這是RISC-V跑大模型系列的第二篇文章,主要教大家如何將LLaMA移植到RISC-V環境里。
2023-07-17 16:16:20 917
917 
這是RISC-V跑大模型系列的第三篇文章,前面我們為大家介紹了如何在RISC-V下運行LLaMA,本篇我們將會介紹如何為LLaMA提供中文支持。
2023-07-17 17:15:47495 
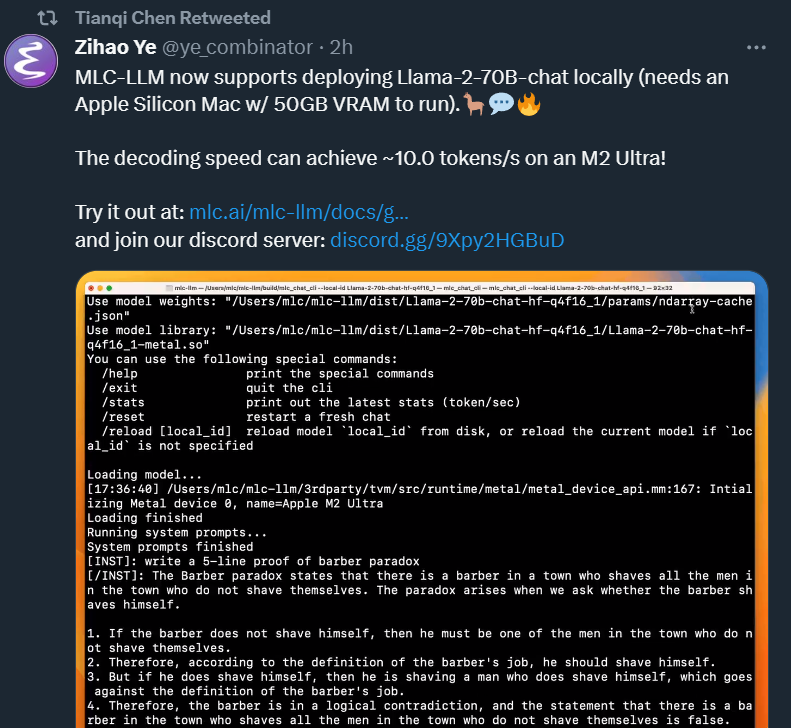
英特爾廣泛的AI硬件組合及開放的軟件環境,為Meta發布的Llama 2模型提供了極具競爭力的選擇,進一步助力大語言模型的普及,推動AI發展惠及各行各業。 ? 大語言模型(LLM)在生成文本、總結
2023-07-25 09:56:26736 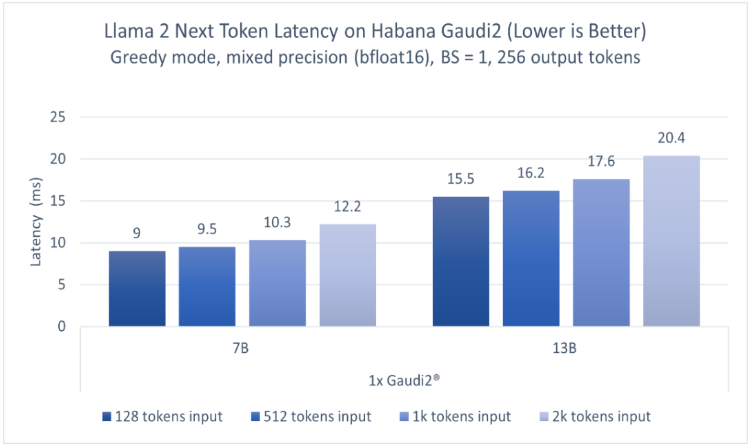
Llama 2是 Meta 發布了其最新的大型語言模型,Llama2 是基于 Transformer 的人工神經網絡,以一系列單詞作為輸入,遞歸地預測下一個單詞來生成文本。
2023-08-06 11:06:30523 
llama.cpp 的代碼結構比較直觀,如下所示,為整體代碼結構中的比較核心的部分的代碼結構
2023-11-07 09:23:27756 
LLama.cpp 支持x86,arm,gpu的編譯。
2024-01-22 09:10:16317 
KEYPAD LEGEND TILE LLAMA
2023-03-29 22:35:13
CC2640和CC2640R2F如何提升IoT應用的性能?
2021-06-15 09:13:20
請問CC3200是否可以布2層板,性能方面除了影響WIFI的射頻性能,還有其他影響嗎?
2016-03-23 11:43:19
專家好,
CCS調試程序過程中,需要分析下各函數的執行時間,CCS中提供了性能分析器profile
Q1:性能分析器profile是否只能在Simulator下才能使用,Emulator下沒有這個功能?
