") 免費(fèi)GPU哪家強(qiáng)?谷歌Kaggle vs和Colab
免費(fèi)GPU哪家強(qiáng)?谷歌Kaggle vs和Colab

谷歌有兩個(gè)平臺(tái)提供免費(fèi)的云端GPU:Colab和Kaggle, 如果你想深入學(xué)習(xí)人工智能和深度學(xué)習(xí)技術(shù),那么這兩款GPU將帶給你很棒學(xué)習(xí)的體驗(yàn)。那么問題來了,我們?cè)撨x擇哪個(gè)平臺(tái)進(jìn)行學(xué)習(xí)和工作呢?接下來,本文將介紹如何比較硬件規(guī)格和探索優(yōu)缺點(diǎn)的差異;本文還將基于一個(gè)計(jì)算機(jī)視覺任務(wù),比較在不同平臺(tái)下,使用遷移學(xué)習(xí)、混合精度訓(xùn)練、學(xué)習(xí)率模擬退火以及測(cè)試時(shí)間增廣等操作時(shí),所需的訓(xùn)練時(shí)間。基于上述內(nèi)容,你將對(duì)這兩個(gè)平臺(tái)的GPU性能,有一個(gè)更加全面和清楚的了解。
Kaggle 和 Colab 是兩個(gè)非常相似的產(chǎn)品,它們都具有如下特性:
提供免費(fèi)的GPU
在瀏覽器中使用Jupyter進(jìn)行交互——但是它們都有自己獨(dú)特的風(fēng)格
旨在促進(jìn)機(jī)器學(xué)習(xí)的協(xié)作
都是谷歌的產(chǎn)品
不是十全十美,但是在多數(shù)場(chǎng)景下都適用,尤其是在入門深度學(xué)習(xí)的時(shí)候
官方文檔對(duì)硬件規(guī)格的描述較為簡(jiǎn)略
最后一項(xiàng)是本文研究的重點(diǎn),但不幸的是,Kaggle和Colab都不提供對(duì)使用環(huán)境的詳細(xì)描述,而且官方文檔(https://www.kaggle.com/docs/kernels#technical-specifications)往往很過時(shí),跟不上平臺(tái)硬件更新的速度。除此之外,平臺(tái)IDE的小控件雖然提供了一些信息,但是這往往不是我們真正想要的。接下來,本文展示常用的profiler命令,該命令可以查看平臺(tái)環(huán)境的信息。
在正式開始之前,我們得先了解一些GPU的背景知識(shí)。
什么是GPU?
GPU是圖形處理單元的簡(jiǎn)稱,最初GPU是為加速視頻游戲的圖形所開發(fā)的專用芯片,它們能夠快速的完成大量的矩陣運(yùn)算。該特性也使得GPU在深度學(xué)習(xí)領(lǐng)域嶄露頭角,有趣的是,出于相同的原因,GPU也是挖掘加密貨幣的首選工具。
Nvidia P100 GPU
為什么要使用GPU?
使用大顯存的GPU來訓(xùn)練深度學(xué)習(xí)網(wǎng)絡(luò),比單純用CPU來訓(xùn)練要快得多。想象一下,使用GPU能夠在十幾分鐘或者幾個(gè)小時(shí)內(nèi),獲得所訓(xùn)練網(wǎng)絡(luò)的反饋信息,而使用CPU則要花費(fèi)數(shù)天或者數(shù)周的時(shí)間,GPU簡(jiǎn)直是棒呆了。
硬件規(guī)格
2019年三月初,kaggle將它的GPU芯片從Nvidia Tesla K80升級(jí)到了Nvida Tesla P100,然而Colab還在用K80。有關(guān)Nvidia 芯片類型的討論,可以參見這篇文章(https://towardsdatascience.com/maximize-your-gpu-dollars-a9133f4e546a)。
有很多不同方法可以查看硬件的信息,兩個(gè)比較常用的命令是!nvidia-smi和 !cat/proc/cpuinfo,分別用于查看GPU和CPU的信息。即使你想用GPU來訓(xùn)練模型,CPU也是不必可少的,因此了解CPU的信息是必不可少的。
下圖所示為Kaggle和Colab的硬件配置信息,更多內(nèi)容可以參考谷歌官方文檔(https://docs.google.com/spreadsheets/d/1YBNlI9QxQTiPBOhsSyNg6EOO9LH2M3zF7ar88SeFQRk/edit?usp=sharing)。

