 電子發(fā)燒友App
電子發(fā)燒友App


一. 什么是NLP?
自然語言處理是計算機科學(xué)領(lǐng)域與人工智能領(lǐng)域中的一個重要方向。它研究能實現(xiàn)人與計算機之間用自然語言進行有效通信的各種理論和方法。自然語言處理是一門融語言學(xué)、計算機科學(xué)、數(shù)學(xué)于一體的科學(xué)。因此,這一領(lǐng)域的研究將涉及自然語言,即人們?nèi)粘J褂玫恼Z言,所以它與語言學(xué)的研究有著密切的聯(lián)系,但又有重要的區(qū)別。自然語言處理并不是一般地研究自然語言,而在于研制能有效地實現(xiàn)自然語言通信的計算機系統(tǒng),特別是其中的軟件系統(tǒng)。因而它是計算機科學(xué)的一部分。
自然語言處理,即實現(xiàn)人機間自然語言通信,實現(xiàn)自然語言理解和自然語言生成是十分困難的。造成困難的根本原因是自然語言文本和對話的各個層次上廣泛存在的各種各樣的歧義性或多義性。用自然語言與計算機進行通信,這是人們長期以來所追求的。因為它既有明顯的實際意義,同時也有重要的理論意義:人們可以用自己最習(xí)慣的語言來使用計算機,而無需再花大量的時間和精力去學(xué)習(xí)不很自然和習(xí)慣的各種計算機語言;人們也可通過它進一步了解人類的語言能力和智能的機制。
能力模型,通常是基于語言學(xué)規(guī)則的模型,建立在人腦中先天存在語法通則這一假設(shè)的基礎(chǔ)上,認(rèn)為語言是人腦的語言能力推導(dǎo)出來的,建立語言模型就是通過建立人工編輯的語言規(guī)則集來模擬這種先天的語言能力。又稱“理性主義的”語言模型。
應(yīng)用模型,根據(jù)不同的語言處理應(yīng)用而建立的特定語言模型,通常是基于統(tǒng)計的模型。又稱“經(jīng)驗主義的”語言模型,使用大規(guī)模真實語料庫中獲得語言各級語言單位上的統(tǒng)計信息,依據(jù)較低級語言單位上的統(tǒng)計信息運用相關(guān)的統(tǒng)計推理技術(shù)計算較高級語言單位上的統(tǒng)計信息。
?
自然語言處理的基本架構(gòu):分詞=>詞性標(biāo)注=>Parser
1、分詞
詞是最小的能夠獨立活動的有意義的語言成分,英文單詞之間是以空格作為自然分界符的,而漢語是以字為基本的書寫單位,詞語之間沒有明顯的區(qū)分標(biāo)記,因此,中文詞語分析是中文信息處理的基礎(chǔ)與關(guān)鍵。
中文分詞技術(shù)可分為三大類:基于字典、詞庫匹配的分詞方法;基于詞頻度統(tǒng)計的分詞方法和基于知識理解的分詞方法。
2、詞性標(biāo)注(Part-of-Speech tagging 或POS tagging),又稱詞類標(biāo)注或者簡稱標(biāo)注,是指為分詞結(jié)果中的每個單詞標(biāo)注一個正確的詞性的程序,也即確定每個詞是名詞、動詞、形容詞或其他詞性的過程。在漢語中,詞性標(biāo)注比較簡單,因為漢語詞匯詞性多變的情況比較少見,大多詞語只有一個詞性,或者出現(xiàn)頻次最高的詞性遠(yuǎn)遠(yuǎn)高于第二位的詞性。據(jù)說,只需選取最高頻詞性,即可實現(xiàn)80%準(zhǔn)確率的中文詞性標(biāo)注程序。利用HMM即可實現(xiàn)更高準(zhǔn)確率的詞性標(biāo)注。
3、名實體識別
命名實體識別(Named Entity Recognition,簡稱NER),又稱作“專名識別”,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構(gòu)名、專有名詞等。
(1)實體邊界識別;(2) 確定實體類別(人名、地名、機構(gòu)名或其他)
命名實體識別是信息提取、問答系統(tǒng)、句法分析、機器翻譯、面向Semantic Web的元數(shù)據(jù)標(biāo)注等應(yīng)用領(lǐng)域的重要基礎(chǔ)工具。
