 基于神經轉移模型的論辯挖掘任務
基于神經轉移模型的論辯挖掘任務
引言
論辯挖掘任務旨在識別文本中的論辯結構,近年來受到了廣泛的關注。在信息檢索等諸多領域里,論辯挖掘取得了卓越的進展。通常來說,論辯挖掘包含兩個子任務:1)對于論點進行分類;2)對于論點之間的關系進行分類。
本次分享我們將介紹兩篇來自ACL2021和一篇來自EMNLP2021的論辯挖掘相關論文。第一篇文章提出了一種基于神經轉移的論辯挖掘模型;第二篇文章提出了一種評估論證充分性的新方法;第三篇文章對于推文的論辯挖掘定義為一種新的文本分類任務。
文章概覽
1.基于神經轉移的論辯挖掘模型(A Neural Transition-based Model for Argumentation Mining)
論文提出了一種針對論辯挖掘任務的新方法,該方法通過產生一系列的動作來逐步構建出一個論證圖,從而有效地避免了枚舉操作;此外,該方法還可以在不引入任何新的結構約束條件下處理樹形(tree)或非樹形(non-tree)的結構化論證。試驗結果表明,該模型在兩個不同結構的公開數據集上達到了最優性能。
論文地址:https://aclanthology.org/2021.acl-long.497
2.基于結論生成的論證充分性評估(Assessing the Sufficiency of Arguments through Conclusion Generation)
論文提出了一種針對論證充分性評估的新方法,即假設充分的論證所生成的結論是可以由其前提(premise)生成的。為了驗證猜想,文章基于大規模預訓練語言模型來探索充分性評估的潛力。實驗結果表明,該方法性能達到最優,F1-score高達0.885。
論文地址:https://aclanthology.org/2021.argmining-1.7
3. 基于推文的論辯挖掘:計劃生育立場辯論的案例研究(Argument Mining on Twitter: A Case Study on the Planned Parenthood Debate)
對于推文的論辯挖掘,論文用一種新的方式定義了該問題。由于主張在推文中很容易被識別出來,所以文章的重點就在于識別出支持或反對主張的前提,即將該問題定義為文本分類任務。論文提供了一個新的數據集,并且通過分析信息最豐富的文本,論文在推文中挖掘出了突出論點。
論文地址:https://aclanthology.org/2021.argmining-1.1
論文細節
1

動機
論辯挖掘(AM)其中一個子任務的目的是從文本中自動地識別出論點之間是否有關(ARI)。由于論點之間的語義關系是非常復雜的,所以論點之間的關系識別是論辯挖掘任務中最具有挑戰性的。而大多數現有的方法都是通過枚舉出論點之間所有可能的配對來確定它們之間是否有關。但是大多數論點之間是無關的,所以將所有的論點進行配對會使得效率極低并且會造成類別不平衡的問題。此外,對于樹型結構來講,每一個論點至多有一個“出邊(outgoing)”來指向另一個論點;對于非樹型結構則沒有這種限制。由于論證的復雜性,到目前為止,還沒有一種通用的方法可以同時解決樹型或非樹型的論證結構。
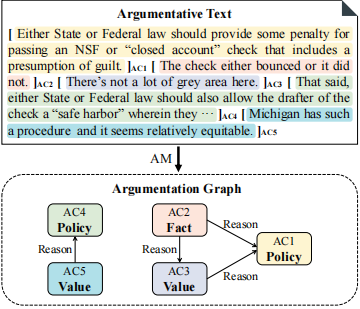
任務定義
由于論文假設AM任務的第一階段已經完成,即已經將論點句子從文本中識別出來,所以論文的任務分為以下兩部分:1)對論點(AC)進行分類;2)識別論點之間是否存在關聯,從而得到一個有向論證圖,其中論證圖的節點表示論點,有向邊表示論點之間的存在關聯。同時,論文定義了包含了個單詞的段落以及包含個論點的集合,每一個論點由論點的開始位置和結束位置來表示。
模型方法
轉移系統(Transition System)
轉移系統包含了六種動作(actions),不同的動作將會以不同的方式改變解析狀態(parser state):
:當非空并且不在之中,從彈出,然后將移到的頂部。
:當非空并且在之中,從和刪除,保持不變。
:當為空,從中刪除,并保持和不變。
:當為空,從中刪除,并為到分配一條有向邊。
:當非空,從彈出,然后將移到的頂部,并為到分配一條有向邊,并且將添加到之中。這一策略有利于挖掘出更多與有關的有向邊 。
:從中刪除,并為到分配一條有向邊。

