 電子發(fā)燒友App
電子發(fā)燒友App


我們知道的HDFS、Gluster、Ceph、Swift等互聯(lián)網(wǎng)常用的大規(guī)模集群文件系統(tǒng)無一例外都屬于分布式集群文件系統(tǒng)。分布式集群文件系統(tǒng)可擴(kuò)展性更強(qiáng),目前已知最大可擴(kuò)展至10K節(jié)點(diǎn)。對(duì)于分布式集群,其對(duì)文件元數(shù)據(jù)的管理方式又可以分為single path image和single filesystem image兩種方式。
異常分類
分布式存儲(chǔ)系統(tǒng)所關(guān)注的異常類型和單體系統(tǒng)不一樣,有如下幾種:
服務(wù)器宕機(jī):設(shè)計(jì)存儲(chǔ)系統(tǒng)時(shí)需要考慮如何通過讀取持久化介質(zhì)(如機(jī)械硬盤,固態(tài)硬盤)中的數(shù)據(jù)來恢復(fù)內(nèi)存信息。
網(wǎng)絡(luò)異常:設(shè)計(jì)容錯(cuò)系統(tǒng)的一個(gè)基本原則是:網(wǎng)絡(luò)永遠(yuǎn)是不可靠的,任何一個(gè)消息只有收到對(duì)方的回復(fù)后才可以認(rèn)為發(fā)送成功,系統(tǒng)設(shè)計(jì)時(shí)總是假設(shè)網(wǎng)絡(luò)將會(huì)出現(xiàn)異常并采取相應(yīng)的處理措施。
磁盤故障:對(duì)于磁盤數(shù)據(jù)錯(cuò)誤,往往可以采用校驗(yàn)和( checksum)機(jī)制來解決。
除了異常之外,還存在“超時(shí)”狀態(tài),RPC執(zhí)行的結(jié)果有三種狀態(tài):“成功”、“失敗”、“超時(shí)”(未知狀態(tài)),也稱為分布式存儲(chǔ)系統(tǒng)的三態(tài)。
一致性保證
副本是分布式存儲(chǔ)系統(tǒng)容錯(cuò)技術(shù)的唯一手段。由于多個(gè)副本的存在,如何保證副本之間的一致性是整個(gè)分布式系統(tǒng)的理論核心。從客戶端的角度來看,一致性包含如下三種情況:
1、強(qiáng)一致性:
2、弱一致性:
3、最終一致性:最終一致性是弱一致性的一種特例。“最終”一致性有一個(gè)“不一致窗口”(時(shí)間延遲),最終一致性描述比較粗略,其常見的變體如下:
會(huì)話( Session)-致性
單調(diào)讀( Monotonic read)-致性
單調(diào)寫( Monotonic write)-致性
從存儲(chǔ)系統(tǒng)的角度看,一致性主要包含如下幾個(gè)方面:
1) 副本一致性:存儲(chǔ)系統(tǒng)的多個(gè)副本之間的數(shù)據(jù)是否一致,不一致的時(shí)間窗口等;
2) 更新順序一致性:存儲(chǔ)系統(tǒng)的多個(gè)副本之間是否按照相同的順序執(zhí)行更新操作。
衡量指標(biāo)
評(píng)價(jià)分布式存儲(chǔ)系統(tǒng)有一些常用的指標(biāo):
性能:吞吐能力(QPS、TPS)、響應(yīng)延遲。
可用性:系統(tǒng)的可用性可以用系統(tǒng)停服務(wù)的時(shí)間與正常服務(wù)的時(shí)間的比例來衡量。