基于規(guī)則和詞典的方法( MUC-6 會議中幾乎所有參賽成員都采用基于規(guī)則的方法),該方法需要專家制定規(guī)則,準(zhǔn)確率較高,但依賴于特征領(lǐng)域,可移植性差;
基于統(tǒng)計的方法,主要采用 HMM 、 MEMM 、 CRF, 難點在于特征選擇上,該方法能獲得好的魯棒性和靈活性,不需太多的人工干預(yù)和領(lǐng)域限制,但需要大量的標(biāo)注集。
混合方法,采用規(guī)則與統(tǒng)計相結(jié)合,多種統(tǒng)計方法相結(jié)合等,是目前主流的方法。
特征:上下文信息+構(gòu)詞法
4、指代消解
指代是一種常見的語言現(xiàn)象,一般情況下,指代分為2種:回指和共指。
回指是指當(dāng)前的照應(yīng)語與上文出現(xiàn)的詞、短語或句子(句群)存在密切的語義關(guān)聯(lián)性,指代依存于上下文語義中,在不同的語言環(huán)境中可能指代不同的實體,具有非對稱性和非傳遞性;
共指主要是指2個名詞(包括代名詞、名詞短語)指向真實世界中的同一參照體,這種指代脫離上下文仍然成立。
目前指代消解研究主要側(cè)重于等價關(guān)系,只考慮2個詞或短語是否指示現(xiàn)實世界中同一實體的問題,即共指消解。
中文的指代主要有3種典型的形式:
(1)人稱代詞(pronoun),例如:李明 怕高媽媽一人呆在家
里寂寞,他 便將家里的電視搬了過來。
(2)指示代詞(demonstrative),例如:很多人都想留下什么給孩子,這 可以理解,但不完全正確。
(3)有定描述(definite description),例如:,貿(mào)易制裁已經(jīng)成為了美國政府對華的慣用大棒,這根 大棒 真如美國政府所希望的那樣靈驗嗎?
5、文本分類
一個文本(以下基本不區(qū)分“文本”和“文檔”兩個詞的含義) 分類問題就是將
一篇文檔歸入預(yù)先定義的幾個類別中的一個或幾個,而文本的自動分類則是使用計算機程序來實現(xiàn)這樣的分類。
6、問答系統(tǒng)
問答系統(tǒng)(Question Answering System, QA)是信息檢索系統(tǒng)的一種高級形式,它能用準(zhǔn)確、簡潔的自然語言回答用戶用自然語言提出的問題。
依據(jù)問題類型可分為:限定域和開放域兩種,依據(jù)數(shù)據(jù)類型可分為:結(jié)構(gòu)型和無結(jié)構(gòu)型(文本),依據(jù)答案類型可分為:抽取式和產(chǎn)生式兩種。
問句分析-》文檔檢索-》答案抽取(驗證)
?
自然語言處理工具包:
中文的是哈工大開源的那個工具包 LTP (Language Technology Platform) developed by HIT-SCIR(哈爾濱工業(yè)大學(xué)社會計算與信息檢索研究中心)。
英文的(python):
· pattern - simpler to get started than NLTK
· chardet - character encoding detection
· pyenchant - easy access to dictionaries
· scikit-learn - has support for text classification
· unidecode - because ascii is much easier to deal with
掌握以下的幾個tool:
CRF++
GIZA
Word2Vec
? ? ?自然語言處理推薦學(xué)習(xí)書籍
現(xiàn)在自然語言處理都要靠統(tǒng)計學(xué)知識,下面推薦四本自然語言處理領(lǐng)域的標(biāo)準(zhǔn)書籍
《數(shù)學(xué)之美》,這個書寫得特別科普且生動形象,我相信你不會覺得枯燥
《統(tǒng)計學(xué)習(xí)方法》
《自然語言處理綜論》
《統(tǒng)計自然語言處理基礎(chǔ)》
《自然語言理解》
#e#
自然語言處理概況
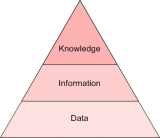
自然語言處理是研究計算機處理人類語言的一門技術(shù),包括:
