 電子發(fā)燒友App
電子發(fā)燒友App


P2P技術(shù)原理
P2P技術(shù)屬于覆蓋層網(wǎng)絡(luò)(Overlay Network)的范疇,是相對(duì)于客戶機(jī)/服務(wù)器(C/S)模式來說的一種網(wǎng)絡(luò)信息交換方式。在C/S模式中,數(shù)據(jù)的分發(fā)采用專門的服務(wù)器,多個(gè)客戶端都從此服務(wù)器獲取數(shù)據(jù)。這種模式的優(yōu)點(diǎn)是:數(shù)據(jù)的一致性容易控制,系統(tǒng)也容易管理。但是此種模式的缺點(diǎn)是:因?yàn)榉?wù)器的個(gè)數(shù)只有一個(gè)(即便有多個(gè)也非常有限),系統(tǒng)容易出現(xiàn)單一失效點(diǎn);單一服務(wù)器面對(duì)眾多的客戶端,由于CPU能力、內(nèi)存大小、網(wǎng)絡(luò)帶寬的限制,可同時(shí)服務(wù)的客戶端非常有限,可擴(kuò)展性差。P2P技術(shù)正是為了解決這些問題而提出來的一種對(duì)等網(wǎng)絡(luò)結(jié)構(gòu)。在P2P網(wǎng)絡(luò)中,每個(gè)節(jié)點(diǎn)既可以從其他節(jié)點(diǎn)得到服務(wù),也可以向其他節(jié)點(diǎn)提供服務(wù)。這樣,龐大的終端資源被利用起來,一舉解決了C/S模式中的兩個(gè)弊端。
對(duì)等網(wǎng)絡(luò)的基本結(jié)構(gòu)
(1)集中式對(duì)等網(wǎng)絡(luò)(Napster、QQ)
集中式對(duì)等網(wǎng)絡(luò)基于中央目錄服務(wù)器,為網(wǎng)絡(luò)中各節(jié)目提供目錄查詢服務(wù),傳輸內(nèi)容無需再經(jīng)過中央服務(wù)器。這種網(wǎng)絡(luò),結(jié)構(gòu)比較簡(jiǎn)單,中央服務(wù)器的負(fù)擔(dān)大大降低。但由于仍存在中央節(jié)點(diǎn),容易形成傳輸瓶頸,擴(kuò)展性也比較差,不適合大型網(wǎng)絡(luò)。但由于目錄集中管理,對(duì)于小型網(wǎng)絡(luò)的管理和控制上倒是一種可選擇方案。
(2)無結(jié)構(gòu)分布式網(wǎng)絡(luò)(Gnutella)
無結(jié)構(gòu)分布式網(wǎng)絡(luò)與集中式的最顯著區(qū)別在于,它沒有中央服務(wù)器,所有結(jié)點(diǎn)通過與相鄰節(jié)點(diǎn)間的通信,接入整個(gè)網(wǎng)絡(luò)。在無結(jié)構(gòu)的網(wǎng)絡(luò)中,節(jié)點(diǎn)采用一種查詢包的機(jī)制來搜索需要的資源。具體的方式為,某節(jié)點(diǎn)將包含查詢內(nèi)容的查詢包發(fā)送到與之相鄰的節(jié)點(diǎn),該查詢包以擴(kuò)散的方式在網(wǎng)絡(luò)中蔓延,由于這樣的方式如果不加節(jié)制,會(huì)造成消息泛濫,因此一般會(huì)設(shè)置一個(gè)適當(dāng)?shù)纳鏁r(shí)間(TTL),在查詢的過程中遞減,當(dāng)TTL值為0時(shí),將不再繼續(xù)發(fā)送。
這種無結(jié)構(gòu)的方式,組織方式比較松散,節(jié)點(diǎn)的加入與離開比較自由,當(dāng)查詢熱門內(nèi)容時(shí),很容易就能找到,但如果需求的內(nèi)容比較冷門,較小的TTL不容易找到,而較大的TTL值又容易引起較大的查詢流量,尤其當(dāng)網(wǎng)絡(luò)范圍擴(kuò)展到一定規(guī)模時(shí),即使限制的TTL值較小,仍然會(huì)引起流量的劇增。但當(dāng)網(wǎng)絡(luò)中存在一些擁有豐富資源的所謂的類服務(wù)器節(jié)點(diǎn)時(shí),可顯著提高查詢的效率。
