使用 C 語言的OpenCL 2a并行編程擴展來補充基于 FPGA 的 CNN 加速應用程序的開發。適用于卷積神經網絡的 FPGA 器件的一個示例是英特爾可編程解決方案集團 (PSG)的Arria 10系列器件,其正式名稱為Altera。
2022-08-02 15:13:16 2607
2607 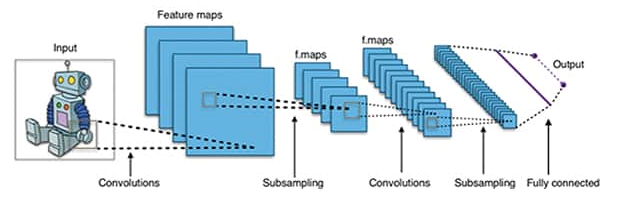
現場可編程門陣列(FPGA)具有低功耗、高性能和靈活性的特點。FPGA神經網絡加速的研究正在興起,但大多數研究都基于國外的FPGA器件。為了改善國內FPGA的現狀,提出了一種新型的卷積神經網絡加速器
2023-08-21 10:30:011800 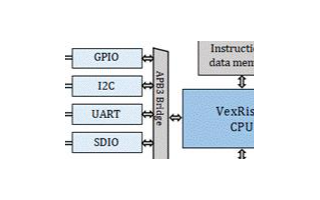
相比GPU和GPP,FPGA在滿足深度學習的硬件需求上提供了具有吸引力的替代方案。憑借流水線并行計算的能力和高效的能耗,FPGA將在一般的深度學習應用中展現GPU和GPP所沒有的獨特優勢。同時,算法
2016-07-28 12:16:387349 在今年的世界超算大會 SC16 上, Intel 發布了針對 AI 開發者的深度學習推理加速器,對卷積神經網絡的計算提供更強大支持。
2016-11-18 14:17:23610 
數據中心采用FPGA做加速器已經成為主流,像MS的Catapult,Amazon基于Xilinx FPGA的AWS F1,Intel的Altera,Baidu公司等
2017-10-16 11:49:248560 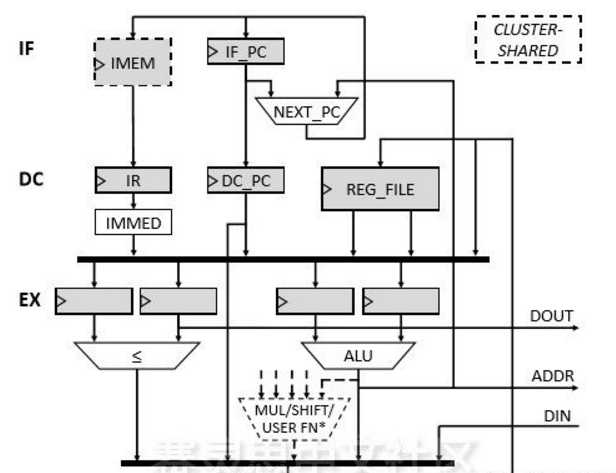
前言 做深度學習加速器已經兩年了,從RTL設計到仿真驗證,以及相應的去了解了Linux驅動,深度學習壓縮方法等等。今天來捋一捋AI加速器都涉及到哪些領域,需要哪些方面的知識。可以用于AI加速器
2020-10-10 16:25:433349 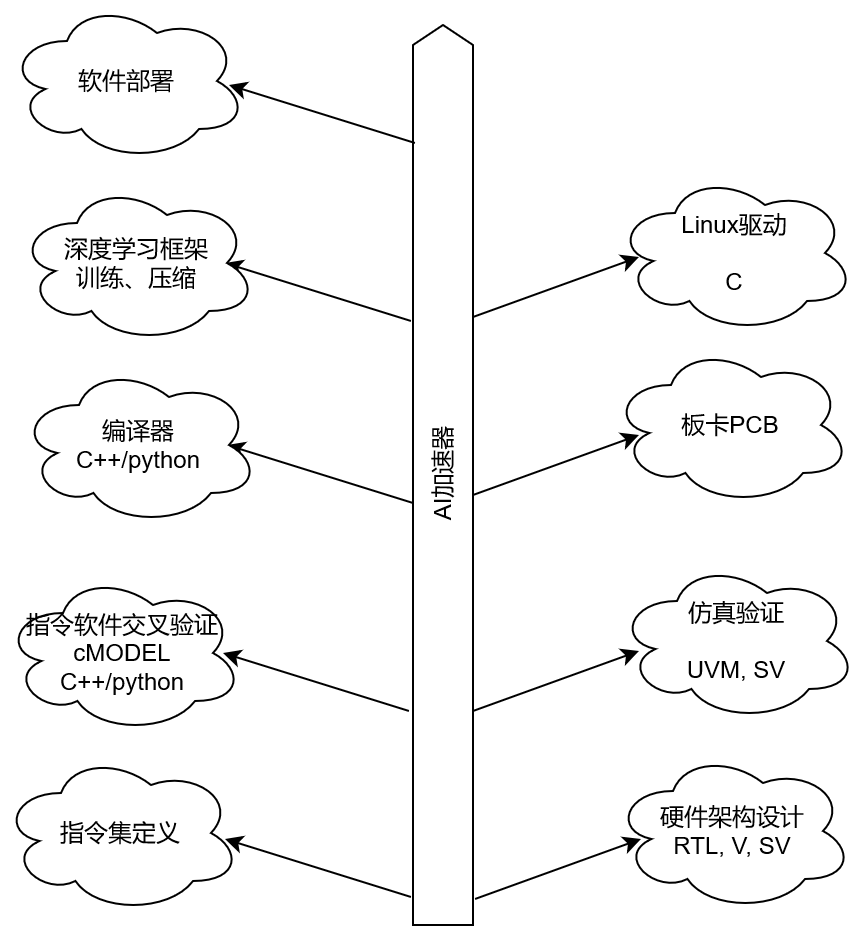
深度學習與圖神經網絡學習分享:CNN 經典網絡之-ResNet resnet 又叫深度殘差網絡 圖像識別準確率很高,主要作者是國人哦 深度網絡的退化問題 深度網絡難以訓練,梯度消失,梯度爆炸
2022-10-12 09:54:42684 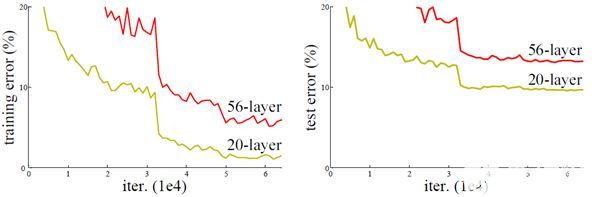
MAX78000是一款具有超低功耗CNN加速器的AI微控制器,這是一種先進的片上系統。它能夠以超低功耗為資源受限的邊緣設備或物聯網應用提供神經網絡。
