夠高的效率。比如,TensorFlow 中的 XLA 系統(tǒng)可以把編寫(xiě)的程序翻譯成使用不同處理器的版本,在英偉達(dá) GPU 和谷歌 TPU 上都可以運(yùn)行。在 DSA 之間平衡可遷移性的同時(shí)還要保持足夠高的效率,這對(duì)語(yǔ)言設(shè)計(jì)師、編譯器設(shè)計(jì)師、DSA 架構(gòu)師們來(lái)說(shuō)都是一個(gè)有意思的科研挑戰(zhàn)。
下面用 TPUv1 這款 DSA 芯片舉例做詳細(xì)的解釋。谷歌 TPUv1 的設(shè)計(jì)目標(biāo)是加速神經(jīng)網(wǎng)絡(luò)的推理過(guò)程。這款 TPU 從 2015 年就投入了生產(chǎn)環(huán)境開(kāi)始使用,它支持著谷歌的各種應(yīng)用計(jì)算需求,包括搜索查詢(xún)、語(yǔ)言翻譯、圖像識(shí)別,一直到 DeepMind 的圍棋/象棋 AI AlphaGo/AlphaZero。這個(gè)芯片的設(shè)計(jì)目標(biāo)就是把深度神經(jīng)網(wǎng)絡(luò)推理時(shí)的性能表現(xiàn)和能量效率提升 10 倍。
如下方圖 8 所示,TPU 的內(nèi)核結(jié)構(gòu)設(shè)計(jì)和通用計(jì)算處理器完全不同。其中的主計(jì)算單元是一個(gè)矩陣計(jì)算單元,這是一個(gè)脈動(dòng)列表結(jié)構(gòu),它可以在每個(gè)時(shí)鐘周期進(jìn)行一次 256x256 矩陣的乘法加法運(yùn)算。在這項(xiàng)功能上聯(lián)合使用的 8 位精度、高效率的脈動(dòng)架構(gòu)、SIMD 控制、專(zhuān)門(mén)劃分出的一大片芯片面積,最終讓這個(gè)乘法累加器的每時(shí)鐘周期性能比一般的單核心通用計(jì)算 CPU 提升了大約 100 倍。而且,TPU 中并沒(méi)有使用緩存,它使用的是大小為 24MB 的本地存儲(chǔ)器,這相當(dāng)于是 2015 年時(shí)期的相同功耗的 CPU 上帶有的緩存空間的 2 倍。最后,激活值存儲(chǔ)器和權(quán)重存儲(chǔ)器(以及保留權(quán)重的 FIFO 架構(gòu))都通過(guò)一個(gè)用戶(hù)控制的高帶寬存儲(chǔ)通道連接在一起。在基于谷歌數(shù)據(jù)中心的六種常見(jiàn)推理問(wèn)題的加權(quán)性能統(tǒng)計(jì)中,TPU 要比通用計(jì)算 CPU 快 29 倍。由于 TPU 消耗的電能還不到 CPU 的一半,在處理這些負(fù)載時(shí) TPU 的能量效率要比通用計(jì)算 CPU 高 80 倍還不止。
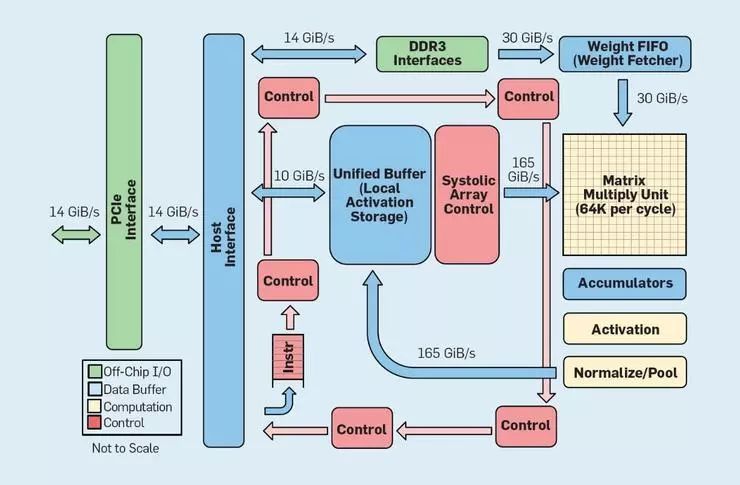
圖 8
總結(jié)
我們分析了通過(guò)提高硬件效率來(lái)提升程序運(yùn)行性能的兩種不同的方案。方案一,改進(jìn)通常是解釋執(zhí)行的現(xiàn)代高級(jí)編程語(yǔ)言的性能;方案二,設(shè)計(jì)領(lǐng)域?qū)S玫挠?jì)算架構(gòu),相比于通用計(jì)算 CPU 的表現(xiàn),這樣可以極大改進(jìn)運(yùn)行速度和能源效率。DSL 也是改進(jìn)硬件/軟件接口,從而讓計(jì)算架構(gòu)設(shè)計(jì)師們可以做出 DSA 這樣的創(chuàng)新的另一個(gè)重要例子。