1.句法語義分析:對于給定的句子,進行分詞、詞性標(biāo)記、命名實體識別和鏈接、句法分析、語義角色識別和多義詞消歧。
2.信息抽取:從給定文本中抽取重要的信息,比如,時間、地點、人物、事件、原因、結(jié)果、數(shù)字、日期、貨幣、專有名詞等等。通俗說來,就是要了解誰在什么時候、什么原因、對誰、做了什么事、有什么結(jié)果。涉及到實體識別、時間抽取、因果關(guān)系抽取等關(guān)鍵技術(shù)。
3.文本挖掘(或者文本數(shù)據(jù)挖掘):包括文本聚類、分類、信息抽取、摘要、情感分析以及對挖掘的信息和知識的可視化、交互式的表達(dá)界面。目前主流的技術(shù)都是基于統(tǒng)計機器學(xué)習(xí)的。
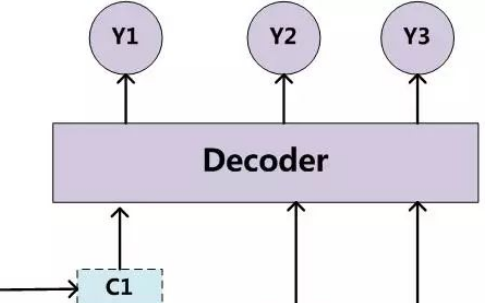
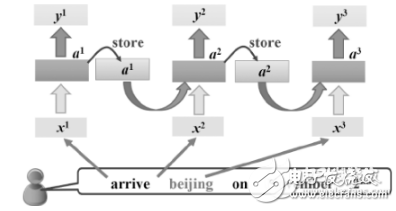
4.機器翻譯:把輸入的源語言文本通過自動翻譯獲得另外一種語言的文本。根據(jù)輸入媒介不同,可以細(xì)分為文本翻譯、語音翻譯、手語翻譯、圖形翻譯等。機器翻譯從最早的基于規(guī)則的方法到二十年前的基于統(tǒng)計的方法,再到今天的基于神經(jīng)網(wǎng)絡(luò)(編碼-解碼)的方法,逐漸形成了一套比較嚴(yán)謹(jǐn)?shù)姆椒w系。
5.信息檢索:對大規(guī)模的文檔進行索引。可簡單對文檔中的詞匯,賦之以不同的權(quán)重來建立索引,也可利用1,2,3的技術(shù)來建立更加深層的索引。在查詢的時候,對輸入的查詢表達(dá)式比如一個檢索詞或者一個句子進行分析,然后在索引里面查找匹配的候選文檔,再根據(jù)一個排序機制把候選文檔排序,最后輸出排序得分最高的文檔。
6.問答系統(tǒng): 對一個自然語言表達(dá)的問題,由問答系統(tǒng)給出一個精準(zhǔn)的答案。需要對自然語言查詢語句進行某種程度的語義分析,包括實體鏈接、關(guān)系識別,形成邏輯表達(dá)式,然后到知識庫中查找可能的候選答案并通過一個排序機制找出最佳的答案。
7.對話系統(tǒng):系統(tǒng)通過一系列的對話,跟用戶進行聊天、回答、完成某一項任務(wù)。涉及到用戶意圖理解、通用聊天引擎、問答引擎、對話管理等技術(shù)。此外,為了體現(xiàn)上下文相關(guān),要具備多輪對話能力。同時,為了體現(xiàn)個性化,要開發(fā)用戶畫像以及基于用戶畫像的個性化回復(fù)。
隨著深度學(xué)習(xí)在圖像識別、語音識別領(lǐng)域的大放異彩,人們對深度學(xué)習(xí)在NLP的價值也寄予厚望。再加上AlphaGo的成功,人工智能的研究和應(yīng)用變得炙手可熱。自然語言處理作為人工智能領(lǐng)域的認(rèn)知智能,成為目前大家關(guān)注的焦點。很多研究生都在進入自然語言領(lǐng)域,寄望未來在人工智能方向大展身手。但是,大家常常遇到一些問題。俗話說,萬事開頭難。如果第一件事情成功了,學(xué)生就能建立信心,找到竅門,今后越做越好。否則,也可能就灰心喪氣,甚至離開這個領(lǐng)域。這里針對給出我個人的建議,希望我的這些粗淺觀點能夠引起大家更深層次的討論
建議1:如何在NLP領(lǐng)域快速學(xué)會第一個技能?
我的建議是:找到一個開源項目,比如機器翻譯或者深度學(xué)習(xí)的項目。理解開源項目的任務(wù),編譯通過該項目發(fā)布的示范程序,得到與項目示范程序一致的結(jié)果。然后再深入理解開源項目示范程序的算法。自己編程實現(xiàn)一下這個示范程序的算法。再按照項目提供的標(biāo)準(zhǔn)測試集測試自己實現(xiàn)的程序。如果輸出的結(jié)果與項目中出現(xiàn)的結(jié)果不一致,就要仔細(xì)查驗自己的程序,反復(fù)修改,直到結(jié)果與示范程序基本一致。如果還是不行,就大膽給項目的作者寫信請教。在此基礎(chǔ)上,再看看自己能否進一步完善算法或者實現(xiàn),取得比示范程序更好的結(jié)果。
建議2:如何選擇第一個好題目?