2023-11-24 09:22:38216 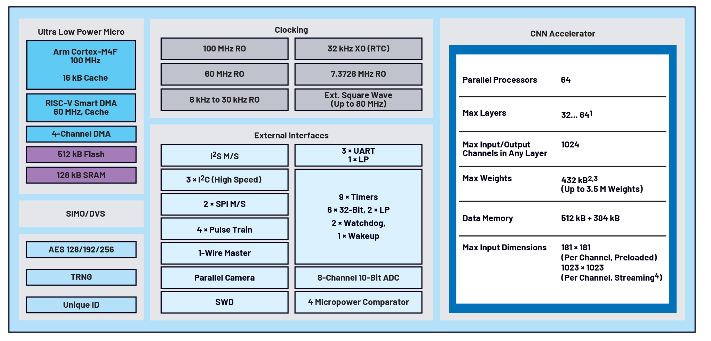
本文提出了一種更高效、更通用的卷積加速器。提出的加速器峰值性能達到153.6GOP/s,僅占用14K LUT、32個DRM和208個APM。
2022-11-18 11:07:10661 目前在用21489內部的IIR加速器去做一個低通濾波器,在例程的基礎上修改參數。通過平板的fda 工具工具去設計參數,但是設計出來的參數不知道如何對應加速器的濾波參數,手冊里也看得不是很明白。
設計的參數如下:
請問這些參數應該如何對應起來?
2023-11-30 08:11:55
。很顯然,第二個方案需要很高的技術門檻。對于FPGA加速器來說,如果要把可重配置作為賣點,要么是賣給有能力自己開發FPGA的企業用戶(如百度,微軟等公司確實有在開發基于FPGA的深度學習加速器并且在
2016-12-15 19:21:50
,這使得它比一般處理器更高效。但是,很難對 FPGA 進行編程,Larzul 希望通過自己公司開發的新平臺解決這個問題。
專業的人工智能硬件已經成為了一個獨立的產業,但對于什么是深度學習算法的最佳
2024-03-21 15:19:45
一天,建議參賽者提前提交設計方案,以給評委充足的時間評選方案。設計方案提交到FPGA版塊的“FPGA設計大賽”主題分類下。對于設計代碼,如果參賽者為了防止別人抄襲,建議參賽者將設計代碼設置為“僅作者可見”。但方案截止日期后,需要所有設置為可見,方便評委評選、論壇會員學習討論。
2012-05-04 10:27:46
一:深度學習DeepLearning實戰時間地點:1 月 15日— 1 月18 日二:深度強化學習核心技術實戰時間地點: 1 月 27 日— 1 月30 日(第一天報到 授課三天;提前環境部署 電腦
2021-01-09 17:01:54
嵌入式開發和平臺抽象;在TI硬件上實現用于加速CNN的高度優化的內核,以及支持從開放框架(如Caffe和TensorFlow)到使用TIDL應用程序編程界面的嵌入式框架進行網絡轉換的轉換器。有關此解決方案的更多詳細信息,請閱讀白皮書“TIDL:嵌入式低功耗深度學習,” 并查看其它資源中的視頻。
2019-03-13 06:45:03
。如上所述種種設計挑戰的存在,使得業界急需一種可以支持高度并發實時計算、巨大內存容量和帶寬、以及在數據中心范圍可擴展的GNN加速解決方案。5.GNN加速器的FPGA設計方案Achronix公司推出
2021-07-07 08:00:00
H.264解碼器中CABAC硬件加速器怎么實現?