一致性:越是強(qiáng)的一致性模型,用戶使用起來越簡單。如果系統(tǒng)部署在同一個(gè)數(shù)據(jù)中心,只要系統(tǒng)設(shè)計(jì)合理,在保證強(qiáng)一致性的前提下,不會(huì)對(duì)性能和可用性造成太大的影響。
可擴(kuò)展性:系統(tǒng)的可擴(kuò)展性( scalability)指分布式存儲(chǔ)系統(tǒng)通過擴(kuò)展集群服務(wù)器規(guī)模來提高系統(tǒng)存儲(chǔ)容量、計(jì)算量和性能的能力。
性能分析
一般來說,對(duì)分布式系統(tǒng)的性能分析的結(jié)果是不精確的,然而,至少可以保證,估算的結(jié)果與實(shí)際值不會(huì)相差一個(gè)數(shù)量級(jí)。舉個(gè)例子,Google的BigTable中隨機(jī)寫和順序?qū)懙男阅苁遣畈欢嗟模瑢懭氩僮餍枰紫葘⒉僮魅罩緦懭氲紾FS,接著修改本地內(nèi)存。為了提高性能,BigTable實(shí)現(xiàn)了成組提示技術(shù)。
只有理解存儲(chǔ)系統(tǒng)的底層設(shè)計(jì)和實(shí)現(xiàn),并在實(shí)踐中不斷地練習(xí),性能估算才會(huì)越來越準(zhǔn)。
數(shù)據(jù)分布
1、哈希分布(代表:Dynomo):如果哈希函數(shù)的散列特性很好,哈希方式可以將數(shù)據(jù)比較均勻地分布到集群中去。然而,找出一個(gè)散列特性很好的哈希函數(shù)是很難的。這是因?yàn)椋绻凑罩麈I散列,那么同一個(gè)用戶id下的數(shù)據(jù)可能被分散到多臺(tái)服務(wù)器,這會(huì)使得一次操作同一個(gè)用戶id下的多條記錄變得困難;如果按照用戶id散列,容易出現(xiàn)“數(shù)據(jù)傾斜”(data skew)問題,即某些大用戶的數(shù)據(jù)量很大,無論集群的規(guī)模有多大,這些用戶始終由一臺(tái)服務(wù)器處理。另一種思路就是采用一致性哈希( Distributed Hash Table,DHT)算法(順時(shí)針查找)。一致性哈希的優(yōu)點(diǎn)在于節(jié)點(diǎn)加入/刪除時(shí)只會(huì)影響到在哈希環(huán)中相鄰的節(jié)點(diǎn),而對(duì)其他節(jié)點(diǎn)沒影響。一致性哈希算法在很大程度上避免了數(shù)據(jù)遷移。Dynamo系統(tǒng)通過犧牲空間換時(shí)間,在每臺(tái)服務(wù)器維護(hù)整個(gè)集群中所有服務(wù)器的位置信息,將查找服務(wù)器的時(shí)間復(fù)雜度降為O(l)。一致性哈希還需要考慮負(fù)載均衡,比較好的做法是引入“虛擬節(jié)點(diǎn)”的概念。
2、順序分布(代表:BigTable):哈希散列破壞了數(shù)據(jù)的有序性,只支持隨機(jī)讀取操作,不能夠支持順序掃描。順序分布在分布式表格系統(tǒng)中比較常見,一般的做法是將大表順序劃分為連續(xù)的范圍,每個(gè)范圍稱為一個(gè)子表。Bigtable將一張大表根據(jù)主鍵切分為有序的范圍,每個(gè)有序范圍是一個(gè)子表。為了支持更大的集群規(guī)模,Bigtable這樣的系統(tǒng)將索引分為兩級(jí):根表以及元數(shù)據(jù)表(Meta表),由Meta表維護(hù)User表的位置信息。