想要通過(guò)這些方式取得程序性能的顯著提高,需要一支垂直集成的設(shè)計(jì)團(tuán)隊(duì),他們需要了解應(yīng)用、了解領(lǐng)域?qū)S谜Z(yǔ)言以及對(duì)應(yīng)的編譯器技術(shù)、了解計(jì)算機(jī)架構(gòu)和組件,并且了解其中蘊(yùn)含的實(shí)現(xiàn)技術(shù)。在整個(gè)計(jì)算機(jī)產(chǎn)業(yè)鏈變得水平整合之前,計(jì)算領(lǐng)域的許多早期工作都表現(xiàn)出了強(qiáng)烈的「垂直集成、可以跨越多個(gè)不同的抽象層次」的特點(diǎn)。而在現(xiàn)在這個(gè)新時(shí)代中,垂直整合能力變得更為重要,能夠做出重要的權(quán)衡并進(jìn)行檢驗(yàn)和優(yōu)化的團(tuán)隊(duì)將會(huì)占有先機(jī)。
這些改進(jìn)機(jī)會(huì)已經(jīng)引發(fā)了計(jì)算架構(gòu)創(chuàng)新的新浪潮,吸引了許多來(lái)自不同計(jì)算架構(gòu)設(shè)計(jì)邏輯的競(jìng)爭(zhēng)者:
GPU - 英偉達(dá) GPU 有許多核心,每個(gè)都有很大的寄存器,有許多硬件線(xiàn)程,也有緩存
TPU - 谷歌 TPU 主要依賴(lài)其中的大規(guī)模二維脈動(dòng)乘法累加器,以及依靠軟件控制片上存儲(chǔ)
FPGA - 微軟在數(shù)據(jù)中心中部署了現(xiàn)場(chǎng)可編程邏輯陣列(FPGA),這些數(shù)據(jù)中心是專(zhuān)為神經(jīng)網(wǎng)絡(luò)應(yīng)用優(yōu)化的
CPU - 英特爾提供的 CPU 帶有許多核心,然后用大容量的多級(jí)別緩存和一維 SIMD 指令增強(qiáng) CPU 的性能;英特爾也提供微軟使用的 FPGA,以及另一種更接近 TPU 的新型神經(jīng)網(wǎng)絡(luò)處理器。
除了這些大體量的競(jìng)爭(zhēng)者之外,也有好幾十家初創(chuàng)企業(yè)提出了自己的想法。為了滿(mǎn)足不斷增長(zhǎng)的計(jì)算需求,計(jì)算架構(gòu)設(shè)計(jì)師們把這樣的芯片成百上千地互相連接起來(lái),形成了為神經(jīng)網(wǎng)絡(luò)計(jì)算服務(wù)的超級(jí)計(jì)算機(jī)。
深度神經(jīng)網(wǎng)絡(luò)的瀑布式結(jié)構(gòu)也為計(jì)算機(jī)架構(gòu)設(shè)計(jì)帶來(lái)一段有趣的時(shí)光。很難預(yù)測(cè) 2019 年中這些不同的方向中是否會(huì)出現(xiàn)勝利者,但是市場(chǎng)最終一定會(huì)為這場(chǎng)競(jìng)爭(zhēng)分出勝負(fù),就像它過(guò)去也曾分出了一場(chǎng)計(jì)算機(jī)架構(gòu)之爭(zhēng)的勝負(fù)一樣。
開(kāi)放的架構(gòu)