2021-06-07 06:48:58
英特爾媒體加速器參考軟件是用于數字標志、交互式白板(IWBs)和亭位使用模型的參考媒體播放器應用軟件,它利用固定功能硬件加速來提高媒體流速、改進工作量平衡和資源利用,以及定制的圖形處理股(GPU)管道解決方案。該用戶指南將介紹和解釋如何使用英特爾媒體加速器視窗參考軟件。
2023-08-04 07:07:34
快速的部署到TI嵌入式平臺。 TDA4擁有TI最新一代的深度學習加速模塊C7x DSP與MMA矩陣乘法加速器,可以運行TIDL進行卷積等基本計算,從而快速地進行前向推理,得到計算結果。 當深度學習遇上
2022-11-03 06:53:11
AI加速器設計的學習和一些思考
致謝
首先感謝電子發燒友論壇提供的書籍
然后為該書打個廣告吧,32K的幅面,非常小巧方便,全彩印刷,質量精良,很有質感。
前言
設計神經網絡首先要考慮的幾個問題
2023-09-16 11:11:01
首先感謝電子發燒友論壇提供的書籍和閱讀評測的機會。
拿到書,先看一下封面介紹。這本書的中文名是《AI加速器架構設計與實現》,英文名是Accelerator Based on CNN Design
2023-09-17 16:39:45
項目名稱:基于深度學習的目標檢測系統設計試用計劃:嘗試在硬件平臺實現對Yolo卷積神經網絡的加速運算,期望提出的方法能夠使目標檢測技術更便捷,運用領域更廣泛。針對課題的研究一是研究基于開發板低功耗
2020-09-25 10:11:49
經驗總結圖解NPU算法、架構與實現,從零設計產品級加速器當前,ChatGPT和自動駕駛等技術正在為人類社會帶來巨大的生產力變革,其中基于深度學習和增強學習的AI計算扮演著至關重要的角色。新的計算范式需要
2023-07-28 10:50:51
的固定架構之外進行模型優化探究。同時,FPGA在單位能耗下性能更強,這對大規模服務器部署或資源有限的嵌入式應用的研究而言至關重要。本文從硬件加速的視角考察深度學習與FPGA,指出有哪些趨勢和創新使得
2018-08-13 09:33:30
擴展到數據中心的GNN加速解決方案。基于FPGA設計方案的GNN加速器Achronix的Speedster?7t系列FPGA產品(以及該系列的第一款器件AC7t1500)是針對數據中心和機器學習工作負載
2021-09-25 17:20:41
都出現了重大突破。深度學習是這些領域中所最常使用的技術,也被業界大為關注。然而,深度學習模型需要極為大量的數據和計算能力,只有更好的硬件加速條件,才能滿足現有數據和模型規模繼續擴大的需求。 FPGA
2019-10-10 06:45:41
上述分類之外,還被用于多項任務(下面顯示了四個示例)。在 FPGA 上進行深度學習的好處我們已經提到,許多服務和技術都使用深度學習,而 GPU 大量用于這些計算。這是因為矩陣乘法作為深度學習中的主要
2023-02-17 16:56:59
您好!當我使用ADSP-21489的fir加速器時,存在很大的噪音,未知如何解決,希望這里有高人幫我解決。
附件上有工程,該工程參考iir加速器使用例子編寫。
2023-11-30 07:49:32
介紹使用 AMD-Xilinx FPGA設計一個全連接DNN核心現在比較容易(Vitis AI),但是利用這個核心在 DNN 計算中使用它是另一回事。本項目主要是設計AI加速器,利用Xilinx
2023-02-21 15:01:58
各位TI 的工程師:
? ? ?我最近在研究NETCP網絡加速器的使用,我想做的是電腦通過網線連接到NETCP加速器實現與DSP之間的通信,傳輸協議依次為tcp、IPV4,請問有沒有相關的例子可用
2018-06-21 10:15:40
關于長整加速器的工作步驟:1. 系統置位后,CPU向加速器的源地址寄存器發送當前長整計算的源操作數地址(位于Memory中)2. 接著,CPU向加速器的目標地址寄存器發送當前長整計算的目標操作數地址
2018-03-17 10:53:37