順序分布與B+樹數(shù)據(jù)結(jié)構(gòu)比較類似,每個(gè)子表相當(dāng)于葉子節(jié)點(diǎn),隨著數(shù)據(jù)的插入和刪除,某些子表可能變得很大,某些變得很小,數(shù)據(jù)分布不均勻。如果采用順序分布,系統(tǒng)設(shè)計(jì)時(shí)需要考慮子表的分裂與合并。子表合并的目的是為了防止系統(tǒng)中出現(xiàn)過多太小的子表,減少系統(tǒng)中的元數(shù)據(jù)。
3、負(fù)載均衡:工作節(jié)點(diǎn)通過心跳包(Heartbeat,定時(shí)發(fā)送)將節(jié)點(diǎn)負(fù)載相關(guān)的信息,如CPU,內(nèi)存,磁盤,網(wǎng)絡(luò)等資源使用率,讀寫次數(shù)及讀寫數(shù)據(jù)量等發(fā)送給主控節(jié)點(diǎn)。負(fù)載均衡操作需要控制節(jié)奏,負(fù)載均衡操作需要做到比較平滑,一般來說,從新機(jī)器加入,到集群負(fù)載達(dá)到比較均衡的狀態(tài)需要較長一段時(shí)間,比如30分鐘到一個(gè)小時(shí)。
復(fù)制
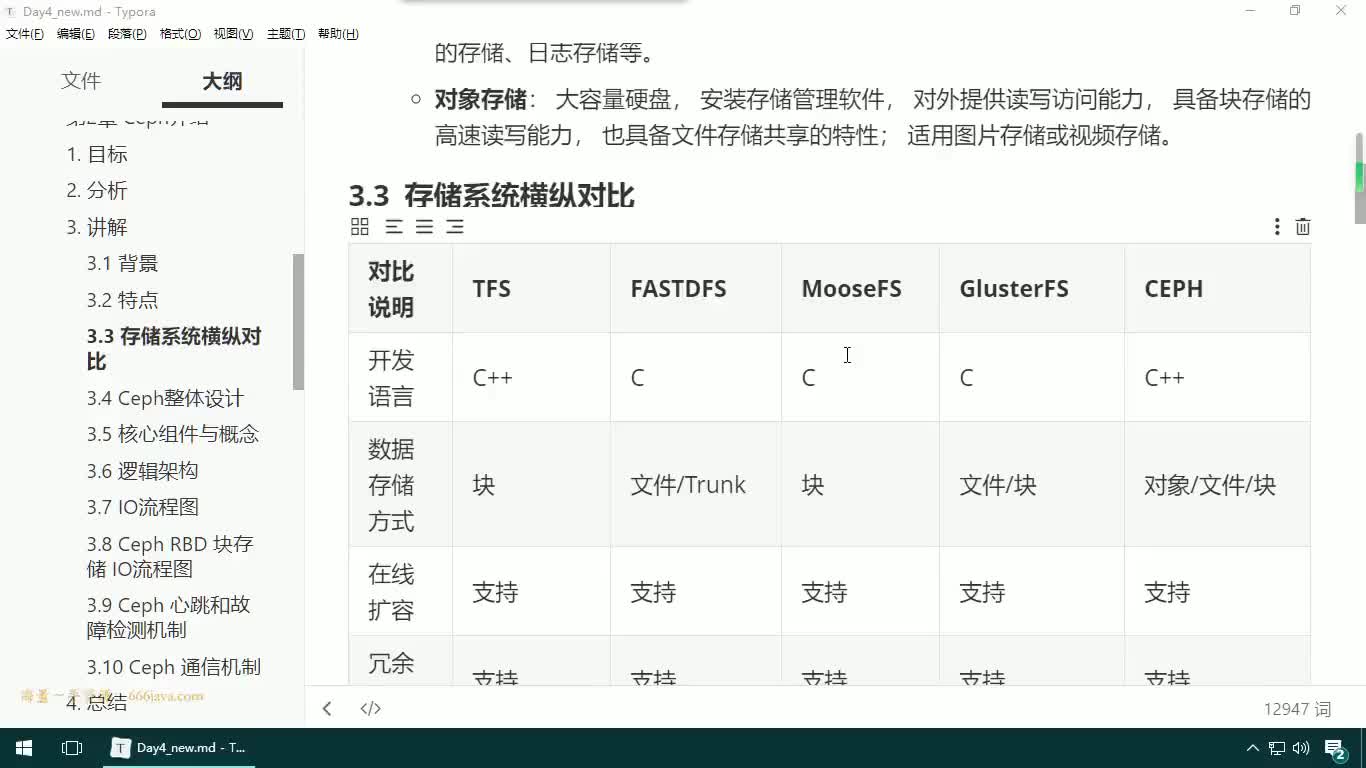
復(fù)制協(xié)議分為兩種:強(qiáng)同步復(fù)制和異步復(fù)制,如圖1。
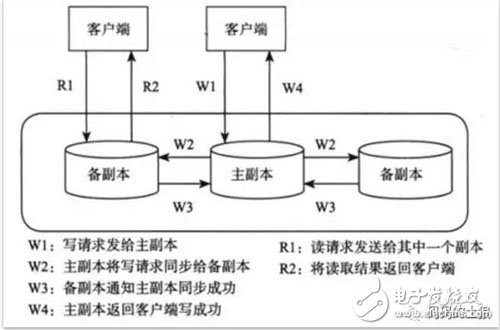
圖1 主備復(fù)制協(xié)議示范
強(qiáng)同步復(fù)制和異步復(fù)制都是將主副本的數(shù)據(jù)以某種形式發(fā)送到其他副本,這種復(fù)制協(xié)議稱為基于主副本的復(fù)制協(xié)議( Primary-based protocol)。這種方法要求在任何時(shí)刻只能有一個(gè)副本為主副本,由它來確定寫操作之間的順序。如果主副本出現(xiàn)故障,需要選舉一個(gè)備副本成為新的主副本,這步操作稱為選舉,經(jīng)典的選舉協(xié)議為Paxos協(xié)議。
主備副本之間的復(fù)制一般通過操作日志來實(shí)現(xiàn)。操作日志的原理很簡單:為了利用好磁盤的順序讀寫特性,將客戶端的寫操作先順序?qū)懭氲酱疟P中,然后應(yīng)用到內(nèi)存中,由于內(nèi)存是隨機(jī)讀寫設(shè)備,可以很容易通過各種數(shù)據(jù)結(jié)構(gòu),比如B+樹將數(shù)據(jù)有效地組織起來。當(dāng)服務(wù)器宕機(jī)重啟時(shí),只需要回放操作日志就可以恢復(fù)內(nèi)存狀態(tài)。為了提高系統(tǒng)的并發(fā)能力,系統(tǒng)會(huì)積攢一定的操作日志再批量寫入到磁盤中,這種技術(shù)一般稱為成組提交。
如果每次服務(wù)器出現(xiàn)故障都需要回放所有的操作日志,效率是無法忍受的,檢查點(diǎn)( CheckPoint)正是為了解決這個(gè)問題。系統(tǒng)定期將內(nèi)存狀態(tài)以檢查點(diǎn)文件的形式dump到磁盤中,并記錄檢查點(diǎn)時(shí)刻對(duì)應(yīng)的操作日志回放點(diǎn)。檢查點(diǎn)文件成功創(chuàng)建后,回放點(diǎn)之前的日志可以被垃圾回收,以后如果服務(wù)器出現(xiàn)故障,只需要回放檢查點(diǎn)之后的操作日志。(內(nèi)存中只有“檢查點(diǎn)”之后的數(shù)據(jù))
