 電子發燒友App
電子發燒友App


P2P技術原理
P2P技術屬于覆蓋層網絡(Overlay Network)的范疇,是相對于客戶機/服務器(C/S)模式來說的一種網絡信息交換方式。在C/S模式中,數據的分發采用專門的服務器,多個客戶端都從此服務器獲取數據。這種模式的優點是:數據的一致性容易控制,系統也容易管理。但是此種模式的缺點是:因為服務器的個數只有一個(即便有多個也非常有限),系統容易出現單一失效點;單一服務器面對眾多的客戶端,由于CPU能力、內存大小、網絡帶寬的限制,可同時服務的客戶端非常有限,可擴展性差。P2P技術正是為了解決這些問題而提出來的一種對等網絡結構。在P2P網絡中,每個節點既可以從其他節點得到服務,也可以向其他節點提供服務。這樣,龐大的終端資源被利用起來,一舉解決了C/S模式中的兩個弊端。
對等網絡的基本結構
(1)集中式對等網絡(Napster、QQ)
集中式對等網絡基于中央目錄服務器,為網絡中各節目提供目錄查詢服務,傳輸內容無需再經過中央服務器。這種網絡,結構比較簡單,中央服務器的負擔大大降低。但由于仍存在中央節點,容易形成傳輸瓶頸,擴展性也比較差,不適合大型網絡。但由于目錄集中管理,對于小型網絡的管理和控制上倒是一種可選擇方案。
(2)無結構分布式網絡(Gnutella)
無結構分布式網絡與集中式的最顯著區別在于,它沒有中央服務器,所有結點通過與相鄰節點間的通信,接入整個網絡。在無結構的網絡中,節點采用一種查詢包的機制來搜索需要的資源。具體的方式為,某節點將包含查詢內容的查詢包發送到與之相鄰的節點,該查詢包以擴散的方式在網絡中蔓延,由于這樣的方式如果不加節制,會造成消息泛濫,因此一般會設置一個適當的生存時間(TTL),在查詢的過程中遞減,當TTL值為0時,將不再繼續發送。
這種無結構的方式,組織方式比較松散,節點的加入與離開比較自由,當查詢熱門內容時,很容易就能找到,但如果需求的內容比較冷門,較小的TTL不容易找到,而較大的TTL值又容易引起較大的查詢流量,尤其當網絡范圍擴展到一定規模時,即使限制的TTL值較小,仍然會引起流量的劇增。但當網絡中存在一些擁有豐富資源的所謂的類服務器節點時,可顯著提高查詢的效率。
(3)結構化分布式網絡(第三代P2P Pastry、Tapestry、Chord、CAN)
結構化分布式網絡,是近幾年基于分布式哈希表(Distributed Hash Table)技術的研究成果。它的基本思想是將網絡中所有的資源整理成一張巨大的表,表內包含資源的關鍵字和所存放結點的地址,然后將這張表分割后分別存儲到網絡中的每一結點中去。當用戶在網絡中搜索相應的資源時,它將能發現存儲與關鍵詞對應的哈希表內容所存放的結點,在該結點中存儲了包含所需資源的結點地址,然后發起搜索的結點根據這些地址信息,與對應結點連接并傳輸資源。這是一種技術上比較先進的對等網絡,它具有高度結構化,高可擴展性,結點的加入與離開比較自由。這種方式適合比較大型的網絡。
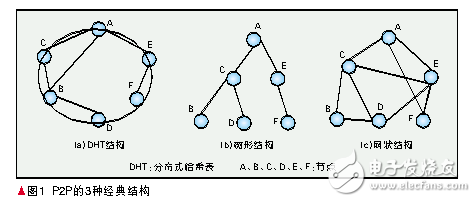
P2P網絡有3種比較流行的組織結構,被應用在不同的P2P應用中。
(1)DHT結構
分布式哈希表(DHT)[1]是一種功能強大的工具,它的提出引起了學術界一股研究DHT的熱潮。雖然DHT具有各種各樣的實現方式,但是具有共同的特征,即都是一個環行拓撲結構,在這個結構里每個節點具有一個唯一的節點標識(ID),節點ID是一個128位的哈希值。每個節點都在路由表里保存了其他前驅、后繼節點的ID。如圖1(a)所示。通過這些路由信息,可以方便地找到其他節點。這種結構多用于文件共享和作為底層結構用于流媒體傳輸[2]。
(2)樹形結構
P2P網絡樹形結構如圖1(b)所示。在這種結構中,所有的節點都被組織在一棵樹中,樹根只有子節點,樹葉只有父節點,其他節點既有子節點也有父節點。信息的流向沿著樹枝流動。最初的樹形結構多用于P2P流媒體直播[3-4]。
(3)網狀結構
網狀結構如圖1(c)所示,又叫無結構。顧名思義,這種結構中,所有的節點無規則地連在一起,沒有穩定的關系,沒有父子關系。網狀結構[5]為P2P提供了最大的容忍性、動態適應性,在流媒體直播和點播應用中取得了極大的成功。當網絡變得很大時,常常會引入超級節點的概念,超級節點可以和任何一種以上結構結合起來組成新的結構,如KaZaA[6]。
