 電子發燒友App
電子發燒友App


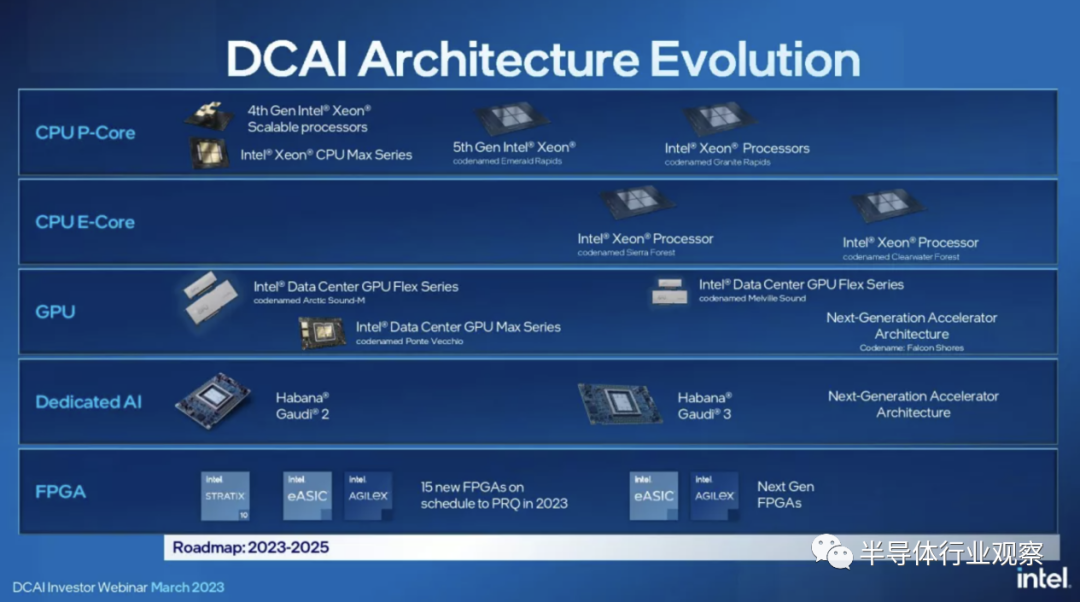
英特爾今天舉行了其數據中心和 AI 投資者網絡研討會,透露其第一代高效至強 Sierra Forest 將配備令人難以置信的 144 個內核,從而提供比 AMD 競爭的 128 核 EPYC Bergamo 芯片更高的內核密度。該公司甚至在其活動的演示中取笑了該芯片。
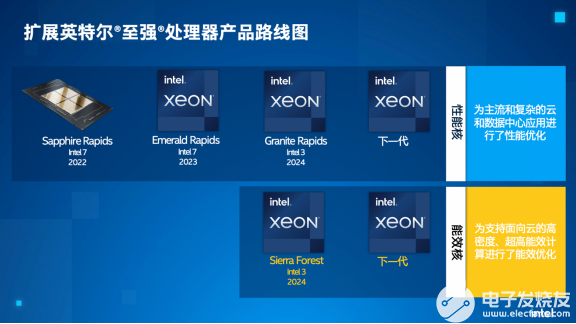
英特爾還透露了 Clearwater Forest 的第一個細節,它是將于 2025 年首次亮相的第二代至強處理器。英特爾跳過了其20A 工藝節點,為這款新芯片選擇了性能更高的 18A,這充分說明了其對其健康狀況的信心未來節點。該公司還展示了新產品和性能演示以及路線圖更新,表明該公司的 Xeon 正在按計劃推進。
英特爾還展示了幾個演示,包括針對AMD 的 EPYC Genoa 的 正面 AI 基準測試,顯示 Xeon 在兩個 48 核芯片的正面交鋒中具有 4 倍的性能優勢,以及內存吞吐量基準測試,顯示了下一代的Granite Rapids Xeon 在雙路服務器中提供令人難以置信的 1.5 TB/s 帶寬。
英特爾的披露,包括我們將在下面介紹的許多其他發展,是在該公司執行其在四年內交付五個新節點的大膽目標之際發布的,這是一個前所未有的速度,將為其廣泛的數據中心和包括 CPU 、GPU、FPGA 和Gaudi AI 加速器在內的產品組合提供動力, 。
英特爾在數據中心的性能領先地位已被 AMD 奪走,其救贖之路因Sapphire Rapids和 GPU 產品線的延遲而受阻。然而,該公司表示,它已經解決了其工藝節點技術中的根本問題,并改進了其芯片設計方法,以防止其下一代產品的進一步延遲。讓我們看看路線圖是什么樣的。
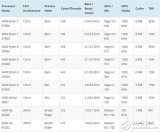
英特爾至強 CPU 數據中心路線圖
自 2022 年 2 月上次更新以來,英特爾現有至強產品的路線圖保持不變并按計劃進行,但現在有一個新進入者——Clearwater Forest。我們將在下面進一步詳細介紹該芯片。

