 大數據分析中Spark,Hadoop,Hive框架該用哪種開源分布式系統
大數據分析中Spark,Hadoop,Hive框架該用哪種開源分布式系統

眾所周知,大數據開發和分析、機器學習、數據挖掘中,都離不開各種開源分布式系統。最常見的就是 Hadoop、Hive、Spark這三個框架了。最近不少朋友有問到關于這些的問題:
大廠里還有在用 Hadoop 嗎?感覺都在用 Spark,有些慌!
SQL boy 大廠面試都問什么?Hadoop、Spark、Flink 都搞過!
聽說百度只用 Hadoop,為什么不用業界都在用的 Spark !
為什么百度不用SQL支持數據處理,還在寫一堆 Hadoop 腳本!
Java 開發需要對大數據了解多少,Hbase、Hive、Spark 這些嗎?
不同的業務場景決定了不同的系統架構選型。Hadoop 用于分布式存儲和 Map-Reduce 計算,Spark 用于分布式機器學習,Hive 則是分布式數據庫。Hive 和 Spark 是大數據領域內為不同目的而構建的不同產品。二者都有不可替代的優勢。Hive 是一個基于Hadoop 的分布式數據庫,Spark 則是一個用于數據分析的框架。
這就要求技術人不得不掌握各種開源的技術框架。這就會造成顧此失彼,學完易忘、易混淆的情況。為了解決這個問題,這里推薦給大家一個高效學習和開發的寶藏:一份大數據/分布式開發速查表。內容涵蓋:Spark、Hadoop及Hive等日常工作中幾乎所有的技術知識點。