受到開(kāi)源軟件的成功的啟發(fā),計(jì)算機(jī)架構(gòu)的第二個(gè)發(fā)展機(jī)遇在于開(kāi)放 ISA。為了創(chuàng)建一個(gè)「處理器的 Linux」,這個(gè)領(lǐng)域需要工業(yè)標(biāo)準(zhǔn)級(jí)別的開(kāi)放 ISA,這樣整個(gè)生態(tài)中才可以創(chuàng)建開(kāi)源的核心,在不同公司持有各自的專(zhuān)有核心架構(gòu)的環(huán)境中形成補(bǔ)充。如果許多組織結(jié)構(gòu)都使用同樣的 ISA 設(shè)計(jì)處理器,更激烈的競(jìng)爭(zhēng)可能會(huì)帶來(lái)的更快的創(chuàng)新和發(fā)展。這里的發(fā)展目標(biāo)是為不同的使用用途提供不同規(guī)模的處理器設(shè)計(jì),可以有 100 美元一個(gè)的處理器,也可以有幾美分一個(gè)的處理器。
這里的第一個(gè)例子就是 RISC-V,UC 伯克利大學(xué)開(kāi)發(fā)的第五代 RISC 架構(gòu)。在 RISC-V 基金會(huì)的管理之下,RISC-V 有一整個(gè)生態(tài)維護(hù)著這個(gè)架構(gòu)。選擇了開(kāi)放,也就讓這個(gè) ISA 也可以在公眾中露面,軟件和硬件專(zhuān)家們也可以在做出最終決定之前就展開(kāi)合作。開(kāi)放體系還會(huì)帶來(lái)一個(gè)好處,就是 ISA 很少會(huì)出于純市場(chǎng)營(yíng)銷(xiāo)的原因而擴(kuò)大,相比之下專(zhuān)有指令集就經(jīng)常會(huì)為了市場(chǎng)營(yíng)銷(xiāo)而增擴(kuò)充指令集。
首先,RISC-V 是一個(gè)模塊化的指令集。一小組基礎(chǔ)指令首先支持整個(gè)開(kāi)源軟件框架的運(yùn)行,然后有一些標(biāo)準(zhǔn)的拓展指令,設(shè)計(jì)師們可以根據(jù)自己的需求添加或者刪除。基礎(chǔ)指令含有 32 位和 64 位地址的版本。RISC-V 指令集的增長(zhǎng)完全可以只依靠可選的拓展指令的增加,支持軟件框架運(yùn)行的基礎(chǔ)指令不增加任何新的拓展也不會(huì)有任何問(wèn)題。專(zhuān)有指令集的處理器架構(gòu)一般都會(huì)需要向前的二進(jìn)制兼容性,這意味著如果一家處理器制造商決定在某一代處理器中增加一個(gè)新的功能,那么這家制造商未來(lái)的所有處理器都需要保留對(duì)這個(gè)功能的支持。但 RISC-V 就不需要這樣,所有的功能增強(qiáng)都是可選的,而且如果沒(méi)有應(yīng)用需要的話(huà)就可以隨時(shí)刪除。目前 RISC-V 中有如下幾個(gè)標(biāo)準(zhǔn)的拓展指令集,用首字母作為它們的簡(jiǎn)稱(chēng)
M. 整型乘法/除法
A. 原子內(nèi)存操作
F/D. 單精度/雙精度浮點(diǎn)運(yùn)算
C. 壓縮指令
其次,RISC-V 有一個(gè)特色是 ISA 的簡(jiǎn)潔性。下面提供了一組 RISC-V 與 ARM 公司在近似時(shí)間開(kāi)發(fā)的 ARMv8 架構(gòu)的對(duì)比,雖然對(duì)比的內(nèi)容不是完全可以量化的。
指令更少。RISC-V 的指令更少,基礎(chǔ)指令只有 50 條,這個(gè)數(shù)量和這些指令的性質(zhì)和最初的 RISC-I 驚人地相似。其它的幾個(gè)標(biāo)準(zhǔn)拓展指令集,M、A、F 和 D,一共增加 53 條指令,再加上 C 的另外 34 條,一共也只有 137 條。ARMv8 則有超過(guò) 500 條。
指令格式更少。RISC-V 的指令格式更少,只有 6 種,而 ARMv8 至少有 14 種。