華為FPGA加速云服務器讓“硬用”上云成為新增長點隨著通信和互聯網產業的快速發展,FPGA作為高性能計算加速器在大數據、深度學習、圖像視頻處理、基因計算、金融分析和加解密等眾多領域得到廣泛應用,市場空間巨大。
2019-10-22 07:12:32
區定制創新方案,助力科技加速與產業升級;注重本土產業與國際市場的合作,通過全球化布局幫助國外先進技術在國內落地,以及國內項目在國外推廣和落地。
權益介紹
為助力第九屆中國硬件創新創客大賽,安創加速器將為
2023-08-18 14:37:37
占比達52%,歷屆參賽項目累計估值200億。近日,第八屆硬創賽與安創加速器達成戰略合作。安創加速器作為Arm全球唯一加速器,依托于Arm全球龐大的生態系統資源及行業領先的技術,通過創業加速和創新賦能為
2022-06-22 17:34:34
【深度學習】卷積神經網絡CNN
2020-06-14 18:55:37
(FPGA)來構建硬件加速電路,來提升計算CNN的性能。
其中 ASIC 具備高性能、低功耗等特點,但 ASIC 的設計周期長,制造成本高,而 GPU 的并行度高,計算速度快,具有深度流水線結構,非常
2023-06-20 19:45:12
上學時做的變頻器設計方案,利用simulink仿真,基于FPGA的變頻器設計方案。
2014-09-10 10:40:12
方案。這里介紹一種MEMS器件微加速度計的數據采集設計方案,結合當前應用廣泛的處理芯片ARM和FPGA,給出了一種配置靈活、通用性強的數據采集方案。實驗中可準確采集美新加速度計MXR6150G/M
2020-11-25 06:17:24
隨著arm生態系統的發展壯大,各種各樣的應用場景層出不窮。為了更好地在特定場景下得到更好的性能,能耗比等指標,針對特定應用場景的加速器市場也在蓬勃發展,近年來火熱的人工智能加速器
2022-07-29 15:38:43
1、基于arm Cortex-M3處理器與深度學習加速器的實時人臉口罩檢測 SoC本項目采用arm公司提供的DesignStartEval版本的Cortex-M3處理器作為系統的中央處理單元,通過
2022-08-26 15:23:33
FPGA 上實現卷積神經網絡 (CNN)。CNN 是一類深度神經網絡,在處理大規模圖像識別任務以及與機器學習類似的其他問題方面已大獲成功。在當前案例中,針對在 FPGA 上實現 CNN 做一個可行性研究
2019-06-19 07:24:41
從網絡到板卡處理,無需經過CPU,減低了傳輸延時。 而在算法上,浪潮FPGA深度學習加速解決方案針對CNN卷積神經網絡的相關算法進行優化和固化。客戶在采用此解決方案后,只需要將目前深度學習的算法
2021-09-17 17:08:32
的場景。如上所述種種設計挑戰的存在,使得業界急需一種可以支持高度并發實時計算、巨大內存容量和帶寬、以及在數據中心范圍可擴展的GNN加速解決方案。5. GNN加速器的FPGA設計方案Achronix 公司
2020-10-20 09:48:39
求一種基于FPGA的HDLC協議控制器設計方案
2021-04-30 06:53:06
求一種基于FPGA的永磁同步電機控制器的設計方案。
2021-05-08 07:02:07
使用 SDAccel 進行主機及加速器代碼優化 - Xilinx使用 FPGA 在云端進行視頻加速 - Xilinx阿里云 Faas 平臺創新與應用場景 - 阿里云從深度感知到三維識別
2019-01-03 15:19:42
英特爾媒體加速器參考軟件是用于數字標志、交互式白板(IWBs)和亭位使用模型的參考媒體播放器應用軟件,它利用固定功能硬件加速來提高媒體流速、改進工作量平衡和資源利用,以及定制的圖形處理股(GPU)管道解決方案。該用戶指南將介紹和解釋如何為Linux* 使用英特爾媒體加速器參考軟件。
2023-08-04 06:34:54
目前在用21489內部的IIR加速器去做一個低通濾波器,在例程的基礎上修改參數。通過Matlab的FDAtool去設計參數,但是設計出來的參數不知道如何對應加速器的濾波參數,手冊里也看得不是很明白。設計的參數如下:請問這些參數應該如何對應起來?