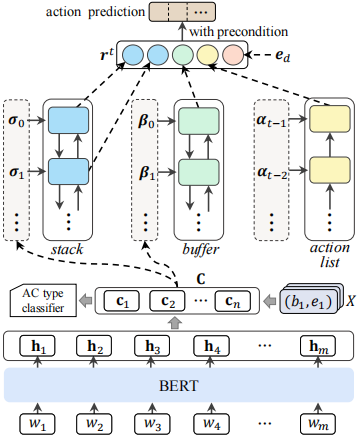
狀態表示(State Representation)
文章用BERT來獲得論點的表示,用LSTM來編碼、和的長期依賴。
論點的表示將段落傳入BERT得到文本表示矩陣,其中表示第個單詞的詞向量,表示BERT最后一層的向量維度。對于論點,文章通過平均池化操作來獲得論點的表示,具體來說:
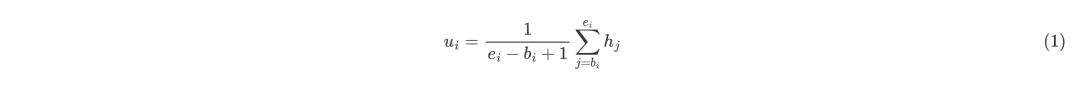
其中表示第個論點。另外,對于論點的表示,文章結合了一些額外的特征:詞袋特征、位置編碼以及段落類型編碼。將其他特征歸結為,此時第個論點表示為和的組合:
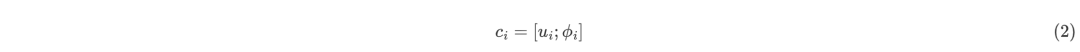
因此,在段落中的論點可以表示為。
解析狀態的表示在每一時間步,文章將解析狀態表示為,表示,存儲處理過的論點;表示,存儲未處理的論點;表示,記錄之后需要被刪除的論點;表示,記錄歷史動作。為了獲得的文本表示,將它傳遞給BiLSTM:
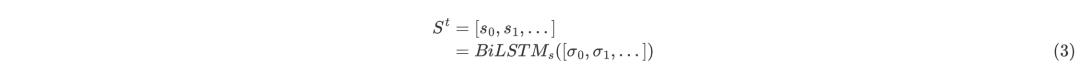
其中,為的長度,為隱藏元的數量;同理的文本表示為:
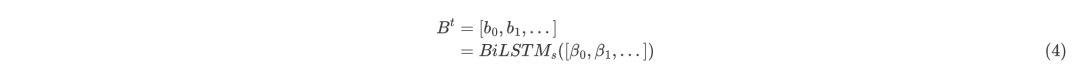
其中,為的長度。對于歷史動作信息,文中中采用單向LSTM來編碼:
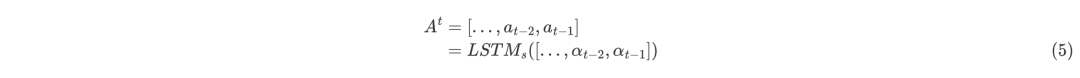
其中,為的長度。考慮到之間的相對距離對于確定它們之間是否有關來說是非常好的特征,所以文章將這種相對距離嵌入為,因此,解析狀態可以表示為:
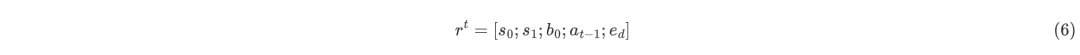
其中和表示中的第一個和第二個元素,表示中的第一個元素。
動作預測首先通過多層感知機將降維到,之后再通過softmax預測動作的概率。
實驗
數據集
Persuasive Essays (PE)該數據集包含402篇學生議論文,1833個段落。論點分為三種:Major-Claim,Claim和Premise。PE數據集中每個論點最多只有一條“出邊”,即符合樹型結構。
CDCP該數據集一共包含731個段落。論點分為五類:Reference,Fact,Testimony,Value和Policy。該數據集每個論點可以有多條“出邊”,屬于非樹型結構。
實驗結果
實驗結果表明,文章提出的模型在兩個數據集上的結果均為最優。
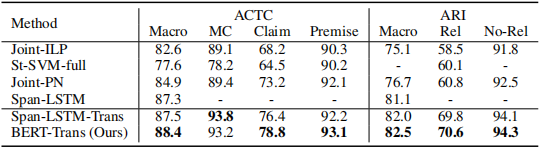