(3)結(jié)構(gòu)化分布式網(wǎng)絡(luò)(第三代P2P Pastry、Tapestry、Chord、CAN)
結(jié)構(gòu)化分布式網(wǎng)絡(luò),是近幾年基于分布式哈希表(Distributed Hash Table)技術(shù)的研究成果。它的基本思想是將網(wǎng)絡(luò)中所有的資源整理成一張巨大的表,表內(nèi)包含資源的關(guān)鍵字和所存放結(jié)點(diǎn)的地址,然后將這張表分割后分別存儲(chǔ)到網(wǎng)絡(luò)中的每一結(jié)點(diǎn)中去。當(dāng)用戶在網(wǎng)絡(luò)中搜索相應(yīng)的資源時(shí),它將能發(fā)現(xiàn)存儲(chǔ)與關(guān)鍵詞對(duì)應(yīng)的哈希表內(nèi)容所存放的結(jié)點(diǎn),在該結(jié)點(diǎn)中存儲(chǔ)了包含所需資源的結(jié)點(diǎn)地址,然后發(fā)起搜索的結(jié)點(diǎn)根據(jù)這些地址信息,與對(duì)應(yīng)結(jié)點(diǎn)連接并傳輸資源。這是一種技術(shù)上比較先進(jìn)的對(duì)等網(wǎng)絡(luò),它具有高度結(jié)構(gòu)化,高可擴(kuò)展性,結(jié)點(diǎn)的加入與離開比較自由。這種方式適合比較大型的網(wǎng)絡(luò)。
P2P網(wǎng)絡(luò)有3種比較流行的組織結(jié)構(gòu),被應(yīng)用在不同的P2P應(yīng)用中。
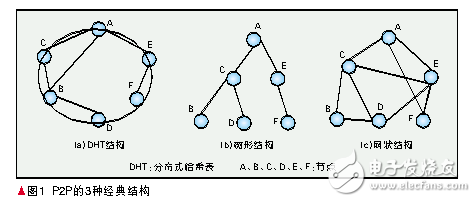
(1)DHT結(jié)構(gòu)
分布式哈希表(DHT)[1]是一種功能強(qiáng)大的工具,它的提出引起了學(xué)術(shù)界一股研究DHT的熱潮。雖然DHT具有各種各樣的實(shí)現(xiàn)方式,但是具有共同的特征,即都是一個(gè)環(huán)行拓?fù)浣Y(jié)構(gòu),在這個(gè)結(jié)構(gòu)里每個(gè)節(jié)點(diǎn)具有一個(gè)唯一的節(jié)點(diǎn)標(biāo)識(shí)(ID),節(jié)點(diǎn)ID是一個(gè)128位的哈希值。每個(gè)節(jié)點(diǎn)都在路由表里保存了其他前驅(qū)、后繼節(jié)點(diǎn)的ID。如圖1(a)所示。通過這些路由信息,可以方便地找到其他節(jié)點(diǎn)。這種結(jié)構(gòu)多用于文件共享和作為底層結(jié)構(gòu)用于流媒體傳輸[2]。
(2)樹形結(jié)構(gòu)
P2P網(wǎng)絡(luò)樹形結(jié)構(gòu)如圖1(b)所示。在這種結(jié)構(gòu)中,所有的節(jié)點(diǎn)都被組織在一棵樹中,樹根只有子節(jié)點(diǎn),樹葉只有父節(jié)點(diǎn),其他節(jié)點(diǎn)既有子節(jié)點(diǎn)也有父節(jié)點(diǎn)。信息的流向沿著樹枝流動(dòng)。最初的樹形結(jié)構(gòu)多用于P2P流媒體直播[3-4]。
(3)網(wǎng)狀結(jié)構(gòu)