Q2:性能分析器profile的使用方法是否有相應的教程參考?
謝謝
NanShan
2018-06-21 19:20:12
ESP32性能怎么樣?
2022-02-28 07:20:09
HyperLink介紹HyperLink的性能
2021-04-02 07:37:58
。對影響HyperLink 性能的一些因素進行了討論。2、HyperLink 配置 本節提供了一些配置 HyperLink 模塊的補充信息。2.1 Serdes 配置Serdes 必須配置成期望的鏈接速度。 圖 1 表示了
2019-06-21 05:00:07
接觸了當時宏晶(STC)最新推出的 IAP15F2K61S2(對應 STC15F2K60S2)可仿真單片機, 很快就被它的各 種新穎性能所吸引:3通道捕獲/比較單元(CCP/PWM/PCA);雙
2021-09-17 08:19:50
關于燈具光學、能效、性能等,我司可辦理DLC,LM-80,ERP,IEC 62612,IEC62722-2-1,IEC60969,IEC62717,TM-21,LM-79,IES測試,積分球測試,閃
2020-06-26 12:26:37
JE350G跟2SB649相比那種管子的性能好一點,與2SA1943搭配用用哪一種管子音質更好呢????
2012-12-18 21:18:23
如圖Labview性能和內存信息能看出來內存泄露嗎?如上圖,未命名1.vi是否存在內存泄露?
補充內容 (2016-2-23 21:03):
Labview自帶的工具能檢查出內存泄露嗎?
2016-02-23 14:33:55
你好,我們在PTC Creo和Nvidia K2以及K260配置文件中遇到了一些性能問題。有沒有人有同樣的問題?謝謝亞歷克斯以上來自于谷歌翻譯以下為原文Hello,we have some
2018-09-17 14:36:08
SRAM的性能及結構
2020-12-29 07:52:53
XC7A200T-2FFG1156C集成電路具有哪些性能與優勢呢?
2021-12-27 07:08:35
從XD 7.6升級到XD 7.15后,桌面的性能顯著下降。 AutoCAD的鼠標滯后時間長達15秒。我們認為K2不支持XD 7.15的所有新功能。有人做同樣的經歷嗎?最好的祝福,西蒙以上來自于谷歌
2018-09-25 14:56:52
星光 2是迄今最高性能單板機。 搭載高性能昉·驚鴻7110搭載64位高性能四核RISC-V CPU,2MB的二級緩存,工作頻率最高可達1.5 GHz。昉·驚鴻7110具有多個的高速本地接口,支持
2023-09-28 10:34:57
ChatGLM2-6B、AIGC、Llama2、SAM、Whisper等超大參數模型
還有一份詳細的英文的規格表:
另外,算能RADXA微服務器服務器,還是大學生集成電路創新創業大賽之# 第八屆集創賽杯賽題目
2024-02-28 11:21:57
性能測試之CPU性能前言CoreMark是用在嵌入式系統中用來測量CPU性能的基準程序。該標準于2009年由EEMBC(Embedded Microprocessor Benchmark
2022-08-16 14:03:54
性能測試之EMMC性能前言對于越來越高端的嵌入式芯片,尤其用于汽車,人機,AI,邊緣計算等場景的高性能CPU,其綜合性能是一個關注點,板子的性能不僅僅和CPU相關,綜合來看的話存儲部分也是一個很重
2022-08-16 13:17:27
性能測試之RAM測試前言對于越來越高端的嵌入式芯片,尤其用于汽車,人機,AI,邊緣計算等場景的高性能CPU,其綜合性能是一個關注點,板子的性能不僅僅和CPU相關,綜合來看的話存儲部分也是一個很重
2022-08-16 12:51:08
預訓練語言模型。該模型最大的特點就是基于以較小的參數規模取得了優秀的性能,根據官網提供的信息,LLaMA的模型包含4個版本,最小的只有70億參數,最大的650億參數,但是其性能相比較之前的OPT
2023-12-22 10:18:11
描述Red LLama / CA Tube Sound Fuzz新的 Red Llama 與原版略有不同。它仍然令人印象深刻,但不如其前身那么甜美。話雖如此,它是少數幾個在打開時不會給吉他音色上色
2022-08-05 07:11:36
關于燈具光學、能效、性能等,我司可辦理DLC,LM-80,ERP,IEC 62612,IEC62722-2-1,IEC60969,IEC62717,TM-21,LM-79,IES測試,積分球測試,閃
2020-06-29 16:04:47
什么是OTP-638D2?OTP-638D2有哪些性能參數?
2021-06-16 07:06:09
什么是插頭電腦?它的性能如何?用途何在?如何使用?
