") 爬蟲框架是什么
爬蟲框架是什么
爬蟲框架是什么
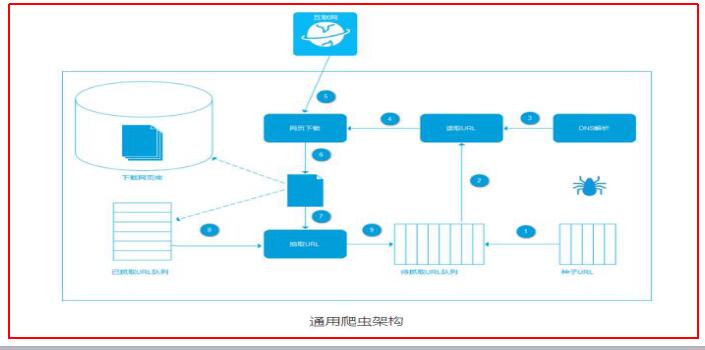
爬蟲系統(tǒng)首先從互聯(lián)網(wǎng)頁面中精心選擇一部分網(wǎng)頁,以這些網(wǎng)頁的鏈接地址作為種子URL,將這些種子放入待抓取URL隊(duì)列中,爬蟲從待抓取URL隊(duì)列依次讀取,并將URL通過DNS解析,把鏈接地址轉(zhuǎn)換為網(wǎng)站服務(wù)器對應(yīng)的IP地址。
然后將其和網(wǎng)頁相對路徑名稱交給網(wǎng)頁下載器,網(wǎng)頁下載器負(fù)責(zé)頁面的下載。
對于下載到本地的網(wǎng)頁,一方面將其存儲到頁面庫中,等待建立索引等后續(xù)處理;另一方面將下載網(wǎng)頁的URL放入已抓取隊(duì)列中,這個隊(duì)列記錄了爬蟲系統(tǒng)已經(jīng)下載過的網(wǎng)頁URL,以避免系統(tǒng)的重復(fù)抓取。
對于剛下載的網(wǎng)頁,從中抽取出包含的所有鏈接信息,并在已下載的URL隊(duì)列中進(jìn)行檢查,如果發(fā)現(xiàn)鏈接還沒有被抓取過,則放到待抓取URL隊(duì)列的末尾。在之后的抓取調(diào)度中會下載這個URL對應(yīng)的網(wǎng)頁。
如此這般,形成循環(huán),直到待抓取URL隊(duì)列為空,這代表著爬蟲系統(tǒng)將能夠抓取的網(wǎng)頁已經(jīng)悉數(shù)抓完,此時完成了一輪完整的抓取過程。
爬蟲框架有哪些
1、神箭手云爬蟲框架
是一個免費(fèi)的網(wǎng)絡(luò)爬蟲框架,為開發(fā)者提供成套的開發(fā)教程和開發(fā)工具,為企業(yè)提供專業(yè)化的數(shù)據(jù)抓取、數(shù)據(jù)實(shí)時監(jiān)控和數(shù)據(jù)分析服務(wù)。
最大的特點(diǎn)是一站式服務(wù),通過底層框架簡化了網(wǎng)絡(luò)爬蟲開發(fā)難度,而且提供了豐富的開源網(wǎng)絡(luò)爬蟲資源。
2、Nutch
這是一個開源Java實(shí)現(xiàn)的搜索引擎,提供了我們運(yùn)行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬蟲。Nutch目前最新的版本為versionv2.3。
3、Crawler4j
Crawler4j是一個開源的Java類庫提供一個用于抓取Web頁面的簡單接口。可以利用它來構(gòu)建一個多線程的Web爬蟲。
4、WebMagic
WebMagic是一個簡單靈活的Java爬蟲框架。
它的特性包括:簡單的API,可快速上手;模塊化的結(jié)構(gòu),可輕松擴(kuò)展;提供多線程和分布式支持
5、Heritrix
這是一個由java開發(fā)的、開源的網(wǎng)絡(luò)爬蟲,用戶可以使用它來從網(wǎng)上抓取想要的資源。其最出色之處在于它良好的可擴(kuò)展性,方便用戶實(shí)現(xiàn)自己的抓取邏輯。
-
爬蟲
+關(guān)注
關(guān)注
0文章
83瀏覽量
7416
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論