第三,RISC-V 的簡(jiǎn)潔性不僅降低了設(shè)計(jì)處理器的復(fù)雜度,也減小了驗(yàn)證硬件正確性的難度。由于 RISC-V 的目標(biāo)就是要應(yīng)用在包括數(shù)據(jù)庫(kù)的高性能計(jì)算芯片到 IoT 設(shè)備上的低功耗芯片上,設(shè)計(jì)驗(yàn)證也可以在開(kāi)發(fā)成本中占據(jù)不小的比例。
第四,RISC-V 是一個(gè)完全從頭開(kāi)始的設(shè)計(jì),它是在初始設(shè)計(jì)的 25 年后開(kāi)始的。它的設(shè)計(jì)師們從前幾代的設(shè)計(jì)中吸取了許多錯(cuò)誤經(jīng)驗(yàn)。與第一代的 RISC 架構(gòu)不同,RISC-V 避開(kāi)了依賴(lài)微架構(gòu)和依賴(lài)技術(shù)的特征(比如延遲分支和延遲載入)以及很新的創(chuàng)新(比如寄存器窗口),實(shí)際上這些功能都隨著編譯器技術(shù)的發(fā)展而被替代了。
最后,RISC-V 還可以為定制化設(shè)計(jì)的加速器提供很大的操作指令設(shè)計(jì)空間,這為 DSA 提供了良好的支持。
除了 RISC-V 之外,英偉達(dá)也在 2017 年發(fā)布了一個(gè)免費(fèi)開(kāi)放的架構(gòu),名為英偉達(dá)深度學(xué)習(xí)加速器(NVDLA),這是一個(gè)用于深度學(xué)習(xí)推理的標(biāo)量、可配置的 DSA。它的可選配置包括數(shù)據(jù)類(lèi)型(8 位整型、16 位整型、16 位浮點(diǎn))以及其中的二維乘法矩陣的大小。根據(jù)不同的配置,芯片面積可以有 0.5mm2 到 3mm2 的不同大小,功耗也有 20mW 到 200mW 不同。這個(gè)架構(gòu)的 ISA、軟件架構(gòu)、實(shí)現(xiàn)方案也都是全部開(kāi)放的。
開(kāi)放的簡(jiǎn)單架構(gòu)實(shí)際上會(huì)帶來(lái)安全方面的好處。首先,安全專(zhuān)家們并不相信模糊不清就可以帶來(lái)安全,所以開(kāi)放的技術(shù)實(shí)現(xiàn)方案對(duì)他們更有吸引力;開(kāi)放的技術(shù)實(shí)現(xiàn)也就需要開(kāi)放的架構(gòu)。同等重要的是,有越來(lái)越多的人和組織機(jī)構(gòu)參與,也就可以圍繞安全的架構(gòu)設(shè)計(jì)做出更多改進(jìn)。專(zhuān)用的架構(gòu)把參與者局限為企業(yè)的員工,而開(kāi)放的架構(gòu)允許全世界學(xué)術(shù)和工業(yè)界的人參與提高安全性。更重要的是,這樣開(kāi)放的架構(gòu)、技術(shù)實(shí)現(xiàn)、軟件架構(gòu),再加上 FPGA 的高可塑性,都意味著架構(gòu)設(shè)計(jì)師們可以在線(xiàn)部署并評(píng)價(jià)新的解決方案,而且這個(gè)周期不再是以年計(jì),而是以周計(jì)。雖然 FPGA 比定制化芯片慢大約 10 倍,但這樣的性能表現(xiàn)也已經(jīng)足以支持用戶(hù)的在線(xiàn)使用,也就可以針對(duì)真正的攻擊者更及時(shí)地做出安全改進(jìn)。我們期待開(kāi)放的計(jì)算架構(gòu)未來(lái)成為架構(gòu)設(shè)計(jì)師和安全專(zhuān)家們進(jìn)行軟硬件聯(lián)合設(shè)計(jì)的典型范例。
敏捷硬件開(kāi)發(fā)
