 電子發燒友App
電子發燒友App


在過去的幾年里,根據自己的工作經驗,整理了我認為最重要的機器學習算法。
通過這個,我希望提供一個工具和技術的存儲庫,以便您可以解決各種數據科學問題!
讓我們深入研究六種最重要的機器學習算法:
解釋性算法
模式挖掘算法
集成學習算法
聚類算法
時間序列算法
相似度算法
1.解釋算法
機器學習中最大的問題之一是了解各種模型如何得出最終預測。我們常常知道“是什么”,但很難解釋“為什么”。
解釋性算法幫助我們識別對我們感興趣的結果有有意義影響的變量。這些算法使我們能夠理解模型中變量之間的關系,而不是僅僅使用模型來預測結果。
您可以使用多種算法更好地理解給定模型的自變量和因變量之間的關系。
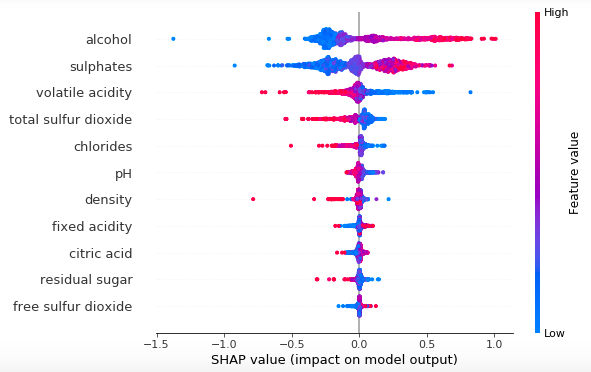
算法
線性/邏輯回歸:一種對因變量與一個或多個自變量之間的線性關系建模的統計方法——可用于根據 t 檢驗和系數了解變量之間的關系。
決策樹:一種機器學習算法,它創建決策及其可能后果的樹狀模型。通過查看拆分分支的規則,它們對于理解變量之間的關系很有用。
主成分分析 (PCA):一種降維技術,可將數據投射到低維空間,同時保留盡可能多的方差。PCA 可用于簡化數據或確定特征重要性。
Local Interpretable Model-Agnostic Explanations (LIME):一種算法,通過使用線性回歸或決策樹等技術構建更簡單的模型,在預測周圍近似模型來解釋任何機器學習模型的預測。
Shapley Additive explanations (SHAPLEY):一種算法,通過使用基于“邊際貢獻”概念的方法計算每個特征對預測的貢獻來解釋任何機器學習模型的預測。在某些情況下,它可能比 SHAP 更準確。
Shapley Approximation (SHAP):一種通過估計每個特征在預測中的重要性來解釋任何機器學習模型的預測的方法。SHAP 使用一種稱為“聯合博弈”的方法來近似 Shapley 值,并且通常比 SHAPLEY 更快。
2.模式挖掘算法
模式挖掘算法是一種數據挖掘技術,用于識別數據集中的模式和關系。這些算法可用于多種目的,例如識別零售環境中的客戶購買模式、了解網站/應用程序的常見用戶行為序列,或在科學研究中尋找不同變量之間的關系。
模式挖掘算法通常通過分析大型數據集并尋找重復模式或變量之間的關聯來工作。一旦確定了這些模式,就可以使用它們來預測未來趨勢或結果,或者了解數據中的潛在關系。
算法
Apriori 算法:一種用于在事務數據庫中查找頻繁項集的算法 - 它高效且廣泛用于關聯規則挖掘任務。
遞歸神經網絡 (RNN):一種神經網絡,旨在處理順序數據,因為它們能夠捕獲數據中的時間依賴性。
長短期記憶 (LSTM):一種循環神經網絡,旨在更長時間地記住信息。LSTM 能夠捕獲數據中的長期依賴關系,通常用于語言翻譯和語言生成等任務。
使用等價類 (SPADE) 的順序模式發現:一種通過將在某種意義上等價的項目組合在一起來查找順序數據中頻繁模式的方法。這種方法能夠處理大型數據集并且相對高效,但可能不適用于稀疏數據。
PrefixSpan:一種通過構建前綴樹和修剪不頻繁項目來查找順序數據中頻繁模式的算法。PrefixScan 能夠處理大型數據集并且相對高效,但可能不適用于稀疏數據。
3.集成學習
集成算法是一種機器學習技術,它結合了多個模型的預測,以便做出比任何單個模型都更準確的預測。集成算法優于傳統機器學習算法的原因有以下幾個:
多樣性:通過組合多個模型的預測,集成算法可以捕獲數據中更廣泛的模式。
魯棒性:集成算法通常對數據中的噪聲和異常值不太敏感,這可以導致更穩定和可靠的預測。