分布式存儲(chǔ)系統(tǒng)要求能夠自動(dòng)容錯(cuò),也就是說,CAP理論中的“分區(qū)可容忍性”總是需要滿足的,因此,一致性和寫操作的可用性不能同時(shí)滿足。例如,Oracle教據(jù)庫的DataGuard復(fù)制組件包含三種模式:
最大保護(hù)模式( Maximum Protection):即強(qiáng)同步復(fù)制模式,寫操作要求主庫先將操作日志(數(shù)據(jù)庫的redo/undo日志)同步到至少一個(gè)備庫才可以返回客戶端成功。
最大性能模式( Maximum Performance):即異步復(fù)制模式,寫操作只需要在主庫上執(zhí)行成功就可以返回客戶端成功。
最大可用性模式( Maximum Availability):上述兩種模式的折衷。
容錯(cuò)
常見故障中,單機(jī)故障和磁盤故障發(fā)生概率最高。在分布式系統(tǒng)中,可以通過租約(Lease)機(jī)制進(jìn)行故障檢測(cè)。
租約機(jī)制就是帶有超時(shí)時(shí)間的一種授權(quán)。假設(shè)機(jī)器A需要檢測(cè)機(jī)器B是否發(fā)生故障,機(jī)器A可以給機(jī)器B發(fā)放租約,機(jī)器B持有的租約在有效期內(nèi)才允許提供服務(wù),否則主動(dòng)停止服務(wù)。需要注意的是,實(shí)現(xiàn)租約機(jī)制時(shí)需要考慮一個(gè)提前量。
故障恢復(fù)中,總控節(jié)點(diǎn)一般需要等待一段時(shí)間,比如1個(gè)小時(shí),如果之前下線的節(jié)點(diǎn)重新上線,可以認(rèn)為是臨時(shí)性故障,否則,認(rèn)為是永久性故障。停服務(wù)時(shí)間包含兩個(gè)部分,故障檢測(cè)時(shí)間以及故障恢復(fù)時(shí)間。故障檢測(cè)時(shí)間一般在幾秒到十幾秒,和集群規(guī)模密切相關(guān),集群規(guī)模越大,故障檢測(cè)對(duì)總控節(jié)點(diǎn)造成的壓力就越大,故障檢測(cè)時(shí)間就越長。
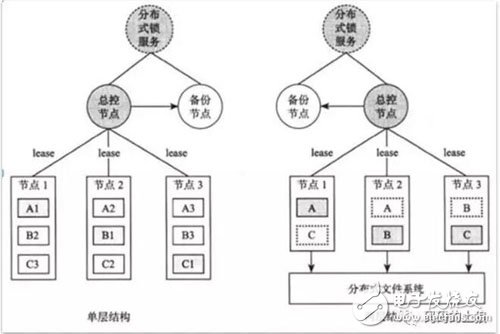
圖2 故障恢復(fù)
可擴(kuò)展性
分布式存儲(chǔ)系統(tǒng)大多都帶有總控節(jié)點(diǎn),基于這點(diǎn),很多人會(huì)自然地認(rèn)為總控節(jié)點(diǎn)存在瓶頸問題,認(rèn)為去中心化的P2P架構(gòu)更有優(yōu)勢(shì)。然而,事實(shí)卻并非如此,主流的分布式存儲(chǔ)系統(tǒng)大多帶有總控節(jié)點(diǎn),且能夠支持成千上萬臺(tái)的集群規(guī)模。可擴(kuò)展性應(yīng)該綜合考慮節(jié)點(diǎn)故障后的恢復(fù)時(shí)間,擴(kuò)容的自動(dòng)化程度,擴(kuò)容的靈活性等。