英特爾的數據中心路線圖分為兩條泳道。P-Core(性能核心)模型是傳統的 Xeon 數據中心處理器,其核心僅可提供英特爾最快架構的全部性能。這些芯片專為實現最高的每核和 AI 工作負載性能而設計。它們還與加速器配對,正如我們在 Sapphire Rapids 中看到的那樣。

E-Core(效率核心)系列由僅具有較小效率核心的芯片組成,就像我們在英特爾的消費芯片上看到的那樣,它避開了一些功能,如 AMX 和 AVX-512,以提供更高的密度。這些芯片專為高能效、核心密度和總吞吐量而設計,對超大規模企業具有吸引力。英特爾的 Xeon 處理器不會有任何型號在同一芯片上同時具有 P 核和 E 核,因此這些是具有不同用例的不同系列。

在這里,我們可以看到英特爾的路線圖與AMD 的數據中心路線圖相比如何。當前,AMD 去年推出的 EPYC Genoa 和英特爾今年年初推出的 Sapphire Rapids 之間的高性能大戰正在激烈進行。英特爾將于今年第四季度推出其更新一代的Emerald Rapids ,該公司表示將配備更多內核和更快的時鐘速率,以及注入 HBM 的 Xeon Max CPU。AMD 的 5nm Genoa-X 產品定于今年晚些時候發布。明年,英特爾的下一代 Granite Rapids 將與 AMD 的 Turin 展開較量。
在效率泳道上,AMD 的 Bergamo 通過利用 AMD 密集的 Zen 4c 內核,采用與 Sierra Forest 非常相似的重核方法,但它將在今年上半年到貨,而英特爾的 Sierra Forrest 將在2024 年上半年到貨。AMD 沒有說它的第二代 e-core 模型什么時候到貨,但英特爾現在在 2025 年的路線圖上有它的 Clearwater Forest。
Intel E-Core Xeon CPU:
Sierra Forest 和 Clearwater Forest
英特爾的 e-core 路線圖從 144 核 Sierra Forest 開始,它將在單個雙路服務器中提供 256 個內核。第五代 Xeon Sierra Forest 的 144 個內核在內核數方面也超過了 AMD 的 128 核 EPYC Bergamo,但在線程數方面可能并不領先——英特爾面向消費市場的 e 內核是單線程的,但該公司尚未透露數據中心的電子內核是否支持超線程。相比之下,AMD 表示 128 核 Bergamo 是超線程的,因此每個插槽總共提供 256 個線程。

我們也不知道英特爾或 AMD 密集內核的性能細節,因此在芯片上市之前我們無法知道這些芯片的性能。但是,我們確實知道英特爾的 e-cores 不支持其 p-core 支持的某些 ISA;英特爾省略了 AVX-512 和 AMX 以確保最大密度,而 AMD 的 Bergamo Zen 4c 內核支持與其標準內核相同的功能。

不過,英特爾的 Sierra Forest 顯然在 2024 年上半年進展順利:Mountain Stream 系統的圖像已經在網上泄露,包括您可以在下面看到的大型LGA7529 插座的圖片。該插槽將容納 e-core Sierra Forest 和 p-core Granite Rapids 處理器。