2018-11-09 09:40:51
本帖最后由 一只耳朵怪 于 2018-6-19 10:42 編輯
請問,在66ak系列有加密加速器,現在的項目需要此功能,請問,在程序設計中如何調用此加速器?采用pdk平臺,openmpacc開發。
2018-06-19 05:53:08
如何去選擇并優化IDCT快速算法?怎樣去設計一種MPEG-4加速器?如何對MPEG-4加速器進行仿真驗證?
2021-06-04 07:20:42
IoT應用。通過提供結合了靈活、超低功耗FPGA硬件和軟件解決方案、功能全面的機器學習推理技術,Lattice sensAI將加速網絡邊緣設備上傳感器數據處理和分析的集成。這些新的網絡邊緣計算解決方案
2018-05-23 15:31:04
也因而開始轉向采用加速器來滿足低時延、高吞吐量的需求,同時保持合理的功耗水平。 賽靈思FPGA所提供的功耗效率讓加速器能部署于整個數據中心,而且可將單位功耗性能比提升10-20倍。百度優化的FPGA
2016-12-15 17:15:52
占比達52%,歷屆參賽項目累計估值200億。近日,第八屆硬創賽與安創加速器達成戰略合作。安創加速器作為Arm全球唯一加速器,依托于Arm全球龐大的生態系統資源及行業領先的技術,通過創業加速和創新賦能為
2022-06-22 17:44:23
根據中國散裂中子源(CSNS)快周期同步加速器(RCS)磁鐵電源的需要,提出并介紹了RCS 磁鐵電源監測系統的設計方案。該方案選擇嵌入式FPGA+ARM 的硬件結構配合基于Linux 操作系統的
2009-12-08 11:23:40 16
16 一種加速器用高壓電源系統設計方案
0 引言
該電源系統為加速器供電,包括DC一200~一350kV 60mA主電源、30kV 100mA電源和10V 3A燈絲電源,其中30kV電源
2009-12-23 10:06:351342 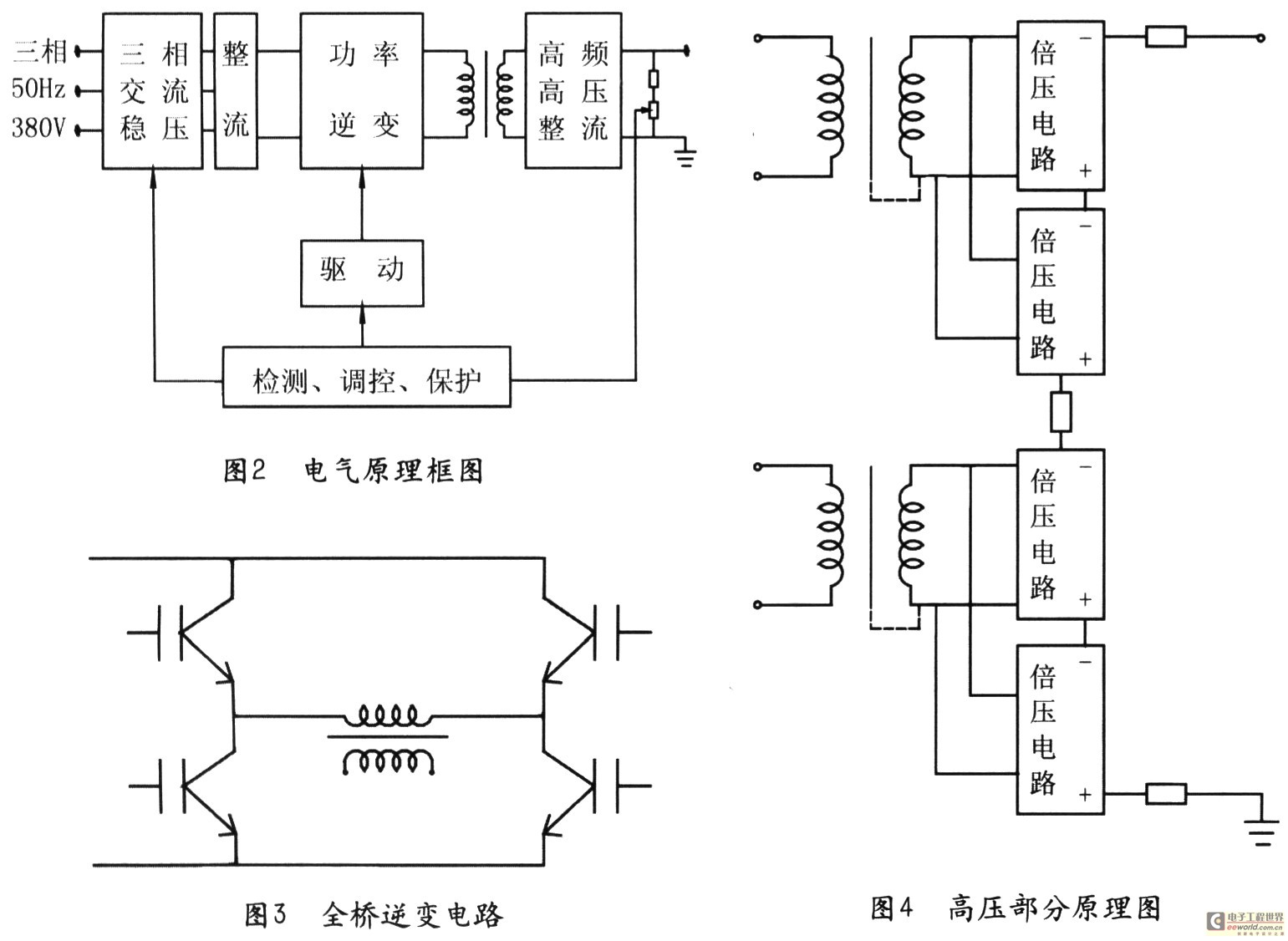
FPGA是深度學習的未來,學習資料,感興趣的可以看看。
2016-10-26 15:29:040 Intel 在世界超算大會 SC16 推出深度學習推理加速器和新至強芯片 Xeon-E5-2699A 在今年的世界超算大會 SC16 上, Intel 發布了針對 AI 開發者的深度學習推理加速器
2016-11-18 11:59:12616 NVIDIA(英偉達)21 日宣布推出 Pascal 架構深度學習平臺的最新生力軍 NVIDIA Tesla P4 及 P40 GPU 加速器與全新軟件,在效能及速度提供大幅度的提升以加速人工智能服務的推論生產作業負載。
2016-12-30 19:41:11619 學習應用。兩家公司正合作進一步擴大 FPGA 加速平臺的部署規模。新興應用的快速發展正日漸加重計算工作的負載,數據中心也因而開始轉向采用加速器來滿足低時延、高吞吐量的需求,同時保持合理的功耗水平。 賽靈思 FPGA 所提供的功耗效率讓加速器能部署于整個數據中心,而且