2021-06-04 07:24:22
制備方法對Ba2FeMoO6雙鈣鈦礦磁性能的影響采用濕化學法和固相反應制備了Ba2FeMoO6雙鈣鈦礦化合物,對比研究了制備方法對其磁性能尤其是磁卡效應的影響。實驗結果表明,濕化學法準備的樣品具有
2009-05-26 00:22:45
(即2)來獲得可用的操作單元。這是1,800。4-每個操作單元需要282個LUT。可用邏輯只能支持982個操作單元,因此性能如下:989運算* 393 MHz = 385,926 MFlops
2020-08-13 09:56:00
本文介紹的三個應用案例展示了業界上先進的機器視覺軟件和及其圖像預處理技術如何促使2D和3D視覺檢測的性能成倍提升。
2021-02-22 06:56:21
提升SRAM性能的傳統方法
2021-01-08 07:41:27
如何提升基站性能?
2021-05-26 06:33:50
如何提高FATFS SD性能?
2022-02-11 06:28:46
如何提高VMMK器件的性能?
2021-05-21 06:35:39
無論您的系統是用于無線通信、雷達,還是 EMI/EMC 測試,系統的性能水平都是由其中的天線決定的。系統天線的性能決定了系統的整體質量,最終可能會影響整個程序或應用軟件的效率。本文介紹了 5 個旨在幫助您提高天線性能的關鍵要點。
2021-02-24 07:24:14
嵌入設備的實時性能是什么
2021-04-28 06:18:31
本文將討論如何在產品開發過程中,使用現代仿真技術驗證M2M或MTC應用的性能,以便制造商在現場部署產品時有信心保證無差錯地工作。
2021-04-19 08:03:11
目前的實時信號處理機要求ADC盡量靠近視頻?中頻甚至射頻,以獲取盡可能多的目標信息?因而,ADC的性能好壞直接影響整個系統指標的高低和性能好壞,從而使得ADC的性能測試變得十分重要?那要怎么測試高速ADC的性能?
2021-04-14 06:02:51
關于燈具光學、能效、性能等,我司可辦理DLC,LM-80,ERP,IEC 62612,IEC62722-2-1,IEC60969,IEC62717,TM-21,LM-79,IES測試,積分球測試,閃
2020-06-29 16:24:10
在產品重量上做出的努力。·雙核A5處理器 顯示性能提升9倍 蘋果iPad 2采用全新的A5處理器(1GHz),雙核架構提升了多任務處理能力,CPU速度比老款iPad提升了兩倍,并帶來高達9倍的顯示性能
2011-03-03 16:55:52
【作者】:李楊超;張銘;趙學平;董國波;嚴輝;【來源】:《納米科技》2010年01期【摘要】:采用射頻磁控濺射法制備了不同襯底溫度的CuCrO2薄膜,通過X射線衍射、掃描電鏡、紫外吸收光譜及電學性能
2010-04-24 09:00:59
示例嗎?2) evkbimxrt1050_dev_hid_mouse_freertos 只有“中斷輸入”,如何修改示例以具有“批量輸出”以進行 USB 性能測試?
2023-04-04 08:57:51
。對金屬材料而言、鑄造性主要包括流動性、收縮率、偏析傾向等指標。流動性好、收縮率小、偏析傾向小的材料其鑄造性也好。對某些工程縮料而言,在其成型工藝方法中,也要求較好的流動性和小的收縮率。(2)鍛造性能可鍛性
2017-08-25 09:36:21
有哪些新型可用于基帶處理的高性能DSP?性能參數如何?