工程型研究生,選題很多都是老師給定的。需要采取比較實用的方法,扎扎實實地動手實現(xiàn)。可能不需要多少理論創(chuàng)新,但是需要較強的實現(xiàn)能力和綜合創(chuàng)新能力。而學(xué)術(shù)型研究生需要取得一流的研究成果,因此選題需要有一定的創(chuàng)新。我這里給出如下的幾點建議。
· 先找到自己喜歡的研究領(lǐng)域。你找到一本最近的ACL會議論文集, 從中找到一個你比較喜歡的領(lǐng)域。在選題的時候,多注意選擇藍(lán)海的領(lǐng)域。這是因為藍(lán)海的領(lǐng)域,相對比較新,容易出成果。
· 充分調(diào)研這個領(lǐng)域目前的發(fā)展?fàn)顩r。包括如下幾個方面的調(diào)研:方法方面,是否有一套比較清晰的數(shù)學(xué)體系和機器學(xué)習(xí)體系;數(shù)據(jù)方面,有沒有一個大家公認(rèn)的標(biāo)準(zhǔn)訓(xùn)練集和測試集;研究團隊,是否有著名團隊和人士參加。如果以上幾個方面的調(diào)研結(jié)論不是太清晰,作為初學(xué)者可能不要輕易進入。
· 在確認(rèn)進入一個領(lǐng)域之后,按照建議一所述,需要找到本領(lǐng)域的開源項目或者工具,仔細(xì)研究一遍現(xiàn)有的主要流派和方法,先入門。
· 反復(fù)閱讀本領(lǐng)域最新發(fā)表的文章,多閱讀本領(lǐng)域牛人發(fā)表的文章。在深入了解已有工作的基礎(chǔ)上,探討還有沒有一些地方可以推翻、改進、綜合、遷移。注意做實驗的時候,不要貪多,每次實驗只需要驗證一個想法。每次實驗之后,必須要進行分析存在的錯誤,找出原因。
· 對成功的實驗,進一步探討如何改進算法。注意實驗數(shù)據(jù)必須是業(yè)界公認(rèn)的數(shù)據(jù)。
· 與已有的算法進行比較,體會能夠得出比較一般性的結(jié)論。如果有,則去寫一篇文章,否則,應(yīng)該換一個新的選題。
建議3:如何寫出第一篇論文?
· 接上一個問題,如果想法不錯,且被實驗所證明,就可開始寫第一篇論文了。
· 確定論文的題目。在定題目的時候,一般不要“…系統(tǒng)”、“…研究與實踐”,要避免太長的題目,因為不好體現(xiàn)要點。題目要具體,有深度,突出算法。
· 寫論文摘要。要突出本文針對什么重要問題,提出了什么方法,跟已有工作相比,具有什么優(yōu)勢。實驗結(jié)果表明,達(dá)到了什么水準(zhǔn),解決了什么問題。
· 寫引言。首先講出本項工作的背景,這個問題的定義,它具有什么重要性。然后介紹對這個問題,現(xiàn)有的方法是什么,有什么優(yōu)點。但是(注意但是)現(xiàn)有的方法仍然有很多缺陷或者挑戰(zhàn)。比如(注意比如),有什么問題。本文針對這個問題,受什么方法(誰的工作)之啟發(fā),提出了什么新的方法并做了如下幾個方面的研究。然后對每個方面分門別類加以敘述,最后說明實驗的結(jié)論。再說本文有幾條貢獻,一般寫三條足矣。然后說說文章的章節(jié)組織,以及本文的重點。有的時候東西太多,篇幅有限,只能介紹最重要的部分,不需要面面俱到。
· 相關(guān)工作。對相關(guān)工作做一個梳理,按照流派劃分,對主要的最多三個流派做一個簡單介紹。介紹其原理,然后說明其局限性。
· 然后可設(shè)立兩個章節(jié)介紹自己的工作。第一個章節(jié)是算法描述。包括問題定義,數(shù)學(xué)符號,算法描述。文章的主要公式基本都在這里。有時候要給出簡明的推導(dǎo)過程。如果借鑒了別人的理論和算法,要給出清晰的引文信息。在此基礎(chǔ)上,由于一般是基于機器學(xué)習(xí)或者深度學(xué)習(xí)的方法,要介紹你的模型訓(xùn)練方法和解碼方法。第二章就是實驗環(huán)節(jié)。一般要給出實驗的目的,要檢驗什么,實驗的方法,數(shù)據(jù)從哪里來,多大規(guī)模。最好數(shù)據(jù)是用公開評測數(shù)據(jù),便于別人重復(fù)你的工作。然后對每個實驗給出所需的技術(shù)參數(shù),并報告實驗結(jié)果。同時為了與已有工作比較,需要引用已有工作的結(jié)果,必要的時候需要重現(xiàn)重要的工作并報告結(jié)果。用實驗數(shù)據(jù)說話,說明你比人家的方法要好。要對實驗結(jié)果好好分析你的工作與別人的工作的不同及各自利弊,并說明其原因。對于目前尚不太好的地方,要分析問題之所在,并將其列為未來的工作。













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論