分布式存儲(chǔ)系統(tǒng)中往往有一個(gè)總控節(jié)點(diǎn)用于維護(hù)數(shù)據(jù)分布信息,執(zhí)行工作機(jī)管理,數(shù)據(jù)定位,故障檢測(cè)和恢復(fù),負(fù)載均衡等全局調(diào)度工作。通過引入總控節(jié)點(diǎn),可以使得系統(tǒng)的設(shè)計(jì)更加簡單,并且更加容易做到強(qiáng)一致性,對(duì)用戶友好。那么,總控節(jié)點(diǎn)是否會(huì)成為性能瓶頸呢?如果總控節(jié)點(diǎn)成為瓶頸,例如需要支持超過一萬臺(tái)的集群規(guī)模,或者需要支持海量的小文件,那么,可以采用兩級(jí)結(jié)構(gòu),如圖3所示。
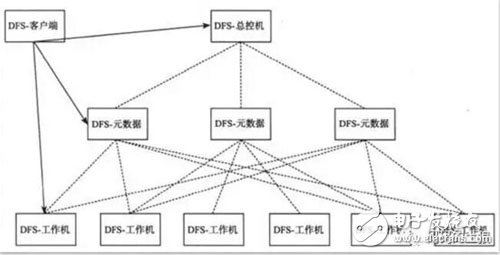
圖3 兩級(jí)元數(shù)據(jù)結(jié)構(gòu)
在數(shù)據(jù)庫的擴(kuò)容中,如果系統(tǒng)的讀取能力不足,可以通過增加副本的方式解決,如果系統(tǒng)的寫入能力不足,可以根據(jù)業(yè)務(wù)的特點(diǎn)重新拆分?jǐn)?shù)據(jù),常見的做法為雙倍擴(kuò)容,即將每個(gè)分片的數(shù)據(jù)拆分為兩個(gè)分片,擴(kuò)容的過程中需要遷移一半的數(shù)據(jù)到新加入的存儲(chǔ)節(jié)點(diǎn)。傳統(tǒng)的數(shù)據(jù)庫架構(gòu)在可擴(kuò)展性上面臨如下問題:
1. 擴(kuò)容不夠靈活。
2. 擴(kuò)容不夠自動(dòng)化。
3. 增加副本時(shí)間長。
同一個(gè)組內(nèi)的節(jié)點(diǎn)服務(wù)相同的數(shù)據(jù),這樣的系統(tǒng)稱為同構(gòu)系統(tǒng)。同構(gòu)系統(tǒng)的問題在于增加副本需要遷移的數(shù)據(jù)量太大,由于拷貝數(shù)據(jù)的過程中存儲(chǔ)節(jié)點(diǎn)再次發(fā)生故障的概率很高,所以這樣的架構(gòu)很難做到自動(dòng)化,不適用大規(guī)模分布式存儲(chǔ)系統(tǒng)。而異構(gòu)系統(tǒng)將數(shù)據(jù)劃分為很多大小接近的分片,每個(gè)分片的多個(gè)副本可以分布到集群中的任何一個(gè)存儲(chǔ)節(jié)點(diǎn)。由于整個(gè)集群都參與到節(jié)點(diǎn)的故障恢復(fù)過程,故障恢復(fù)時(shí)間很短,而且集群規(guī)模越大,優(yōu)勢(shì)就會(huì)越明顯。
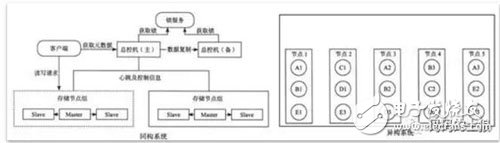
圖4 同構(gòu)系統(tǒng)和異構(gòu)系統(tǒng)的區(qū)別
分布式協(xié)議
在計(jì)算機(jī)世界里,為了解決一件事情,另外的問題就會(huì)接踵而至,從另一個(gè)層面印證了IT架構(gòu)永遠(yuǎn)是一種平衡的藝術(shù)。
“BASE”其核心思想是根據(jù)業(yè)務(wù)特點(diǎn),采用適當(dāng)?shù)姆绞絹硎瓜到y(tǒng)達(dá)到最終一致性(Eventual consistency);在互聯(lián)網(wǎng)領(lǐng)域,通常需要犧牲強(qiáng)一致性來換取系統(tǒng)的高可用性,只需要保證數(shù)據(jù)的“最終一致”,只是這個(gè)最終時(shí)間需要在用戶可以接受的范圍內(nèi);但在金融相關(guān)的交易領(lǐng)域,仍然需要采用強(qiáng)一致性的方式來保障交易的準(zhǔn)確性與可靠性。
