 在沒有災難性遺忘的情況下,實現深度強化學習的偽排練
在沒有災難性遺忘的情況下,實現深度強化學習的偽排練
在沒有災難性遺忘的情況下,實現深度強化學習的偽排練

該新模型集成了偽排練,深度生成模型和雙重內存方案,從而實現了一種高效的方法,即使任務數量增加,也不需要額外的存儲要求。通過迭代,該模型學習了三個Atari游戲,并在這三個游戲中保持了高于人類水平的表現,高效程度不亞于經過單獨訓練的一組網絡。
所有這些都是在不訪問以前的任務數據的情況下實現的。與現有的深度增強任務算法相比,新模型已經表明它們不會像傳統的模型一樣忘記之前的任務。
潛在應用與效果
研究人員和人工智能社區可以利用新模型進一步改進研究工作,并將模型應用于前沿的電子游戲、自動駕駛汽車和機器人中。如果有足夠大的網絡,也許會誕生能處理多種任務的機器人特工。
原文:
https://arxiv.org/abs/1812.02464v2
雙注意網絡(DAN)用于改進視覺參考分辨率
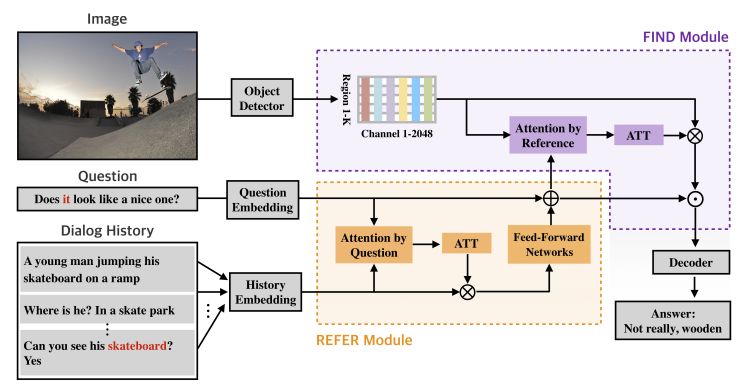
最近,研究人員通過提出DAN增強了視覺參考分辨率,為解決視覺參考分辨率問題奠定了基礎。DAN實現了兩種類型的關注網絡,包括REFER和FIND。REFER專門用于通過自我關注方法來學習查詢和對話歷史之間的關系。
相反,FIND采用圖像特征和參考感知表示輸入(REFER模塊的輸出),并通過實施自下而上的注意技術實現視覺接地。在VisDial v1.0和v0.9數據集上對DAN的定量和定性評估表明,它在很大程度上優于現有的可視對話模型。
潛在應用與效果
AI社區可以使用DAN來實現各種視覺對話任務的視覺參考分辨率,比如協作對話系統。因為它不依賴于之前的視覺注意力圖,所以DAN可以通過實施REFER組件來解決不清晰的視覺效果,并使用FIND模型組件對可視圖像進行地面解析參考。
原文:
https://arxiv.org/abs/1902.09368v1
用于增強邊緣檢測的動態特征融合(DFF)方法
來自中國的研究人員通過提出一種新的動態特征融合(DFF)策略來管理動態特征融合,該策略為不同的圖像和位置分配不同的融合權重。DFF包括兩個模塊,特征提取器和自適應權重融合組件。該模型通過實施權重模型來實現動態特征融合,從而能夠針對輸入特征圖中的每一單個位置推斷多級特征上的適當融合權重。
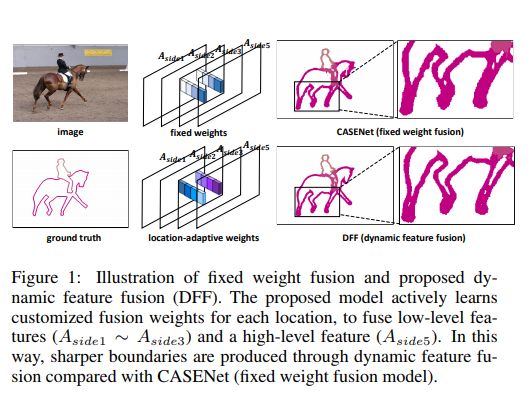
在對標準基準數據集(如Cityscapes和SBD)進行實驗后,DFF證明了它可以通過更精確地定位對象邊緣和抑制不重要的邊緣響應來大大提高模型性能。
潛在應用與效果
語義邊緣檢測旨在聯合提取邊緣及其類別信息,以實現領域中的高端應用,包括語義分割,對象識別等。DFF是第一個旨在學習自適應融合權重的研究工作,它以輸入數據為條件,在SED研究中融合多層次特征,以促進和實現SED任務的最新技術。通過考慮高級和低級主干特征映射,可以改善位置自適應權重學習器。
原文:
https://arxiv.org/abs/1902.09104v1