2018-06-24 05:20:19
的功能。本文將介紹高性能SitaraAM2x MCU幫助設計工程師克服當前和未來系統挑戰的五大特性,如圖1所示。圖1:Sitara AM2x高性能MCU的優勢實現更強大的性能MCU最近在內存大小、模擬
2022-11-04 06:28:40
最近由UC Berkeley、CMU、Stanford, 和 UC San Diego的研究人員創建的 Vicuna-13B,通過在 ShareGPT 收集的用戶共享對話數據中微調 LLaMA獲得。
2023-04-06 10:16:06962 Linly-Chinese-LLaMA:中文基礎模型,基于 LLaMA 在高質量中文語料上增量訓練強化中文語言能力,現已開放 7B、13B 和 33B 量級,65B 正在訓練中。
2023-05-04 10:29:07706 
通過醫學知識圖譜和 GPT 3.5 API 構建了中文醫學指令數據集,并在此基礎上對 LLaMA 進行了指令微調,提高了 LLaMA 在醫療領域的問答效果。
2023-05-08 11:30:211186 
通過我們的VPGTrans框架可以根據需求為各種新的大語言模型靈活添加視覺模塊。比如我們在LLaMA-7B和Vicuna-7B基礎上制作了VL-LLaMA和VL-Vicuna。
2023-05-17 11:46:25497 
目前主要的模型的參數 LLaMA系列是否需要擴中文詞表 不同任務的模型選擇 影響LLM性能的主要因素 Scaling Laws for Neural Language Models OpenAI的論文
2023-05-22 15:26:201148 
去訓練),并且和Vision結合的大模型也逐漸多了起來。所以怎么部署大模型是一個 超級重要的工程問題 ,很多公司也在緊鑼密鼓的搞著。 目前效果最好討論最多的開源實現就是LLAMA,所以我這里討論的也是基于 LLAMA的魔改部署 。 基于LLAMA的finetune模型
2023-05-23 15:08:474397 
你可以看到,Llama 的參數數量大概是 650 億。現在,盡管與 GPT3 的 1750 億個參數相比,Llama 只有 65 個 B 參數,但 Llama 是一個明顯更強大的模型,直觀地說,這是
2023-05-30 14:34:56642 
「我們在MMLU上復現了LLaMA 65B的評估,得到了61.4的分數,接近官方分數(63.4),遠高于其在Open LLM Leaderboard上的分數(48.8),而且明顯高于獵鷹(52.7)。」
2023-06-09 16:43:14820 
這是一組由 Meta 開源的大型語言模型,共有 7B、13B、33B、65B 四種版本。其中,LLaMA-13B 在大多數數據集上超過了 GPT-3(175B),LLaMA-65B 達到了和 Chinchilla-70B、PaLM-540B 相當的水平。