兩個(gè)平臺(tái)上的內(nèi)存大小和磁盤空間,可能會(huì)存在一些令人疑惑的地方。一旦在Kaggle或者Colab上安裝軟件并開始進(jìn)程,它的內(nèi)存和磁盤可用量就會(huì)發(fā)生變化了。我們可以用!cat/proc/meminfo 命令來測(cè)試這種容量變化,如下圖所示。
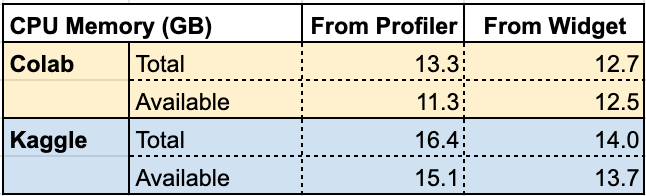
Total表示總內(nèi)存容量,Available表示啟動(dòng)后,沒有任何其他進(jìn)程運(yùn)行的情況下,實(shí)際觀察到的內(nèi)存容量。從上圖可以看到,我們自己測(cè)量的值和Colab或Kaggle的IDE控件面板中顯示的很相似,但是并不完全匹配,如下圖所示。
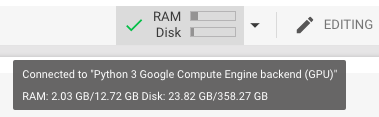
Mouseover in Colab
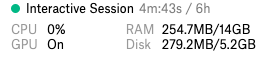
Kaggle Sidebar
上圖顯示的是Kaggle的內(nèi)核和Colab Notebook中的硬件規(guī)格信息,請(qǐng)注意,在開始前一定要確保開啟了GPU的功能。
還有一點(diǎn)值得注意,使用命令行查看GPU的硬件規(guī)格時(shí),系統(tǒng)返回值的單位是Mebibytes,該單位和Megabytes(兆字節(jié))相似但并不等同。通過谷歌搜索相應(yīng)信息,可以將Mebibytes轉(zhuǎn)化為Megabytes。
Kaggle 的widget(小部件)顯示,實(shí)際使用的磁盤空間比前文調(diào)研的要小得多,這是因?yàn)椋瑹o論理論上的磁盤總量是多少,Kaggle都會(huì)限制實(shí)際能夠使用的磁盤空間。
在官方文檔中Kaggle聲明,用戶擁有9個(gè)小時(shí)的使用時(shí)間,然而,對(duì)于每個(gè)會(huì)話,內(nèi)核環(huán)境最多只會(huì)在窗口上顯示6個(gè)小時(shí)。值得注意的是,重新啟動(dòng)內(nèi)核會(huì)重新啟動(dòng)時(shí)鐘。此外,如果用戶在60分鐘內(nèi)沒有任何操作,Kaggle會(huì)將會(huì)話重啟。
Colab為用戶提供12小時(shí)的執(zhí)行時(shí)間,但是如果閑置時(shí)間超過90分鐘,Colab就會(huì)將你踢掉。
接下來就要進(jìn)入本文的重點(diǎn)了:訓(xùn)練一個(gè)深度學(xué)習(xí)網(wǎng)絡(luò),到底會(huì)花費(fèi)多少時(shí)間。
計(jì)算機(jī)視覺任務(wù)下的速度比較
本文用一個(gè)圖像分類的任務(wù)來比較Kaggle和Colab的計(jì)算性能。該任務(wù)的目標(biāo)是構(gòu)建一個(gè)深度學(xué)習(xí)模型,對(duì)貓狗的圖像進(jìn)行分類。數(shù)據(jù)集包含25000張圖像,貓和狗的樣本數(shù)是均衡的。將數(shù)據(jù)集分為兩部分,其中23000張圖像用于訓(xùn)練,另外2000張用于驗(yàn)證。
Cat and dog images from the dataset
本文用FastAI庫構(gòu)建了一個(gè)卷積神經(jīng)網(wǎng)絡(luò),并以ResNet30為基礎(chǔ)運(yùn)用遷移學(xué)習(xí)訓(xùn)練該模型。模型的訓(xùn)練使用了以下幾個(gè)技巧,分別是數(shù)據(jù)增廣和學(xué)習(xí)率退火。在模型的測(cè)試階段,本文使用測(cè)試時(shí)間增廣技術(shù)來構(gòu)建測(cè)試集。本節(jié)的代碼改編自FastAI的示例(https://github.com/fastai/fastai/blob/master/examples/dogs_cats.ipynb)。