這表明 Sierra Forest 平臺已經與英特爾的合作伙伴合作,該公司還告訴我們,它已經為芯片供電,并在不到 18 小時的時間內啟動了操作系統。該芯片是“Intel 3”工藝節點的主要載體,因此成功至關重要。英特爾有足夠的信心,它已經向客戶提供了芯片樣品,并在活動中演示了所有 144 個內核的運行情況。英特爾最初將 e-core Xeon 型號定位于特定類型的云優化工作負載,但預計一旦上市,它們將被用于更廣泛的用例。
英特爾還首次公布了Clearwater Forest。英特爾沒有透露 2025 年發布時間之外的更多細節,但確實表示它將為芯片使用 18A 工藝,而不是半年前到達的 20A 工藝節點。這將是第一款采用 18A 工藝的至強芯片。英特爾告訴我們,其工藝路線圖的壓縮性質——該公司計劃在四年內交付五個節點——使其可以選擇 2024 年到達的 18A 工藝或 2024 年下半年投入生產的 20A 工藝.
18A 節點是英特爾的第二代“Angstrom”節點,類似于 1.8nm。英特爾的第一代 Angstrom 節點,20A,將采用 RibbonFET,一種環柵 (GAA) 堆疊納米片晶體管技術,以及英特爾的 PowerVia 背面供電 (BSP) 技術。Intel 將用于 Clearwater Forest 的 18A 工藝將比 20A 的每瓦性能提高 10%,以及其他改進,因此 Intel 選擇采用該節點,因為它是該公司在Clearwater 發射的時間表。
18A工藝擁有行業未來打算采用的所有前沿技術,如GAA和BSP,因此它代表了一個非常先進的節點。英特爾聲稱 18A 節點將在其競爭對手臺積電和 AMD 中獲得明顯的工藝領先地位,而該公司決定跳過 20A 并為 Xeon 轉向 18A 無疑充分說明了其對該節點健康狀況的信心。英特爾還告訴我們,我們不會看到采用 20A 制造的 Xeon 型號。
Intel P-Core Xeon CPU:
Emerald Rapids 和 Granite Rapids
英特爾的下一代 Emerald Rapids 計劃于今年第四季度發布,鑒于 Sapphire Rapids 幾個月前推出,這是一個壓縮的時間框架。Emerald 將落入與 Sapphire Rapids 相同的平臺,從而減少客戶的驗證時間,并且在很大程度上是 Sapphire Rapids 的更新。然而,英特爾表示,它將提供比其前身更快的性能、更好的能效,更重要的是,它將提供更多的內核。英特爾表示,它擁有內部的 Emerald Rapids 硅,并且驗證正在按預期進行,硅達到或超過其性能和功率目標。
Granite Rapids 將于 2024 年抵達,緊隨 Sierra Forest。英特爾將在“Intel 3”工藝上制造這種芯片,這是“intel 4”工藝的一個大大改進版本,缺少Xeon 所需的高密度庫。這是“intel 3”上的第一個 p-core Xeon,它將具有比 Emerald Rapids 更多的內核、來自 DDR5-8800 內存的更高內存帶寬,以及其他未指定的 I/O 創新。
值得注意的是,第一個配備 E 核的系列 Sierra Forest 將與 P 核供電的 Granite Rapids 插座兼容;他們甚至共享相同的 BIOS 和軟件。英特爾通過將這些芯片轉移到 tile-based design來實現這一點,中央 I/O 塊處理內存和其他連接功能,就像我們在 AMD 的 EPYC 處理器上看到的那樣。這將核心和非核心功能分開,因此英特爾通過使用不同類型的compute tiles來創建不同的處理器類型。這提供了多種好處,例如能夠使用相同的系統將更多線程heft與 E 核打包在一起,但在與 P 核模型相同的 TDP 范圍內。
在其網絡研討會期間,英特爾演示了雙插槽 Granite Rapids,可提供驚人的 1.5 TB/s DDR5 內存帶寬;聲稱比現有服務器內存提高了 80% 的峰值帶寬。從長遠來看,Granite Rapids 提供的吞吐量高于 Nvidia 的 960 GB/s Grace CPU 超級芯片,專為內存帶寬設計,也高于 AMD 的雙路Genoa,其理論峰值為 920 GB/s。英特爾使用 DDR5-8800 多路復用器組合列 (MCR) DRAM 實現了這一壯舉,這是一種其發明的新型帶寬優化內存。英特爾已經與 SK 海力士一起推出了這款內存。
Granite Rapids 和 Sierra Forest 是英特爾最近重組其芯片設計流程的攔截點,這應該有助于避免發現該公司對 Sapphire Rapids 處理器進行多次連續步進導致進一步延遲的問題。英特爾表示,Granite Rapids 在其開發周期中比 Sapphire Rapids 在這一點上走得更遠。英特爾表示,Granite Rapids 正在實現所有工程里程碑,并且邁出了健康的第一步。因此,它現在已經在向客戶提供樣品。
英特爾的數據中心和 AI 更新專注于 Xeon,但該公司的產品組合還包括其他“配料”,如 FPGA、GPU 和專用加速器。英特爾在定制硅領域有很多競爭對手,例如谷歌的 TPU 和 Argos 視頻編碼芯片(以及許多其他公司),因此 Gaudi 加速器和 FPGA 是其產品組合的重要組成部分。英特爾表示,今年將推出 15 款新 FPGA,創下其 FPGA 集團的記錄。我們尚未聽說 Gaudi 芯片取得任何重大勝利,但英特爾確實在繼續開發其產品線,并在路線圖上推出了下一代加速器。Gaudi 2 AI加速器出貨,Gaudi 3已錄入。