業(yè)界常見的事務(wù)處理模式很多,包括兩階段提交、三階段提交、Sagas長事務(wù)、補(bǔ)償模式、可靠事件模式(本地事件表、外部事件表)、可靠事件模式(非事務(wù)消息、事務(wù)消息)、TCC、Paxos及其相關(guān)變種等等。不同的事務(wù)模型支持不同的數(shù)據(jù)一致性,這里我們不對(duì)每種協(xié)議都展開詳細(xì)討論,在分布式存儲(chǔ)方面,用的最多的是兩階段提交協(xié)議及Paxos協(xié)議,以下重點(diǎn)介紹這兩種協(xié)議。
1、兩階段提交協(xié)議( Two-phase Commit,2PC):經(jīng)常用來實(shí)現(xiàn)分布式事務(wù),在兩階段協(xié)議中,系統(tǒng)一般包含兩類節(jié)點(diǎn):一類為協(xié)調(diào)者( coordinator),通常一個(gè)系統(tǒng)中只有一個(gè);另一類為事務(wù)參與者(participants,cohorts或workers),一般包含多個(gè)。
協(xié)議中假設(shè)每個(gè)節(jié)點(diǎn)都會(huì)記錄操作日志并持久化到非易失性存儲(chǔ)介質(zhì),即使節(jié)點(diǎn)發(fā)生故障日志也不會(huì)丟失。在提交階段,協(xié)調(diào)者將基于第一個(gè)階段的投票結(jié)果進(jìn)行決策:提交或者取消。并通過引入事務(wù)的超時(shí)機(jī)制防止資源一直不能釋放的情況。
兩階段提交協(xié)議可能面臨兩種故障:
事務(wù)參與者發(fā)生故障。給每個(gè)事務(wù)設(shè)置一個(gè)超時(shí)時(shí)間,如果某個(gè)事務(wù)參與者一直不響應(yīng),到達(dá)超時(shí)時(shí)間后整個(gè)事務(wù)失敗。
協(xié)調(diào)者發(fā)生故障。協(xié)調(diào)者需要將事務(wù)相關(guān)信息記錄到操作日志并同步到備用協(xié)調(diào)者,假如協(xié)調(diào)者發(fā)生故障,備用協(xié)調(diào)者可以接替它完成后續(xù)的工作。如果沒有備用協(xié)調(diào)者,協(xié)調(diào)者又發(fā)生了永久性故障,事務(wù)參與者將無法完成事務(wù)而一直等待下去。
總而言之,兩階段提交協(xié)議是阻塞協(xié)議。
2、Paxos協(xié)議:用于解決多個(gè)節(jié)點(diǎn)之間的一致性問題。只要保證了多個(gè)節(jié)點(diǎn)之間操作日志的一致性,就能夠在這些節(jié)點(diǎn)上構(gòu)建高可用的全局服務(wù),例如分布式鎖服務(wù),全局命名和配置服務(wù)等。為了實(shí)現(xiàn)高可用性,主節(jié)點(diǎn)往往將數(shù)據(jù)以操作日志的形式同步到備節(jié)點(diǎn)。如果主節(jié)點(diǎn)發(fā)生故障,備節(jié)點(diǎn)會(huì)提議自己成為主節(jié)點(diǎn)。網(wǎng)絡(luò)分區(qū)的時(shí)候,可能會(huì)存在多個(gè)備節(jié)點(diǎn)提議(Proposer,提議者)自己成為主節(jié)點(diǎn)。Paxos協(xié)議保證,即使同時(shí)存在多個(gè)proposer,也能夠保證所有節(jié)點(diǎn)最終達(dá)成一致,即選舉出唯一的主節(jié)點(diǎn)。