代碼分別在Kaggle和Colab上的實(shí)施。Batch size 設(shè)為16,F(xiàn)astAI的版本是1.0.48。使用FastAI的內(nèi)置分析器,統(tǒng)計(jì)訓(xùn)練和測(cè)試的總時(shí)間,兩平臺(tái)所用的時(shí)間如下。
在兩個(gè)平臺(tái)中,模型的驗(yàn)證精度都超過了99%,三次迭代的時(shí)間在Kaggle中是11:17分鐘,而Colab中為19:54分鐘。Kaggle的運(yùn)行環(huán)境性能,從速度上看,比Colab要快40%。
Batch Size
在Kaggle中,我們需要將batch size從64降低到16,才能使模型成功進(jìn)行訓(xùn)練。如果batch size過大,會(huì)導(dǎo)致運(yùn)行錯(cuò)誤,該錯(cuò)誤似乎是由于Docker容器中的共享內(nèi)存設(shè)置得太低才引起的。有趣的是,作者在2018年底向Colab提出了這個(gè)問題(https://github.com/googlecolab/colabtools/issues/329),Colab在一周內(nèi)便修復(fù)了這個(gè)問題。然而,截止2019年3月中旬,Kaggle依然存在該問題。
接下來,我們將Colab中的batch size改為256,對(duì)模型進(jìn)行兩次迭代訓(xùn)練。上述的改變導(dǎo)致平均運(yùn)行時(shí)間變成了18:38分鐘。將batch size改為64,同樣進(jìn)行兩次迭代訓(xùn)練,此時(shí)得到的平均運(yùn)行時(shí)間為18:14分鐘。這表示,當(dāng)batch size大于16的時(shí)候,Colab能夠縮減運(yùn)行的時(shí)間。
盡管如此,對(duì)于本節(jié)中的任務(wù)而言,較小的batch size并不是一個(gè)值得深究的大問題,有關(guān)參數(shù)設(shè)置的討論,可以參見這篇文章(https://arxiv.org/abs/1804.07612)。
當(dāng)我將Colab上的batch size設(shè)為256,然后開始訓(xùn)練模型時(shí),Colab拋出了一個(gè)警告,其中寫道:我正在使用的GPU具有11.17GB的顯存。具體如下圖所示。
這個(gè)警告非常棒,但是基于前文的分析,我們已經(jīng)了解了Gibibytes和Gigabytes(https://www.gbmb.org/gib-to-gb)之間的區(qū)別。前文中講到,Colab有11.17 Gibibytes(12 GB)的顯存,這顯然和警告中說的11.17GB矛盾。盡管如此,如果Colab提示你超出內(nèi)存了,那就是超出內(nèi)存了。因此batch size設(shè)為256,可能就是該任務(wù)下Colab的極限了。
混合精度訓(xùn)練
接下來,我們使用了混合精度訓(xùn)練,該訓(xùn)練方式能夠有效地降低訓(xùn)練時(shí)間。混合精度訓(xùn)練在某些可能的情況下,會(huì)使用16位精度的數(shù)值代替32位的數(shù)值,來進(jìn)行計(jì)算。Nvidia聲稱使用16位精度,可以使P100的吞吐量翻倍。
有關(guān)混合精度FastAI模型的介紹可以參見這篇文章(https://docs.fast.ai/callbacks.fp16.html)。請(qǐng)注意,在使用測(cè)試時(shí)間增廣進(jìn)行預(yù)測(cè)之前,我們需要將FastAI學(xué)習(xí)器對(duì)象設(shè)置為32位模式,這是因?yàn)閠orch.stack暫時(shí)不支持半精度。