P2P技術應用
(1)分布式科學計算
P2P技術可以使得眾多終端的CPU資源聯合起來,服務于一個共同的計算。這種計算一般是計算量巨大、數據極多、耗時很長的科學計算。在每次計算過程中,任務(包括邏輯與數據等)被劃分成多個片,被分配到參與科學計算的P2P節點機器上。在不影響原有計算機使用的前提下,人們利用分散的CPU資源完成計算任務,并將結果返回給一個或多個服務器,將眾多結果進行整合,以得到最終結果。
(2)文件共享
BitTorrent是一種無結構的網絡協議。除了BitTorrent之外,還有不少著名的無結構化的P2P文件共享協議,典型的有Gnutella[8]和KaZaA[6]。
(3)流媒體直播
(4)流媒體點播
(5)IP層語音通信
Skype采取類似KaZaA的拓撲結構,在網絡中選取一些超級節點。在通信雙方直連效果不好時,一些合適的超級節點則擔當起其中轉節點的角色,為通信雙方創建中轉連接,并轉發相應的語音通信包。
典型P2P應用的機制分析
3.1BitTorrent
BitTorrent軟件用戶首先從Web服務器上獲得下載文件的種子文件,種子文件中包含下載文件名及數據部分的哈希值,還包含一個或者多個的索引(Tracker)服務器地址。它的工作過程如下:客戶端向索引服務器發一個超文本傳輸協議(HTTP)的GET請求,并把它自己的私有信息和下載文件的哈希值放在GET的參數中;索引服務器根據請求的哈希值查找內部的數據字典,隨機地返回正在下載該文件的一組節點,客戶端連接這些節點,下載需要的文件片段。因此可以將索引服務器的文件下載過程簡單地分成兩個部分:與索引服務器通信的HTTP,與其他客戶端通信并傳輸數據的協議,我們稱為BitTorrent對等協議。BitTorrent軟件的工作原理如圖 4所示。BitTorrent協議也處在不斷變化中,可以通過數據報協議(UDP)和DHT的方法獲得可用的傳輸節點信息,而不是僅僅通過原有的 HTTP,這種方法使得BitTorrent應用更加靈活,提高BitTorrent用戶的下載體驗。

3.2eMule
eMule軟件基于eDonkey協議改進后的協議,同時兼容eDonkey協議。每個eMule客戶端都預先設置好了一個服務器列表和一個本地共享文件列表,客戶端通過TCP連接到eMule服務器進行登錄,得到想要的文件的信息以及可用的客戶端的信息。一個客戶端可以從多個其他的EMule客戶端下載同一個文件,并從不同的客戶端取得不同的數據片段。eMule同時擴展了eDonkey的能力,允許客戶端之間互相交換關于服務器、其他客戶端和文件的信息。eMule服務器不保存任何文件,它只是文件位置信息的中心索引。eMule客戶端一啟動就會自動使用傳輸控制協議 (TCP)連接到eMule服務器上。服務器給客戶端提供一個客戶端標識(ID),它僅在客戶端服務器連接的生命周期內有效。連接建立后,客戶端把其共享的文件列表發送給服務器。服務器將這個列表保存在內部數據庫內。eMule客戶端也會發送請求下載列表。連接建立以后,eMule服務器給客戶端返回一個列表,包括哪些客戶端可以提供請求文件的下載。然后,客戶端再和它們主動建立連接下載文件。圖5所示為eMule的工作原理。

eMule基本原理與BitTorrent類似,客戶端通過索引服務器獲得文件下載信息。eMule同時允許客戶端之間傳遞服務器信息,BitTorrent只能通過索引服務器或者DHT獲得。eMule共享的是整個文件目錄,而BitTorrent只共享下載任務,這使得 BitTorrent更適合分發熱門文件,eMule傾向于一般熱門文件的下載。
3.3迅雷
迅雷是一款新型的基于多資源多線程技術的下載軟件,迅雷擁有比目前用戶常用的下載軟件快7~10倍的下載速度。迅雷的技術主要分成兩個部分,一部分是對現有Internet下載資源的搜索和整合,將現有Internet上的下載資源進行校驗,將相同校驗值的統一資源定位(URL)信息進行聚合。當用戶點擊某個下載連接時,迅雷服務器按照一定的策略返回該URL信息所在聚合的子集,并將該用戶的信息返回給迅雷服務器。另一部分是迅雷客戶端通過多資源多線程下載所需要的文件,提高下載速率。迅雷高速穩定下載的根本原因在于同時整合多個穩定服務器的資源實現多資源多線程的數據傳輸。多資源多線程技術使得迅雷在不降低用戶體驗的前提下,對服務器資源進行均衡,有效降低了服務器負載。