2023-06-11 11:24:20421 
baichuan-7B 主要是參考LLaMA進行的改進,且模型架構與LLaMA一致。而在開源大模型中,LLaMA無疑是其中最閃亮的星,但LLaMA存在如下問題: LLaMA 原生僅支持 Latin
2023-06-17 14:14:28706 既然已經有了成功ChatGPT這一成功的案例,大家都想基于LLaMA把這條路再走一遍,以期望做出自己的ChatGPT。
2023-07-04 15:07:253281 
這是RISC-V跑大模型系列的第二篇文章,主要教大家如何將LLaMA移植到RISC-V環境里。
2023-07-10 10:10:38706 
通過線性插值RoPE擴張LLAMA context長度最早其實是在llamacpp項目中被人發現,有人在推理的時候直接通過線性插值將LLAMA由2k拓展到4k,性能沒有下降,引起了很多人關注。
2023-07-14 16:58:17347 要點 — ?? 高通 計劃從2024 年起,在旗艦智能手機和PC上支持基于Llama 2的AI部署,賦能開發者使用驍龍平臺的AI能力,推出激動人心的全新生成式AI應用。 ?? 與僅僅使用云端AI部署
2023-07-19 10:00:02323 
高通計劃從2024年起,在旗艦智能手機和PC上支持基于Llama 2的AI部署,賦能開發者使用驍龍平臺的AI能力,推出激動人心的全新生成式AI應用。
2023-07-19 10:00:03462 因此,高通技術公司計劃支持基于llama 2的終端ai部署,以創建新的、有趣的ai應用程序。通過這種方式,客戶、合作伙伴和開發者可以構建智能模擬器、生產力應用程序、內容制作工具和娛樂等的使用案例。驍龍?賦能實現的新終端ai體驗,即使在飛行模式下,也可以在沒有網絡連接的地區運行。
2023-07-19 10:26:38345 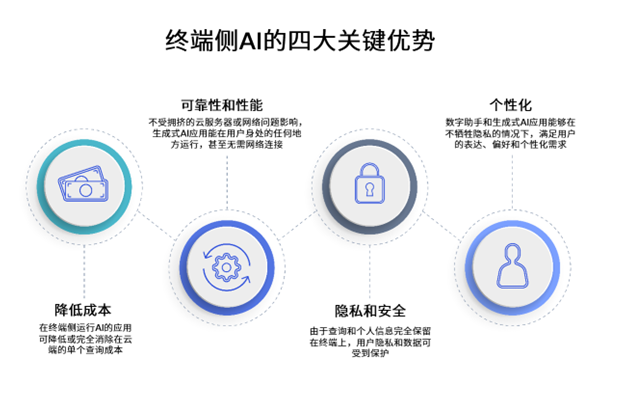
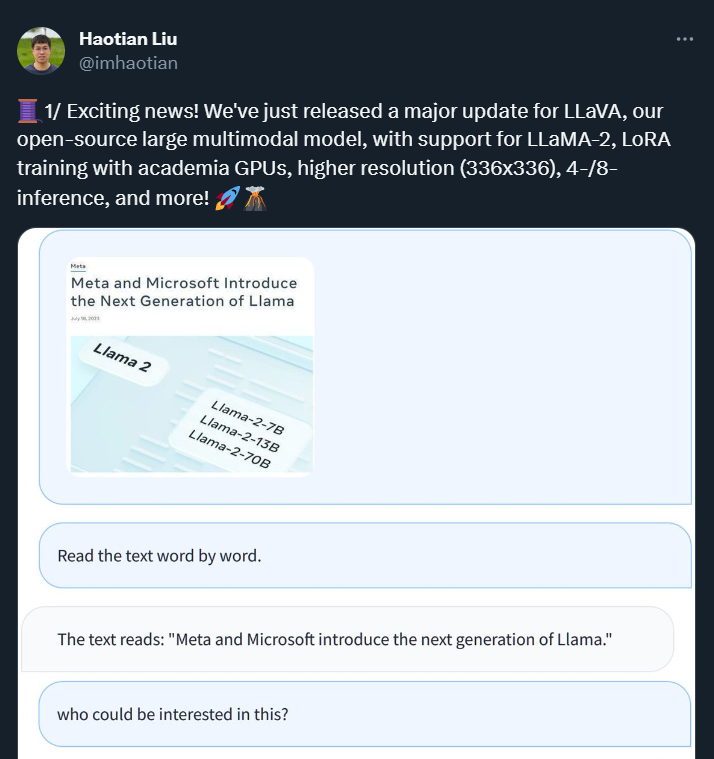
當地時間7月18日,Meta宣布,將發布其開源大模型LLaMA商用版本,新版本名為Llama 2。
2023-07-20 10:27:59193 作為Meta首批合作伙伴之一,亞馬遜云科技宣布客戶可以通過Amazon SageMaker JumpStart來使用Meta開發的Llama 2基礎模型。
2023-07-21 16:10:59904 模型結構為Transformer結構,與Llama相同的是采用RMSNorm歸一化、SwiGLU激活函數、RoPE位置嵌入、詞表的構建與大小,與Llama不同的是增加GQA(分組查詢注意力),擴增了模型輸入最大長度,語料庫增加了40%。
2023-07-23 12:36:541098 
