") 牛津博士論文學(xué)習(xí)重建和分割3D物體,突破AI和機(jī)器理解的界限
牛津博士論文學(xué)習(xí)重建和分割3D物體,突破AI和機(jī)器理解的界限
讓機(jī)器擁有像人類一樣感知 3D 物體和環(huán)境的能力,是人工智能領(lǐng)域的一項(xiàng)重要課題。牛津大學(xué)計(jì)算機(jī)科學(xué)系博士生 Bo Yang 在其畢業(yè)論文中詳細(xì)解讀了如何重建和分割 3D 物體,進(jìn)而賦予機(jī)器感知 3D 環(huán)境的能力,突破了人工智能和機(jī)器理解的界限。
賦予機(jī)器像人類一樣感知三維真實(shí)世界的能力,這是人工智能領(lǐng)域的一個(gè)根本且長(zhǎng)期存在的主題。考慮到視覺輸入具有不同類型,如二維或三維傳感器獲取的圖像或點(diǎn)云,該領(lǐng)域研究中一個(gè)重要的目標(biāo)是理解三維環(huán)境的幾何結(jié)構(gòu)和語(yǔ)義。
傳統(tǒng)方法通常利用手工構(gòu)建的特征來估計(jì)物體或場(chǎng)景的形狀和語(yǔ)義。但是,這些方法難以泛化至新物體和新場(chǎng)景,也很難克服視覺遮擋的關(guān)鍵問題。
今年九月畢業(yè)于牛津大學(xué)計(jì)算機(jī)科學(xué)系的博士生 Bo Yang 在其畢業(yè)論文《Learning to Reconstruct and Segment 3D Objects》中對(duì)這一主題展開了研究。與傳統(tǒng)方法不同,作者通過在大規(guī)模真實(shí)世界的三維數(shù)據(jù)上訓(xùn)練的深度神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)通用和魯棒表示,進(jìn)而理解場(chǎng)景以及場(chǎng)景中的物體。
總體而言,本文開發(fā)了一系列新型數(shù)據(jù)驅(qū)動(dòng)算法,以實(shí)現(xiàn)機(jī)器感知到真實(shí)世界三維環(huán)境的目的。作者表示:「本文可以說是突破了人工智能和機(jī)器理解的界限。」
這篇博士論文有 143 頁(yè),共六章。機(jī)器之心對(duì)該論文的核心內(nèi)容進(jìn)行了簡(jiǎn)要介紹,感興趣的讀者可以閱讀論文原文。
論文地址:https://arxiv.org/pdf/2010.09582.pdf
論文概述
作者在第 2 章首先回顧了以往 3D 物體重建和分割方面的研究工作,包括單視圖和多視圖 3D 物體重建、3D 點(diǎn)云分割、對(duì)抗生成網(wǎng)絡(luò)(GAN)、注意力機(jī)制以及集合上的深度學(xué)習(xí)。此外,本章最后還介紹了在單視圖 / 多視圖 3D 重建和 3D 點(diǎn)云分割方面,該研究相較于 SOTA 方法的新穎之處。
基于單視圖的 3D 物體重建
在第 3 章,作者提出以一種基于 GAN 的深度神經(jīng)架構(gòu)來從單一的深度視圖學(xué)習(xí)物體的密集 3D 形狀。作者將這種簡(jiǎn)單但有效的模型稱為 3D-RecGAN++,它將殘差連接(skip-connected)的 3D 編碼器 - 解碼器和對(duì)抗學(xué)習(xí)結(jié)合,以生成單一 2.5D 視圖條件下的完整細(xì)粒度 3D 結(jié)構(gòu)。該模型網(wǎng)絡(luò)架構(gòu)的訓(xùn)練和測(cè)試流程如下圖所示:
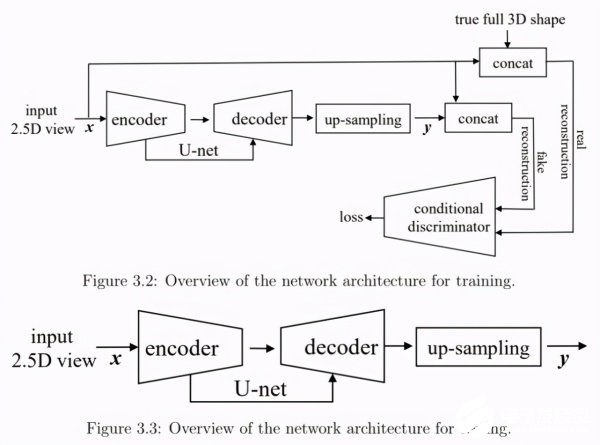