每個用戶在網上下載的文件都會在迅雷的服務器中進行數據記錄,如有其他用戶再下載同樣的文件,迅雷的服務器會在它的數據庫中搜索曾經下載過這些文件的用戶,服務器再連接這些用戶,通過用戶已下載文件中的記錄進行判斷,如用戶下載文件中仍存在此文件(文件如改名或改變保存位置則無效),用戶將在不知不覺中扮演下載中間服務角色,上傳文件。
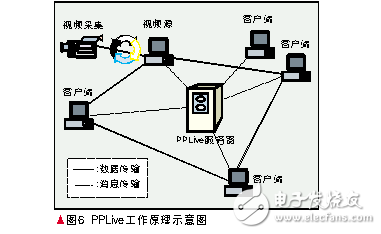
3.4PPLive
PPLive軟件的工作機制和BitTorrent十分類似,PPLive將視頻文件分成大小相等的片段,第三方提供播放的視頻源,用戶啟礬PPLive 以后,從PPLive服務器獲得頻道的列表,用戶點擊感興趣的頻道,然后從其他節點獲得數據文件,使用流媒體實時傳輸協議(RTP)和實時傳輸控制協議 (RTCP)進行數據的傳輸和控制。將數據下載到本地主機后,開放本地端口作為視頻服務器,PPLive的客戶端播放器連接此端口,任何同一個局域網內的用戶都可以通過連接這個地址收看到點播的節目。圖6所示為PPLive的工作原理示意圖。
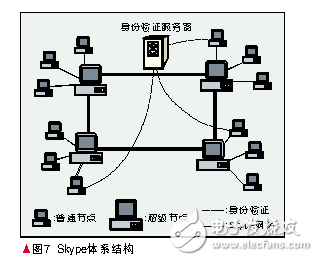
3.5Skype
Skype是網絡語音溝通工具。它可以提供免費高清晰的語音對話,也可以用來撥打國內國際長途,還具備即時通訊所需的其他功能,比如文件傳輸、文字聊天等。Skype是在KaZaA的基礎上開發的,就像KaZaA一樣,Skype本身也是基于覆蓋層的P2P網絡,在它里面有兩種類型的節點:普通節點和超級節點。普通節點是能傳輸語音和消息的一個功能實體;超級節點則類似于普通節點的網絡網關,所有的普通節點必須與超級節點連接,并向Skype的登陸服務器注冊它自己來加入Skype網絡。Skype的登陸服務器上存有用戶名和密碼,并且授權特定的用戶加入Skype網絡,圖7所示為Skype的體系結構 [18]。
Skype的另一個突出特點就是能夠穿越地址轉換設備和防火墻。Skype能夠在最小傳輸帶寬32 kb/s的網絡上提供高質量的語音。Skype是使用P2P語音服務的代表。由于其具有超清晰語音質量、極強的穿透防火墻能力、免費多方通話以及高保密性等優點,成為互聯網上使用最多的P2P應用之一。
P2P運營模式
目前主要P2P業務的運營模式主要有以下幾種:
(1)Skype模式
Skype是互聯網上最流行的P2P VoIP系統。目前Skype采取的模式是基本服務免費(如網內話音通話),而增值服務收費,收費的服務包括:
SkypeOut:通過Skype軟件呼叫固網或移動網電話。
SkypeIn:為用戶提供一個真實的電話號碼,用戶可在世界上任何地方通過該號碼接聽電話。
SkypeZone服務:全球18000個無線局域網(WLAN)熱點,使用電腦或WLAN電話接入。
增值應用服務:語音郵箱、Skype話機、鈴聲/圖片下載等。
(2)廣告模式
這是P2P服務采用的最為廣泛的贏利模式,也是互聯網業務的主要贏利模式。從早期的Napster,到最近比較流行的P2P流媒體業務,如PPlive、UUsee等,都主要采用這種模式,至少是以這種模式為主。
由于P2P應用系統對于服務端的資源需求較少,整個P2P運營系統的成本較低,因此,這種模式在相當一段時間內是主流的贏利模式。
(3)Popular Power和Data Synapse模式
Popular Power[1]公司大量收集處于工作間隙的PC的閑置計算能力,通過集群技術產生超級計算能力,供高強度計算工作和大型研究項目使用。在Popular Power的模式中,用戶被要求在他們的PC上安裝一個特制的屏幕保護程序。當屏保運行時,Popular Power就會向這些用戶的PC分配工作負載。用戶每月將收到一定數額的報酬作為對他們的閑置計算資源的使用費。我們可以把Popular Power模式稱為“商販模式”——通過販賣個人計算機的閑置資源來獲取利潤。