通過在Colab上使用混合精度進(jìn)行訓(xùn)練,在batch size 為16的情況下,平均運(yùn)行時(shí)間為16:37分鐘。顯然,我們成功的縮減了運(yùn)行時(shí)間。
然而,在Kaggle上實(shí)施混合精度訓(xùn)練,總的運(yùn)行時(shí)間卻增加了一分半,達(dá)到了12:47分鐘。我們并沒有改變硬件規(guī)格,而且得到的驗(yàn)證精度都達(dá)到了99%以上,這就很有趣了。
通過調(diào)查發(fā)現(xiàn),Kaggle的默認(rèn)包中的torch和torchvision的版本都很老,將它們的版本更新到和Colab上的一樣后,Kaggle的運(yùn)行時(shí)間并沒有改變。但是這一個(gè)發(fā)現(xiàn)表明,Colab上默認(rèn)包的版本比Kaggle更新的要快。
前文提到的硬件差異,似乎并不是導(dǎo)致Kaggle混合精度性能不佳的原因。那么軟件差異似乎是答案,我們觀察到,兩平臺(tái)唯一的軟件差異就是,Kaggle使用CUDA 9.2.148 和 cuDNN 7.4.1,而Colab 使用CUDA 10.0.130 和 cuDNN 7.5.0。
CUDA是Nvidia的API,可以直接訪問GPU的虛擬指令集。cuDNN是Nvidia基于CUDA的深度學(xué)習(xí)原型庫。根據(jù)Nvidia的這篇文章,Kaggle的軟件應(yīng)該可以提高P100的速度。但是,正如cuDNN更改說明(https://docs.nvidia.com/deeplearning/sdk/cudnn-release-notes/rel_750.html#rel_750)中所示,阻止加速的bug是定期排查和修復(fù)的,那么kaggle在混合精度訓(xùn)練上表現(xiàn)不佳,可能是因?yàn)閎ug修復(fù)不及時(shí)所導(dǎo)致的吧。
既然如此,我們只好等待Kaggle升級(jí)CUDA和cuDNN,看看混合精度訓(xùn)練是否會(huì)變得更快。如果使用Kaggle,還是推薦你采用混合精度訓(xùn)練(雖然速度并不會(huì)得到提升)。如果使用Colab,當(dāng)然采用混合精度訓(xùn)練更佳,但是要注意batch size不要設(shè)置得太大。
優(yōu)缺點(diǎn)對(duì)比
谷歌是一家希望您支付GPU費(fèi)用的公司,天下沒有免費(fèi)的午餐。
Colab和Kaggle當(dāng)然會(huì)有一些令人沮喪的問題。例如,兩個(gè)平臺(tái)運(yùn)行時(shí)斷開連接的頻率太高,這令我們非常沮喪,因?yàn)槲覀儾坏貌恢貑?huì)話。
在過去,這些平臺(tái)并不能總保證你有GPU可以用,但是現(xiàn)在卻可以了。接下來讓我們一起看看,Colab和Kaggle的各自的優(yōu)缺點(diǎn)吧。
Colab
優(yōu)點(diǎn)
能夠在Google Drive上保存notebook
可以在notebook中添加注釋
和GIthub的集成較好——可以直接把notebook保存到Github倉庫中
具有免費(fèi)的TPU。TPU和GPU類似,但是比GPU更快。TPU是谷歌自行開發(fā)的一款芯片,但不幸的是,盡管Colab意在整合PyTotch和TPU,但TPU對(duì)PyTorch的支持仍不太友好。如果使用TensorFlow進(jìn)行編程,而不是使用FastAI/Pytorch編程,那么在Colab上使用TPU可要比在Kaggle上使用GPU快多了。
缺點(diǎn)
部分用戶在Colab中的共享內(nèi)存較小。
谷歌云盤的使用較為麻煩。每個(gè)會(huì)話都需要進(jìn)行身份驗(yàn)證,而且在谷歌云盤中解壓文件較為麻煩。
鍵盤快捷鍵和Jupyter Notebook中不太一樣。具體對(duì)比可以參見這里。
Kaggle
優(yōu)點(diǎn)
Kaggle社區(qū)有利于學(xué)習(xí)和展示你的技能