2017-02-08 03:15:37199 使用 ?Alpha Data Virtex-7? 或 ? 基于 ?Kintex UltraScale? 的 ?FPGA? 加速器卡增強您的 ?HPC? 應用,該卡是轉移高能耗搜索和計算任務的理想選擇,不僅可改善吞吐量與性能,而且還可降低系統功耗要求。 ? 了解更多 ? ?
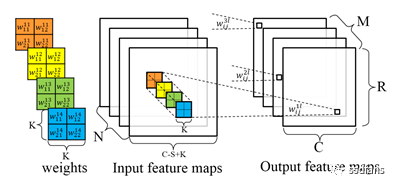
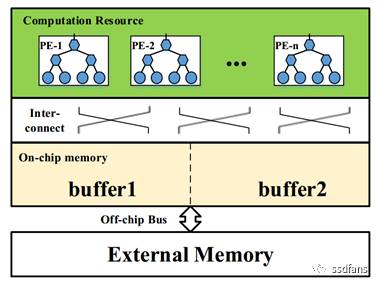
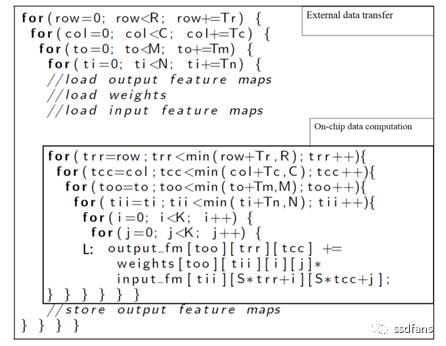
2017-02-08 19:33:08200 基于FPGA的通用CNN加速器整體框架如下,通過Caffe/Tensorflow/Mxnet等框架訓練出來的CNN模型,通過編譯器的一系列優化生成模型對應的指令;同時,圖片數據和模型權重數據按照優化規則進行預處理以及壓縮后通過PCIe下發到FPGA加速器中
2017-10-27 14:09:589882 
FPGA具有低功耗,低延時,高性能的特點,在深度學習計算領域有很廣闊的應用前景。FPGA從2013年開始就應用在許多典型的深度學習模型中,如DNN,RNN,CNN,LSTM等,涵蓋了語音識別
2017-11-15 16:56:36724 
CNN已經廣泛用于圖像識別,因為它能模仿生物視覺神經的行為獲得很高識別準確率。最近,基于深度學習算法的現代應用高速增長進一步改善了研究和實現。特別地,多種基于FPGA平臺的深度CNN加速器被提出
2017-11-17 13:31:017686 剛好在知乎上看到這個問題?如何用FPGA加速卷積神經網絡CNN,恰巧我的碩士畢業設計做的就是在FPGA上實現CNN的架構,在此和大家分享。 先說一下背景,這個項目的目標硬件是Xilinx的PYNQ
2018-06-29 07:55:004538 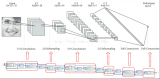
近日KORTIQ公司推出了一款Xilinx FPGA的CNN加速器IP——AIScale,它能夠利用實現訓練好的CNN網絡,比如行業標準的ResNet、AlexNet、Tiny Yolo和VGG-16等,并將它們進行壓縮輸出二進制描述文件,可以部署到Xilinx全系列可編程邏輯器件上。
2018-01-09 08:45:419799 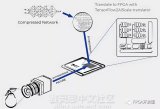
幾乎所有深度學習的研究者都在使用GPU,但是對比深度學習硬鑒方案,ASIC、FPGA、GPU三種究竟哪款更被看好?主要是認清對深度學習硬件平臺的要求。
2018-02-02 15:21:4010203 
以前FPGA沒有一個標準的加速卡,或者沒有一組標準的軟件應用訪問接口,每一個公司都要自己開發自己的東西,所以互相之間是不互通的。現在有了這樣一套相對通用的加速堆棧,不同的合作伙伴開發出來的加速器也好
2018-05-03 09:09:246268 隨著人工智能(AI)的不斷發展,它已經從早期的人工特征工程進化到現在可以從海量數據中學習,機器視覺、語音識別以及自然語言處理等領域都取得了重大突破。CNN(Convolutional Neural