(3)Paxos與2PC的區(qū)別:Paxos協(xié)議和2PC協(xié)議在分布式系統(tǒng)中所起的作用并不相同。Paxos協(xié)議用于保證同一個(gè)數(shù)據(jù)分片的多個(gè)副本之間的數(shù)據(jù)一致性。當(dāng)這些副本分布到不同的數(shù)據(jù)中心時(shí),這個(gè)需求尤其強(qiáng)烈。2PC協(xié)議用于保證屬于多個(gè)數(shù)據(jù)分片上的操作的原子性。這些數(shù)據(jù)分片可能分布在不同的服務(wù)器上,2PC協(xié)議保證多臺(tái)眼務(wù)器上的操作要么全部成功,要么全部失敗。
Paxos協(xié)議有兩種用法:一種用法是用它來實(shí)現(xiàn)全局的鎖服務(wù)或者命名和配置服務(wù),例如Google Chubby以及Apache Zookeeper。另外一種用法是用它來將用戶數(shù)據(jù)復(fù)制到多個(gè)數(shù)據(jù)中心,例如Google Megastore以及Google Spanner。
2PC協(xié)議最大的缺陷在于無法處理協(xié)調(diào)者宕機(jī)問題。如果協(xié)調(diào)者宕機(jī),那么,2PC協(xié)議中的每個(gè)參與者可能都不知道事務(wù)應(yīng)該提交還是回滾,整個(gè)協(xié)議被阻塞,執(zhí)行過程中申請(qǐng)的資源都無法釋放。因此,常見的做法是將2PC和Paxos協(xié)議結(jié)合起來,通過2PC保證多個(gè)數(shù)據(jù)分片上的操作的原子性,通過Paxos協(xié)議實(shí)現(xiàn)同一個(gè)數(shù)據(jù)分片的多個(gè)副本之間的一致性。另外,通過Paxos協(xié)議解決2PC協(xié)議中協(xié)調(diào)者宕機(jī)問題。當(dāng)2PC協(xié)議中的協(xié)調(diào)者出現(xiàn)故障時(shí),通過Paxos協(xié)議選舉出新的協(xié)調(diào)者繼續(xù)提供服務(wù)。
跨機(jī)房部署
機(jī)房之間的數(shù)據(jù)同步方式可能為強(qiáng)同步或者異步。如果采用異步模式,那么,備機(jī)房的數(shù)據(jù)總是落后于主機(jī)房;如果采用強(qiáng)同步模式,那么,備機(jī)房的數(shù)據(jù)和主機(jī)房保持一致。當(dāng)主機(jī)房出現(xiàn)故障時(shí),除了手工切換,還可以采用自動(dòng)切換的方式,即通過分布式鎖服務(wù)檢測(cè)主機(jī)房的服務(wù),當(dāng)主機(jī)房出現(xiàn)故障時(shí),自動(dòng)將備機(jī)房切換為主機(jī)房。






















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論