英特爾還表示其 Artic Sound 和 Ponte Vecchio GPU 正在出貨,但我們并不知道后者在一般市場上有售——相反,第一批 Ponte Vecchio 型號似乎正用于經常延遲的 Aurora 超級計算機。
英特爾最近更新了其 GPU 路線圖,取消了即將推出的 Rialto Bridge 系列數據中心 Max GPU,并將數據中心 GPU 的發布周期改為兩年。該公司的下一個數據中心 GPU 產品將以Falcon Shores的形式出現??基于小芯片的混合芯片,但這些芯片要到 2025 年才會到貨。該公司還降低了對 Falcon Shores 的期望,稱它們現在將作為純 GPU 架構出現,并且不會像最初預期的那樣包括 CPU 內核選項— 那些“XPU”模型現在沒有預計的發布日期。英特爾預測,AI 工作負載將繼續主要在 CPU 上運行,所有模型中的 60%,主要是中小型模型,都在 CPU 上運行。同時,大型模型將包含大約 40% 的工作負載,并在 GPU 和其他定制加速器上運行。英特爾還致力于為 AI 構建可與 Nvidia 的 CUDA 相媲美的軟件生態系統。這還包括采用端到端的方法,在堆棧的每個點都包含芯片、軟件、安全性、機密性和信任機制。
一點思考
幾年前,英特爾就開始將其 CPU 轉向以人工智能為中心的設計,而如今人工智能通過像 ChatGPT 這樣的大型語言模型 (LLM) 進入公眾視野,證明這是一個可靠的賭注。然而,今天的 AI 格局每天都在變化。它涵蓋了一系列鮮為人知和較小的模型,因此為任何一種算法優化新芯片都是徒勞的。當芯片設計周期長達四年時,這尤其具有挑戰性——今天的許多 AI 模型當時并不存在。
我們采訪了英特爾高級研究員 Ronak Singhal,他解釋說,英特爾很久以前就選擇專注于支持人工智能的基本工作負載需求,例如計算能力、內存帶寬和內存容量,從而奠定了一個廣泛適用的基礎,可以支持任何數量的算法。英特爾還穩步擴展了對不同數據類型的支持,例如 AVX-512 及其第一代 AMX 技術,該技術現已出貨,支持 8 位整數和 bfloat16。Intel 還沒有告訴我們它的第二代 AMX 什么時候到貨,但它會支持 16 位整數,并且將來具有支持更多數據類型的擴展性。這種支持基礎使英特爾能夠在許多不同類型的 AI 工作負載中使用 Xeon 提供令人印象深刻的性能,通常超過 AMD 的 EPYC。
是的,許多 AI 模型太大而無法在 CPU 上運行,而且大多數訓練工作負載將保留在 GPU 和定制芯片領域,但較小的模型可以在 CPU 上運行——比如 Facebook 的 LlaMa,它甚至可以在 Raspberry Pi 上運行——與任何其他類型的計算相比,當今更多的推理工作負載在 CPU 上運行——包括 GPU。我們預計這種趨勢將隨著更小的推理模型繼續下去,并且英特爾通過其 P-core Xeon 路線圖為這些工作負載做好了準備。
英特爾不乏競爭對手,Arm 生態系統在數據中心的應用越來越普遍,亞馬遜的Graviton 2、阿里巴巴的倚天、微軟 Azure 中的Ampere Altra、甲骨文云和谷歌云,Nvidia 的Grace CPU、富士通和華為鯤鵬,以及谷歌的Maple 和 Cypress等等。甚至還有兩臺使用Arm Neoverse V1 芯片的百億億級超級計算機部署:SiPearl“Rhea ”和 ETRI K-AB21。
這意味著英特爾和 AMD 一樣,需要采用更注重能效和核心密度的優化芯片,以緩解向 Arm 遷移的超大規模和 CSP 的壓力。這以英特爾的 e-core Xeon 模型和 AMD 的 Bergamo 芯片的形式出現。如果 AMD 實現了它的路線圖,并且沒有理由相信它不會,它將憑借其密度優化的 Bergamo 擊敗英特爾進入市場。這可能會使英特爾在高容量(但利潤率較低)的云市場中處于劣勢。另一方面,英特爾確實計劃將其后續 Clearwater Forest 模型轉移到*可能*比 AMD 更先進的節點,從而在 2025 年展開有趣的競爭。
鑒于公司最近的歷史,英特爾在去年分享的 Xeon 路線圖中仍然堅定不移,這一事實令人鼓舞。18A 節點的加速采用也充分說明了公司更廣泛的基礎工藝技術影響其業務的各個方面。
編輯:黃飛
?
















 工商網監
工商網監
評論