2018-07-10 10:49:004360 高效語音識別引擎。該方案在亞馬遜AWS發布之后,迅速移植上線國內公有云市場。以語音識別為應用載體,對AI類應用推理計算進行全面加速。成為目前國內公有云市場上,首款基于FPGA平臺的原創深度學習語音識別加速解決方案。
2018-07-27 14:25:001719 OpenCL 軟件開發套件來編程的、獨立的英特爾 Arria 10 FPGA 加速器,從而展示對卷積神經網絡 (CNN) 對象分類的 FPGA 加速能力。FPGA 接口和 IP 構建在 BVLC
2018-07-31 09:04:001608 可是,設計一個基于FPGA的高性能DNN推理加速器還是充滿了困難,它需要寄存器傳輸級(RTL)編程技巧,硬件驗證知識和豐富的硬件資源分配經驗等硬件設計相關知識,對于在算法層面關注深度學習的研究人員來說是非常不友好的。
2018-11-16 10:39:175141 了解Xilinx FPGA如何通過深度學習圖像分類示例來加速重要數據中心工作負載機器學習。該演示可通過Alexnet神經網絡模型加速圖像(從ImageNet獲得)分類。它可通過開源框架Caffe實現,也可采用Xilinx xDNN
庫加速,從而可實現全面優化,為8位推理帶來最高計算效率。
2018-11-28 06:54:003521 本教程討論基于Xilinx FPGA的Memcached硬件加速器的技術細節,該硬件加速器可為10G以太網端口提供線速Memcached服務。
2018-11-27 06:41:003433 Kortiq提供易于使用,可擴展且小巧的CNN加速器。
該設備支持所有類型的CNN,并動態加速網絡中的不同層類型。
2018-11-23 06:28:002957 FPGA 的神經網絡加速器如今越來越受到 AI 社區的關注,本文對基于 FPGA 的深度學習加速器存在的機遇與挑戰進行了概述。近年來,神經網絡在各種領域相比于傳統算法有了極大的進步。在圖像、視頻
2019-01-29 16:48:006092 UIUC、IBM 和 Inspirit IoT, Inc(英睿物聯網)的研究人員提出 DNN 和 FPGA 加速器的協同設計方案(DNN/FPGA co-design),通過首創的「Auto-DNN
2019-06-10 14:39:301041 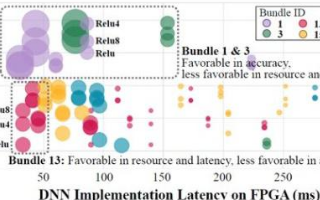
自行科技通過多年CNN與FPGA自主研發經驗,開發出業內最具性價比的FPGA加速設計方案。會中,她表示,FPGA加速設計需要算法工程師和FPGA工程師共同參與。
2019-07-26 16:59:113250 本文從硬件加速的視角考察深度學習與FPGA,指出有哪些趨勢和創新使得這些技術相互匹配,并激發對FPGA如何幫助深度學習領域發展的探討。
2019-06-28 17:31:466529 微軟團隊推出了一個新的深度學習加速平臺,其代號為腦波計劃(Project Brainwave),機器之心將簡要介紹該計劃。