Beck 等人撰寫(xiě)的《軟件敏捷開(kāi)發(fā)手冊(cè)》為軟件開(kāi)發(fā)領(lǐng)域帶來(lái)了一場(chǎng)革命,它克服了傳統(tǒng)瀑布式開(kāi)發(fā)中精心設(shè)計(jì)的開(kāi)發(fā)計(jì)劃和文檔經(jīng)常失效的問(wèn)題。小的編程團(tuán)隊(duì)得以快速開(kāi)發(fā)出包含了核心功能但并不完善的軟件原型,然后在下一次迭代開(kāi)始前就獲得用戶(hù)反饋。競(jìng)爭(zhēng)性的敏捷開(kāi)發(fā)可以讓 5 到 10 人的開(kāi)發(fā)團(tuán)隊(duì)以 2 到 4 周一次迭代的速度快速前進(jìn)。
再一次,受到軟件開(kāi)發(fā)領(lǐng)域成功經(jīng)驗(yàn)的啟發(fā),硬件領(lǐng)域的第三個(gè)機(jī)遇就是敏捷硬件開(kāi)發(fā)。對(duì)架構(gòu)設(shè)計(jì)師們來(lái)說(shuō)也有一個(gè)好消息,現(xiàn)代電子計(jì)算機(jī)輔助設(shè)計(jì)(ECAD)工具提高了抽象級(jí)別,可以讓敏捷開(kāi)發(fā)以及對(duì)應(yīng)的更高級(jí)別的抽象在不同的設(shè)計(jì)之間重復(fù)使用。
如果說(shuō)要把軟件開(kāi)發(fā)中的每四周一次迭代的快速前進(jìn)方式照搬到硬件開(kāi)發(fā),一聽(tīng)之下會(huì)覺(jué)得難以置信,畢竟從硬件設(shè)計(jì)定版到得到芯片成品就有好幾個(gè)月的時(shí)間。而下面的圖 9 就展示了敏捷開(kāi)發(fā)過(guò)程中可以在適當(dāng)?shù)某橄蠹?jí)別上更改原型。最中央的抽象級(jí)別是軟件模擬器,也是在迭代中做改動(dòng)最簡(jiǎn)單、最快的部分。下一層是可以比細(xì)致的軟件模擬器運(yùn)行快數(shù)百倍的 FPGA。在 FPGA 上可以運(yùn)行操作系統(tǒng),也可以進(jìn)行全功能的性能評(píng)測(cè),比如 SPEC 中的測(cè)試項(xiàng)目;這讓原型的評(píng)價(jià)更加準(zhǔn)確。亞馬遜云服務(wù)就提供了 FPGA,架構(gòu)設(shè)計(jì)師們無(wú)需購(gòu)買(mǎi) FPGA 硬件并建立實(shí)驗(yàn)室就可以使用 FPGA 做自己的驗(yàn)證。為了獲得芯片面積和功耗的具體數(shù)值,下一層的 ECAD 工具可以生成芯片的布局圖。在工具運(yùn)行完畢之后還需要人工進(jìn)行一些步驟,對(duì)結(jié)果進(jìn)行微調(diào),確保新的處理器已經(jīng)準(zhǔn)備好投入生產(chǎn)了。處理器設(shè)計(jì)師們把這下一層稱(chēng)作「tape in」。前面的這四個(gè)級(jí)別都可以使用每四周一次的迭代速度。
圖 9
如果是出于科研目的,我們?cè)?tape in 這一步就可以停下來(lái)了,因?yàn)檫@時(shí)就已經(jīng)可以獲得非常準(zhǔn)確的面積、能耗、性能的估計(jì)數(shù)據(jù)了。不過(guò)如果真的停下來(lái)的話(huà),那就像參加長(zhǎng)跑比賽,最后在重點(diǎn)線(xiàn)前 50 米停了下來(lái),「因?yàn)榭梢詼?zhǔn)確地預(yù)測(cè)出最終要花多少時(shí)間了」。