英特爾廣泛的AI硬件組合及開放的軟件環境,為Meta發布的Llama 2模型提供了極具競爭力的選擇,進一步助力大語言模型的普及,推動AI發展惠及各行各業。 大語言模型(LLM)在生成文本、總結和翻譯
2023-07-24 19:31:56387 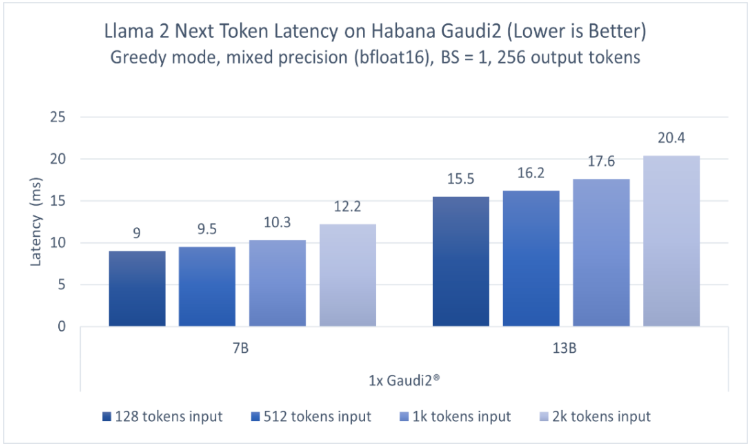
和 Windows 上支持 Llama 2 大型語言模型(LLM)系列 。Llama 2 旨在幫助開發者和組織構建生成式人工智能工具和體驗。Meta 和微軟共同致力于實現“讓人工智能惠及更多
2023-07-26 10:35:01303 
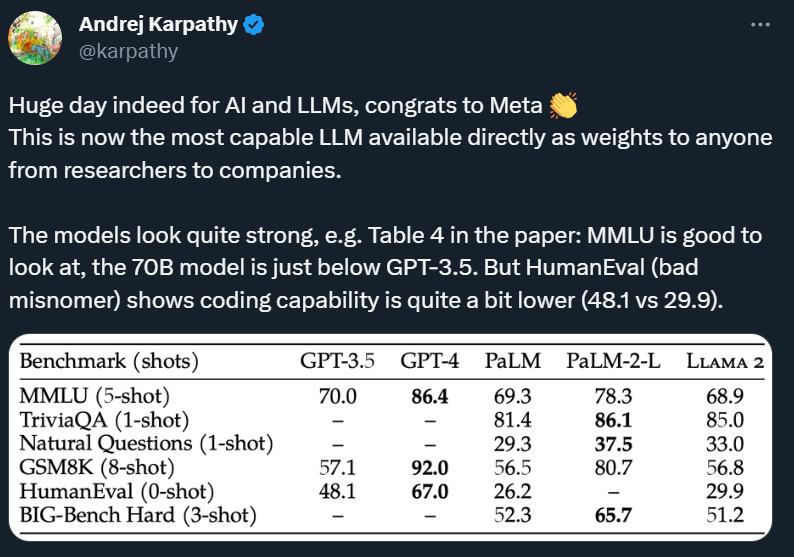
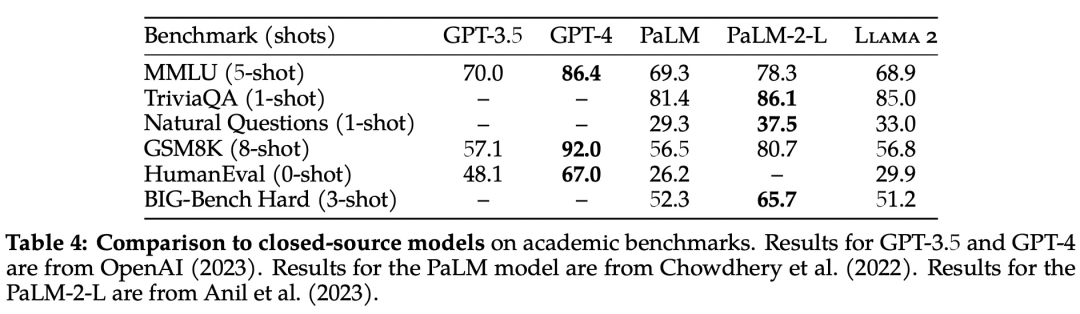
與所有LLM一樣,Llama 2偶爾會產生不正確或不可用的答案,但Meta介紹Llama的論文聲稱,它在學術基準方面與OpenAI的GPT 3.5不相上下,如MMLU(衡量LLM在57門STEM科目中的知識)和GSM8K(衡量LLM對數學的理解)。
2023-08-02 16:17:25410 
隨著 Llama 2 的逐漸走紅,大家對它的二次開發開始流行起來。前幾天,OpenAI 科學家 Karpathy 利用周末時間開發了一個明星項目 llama2.c,借助 GPT-4,該項目僅用
2023-08-02 16:25:28470 
IBM 企業就緒的 AI 和數據平臺?watsonx?不斷推出新功能。IBM 宣布,計劃在 watsonx 的 AI 開發平臺?watsonx.ai?上納入?Meta?的 700?億參數 Llama
2023-08-09 20:35:01314 Code Llama 的卓越功能源自行業領先的 AI 算法。其核心模型由包含編程語言、編碼模式和最佳實踐的大規模數據集訓練而成。自然語言處理(NLP)技術則讓 Code Llama 有能力理解開發者的輸入,并生成與上下文相匹配的代碼建議。
2023-08-21 15:15:02570 目前大部分開源LLM模型都是基于transformers庫來做的,它們的結構大部分都和Llama大同小異。
2023-08-23 11:44:071462 
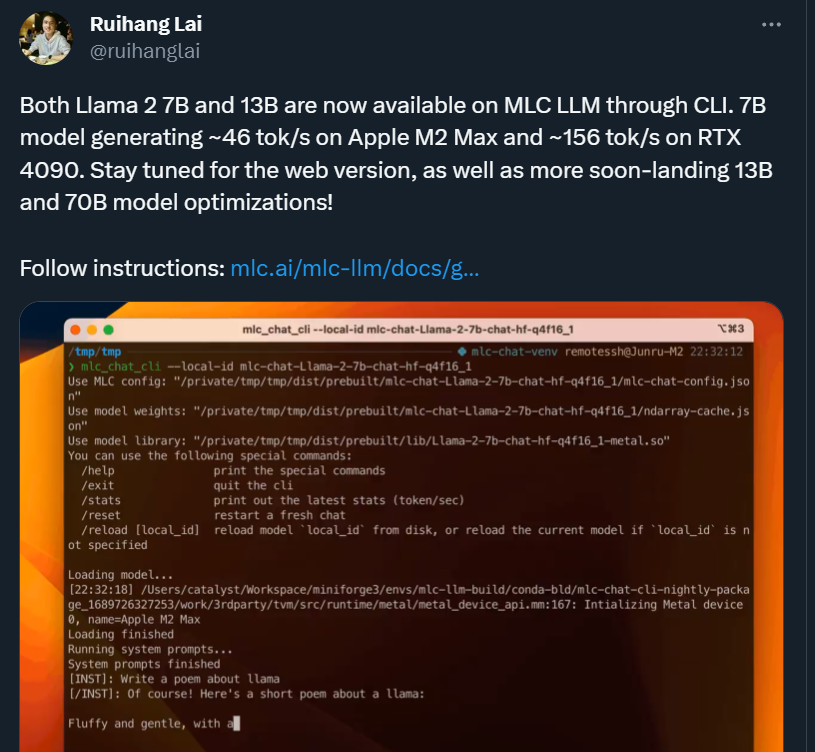
Meta 發布的 Llama 2,是新的 SOTA 開源大型語言模型(LLM)。Llama 2 代表著 LLaMA 的下一代版本,可商用。Llama 2 有 3 種不同的大小 —— 7B、13B 和 70B 個可訓練參數。
2023-08-23 15:40:09674 2023 年 8 月 24 日 – MediaTek今日宣布利用Meta新一代開源大語言模型(LLM)Llama 2 以及MediaTek先進的AI處理器(APU)和完整的AI開發平臺
2023-08-24 13:41:03225 