消融實驗: 驗證了文章提出的模型的優越性。
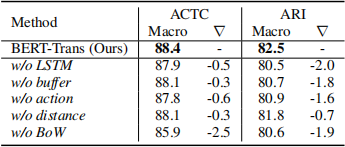
模型復雜度:之前的研究是對任意兩個論點進行配對,模型復雜度高達,而論文提出的模型可以將時間復雜度降為。
2

動機
在之前的研究中,總是將論證的充分性評估建模為標準的文本分類任務,并且用傳統的卷積神經網絡和特征提取的方式來處理。然而為了進一步提高性能,研究者們試圖將文本中直接可用的信息進行整合,但是現有的工作中既沒有考慮論證的前提和結論,也沒有考慮結論和前提之間的關系。由此作者提出了一種假設:只有充分的論證才可能從“前提”中推斷出“結論”。由于論證質量評估任務中幾乎沒有考慮過大規模預訓練語言模型所帶來的編碼信息,所以作者提出基于預訓練語言模型來探索充分性評估的潛力。
任務定義
論證的充分性是指是否可以通過論證的前提來合理地推斷出結論。文章作者研究了由論證的前提自動生成結論是否有利于論證充分性的計算評估,作者旨在通過將生成的結論與原始標注相結合,進而從不充分的論證中挖掘出充分的論證。

文章貢獻
語言模型可以生成與人類說話方式類似的論證結論。
文章提出的方法可以在論證充分性評估中達到SOTA效果。
深入討論了在論證的充分性評估中結構注釋的重要性。
模型方法
方法由兩階段來實現:
在對原始結論進行掩碼操作的論證中得到預訓練語言模型,之后通過該模型來自動的生成結論。
其次,通過對原始輸入論證的的8個實驗,利用生成的結論來評估論證的充分性。
通過降噪來生成結論
BART-unsupervised 不對BART進行微調,使之作為baseline。
BART-supervised 通過在學生議論文數據集中微調BART,以便調整其降噪能力,進而生成結論。
充分性評估
通過在RoBERTa之后加入一個線性層來預測論證的前提是否可以合理地推斷出結論。
評估
評估生成結論的質量
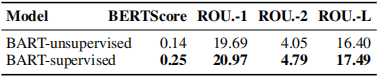
自動評估:通過對比BART-unsupervised與BART-supervised,可以發現微調之后的BART性能更優。
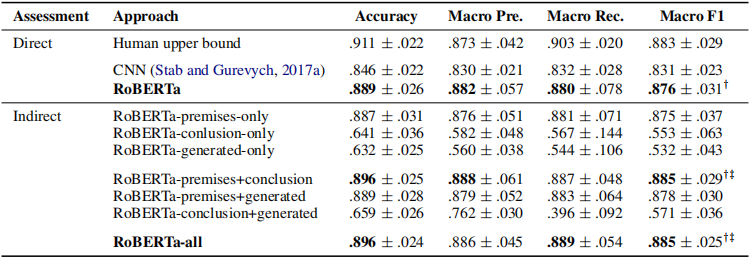
評價充分性評估
直接的充分性評估通過比較RoBERTa與CNN以及人工評估,可以發現經過微調的預訓練語言模型幾乎與人工評估一致。
間接的充分性評估通過對比7種不同的輸入特征可以發現,當綜合了全部特征或者只包含論證的前提以及原始結論時,模型的性能最優。
RoBERTa-premises-only 將原始結論進行掩碼操作之后,再作為模型的輸入。
RoBERTa-conclusion-only 只是將原始結論作為模型的輸入。
RoBERTa-generated-only 只用生成的結論作為模型的輸入。
RoBERTa-premises+conclusion 在原始輸入中對原始結論進行標記之后再作為模型輸入。
RoBERTa-premises+generated 對原始的結論進行掩碼操作并且加入生成的結論來作為模型的輸入。
RoBERTa-conclusion+generated 將原始結論以及生成的結論作為模型的輸入。
RoBERTa-all 結合所有的特征作為模型的輸入。
3