減少過度擬合:通過對多個模型的預測進行平均,集成算法可以減少單個模型過度擬合訓練數據的趨勢,從而提高對新數據的泛化能力。
提高準確性:集成算法已被證明在各種情況下始終優于傳統的機器學習算法。
算法
隨機森林:一種機器學習算法,它創建決策樹的集合并根據樹的多數票進行預測。
XGBoost:一種梯度提升算法,它使用決策樹作為其基礎模型,被認為是最強的 ML 預測算法之一。
LightGBM:另一種梯度提升算法,旨在比其他提升算法更快、更高效。
CatBoost:一種梯度提升算法,專門設計用于很好地處理分類變量。
4.聚類
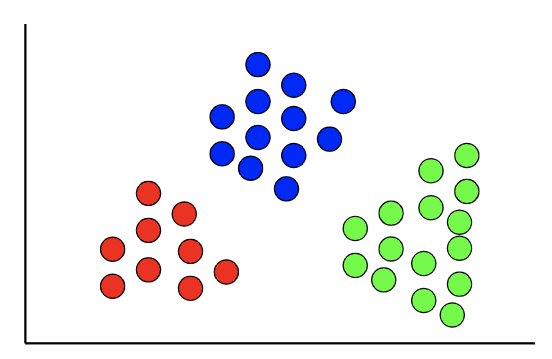
聚類算法是一種無監督學習任務,用于將數據分組為“集群”。與目標變量已知的監督學習相反,聚類中沒有目標變量。
這種技術對于發現數據的自然模式和趨勢很有用,并且經常在探索性數據分析階段使用,以進一步了解數據。此外,聚類可用于根據各種變量將數據集劃分為不同的部分。這方面的一個常見應用是對客戶或用戶進行細分。
算法
K模式聚類:一種專門為分類數據設計的聚類算法。它能夠很好地處理高維分類數據并且實現起來相對簡單。
DBSCAN:一種基于密度的聚類算法,能夠識別任意形狀的聚類。它對噪聲相對穩健,可以識別數據中的異常值。
譜聚類:一種聚類算法,它使用相似矩陣的特征向量將數據點分組到聚類中。它能夠處理非線性可分數據并且相對高效。
5.時間序列算法
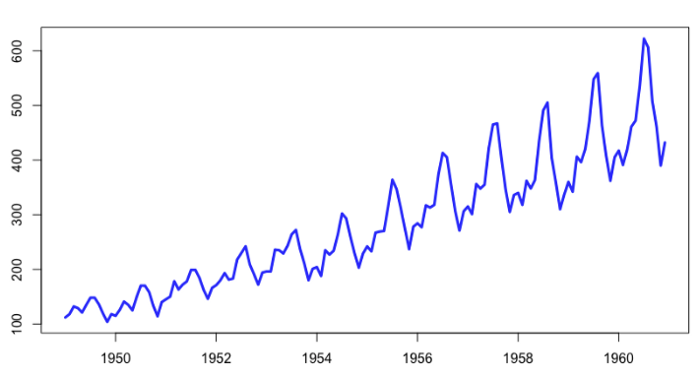
時間序列算法是用于分析時間相關數據的技術。這些算法考慮了一系列數據點之間的時間依賴性,這在嘗試預測未來值時尤為重要。
時間序列算法用于各種業務應用程序,例如預測產品需求、預測銷售或分析客戶隨時間變化的行為。它們還可用于檢測數據中的異常或趨勢變化。
算法
Prophet 時間序列建模:Facebook 開發的一種時間序列預測算法,旨在直觀且易于使用。它的一些主要優勢包括處理缺失數據和趨勢變化、對異常值具有魯棒性以及快速適應。
自回歸積分移動平均 (ARIMA):一種用于預測時間序列數據的統計方法,它對數據與其滯后值之間的相關性進行建模。ARIMA 可以處理范圍廣泛的時間序列數據,但可能比其他一些方法更難實現。
指數平滑:一種預測時間序列數據的方法,它使用過去數據的加權平均值來進行預測。指數平滑實現起來相對簡單,可用于范圍廣泛的數據,但性能可能不如更復雜的方法。
6.相似度算法
相似度算法用于衡量成對的記錄、節點、數據點或文本之間的相似度。這些算法可以基于兩個數據點之間的距離(例如歐氏距離)或基于文本的相似性(例如 Levenshtein 算法)。
這些算法具有廣泛的應用,但在推薦方面特別有用。它們可用于識別相似的項目或向用戶推薦相關內容。
算法
歐氏距離:歐氏空間中兩點之間直線距離的度量。歐氏距離計算簡單,廣泛應用于機器學習,但在數據分布不均勻的情況下可能不是最佳選擇。
余弦相似度:基于兩個向量之間的角度來衡量兩個向量之間的相似度。
Levenshtein 算法:一種用于測量兩個字符串之間距離的算法,基于將一個字符串轉換為另一個字符串所需的最小單字符編輯(插入、刪除或替換)次數。Levenshtein 算法通常用于拼寫檢查和字符串匹配任務。
Jaro-Winkler 算法:一種基于匹配字符數和換位數來衡量兩個字符串之間相似性的算法。它類似于 Levenshtein 算法,通常用于記錄鏈接和實體解析任務。
奇異值分解 (SVD):一種矩陣分解方法,可將一個矩陣分解為三個矩陣的乘積——它是最先進的推薦系統不可或缺的組成部分。
作者:我愛Python數據挖掘?
編輯:黃飛










 工商網監
工商網監
評論