用于自動駕駛的離線和在線角落案例檢測框架
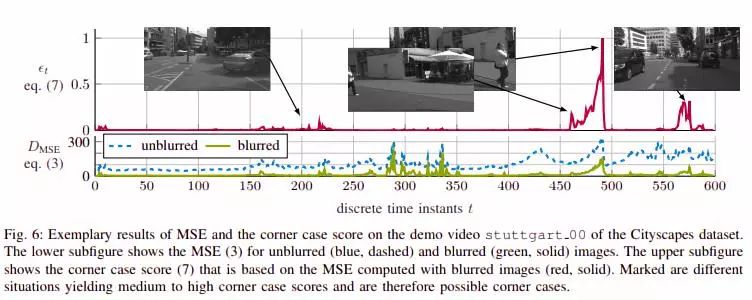
這項新研究定義了角落案例檢測,并提出了一個框架,可以處理來自移動車輛的前置攝像頭的視頻信號,并為在線和離線用例生成角落案例分數。根據該系統框架背后的研究人員所說,角落案例檢測系統可用作備用警告系統,以提供有關自動駕駛系統的異常場景的信息。另外,關于離線模式,角落情況檢測框架可用于分析大量視頻數據以返回異常數據。
角落案例檢測框架針對Cityscapes數據集的分段和圖像預測進行了訓練,該數據集包含來自50個城市的各種街道圖像。
潛在應用與效果
自動駕駛汽車研究人員和工程師可以實施角落案例框架,為自動駕駛系統開發更集中的訓練,因為它有助于解決代表性不足的關鍵訓練數據問題。該系統還有助于選擇用于存儲和(重新)訓練AI模型的相關場景。
此外,此次提出的角落案例檢測框架對于實現運動檢測,圖像注冊,視頻跟蹤,圖像鑲嵌,3D建模,全景拼接,對象識別等方面的進一步開發是有效的。
原文:
https://arxiv.org/abs/1902.09184v1
車輛相遇情況的數據集生成器
訓練數據的缺乏大大減緩了自動駕駛技術的發展速度。而近日發布的一種模擬模型,通過提供大量數據和資源,從而幫助工程師實現有效的自動車輛開發測試,正逐步消除這一限制。
多車輛軌跡生成器(MTG)可以將多車輛場景(駕駛相遇數據)編碼成可用于產生新的高質量駕駛相遇數據的刻度表達。這種發生器模型包括雙向變分自動編碼器和多分支解碼器兩大部分。
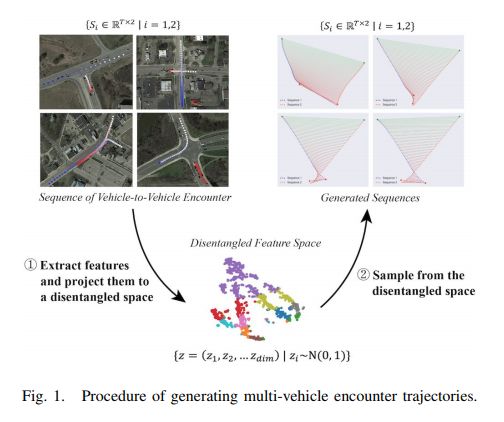
該研究還提出了一種新的解開度量指標,該指標具有綜合分析模擬出的軌跡及駕駛場景模型穩健度的可能性。與現有的VAE和infoGAN模型相比,這種新型生成器模型在生成高質量的駕駛場景信息方面更占優勢。
潛在應用與效果
多車輛軌跡生成器是自動駕駛開發中的一大進步。不僅是自動駕駛技術能因此獲益而加速發展,這一方法同樣可以擴展到有類似數據短缺問題的深度學習其他研究領域。
原文:
https://arxiv.org/abs/1809.05680v5
用于高分辨率人體姿態估計的高分辨率網絡(HRNet)
與以串聯方式連接子網絡的傳統方法不同,新的HRNet方法以并聯方式連接高分辨率子網絡,從而可以保持高分辨率,并實現準確的關鍵點預測。此外,許多現有的融合型方案結合了低級和高級表示,而HRNet執行重復的多尺度融合以增強高分辨率表示,這對于高質量的姿態估計是必不可少的。
在COCO關鍵點檢測和MPII人類姿勢數據集中進行的實驗表明,HRNet較于傳統方式更加有效。此外,HRNet在PoseTrack數據集上進行測試上也表現出了在姿勢跟蹤方面的優勢。所有模型和代碼均可在此鏈接上公開獲取。
潛在應用與效果
研究人員和開發人員可以將HRNet應用于高級對象檢測,動態識別,語義分割,人機交互(HCI),虛擬現實,增強現實,人臉識別及比對,圖像識別及分類,翻譯以及其他依賴跟蹤和識別人類活動而實現服務的應用,例如Amazon Go。我很期待有一天我的智能手機可以告訴我我的舉重姿勢是否正確。