動機
推特是一個很受歡迎的社交平臺,很多網友會在推特上分享自己的觀點。這些信息對決策者、營銷人員和社會科學家來說是無價的。然而,在推特上挖掘論點的努力是有限的,主要是因為一條推文通常太短,不能包含一個完整的論點——既有主張,也有前提。由于這個原因,現有的基于推特的論辯挖掘方法通常側重于識別主張(claim)或者是前提(premise),而不能同時識別出兩者。這并不是理想的,因為作為支持主張的證據同樣是非常重要的。
任務定義
論文就是否支持計劃生育問題,在推特了獲得了24,100條推文作為論文數據集,并且定義了“claim-hashtag”表示帶有主張的推文,“premise-tweet”表示帶有前提的推文。之所以選擇計劃生育角度,是因為關于計劃生育的辯論是多方面的,其中包括女權,人權以及健康醫療等諸多社會話題從論辯挖掘的角度來說,帶有主張的推文可以通過簡單的文本匹配來檢索到。因此,文章的主要任務就是對于給定的推文,判斷其是否為“前提”,即論文將該任務定義為文本分類任務。

文章貢獻
論文提出了一個新的解決問題的方法,用來在推特上挖掘包含主張與前提的完整論點。
論文提供了一個由24,100條推文組成的新標注數據集,它的數據量是之前關于推特的數據集的10到80倍。
通過分析信息最豐富的文本,論文在推文中挖掘出了支持和反對資助計劃生育的突出論點。
數據集
標注人員將每一條推文分類為以下三種類別之一,從而挖掘出包含完整論點的推文:
SUPPORT WITH REASON:用戶支持或反對主張并且給出了原因,無論原因是否有效。
SUPPORT WITHOUT REASON:用戶僅僅支持或反對主張,但是并沒有給出原因。
NO EXPLICIT SUPPORT:用戶對主張表示中立或者立場不明確。

模型方法
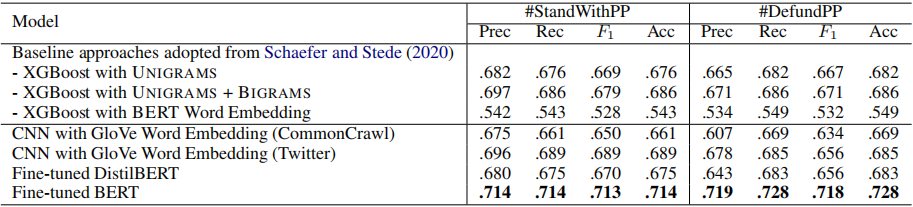
微調BERT在BERT之后加上全連接層并且用ReLu作為激活函數。此外,文章還驗證了DistilBERT的性能,DistilBERT是比BERT在結構上要簡單,并且在一些特殊的下游任務中,性能可以與BERT相媲美。
CNNBERT的注意力機制被證明可以有效地捕捉到文本之間的長短期記憶,但是由于推文一般都是很簡短的,所以單純使用CNN也是有效的,對于單詞的嵌入操作則用GloVe詞向量即可。
XGBoostXGBoost在一些文本分類任務中非常有效,論文將XGBoost的變體模型作為baseline。
實驗結果
實驗結果表明,微調BERT的性能最優。
SHAP值代表對于給定特征,模型對文本分類的影響程度。通過分析微調BERT的SHAP值,可以發現在SUPPORT WITH REASON中,SHAP值越高,意味著該特征越有可能成為突出特征。例如,在支持計劃生育的文本中,“女權”或者“健康服務”的SHAP值排名靠前。當這類詞出現時,該文本最可能被分為SUPPORT WITH REASON中。

審核編輯 :李倩
-
模型
+關注
關注
1文章
3499瀏覽量
50058 -
語言模型
+關注
關注
0文章
560瀏覽量
10689
原文標題:ACL&EMNLP'21 | 基于神經轉移模型的論辯挖掘任務
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論