接著,作者利用條件對(duì)抗訓(xùn)練來細(xì)化編碼器 - 解碼器估計(jì)的 3D 形狀,其中用于 3D 形狀細(xì)化的判別器結(jié)構(gòu)示意圖如下:
最后,作者將提出的 3D-RecGAN++ 與 SOTA 方法做了對(duì)比,并進(jìn)行了控制變量研究。在合成和真實(shí)數(shù)據(jù)集上的大量實(shí)驗(yàn)結(jié)果表明,該模型性能良好。
基于多視圖的 3D 物體重建
在第 4 章,作者提出以一種新的基于注意力機(jī)制的神經(jīng)模塊來從多視圖中推理出更好的 3D 物體形狀。這種簡(jiǎn)單但高效的注意力聚合模塊被稱為 AttSets,其結(jié)構(gòu)如下圖所示。與現(xiàn)有方法相比,這種方法可以學(xué)習(xí)從不同圖像中聚合有用信息。
此外,研究者還引入了兩階段訓(xùn)練算法,以確保在給出一定數(shù)量輸入圖像的情況下,預(yù)估的 3D 形狀具有魯棒性。研究者在多個(gè)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),證明該方法能夠精確地恢復(fù)物體的 3D 形狀。
從點(diǎn)云中學(xué)習(xí)分割 3D 物體
在第五章中,研究者提出了一個(gè)新的框架來識(shí)別大規(guī)模 3D 場(chǎng)景中的所有單個(gè) 3D 物體。與現(xiàn)有的研究相比,該研究的框架能夠直接并且同時(shí)進(jìn)行檢測(cè)、分割和識(shí)別所有的目標(biāo)實(shí)例,而無需任何繁瑣的前 / 后處理步驟。研究者在多個(gè)大型實(shí)際數(shù)據(jù)集上展現(xiàn)了該方法相對(duì)于基線的性能提升。
作者介紹
本文作者 Bo Yang 現(xiàn)為香港理工大學(xué)計(jì)算機(jī)系助理教授。他本科和碩士分別畢業(yè)于北京郵電大學(xué)和香港大學(xué),然后進(jìn)入牛津大學(xué)計(jì)算機(jī)科學(xué)系攻讀博士學(xué)位,其導(dǎo)師為 Niki Trigoni 和 Andrew Markham 教授。
Bo Yang 作為一作以及合著的論文曾被《計(jì)算機(jī)視覺國(guó)際期刊》(IJCV)以及 NeurIPS 和 CVPR 等學(xué)術(shù)會(huì)議接收,谷歌學(xué)術(shù)主頁(yè)上顯示他共著有 22 篇論文,被引用數(shù)超過 400。
論文目錄如下:
責(zé)任編輯:PSY
-
AI
+關(guān)注
關(guān)注
88文章
34591瀏覽量
276289 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134243 -
3D物體識(shí)別
+關(guān)注
關(guān)注
0文章
3瀏覽量
6367
發(fā)布評(píng)論請(qǐng)先 登錄
人形機(jī)器人 3D 視覺路線之爭(zhēng):激光雷達(dá)、雙目和 3D - ToF 誰(shuí)更勝一籌?
NVIDIA助力影眸科技3D生成工具Rodin升級(jí)
將應(yīng)用程序工具套件集成到Unity 3D OpenVINO?過程中遇到\"DLLNotFound異常\"錯(cuò)誤怎么解決?
騰訊混元3D AI創(chuàng)作引擎正式發(fā)布
騰訊混元3D AI創(chuàng)作引擎正式上線
3D打印技術(shù)在材料、工藝方面的突破

3D掃描技術(shù)醫(yī)療領(lǐng)域創(chuàng)新實(shí)踐,積木易搭3D掃描儀Mole助力定制個(gè)性化手臂康復(fù)輔具





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論