今天,Meta發布了Code Llama,一款可以使用文本提示生成代碼的大型語言模型(LLM)。
2023-08-25 09:06:57885 
據路透社報道,meta計劃推出全新編程人工智能模型:Code Llama,可以根據文字提示來編寫計算機代碼,或協助開發者編程。這一AI工具將免費提供。
2023-08-25 11:39:00493 Meta公司表示,Meta發布了一種名為Code Llama的工具,該工具建立在其Llama 2大型語言模型的基礎上,用于生成新代碼和調試人工編寫的工作。 Code Llama將使用與Llama
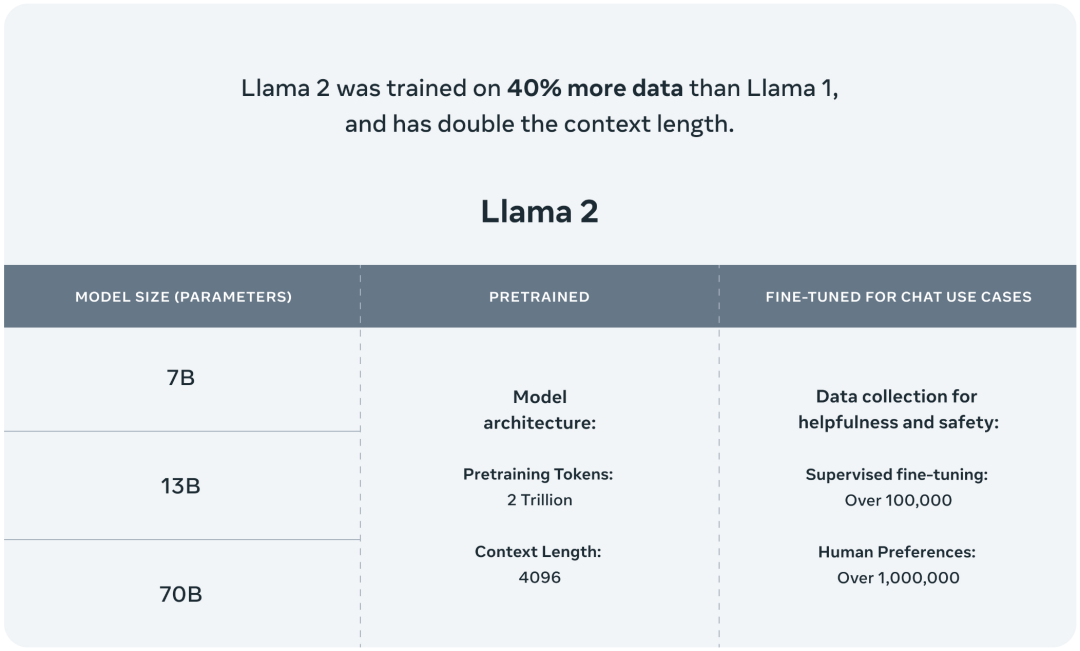
2023-08-28 16:56:39932 時隔半年后,Meta AI在周二發布了最新一代開源大模型Llama 2。相較于今年2月發布的Llama 1,訓練所用的token翻了一倍至2萬億,同時對于使用大模型最重要的上下文長度限制,Llama 2也翻了一倍。Llama 2包含了70億、130億和700億參數的模型。
2023-08-29 16:50:10950 針對 GPU 計算特點,在顯存允許的情況下,XTuner 支持將多條短數據拼接至模型最大輸入長度,以此最大化 GPU 計算核心的利用率,可以顯著提升訓練速度。例如,在使用 oasst1 數據集微調 Llama2-7B 時,數據拼接后的訓練時長僅為普通訓練的 50% 。
2023-09-04 16:12:261242 
1. 1800億參數,世界頂級開源大模型Falcon官宣!碾壓LLaMA 2,性能直逼GPT-4 原文: https://mp.weixin.qq.com
2023-09-08 19:15:02480 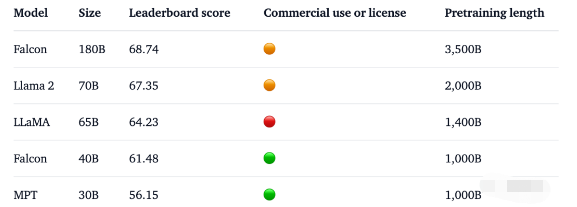
從 GPT-3,Gopher 到 LLaMA,大模型有更好的性能已成為業界的共識。但相比之下,單個 GPU 的顯存大小卻增長緩慢,這讓顯存成為了大模型訓練的主要瓶頸,如何在有限的 GPU 內存下訓練大模型成為了一個重要的難題。
2023-09-11 16:08:49240 
? 世界最強開源大模型 Falcon 180B 忽然火爆全網,1800億參數,Falcon 在 3.5 萬億 token 完成訓練,性能碾壓 Llama 2,登頂 Hugging Face 排行榜
2023-09-18 09:29:05876 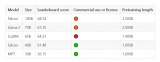
的浪潮信息NF5468服務器大幅提升了LLaMA大模型的微調訓練性能。目前該產品已具備交付能力,客戶可以進行下單采購。
2023-09-22 11:16:311813 使用QLoRA對Llama 2進行微調是我們常用的一個方法,但是在微調時會遇到各種各樣的問題
2023-09-22 14:27:21939 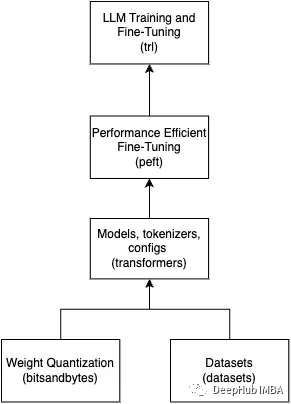