網(wǎng)狀結(jié)構(gòu)如圖1(c)所示,又叫無結(jié)構(gòu)。顧名思義,這種結(jié)構(gòu)中,所有的節(jié)點(diǎn)無規(guī)則地連在一起,沒有穩(wěn)定的關(guān)系,沒有父子關(guān)系。網(wǎng)狀結(jié)構(gòu)[5]為P2P提供了最大的容忍性、動(dòng)態(tài)適應(yīng)性,在流媒體直播和點(diǎn)播應(yīng)用中取得了極大的成功。當(dāng)網(wǎng)絡(luò)變得很大時(shí),常常會(huì)引入超級(jí)節(jié)點(diǎn)的概念,超級(jí)節(jié)點(diǎn)可以和任何一種以上結(jié)構(gòu)結(jié)合起來組成新的結(jié)構(gòu),如KaZaA[6]。
P2P技術(shù)應(yīng)用
(1)分布式科學(xué)計(jì)算
P2P技術(shù)可以使得眾多終端的CPU資源聯(lián)合起來,服務(wù)于一個(gè)共同的計(jì)算。這種計(jì)算一般是計(jì)算量巨大、數(shù)據(jù)極多、耗時(shí)很長(zhǎng)的科學(xué)計(jì)算。在每次計(jì)算過程中,任務(wù)(包括邏輯與數(shù)據(jù)等)被劃分成多個(gè)片,被分配到參與科學(xué)計(jì)算的P2P節(jié)點(diǎn)機(jī)器上。在不影響原有計(jì)算機(jī)使用的前提下,人們利用分散的CPU資源完成計(jì)算任務(wù),并將結(jié)果返回給一個(gè)或多個(gè)服務(wù)器,將眾多結(jié)果進(jìn)行整合,以得到最終結(jié)果。
(2)文件共享
BitTorrent是一種無結(jié)構(gòu)的網(wǎng)絡(luò)協(xié)議。除了BitTorrent之外,還有不少著名的無結(jié)構(gòu)化的P2P文件共享協(xié)議,典型的有Gnutella[8]和KaZaA[6]。
(3)流媒體直播
(4)流媒體點(diǎn)播
(5)IP層語(yǔ)音通信
Skype采取類似KaZaA的拓?fù)浣Y(jié)構(gòu),在網(wǎng)絡(luò)中選取一些超級(jí)節(jié)點(diǎn)。在通信雙方直連效果不好時(shí),一些合適的超級(jí)節(jié)點(diǎn)則擔(dān)當(dāng)起其中轉(zhuǎn)節(jié)點(diǎn)的角色,為通信雙方創(chuàng)建中轉(zhuǎn)連接,并轉(zhuǎn)發(fā)相應(yīng)的語(yǔ)音通信包。
典型P2P應(yīng)用的機(jī)制分析
3.1BitTorrent
BitTorrent軟件用戶首先從Web服務(wù)器上獲得下載文件的種子文件,種子文件中包含下載文件名及數(shù)據(jù)部分的哈希值,還包含一個(gè)或者多個(gè)的索引(Tracker)服務(wù)器地址。它的工作過程如下:客戶端向索引服務(wù)器發(fā)一個(gè)超文本傳輸協(xié)議(HTTP)的GET請(qǐng)求,并把它自己的私有信息和下載文件的哈希值放在GET的參數(shù)中;索引服務(wù)器根據(jù)請(qǐng)求的哈希值查找內(nèi)部的數(shù)據(jù)字典,隨機(jī)地返回正在下載該文件的一組節(jié)點(diǎn),客戶端連接這些節(jié)點(diǎn),下載需要的文件片段。因此可以將索引服務(wù)器的文件下載過程簡(jiǎn)單地分成兩個(gè)部分:與索引服務(wù)器通信的HTTP,與其他客戶端通信并傳輸數(shù)據(jù)的協(xié)議,我們稱為BitTorrent對(duì)等協(xié)議。BitTorrent軟件的工作原理如圖 4所示。BitTorrent協(xié)議也處在不斷變化中,可以通過數(shù)據(jù)報(bào)協(xié)議(UDP)和DHT的方法獲得可用的傳輸節(jié)點(diǎn)信息,而不是僅僅通過原有的 HTTP,這種方法使得BitTorrent應(yīng)用更加靈活,提高BitTorrent用戶的下載體驗(yàn)。

3.2eMule