既然已經(jīng)在比賽的準(zhǔn)備以及前面的大部分賽程中投入了許多精力,但只要不沖過(guò)終點(diǎn)線(xiàn),那就沒(méi)辦法享受到真正的興奮和滿(mǎn)足。所以其實(shí),硬件工程師在有個(gè)方面比軟件工程師強(qiáng),就是因?yàn)樗麄冏罱K會(huì)生產(chǎn)出切實(shí)可感的物品。把芯片成品拿回來(lái)測(cè)量、運(yùn)行真正的程序、把芯片展示給他們的朋友和家人們看,這都是硬件設(shè)計(jì)工作中非常幸福的時(shí)刻。
許多研究人員會(huì)認(rèn)為他們需要在芯片試產(chǎn)之前停下來(lái),因?yàn)樾酒闹圃鞂?shí)在是太貴了。實(shí)際上,當(dāng)芯片很小的時(shí)候,它的制造價(jià)格就非常便宜。架構(gòu)設(shè)計(jì)師們委托半導(dǎo)體廠(chǎng)商制造 100 個(gè) 1mm2 面積的芯片只需要花 1.4 萬(wàn)美元。如果是以 28nm 工藝制作,1mm2 的面積上就可以放下數(shù)百萬(wàn)個(gè)晶體管,足以容納一個(gè) RISC-V 處理器再加一個(gè)英偉達(dá)加速器。如果要制造一個(gè)很大的芯片,那么最外面這一步可能就會(huì)花很多錢(qián),但是如果是為了展現(xiàn)新的想法的話(huà),小的芯片就可以做到。
結(jié)論
「黎明之前正是最灰暗的時(shí)刻」-Thomas Fuller
要從歷史經(jīng)驗(yàn)中學(xué)習(xí),有幾件事架構(gòu)師們必須知道:軟件開(kāi)發(fā)領(lǐng)域的創(chuàng)新點(diǎn)子同樣可以啟發(fā)硬件架構(gòu)設(shè)計(jì)師們,提升硬件/軟件接口設(shè)計(jì)的抽象級(jí)別可以為創(chuàng)新帶來(lái)機(jī)會(huì),以及市場(chǎng)最終會(huì)為計(jì)算機(jī)架構(gòu)之爭(zhēng)畫(huà)上句號(hào)。iAPX-432 和 Itanium 的故事說(shuō)明了硬件架構(gòu)方面的投資可能無(wú)法帶來(lái)對(duì)等的回報(bào),而 S/360、8086、ARM 架構(gòu)則能夠年復(fù)一年地帶來(lái)充沛的盈利。
Dennard Scaling 定律和摩爾定律走向終結(jié),以及標(biāo)準(zhǔn)微處理器的性能提升越來(lái)越慢并不是什么必須解決不可的問(wèn)題,而實(shí)際上,它們完全可以看作是令人激動(dòng)的新機(jī)遇。高級(jí)別、領(lǐng)域?qū)S玫恼Z(yǔ)言和架構(gòu)把架構(gòu)設(shè)計(jì)師們從專(zhuān)用指令集不斷擴(kuò)充的鏈條中解放出來(lái),同樣也釋放了公眾對(duì)于更高的安全性的需求,這都會(huì)帶來(lái)計(jì)算機(jī)架構(gòu)的新的黃金時(shí)代。另外依靠開(kāi)源生態(tài)的幫助,敏捷開(kāi)發(fā)的芯片也會(huì)越來(lái)越令人信服地展現(xiàn)出它的優(yōu)勢(shì),并逐步越來(lái)越快地取得商業(yè)上的成功。對(duì)于通用處理器的設(shè)計(jì)理念,ISA 未來(lái)也將隨著時(shí)間的流逝而越發(fā)顯得熠熠生輝,就像 RISC 一樣。在新的黃金時(shí)代中我們可以期待繼續(xù)看到上個(gè)黃金時(shí)代那樣的高速發(fā)展,只不過(guò)這次首當(dāng)其沖的是價(jià)格、能耗以及安全,性能當(dāng)然也會(huì)有繼續(xù)的提高。