4,096,并對算法細節進行了優化,加速了推理速度,讓 Llama2 的性能有了很大的提升,能夠和 ChatGPT 相媲美。 Llama2 大模型旨在處理廣泛的語言任務,包括文本生成、機器翻譯、問題回答、代碼生成等等。該模型經過大規模的訓練,能夠理解并生成文本,為各種應用提供強大的自然語言處理能力。它的多
2023-10-13 20:35:02564 
MathOctopus在多語言數學推理任務中,表現出了強大的性能。MathOctopus-7B 可以將LLmMA2-7B在MGSM不同語言上的平均表現從22.6%提升到40.0%。更進一步,MathOctopus-13B也獲得了比ChatGPT更好的性能。
2023-11-08 10:37:57154 
在備受關注的人工智能領域,英偉達表示,h200將進一步提高性能。llama 2(700億個llm)的推理速度是h100的兩倍。未來的軟件更新有望為h200帶來更多的性能和改進。
2023-11-14 10:49:16553 微軟發布 Orca 2 LLM,這是 Llama 2 的一個調優版本,性能與包含 10 倍參數的模型相當,甚至更好。
2023-12-26 14:23:16247 據悉,Code Llama工具于去年8月份上線,面向公眾開放且完全免費。此次更新的Code Llama 70B不僅能處理更多復雜查詢,其在HumanEval基準測試中的準確率高達53%,超越GPT-3.5的48.1%,然而與OpenAI公布的GPT-4準確率(67%)仍有一定差距。
2024-01-30 10:36:18279 Meta近日宣布了其最新版本的AI代碼生成模型Code Llama70B,并稱其為“目前最大、最優秀的模型”。這一更新標志著Meta在AI代碼生成領域的持續創新和進步。
2024-01-30 18:21:04793 近日,Meta宣布推出了一款新的開源大模型Code Llama 70B,這是其“Code Llama家族中體量最大、性能最好的模型版本”。這款新模型提供三種版本,并免費供學術界和商業界使用。
2024-01-31 09:24:18311 Meta 發布的 LLaMA 2,是新的 sota 開源大型語言模型 (LLM)。LLaMA 2 代表著 LLaMA 的下一代版本,并且具有商業許可證。
2024-02-21 16:00:21246 AMD詳述運行步驟,如在搭載70億參數的Mistral機器上,需尋找并下載“TheBloke / OpenHermes-2.5-Mistral-7B-GGUF”;若選擇運行70億參數的LLAMA v2,須檢索并下載“TheBloke / Llama-2-7B-Chat-GGUF”。
2024-03-07 15:57:13277
 電子發燒友App
電子發燒友App


















 工商網監
工商網監
評論