eMule軟件基于eDonkey協(xié)議改進(jìn)后的協(xié)議,同時(shí)兼容eDonkey協(xié)議。每個(gè)eMule客戶端都預(yù)先設(shè)置好了一個(gè)服務(wù)器列表和一個(gè)本地共享文件列表,客戶端通過TCP連接到eMule服務(wù)器進(jìn)行登錄,得到想要的文件的信息以及可用的客戶端的信息。一個(gè)客戶端可以從多個(gè)其他的EMule客戶端下載同一個(gè)文件,并從不同的客戶端取得不同的數(shù)據(jù)片段。eMule同時(shí)擴(kuò)展了eDonkey的能力,允許客戶端之間互相交換關(guān)于服務(wù)器、其他客戶端和文件的信息。eMule服務(wù)器不保存任何文件,它只是文件位置信息的中心索引。eMule客戶端一啟動(dòng)就會(huì)自動(dòng)使用傳輸控制協(xié)議 (TCP)連接到eMule服務(wù)器上。服務(wù)器給客戶端提供一個(gè)客戶端標(biāo)識(shí)(ID),它僅在客戶端服務(wù)器連接的生命周期內(nèi)有效。連接建立后,客戶端把其共享的文件列表發(fā)送給服務(wù)器。服務(wù)器將這個(gè)列表保存在內(nèi)部數(shù)據(jù)庫(kù)內(nèi)。eMule客戶端也會(huì)發(fā)送請(qǐng)求下載列表。連接建立以后,eMule服務(wù)器給客戶端返回一個(gè)列表,包括哪些客戶端可以提供請(qǐng)求文件的下載。然后,客戶端再和它們主動(dòng)建立連接下載文件。圖5所示為eMule的工作原理。

eMule基本原理與BitTorrent類似,客戶端通過索引服務(wù)器獲得文件下載信息。eMule同時(shí)允許客戶端之間傳遞服務(wù)器信息,BitTorrent只能通過索引服務(wù)器或者DHT獲得。eMule共享的是整個(gè)文件目錄,而BitTorrent只共享下載任務(wù),這使得 BitTorrent更適合分發(fā)熱門文件,eMule傾向于一般熱門文件的下載。
3.3迅雷
迅雷是一款新型的基于多資源多線程技術(shù)的下載軟件,迅雷擁有比目前用戶常用的下載軟件快7~10倍的下載速度。迅雷的技術(shù)主要分成兩個(gè)部分,一部分是對(duì)現(xiàn)有Internet下載資源的搜索和整合,將現(xiàn)有Internet上的下載資源進(jìn)行校驗(yàn),將相同校驗(yàn)值的統(tǒng)一資源定位(URL)信息進(jìn)行聚合。當(dāng)用戶點(diǎn)擊某個(gè)下載連接時(shí),迅雷服務(wù)器按照一定的策略返回該URL信息所在聚合的子集,并將該用戶的信息返回給迅雷服務(wù)器。另一部分是迅雷客戶端通過多資源多線程下載所需要的文件,提高下載速率。迅雷高速穩(wěn)定下載的根本原因在于同時(shí)整合多個(gè)穩(wěn)定服務(wù)器的資源實(shí)現(xiàn)多資源多線程的數(shù)據(jù)傳輸。多資源多線程技術(shù)使得迅雷在不降低用戶體驗(yàn)的前提下,對(duì)服務(wù)器資源進(jìn)行均衡,有效降低了服務(wù)器負(fù)載。
每個(gè)用戶在網(wǎng)上下載的文件都會(huì)在迅雷的服務(wù)器中進(jìn)行數(shù)據(jù)記錄,如有其他用戶再下載同樣的文件,迅雷的服務(wù)器會(huì)在它的數(shù)據(jù)庫(kù)中搜索曾經(jīng)下載過這些文件的用戶,服務(wù)器再連接這些用戶,通過用戶已下載文件中的記錄進(jìn)行判斷,如用戶下載文件中仍存在此文件(文件如改名或改變保存位置則無效),用戶將在不知不覺中扮演下載中間服務(wù)角色,上傳文件。









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論