在未來(lái) 10 年中,我們可以期待在計(jì)算機(jī)架構(gòu)領(lǐng)域也看到寒武紀(jì)生物大爆炸那樣地充滿(mǎn)新鮮創(chuàng)意,這對(duì)于學(xué)術(shù)界和工業(yè)界的計(jì)算機(jī)架構(gòu)設(shè)計(jì)師們來(lái)說(shuō)會(huì)是一段充滿(mǎn)激情的時(shí)光。
-
cpu
+關(guān)注
關(guān)注
68文章
10906瀏覽量
213049 -
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7544瀏覽量
88659
原文標(biāo)題:圖靈獎(jiǎng)得主長(zhǎng)文報(bào)告:是什么開(kāi)啟了計(jì)算機(jī)架構(gòu)的新黃金十年?
文章出處:【微信號(hào):worldofai,微信公眾號(hào):worldofai】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
計(jì)算機(jī)網(wǎng)絡(luò)架構(gòu)的演進(jìn)
工業(yè)中使用哪種計(jì)算機(jī)?

量子計(jì)算機(jī)與普通計(jì)算機(jī)工作原理的區(qū)別
計(jì)算機(jī)接口位于什么之間
《量子計(jì)算觀察》智庫(kù)報(bào)告第1期:未來(lái)5年“量超融合”黃金期 3大商機(jī)將現(xiàn)

十年預(yù)言:Chiplet的使命
簡(jiǎn)述計(jì)算機(jī)總線(xiàn)的分類(lèi)
晶體管計(jì)算機(jī)和電子管計(jì)算機(jī)有什么區(qū)別
工業(yè)控制計(jì)算機(jī)與普通個(gè)人計(jì)算機(jī)相比有何區(qū)別?
工業(yè)計(jì)算機(jī)與普通計(jì)算機(jī)的區(qū)別
【量子計(jì)算機(jī)重構(gòu)未來(lái) | 閱讀體驗(yàn)】+ 了解量子疊加原理
【量子計(jì)算機(jī)重構(gòu)未來(lái) | 閱讀體驗(yàn)】+量子計(jì)算機(jī)的原理究竟是什么以及有哪些應(yīng)用
【量子計(jì)算機(jī)重構(gòu)未來(lái) | 閱讀體驗(yàn)】+ 初識(shí)量子計(jì)算機(jī)
計(jì)算機(jī)視覺(jué)的十大算法

第一屆中歐計(jì)算機(jī)架構(gòu)研發(fā)與RISC-V機(jī)遇與合作研討會(huì)成功舉辦

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線(xiàn)
- 接口/總線(xiàn)/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車(chē)電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專(zhuān)欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線(xiàn)研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠(chǎng)房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論