原文:
https://arxiv.org/abs/1902.09212v1
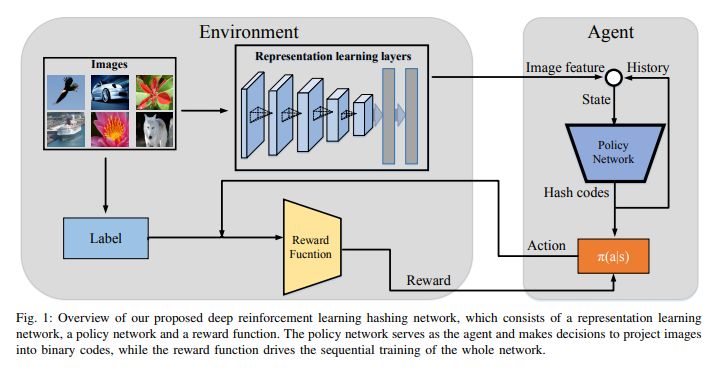
用于圖像復刻的深度強化學習方法(DRLIH)
DRLIH是第一個從深度強化學習角度去解決圖像復刻挑戰的研究項目。
這種深度學習網絡包括特征表示網絡和策略網絡。策略網絡利用遞歸神經網絡(RNN)作為代理,按時間順序將圖像投影為二進制代碼。
這樣的網絡設計有助于生成圖像并將其投影到復刻代碼1中,并計算復刻代碼0的概率。研究人員還提出了一種順序學習策略,通過糾正先前函數的錯誤來提高檢索準確性,從而學習復刻函數。DRLIH方法已經在三個標準數據集上進行了測試,結果證明它比傳統圖像復刻方法有效。
潛在應用與效果
DRLIH 技術可以準確地表示,索引,檢索和自動識別圖像。通過查詢圖像是否為原始圖像的構造或副本,它可用于圖像有效性的驗證。DRLIH還可用于本地存儲或緩存的有效性驗證,防止照片重新傳輸或重復存儲,以及目前通過水印實現的版權保護等。
原文:
https://arxiv.org/abs/1802.02904v2
語境嵌入改進臨床概念提取
新的研究提出了一種處理這一長期挑戰的新方法。研究人員評估了各種嵌入方法,包括word2vec,GloVe fastText,ELMo和BERT。他們還進行了涵蓋四個臨床概念語料庫的分析,以證明上述每種技術的普遍性。
更重要的是,他們使用大型臨床語料庫開發預訓練的情境化嵌入,并將性能與預訓練模型進行了比較。
最后,他們的論文詳述了與開放領域語料庫相比,預訓練對臨床語料庫影響的詳細分析,并總結報告了臨床概念提取的性能提升:該提取在所有測試語料庫中實現了最先進的結果。研究結果顯示出語境嵌入在臨床文本語料庫中的優勢,其在各類任務的完成上都優于傳統模型。
潛在應用與效果
對于臨床概念提取,上下文嵌入有大幅度改善自動文本處理的潛力。
此外,它還使研究人員對臨床文本的訪問更加無障礙,從而進一步推動該領域的信息管理和非結構化臨床文本的數據挖掘。
-
人工智能
+關注
關注
1804文章
48820瀏覽量
247277 -
自動駕駛
+關注
關注
788文章
14240瀏覽量
169880 -
強化學習
+關注
關注
4文章
269瀏覽量
11532
原文標題:DAN改進視覺參考分辨率,DRLIH實現圖像復刻 | AI一周學術
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是深度強化學習?深度強化學習算法應用分析

*** 災難性故障,求救,經驗分享
深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
薩頓科普了強化學習、深度強化學習,并談到了這項技術的潛力和發展方向
一種新型的強化學習算法,能夠教導算法如何在沒有人類協助的情況下解開魔方
Batch的大小、災難性遺忘將如何影響學習速率



模擬矩陣在深度強化學習智能控制系統中的應用






 工商網監
工商網監
評論