對比詳細卻冗長的技術文檔,速查表要顯得更加便捷與直觀。可以幫大家很輕松的從上面找到具體某項技術的快捷命令與語法,相信能大幅提升開發效率,同時,一些遺忘的知識點也都能通過速查表來快速獲取。
由于篇幅原因,下面只展示了速查表的部分內容。無論你是學習進階,還是日后溫習,這套速查表資料都值得好好珍藏。
1.大數據內存計算框架之Spark 必知必會
學習 Spark ,從大方向說,算子大致可以分為以下兩類: (1)Transformation 變換 / 轉換算子:這種變換并不觸發提交作業,這種算子是延遲執行的,也就是說從一個 RDD 轉換生成另一個 RDD 的轉換操作不是馬上執行,需要等到有 Action 操作的時候才會真正觸發。 (2)Action 行動算子:這類算子會觸發 SparkContext 提交 job 作業,并將數據輸出到 Spark 系統。
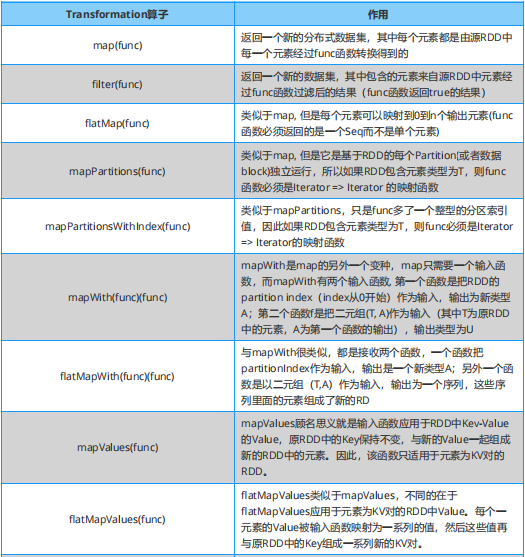
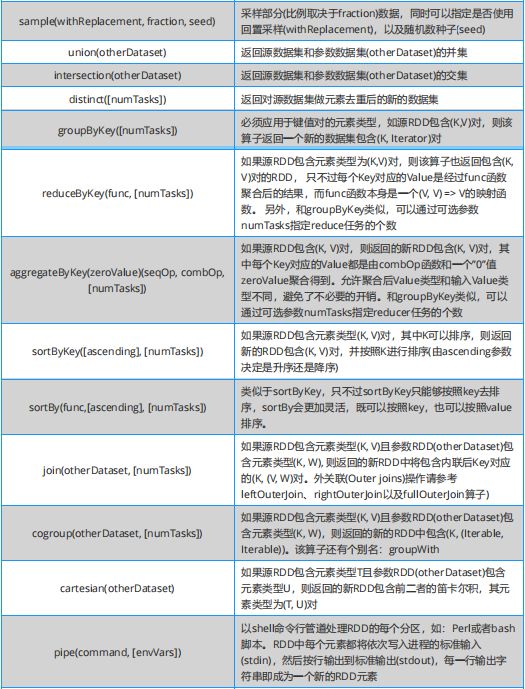
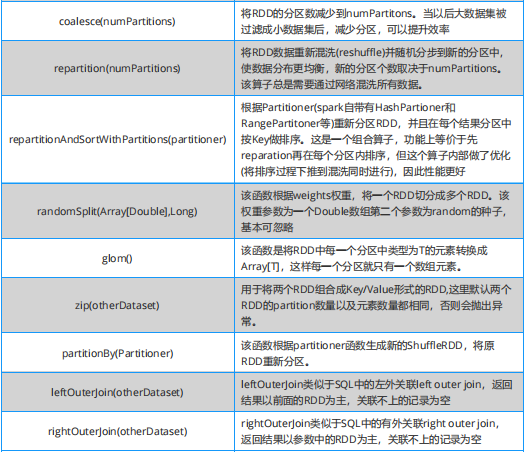
Spark 必知必會:Transformation 算子
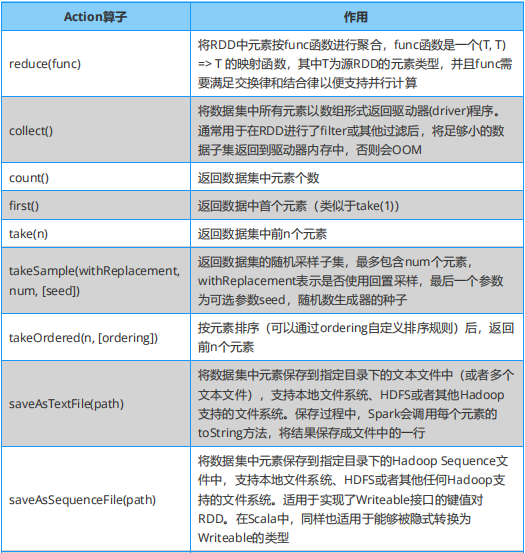
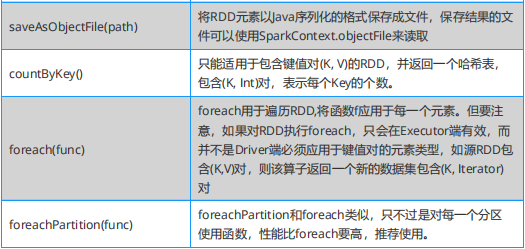
Spark 必知必會:Action算子