在Kaggle上發(fā)布你的工作,能夠記錄一段美好的歷史
Kaggle和Jupyter notebook的鍵盤快捷鍵基本相同
Kaggle有很多免費(fèi)數(shù)據(jù)集
缺點(diǎn)
Kaggle一般會(huì)自動(dòng)保存你的工作,但是如果你沒有提交工作,然后重新加載你的頁面,你的工作很有可能丟失。
就像前面提到的,在Kaggle中,Docker容器中的PyTorch共享內(nèi)存較低。在本次圖像分類任務(wù)中,如果設(shè)置batch size的大小超過16,那么系統(tǒng)就會(huì)報(bào)錯(cuò): RuntimeError: DataLoader worker (pid 41) is killed by signal: Bus error。
Kaggle內(nèi)核通常看起來有些遲鈍。
結(jié)論
Colab和Kaggle都是開展云端深度學(xué)習(xí)的重要資源。我們可以同時(shí)使用兩者,例如在Kaggle和Colab之間相互下載和上傳notebook。
Colab和Kaggle會(huì)不斷更新硬件資源,我們可以通過比較硬件資源的性能,以及對(duì)編程語言的支持,選擇最優(yōu)的平臺(tái)部署代碼。例如,如果我們要運(yùn)行一個(gè)密集的PyTorch項(xiàng)目,并且期望提高精度,那么在Kaggle上開發(fā)可能更加適合。
如果我們希望更加靈活的調(diào)整batch size 的大小,Colab可能更加適用。使用Colab,我們可以將模型和數(shù)據(jù)都保存在谷歌云盤里。如果你用TensorFlow編程,那么Colab的TPU將會(huì)是一個(gè)很好的資源。
如果需要更多的時(shí)間來編寫代碼,或者代碼需要更長(zhǎng)的運(yùn)行時(shí)間,那么谷歌的云平臺(tái)的性價(jià)比可能更高。
-
谷歌
+關(guān)注
關(guān)注
27文章
6231瀏覽量
108102 -
gpu
+關(guān)注
關(guān)注
28文章
4943瀏覽量
131202 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1708瀏覽量
46766
原文標(biāo)題:免費(fèi)GPU哪家強(qiáng)?谷歌Kaggle vs. Colab
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
保證UI流暢運(yùn)行,我們需要多強(qiáng)的GPU性能?

當(dāng)我問DeepSeek國內(nèi)壓力傳感器哪家強(qiáng),它這樣回答

iTOP-3588S開發(fā)板四核心架構(gòu)GPU內(nèi)置GPU可以完全兼容0penGLES1.1、2.0和3.2。
可以手動(dòng)構(gòu)建imx-gpu-viv嗎?
在Google Colab筆記本電腦上導(dǎo)入OpenVINO?工具包2021中的 IEPlugin類出現(xiàn)報(bào)錯(cuò),怎么解決?
OpenVINO?檢測(cè)到GPU,但網(wǎng)絡(luò)無法加載到GPU插件,為什么?
工業(yè)網(wǎng)關(guān)哪家強(qiáng)?各大廠家簡(jiǎn)單測(cè)評(píng)

VS680與智慧教室解決方案

選擇DSP處理器的考慮因素(ADSP-2115 vs. TMS320C5x)

《CST Studio Suite 2024 GPU加速計(jì)算指南》

VS5700動(dòng)態(tài)信號(hào)測(cè)試分析系統(tǒng)
TI TDA2x SoC上基于GPU的環(huán)視優(yōu)化

大模型發(fā)展下,國產(chǎn)GPU的機(jī)會(huì)和挑戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論