DataSynapse公司贏利的方法是“網格計算”,它把成千上萬臺計算機連接起來,利用它們的閑散資源組成一個虛擬的超級計算機。表面上看,DataSynapse模式和Popular Power模式并沒有什么不同——都是在販賣空閑的計算機資源。但是DataSynapse將“網格計算”構建在合作企業之間的內部網 (Intranet)上,而不是互聯網(Internet)上。這樣,一方面,可以解決互聯網的帶寬狹窄、安全性較差的問題;另一方面把目標用戶定位在企業用戶中,有較大的贏利把握。
(4)Lightshare模式
Lightshare的贏利方法是在P2P網絡上開展電子商務。用戶可以在P2P網絡上購買或出售商品。用戶可以搜尋待售商品信息或者列出自己欲售商品的信息。待售的商品保留在出售者的計算機里,但中心服務器上動態地保存該商品的相關信息,以供其他用戶查詢。在Lightshare開展的服務中,初期的交易商品只包括數字文件,但是以后將逐漸擴展到其他領域。這種贏利模式目前存在著管理、計費、安全等方面的困難。
現有P2P技術主要涉及的領域和發展方向
(1)提供文件和其它內容共享的P2P網絡,例如Napster、Gnotella、Freenet、CAN、eDonkey、eMule、BitTorrent等。
(2)基于P2P方式的協同處理與服務共享平臺,例如JXTA、Magi、Groove、.NETMy Service等。
(3)即時通訊交流,包括ICQ、OICQ、Yahoo Messenger等。
(4)安全的P2P通訊與信息共享,利用P2P無中心的特性可以為隱私保護和匿名通訊提供新的技術手段。例如CliqueNet、Crowds、Onion Routing等。
(5)語音與流媒體:由于P2P技術的使用,大量的用戶同時訪問流媒體服務器,也不會造成服務器因負載過重而癱瘓。例如Skype、Coolstream、AnyChat等。
(6)網格計算,挖掘P2P分布計算能力。使用P2P技術以集中那些聯接在網絡上的電腦的空閑的CPU時間片斷、內存空間、硬盤空間來替代“超級計算機”。例如SETI@home、Avaki、Popular Power、distributed.net等。網格計算的宗旨是:將遍布全球的數以萬計的計算節點通過高速Internet連接并組織成一個巨系統,使其能夠透明、高效地完成復雜計算任務。
(7)IBM、微軟、Ariba也在合作開展一個名為UDDI的項目以將B2B電子商務標準化
(8)Eazel正在建立下一代的Linux桌面。
(9)Jabber已經開發了一種基于XML、開放的即時訊息標準,Jabber被認為是建立了未來使用P2P數據交換的標準。
(10)Lotus Notes的開發者創建的Groove試圖“幫助人們以全新的方式溝通”。
(11)英特爾也在推廣它的P2P技術以幫助更有效地使用芯片的計算能力。
(三) P2P資源定位方式
P2P網絡中進行資源定位是首先要解決問題。一般采用三種方式:
(1)集中方式索引
每一個節點將自身能夠提供共享的內容注冊到一個或幾個集中式的目錄服務器中。查找資源時首先通過服務器定位,然后兩個節點之間再直接通訊。例如早期的Napster。這類網絡實現簡單,但往往需要大的目錄服務器的支持,并且系統的健壯性不好。
(2)廣播方式
沒有任何索引信息,內容提交與內容查找都通過相鄰接節點直接廣播傳遞。例如Gnutella。一般情況下,采取這種方式的P2P網絡對參與節點的帶寬要求比較高。
(3)動態哈希表的方式
上述兩種定位方式可以依據不同的P2P應用環境進行選擇,但是人們普遍看好DHT(Distributed Hash Table,分散式雜湊表)方式。基于DHT的P2P網絡在一定程度上可以直接實現內容的定位。一個矛盾的問題是:如果一個節點提供共享的內容表示越復雜,則哈希函數越不好選擇;相應的,網絡的拓撲結構就越復雜。而如果內容表示簡單,則又達不到真正實現依據內容定位的能力。目前大多數DHT方式的P2P網絡對節點所提供共享內容的表示都很簡單,一般僅僅為文件名。









 工商網監
工商網監
評論