2.大數據分布式文件系統之Hadoop 必知必會
內容包括:Hadoop Shell ,HDFS 命令有 hadoop fs 和 hdfs dfs 兩種風格,都可使用,效果相同。
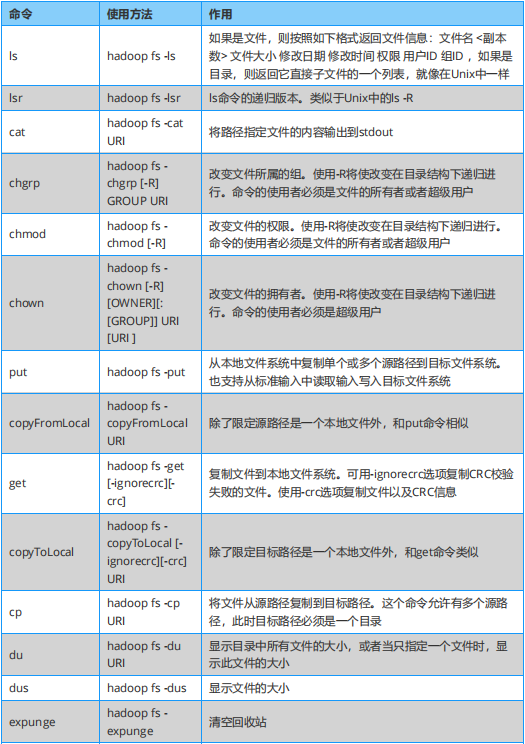
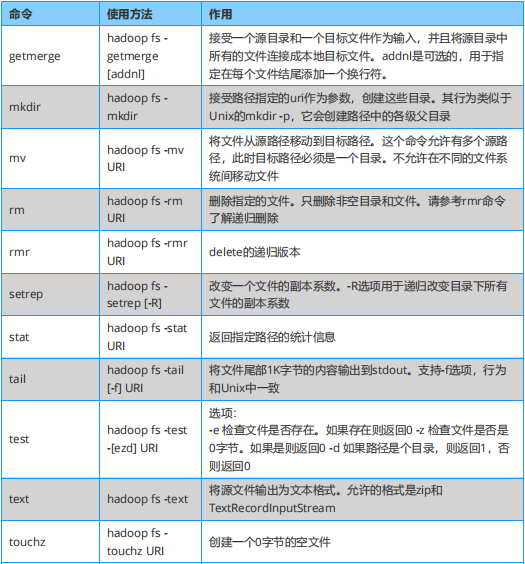
Hadoop 必知必會:Hadoop Shell
3.大數據分布式數據庫之Hive必知必會
Hive 的本質是將 SQL 語句轉換為 MapReduce 或者 spark 等任務執行,并可以針對數據倉庫進行分布式交互查詢。 內容包括:Hive 內置函數速查表,具體有關系、數學及邏輯運算符、數值計算、日期函數、條件函數、字符串函數、聚合函數、高級函數及窗口函數等。
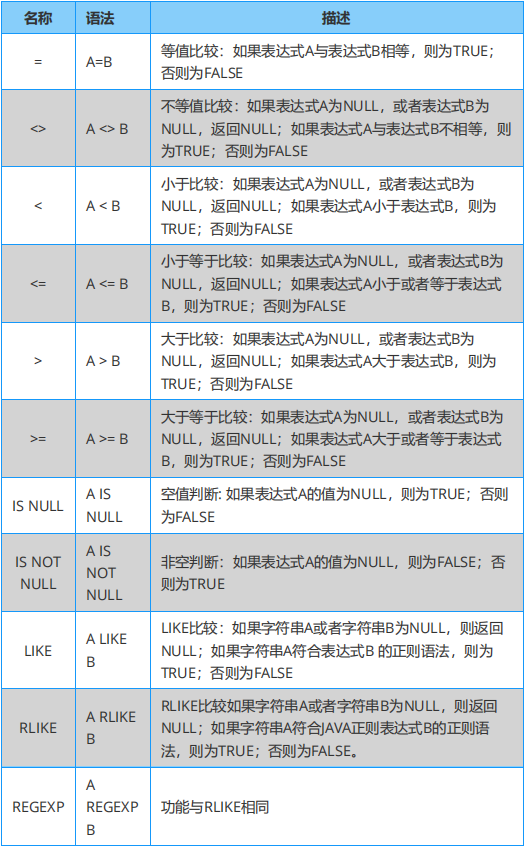
Hive 必知必會:關系運算符
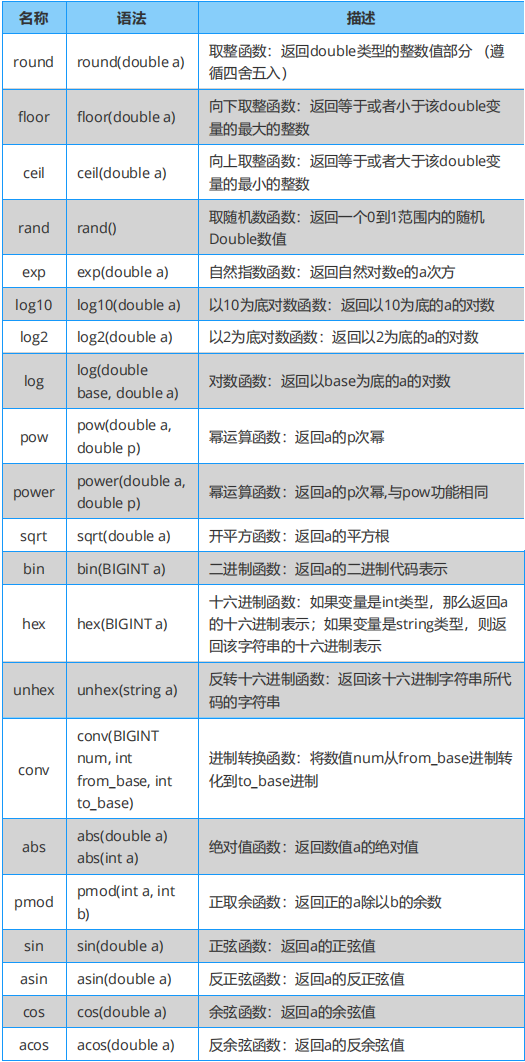
Hive 必知必會:數值計算
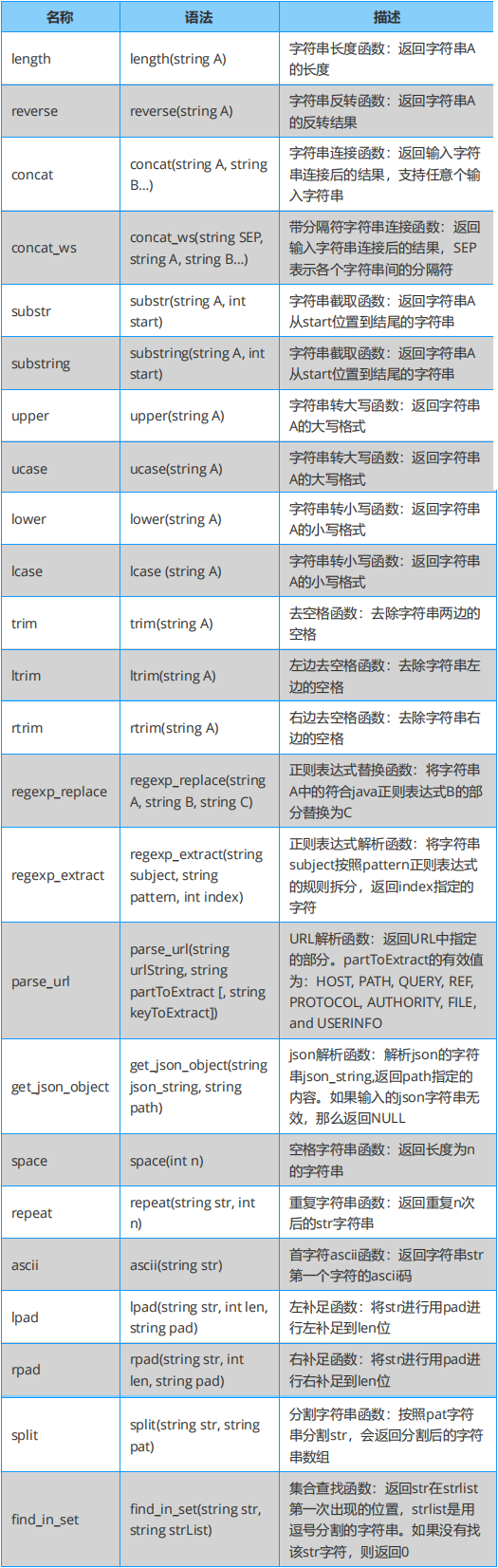
Hive 必知必會:字符串函數
原文標題:在百度,Spark,Hadoop,Hive ,哪個更香?
文章出處:【微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
-
SQL
+關注
關注
1文章
783瀏覽量
45051 -
機器學習
+關注
關注
66文章
8500瀏覽量
134498 -
Hadoop
+關注
關注
1文章
90瀏覽量
16438 -
SPARK
+關注
關注
1文章
106瀏覽量
20552 -
hive
+關注
關注
0文章
12瀏覽量
3996
原文標題:在百度,Spark,Hadoop,Hive ,哪個更香?
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
多通道電源管理芯片在分布式能源系統中的優化策略
分布式存儲數據恢復—虛擬機上hbase和hive數據庫數據恢復案例
Hadoop 生態系統在大數據處理中的應用與實踐
基于ptp的分布式系統設計
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據文件資產遷移
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據權限與基礎數據
raid 在大數據分析中的應用
emc技術在大數據分析中的角色
云計算在大數據分析中的應用
分布式輸電線路故障定位中的分布式是指什么


基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能
大數據從業者必知必會的Hive SQL調優技巧
探秘IO分布式模塊設計:讓大數據處理更高效






 工商網監
工商網監
評論