2019-09-03 14:36:181781 做深度學習加速器已經兩年了,從RTL設計到仿真驗證,以及相應的去了解了Linux驅動,深度學習壓縮方法等等。
2020-03-08 16:29:008342 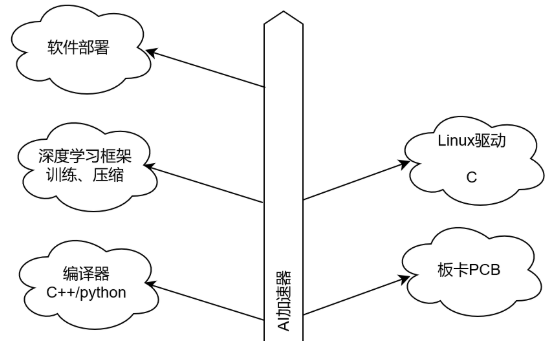
為滿足深度學習推理中對不同規模矩陣乘法的計算需求,提出一種基于 Zynq soc平臺的整數矩陣乘法加速器。采用基于總線廣播的并行結構,充分利用片上數據的重用性并最小化中間累加結果的移動范圍,以降
2021-05-25 16:26:533 電子學報第七期《一種可配置的CNN協加速器的FPGA實現方法》
2021-11-18 16:31:0615 AI加速器是一類專門的硬件加速器或計算機系統旨在加速人工智能的應用,主要應用于人工智能、人工神經網絡、機器視覺和機器學習。
2022-02-06 12:47:003645 電子發燒友網站提供《基于AdderNet的深度學習推理加速器.zip》資料免費下載
2022-10-31 11:12:280 ? ? 機器學習應用提升計算性能和能效可通過多種方式,其中最有效的是將專門構建的專用神經處理單元 (NPU),或稱為機器學習加速器 (MLA) 或深度學習加速器 (DLA) 集成到器件中,以補充CPU計算核心。? 恩智浦提供廣泛的產品組合,從傳統的Kinetis M
2023-02-11 13:15:04785 這是新的系列教程,在本教程中,我們將介紹使用 FPGA 實現深度學習的技術,深度學習是近年來人工智能領域的熱門話題。
2023-03-03 09:52:131088 本文重點解釋如何使用硬件轉換卷積神經網絡(CNN),并特別介紹使用帶CNN硬件加速器的人工智能(AI)微控制器在物聯網(IoT)邊緣實現人工智能應用所帶來的好處。 AI應用通常需要消耗大量能源,并以
2023-05-16 01:05:03467 本文詳細描述了FPGA實現圖像去霧的實現設計方案,采用暗通道先驗算法實現,并利用verilog并行執行的特點對算法進行了加速;
2023-06-05 17:01:45862 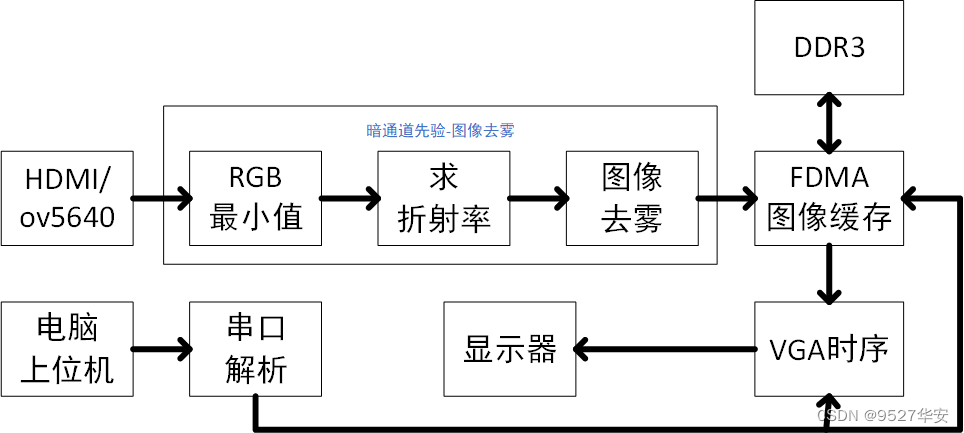
電子發燒友網站提供《基于FPGA的Wide&Deep模型加速器解決方案.pdf》資料免費下載
2023-09-13 10:37:071 電子發燒友網站提供《Rapanda流加速器-實時流式FPGA加速器解決方案.pdf》資料免費下載
2023-09-13 10:17:120 電子發燒友網站提供《MAU加速器解決方案.pdf》資料免費下載
2023-09-13 09:46:540 粒子加速器的加速原理是啥呢? 粒子加速器是一種重要的實驗設備,用于研究粒子物理學、核物理學等領域。其主要原理是通過電場和磁場的作用,對帶電粒子進行加速,在高速運動過程中使其獲得較大的動能,最終達到
2023-12-18 13:52:08639
 電子發燒友App
電子發燒友App
















 工商網監
工商網監
評論