") 使用NVIDIA FLARE開發(fā)更具通用性的AI模型
使用NVIDIA FLARE開發(fā)更具通用性的AI模型

聯(lián)邦學(xué)習(xí)( FL )已成為許多實(shí)際應(yīng)用的現(xiàn)實(shí)。它使全球范圍內(nèi)的跨國合作能夠構(gòu)建更健壯、更通用的機(jī)器學(xué)習(xí)和人工智能模型。
NVIDIA FLARE v2.0 是一款開源的 FL SDK ,通過共享模型權(quán)重而非私有數(shù)據(jù),數(shù)據(jù)科學(xué)家可以更輕松地協(xié)作開發(fā)更具通用性的健壯人工智能模型。
對于醫(yī)療保健應(yīng)用程序,這在數(shù)據(jù)受患者保護(hù)、某些患者類型和疾病的數(shù)據(jù)可能稀少,或者數(shù)據(jù)在儀器類型、性別和地理位置上缺乏多樣性的情況下尤其有益。
查看標(biāo)志
NVIDIA FLARE 代表 聯(lián)合學(xué)習(xí)應(yīng)用程序運(yùn)行時環(huán)境 。它是引擎的基礎(chǔ)NVIDIA Clara Train FL 軟件,它已經(jīng)被用于醫(yī)學(xué)成像、遺傳分析、腫瘤學(xué)和 COVID-19 研究中的人工智能應(yīng)用。 SDK 使研究人員和數(shù)據(jù)科學(xué)家能夠?qū)⑵洮F(xiàn)有的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)工作流調(diào)整為分布式范例,并使平臺開發(fā)人員能夠?yàn)榉植际蕉喾絽f(xié)作構(gòu)建安全、隱私保護(hù)的產(chǎn)品。
NVIDIA FLARE 是一個輕量級、靈活且可擴(kuò)展的分布式學(xué)習(xí)框架,在 Python 中實(shí)現(xiàn),與您的基礎(chǔ)培訓(xùn)庫無關(guān)。您可以在 PyTorch , TensorFlow ,甚至只是 NumPy 中實(shí)現(xiàn)自己的數(shù)據(jù)科學(xué)工作流,并在聯(lián)邦設(shè)置中應(yīng)用它們。
也許您希望實(shí)現(xiàn)流行的 聯(lián)邦平均( FedAvg )算法 。從初始全局模型開始,每個 FL 客戶機(jī)在其本地?cái)?shù)據(jù)上訓(xùn)練模型一段時間,并將模型更新發(fā)送到服務(wù)器進(jìn)行聚合。然后,服務(wù)器使用聚合更新來更新下一輪培訓(xùn)的全局模型。此過程將反復(fù)多次,直到模型收斂。
NVIDIA FLARE 提供可定制的控制器工作流,以幫助您實(shí)施 FedAvg 和其他 FL 算法,例如, 循環(huán)重量轉(zhuǎn)移 。它安排不同的任務(wù),例如深度學(xué)習(xí)培訓(xùn),在參與的 FL 客戶機(jī)上執(zhí)行。工作流使您能夠從每個客戶端收集結(jié)果(例如模型更新),并將其聚合以更新全局模型,并將更新的全局模型發(fā)回以供繼續(xù)培訓(xùn)。圖 1 顯示了原理。
每個 FL 客戶機(jī)充當(dāng)工人,請求執(zhí)行下一個任務(wù),例如模型培訓(xùn)。控制器提供任務(wù)后,工作人員執(zhí)行任務(wù)并將結(jié)果返回給控制器。在每次通信中,可以有可選的過濾器來處理任務(wù)數(shù)據(jù)或結(jié)果,例如, homomorphic encryption 和解密或差異隱私。
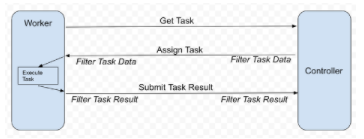
圖 1 。 NVIDIA FLARE 工作流
實(shí)現(xiàn) FedAvg 的任務(wù)可以是一個簡單的 PyTorch 程序,它為 CIFAR-10 訓(xùn)練一個分類模型。您當(dāng)?shù)氐呐嘤?xùn)師可能看起來像下面的代碼示例。為了簡單起見,我跳過了整個培訓(xùn)循環(huán)。
import torch import torch.nn as nn import torch.nn.functional as F from nvflare.apis.dxo import DXO, DataKind, MetaKey, from_shareable from nvflare.apis.executor import Executor from nvflare.apis.fl_constant import ReturnCode from nvflare.apis.fl_context import FLContext from nvflare.apis.shareable import Shareable, make_reply from nvflare.apis.signal import Signal from nvflare.app_common.app_constant import AppConstants class SimpleNetwork(nn.Module): def __init__(self): super(SimpleNetwork, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = torch.flatten(x, 1) # flatten all dimensions except batch x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x class SimpleTrainer(Executor): def __init__(self, train_task_name: str = AppConstants.TASK_TRAIN): super().__init__() self._train_task_name = train_task_name self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") self.model = SimpleNetwork() self.model.to(self.device) self.optimizer = torch.optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9) self.criterion = nn.CrossEntropyLoss() def execute(self, task_name: str, shareable: Shareable, fl_ctx: FLContext, abort_signal: Signal) -> Shareable: """ This function is an extended function from the superclass. As a supervised learning-based trainer, the train function will run training based on model weights from `shareable`. After finishing training, a new `Shareable` object will be submitted to server for aggregation.""" if task_name == self._train_task_name: epoch_len = 1 # Get current global model weights dxo = from_shareable(shareable) # Ensure data kind is weights. if not dxo.data_kind == DataKind.WEIGHTS: self.log_exception(fl_ctx, f"data_kind expected WEIGHTS but got {dxo.data_kind} instead.") return make_reply(ReturnCode.EXECUTION_EXCEPTION) # creates an empty Shareable with the return code # Convert weights to tensor and run training torch_weights = {k: torch.as_tensor(v) for k, v in dxo.data.items()} self.local_train(fl_ctx, torch_weights, epoch_len, abort_signal) # compute the differences between torch_weights and the now locally trained model model_diff = ... # build the shareable using a Data Exchange Object (DXO) dxo = DXO(data_kind=DataKind.WEIGHT_DIFF, data=model_diff) dxo.set_meta_prop(MetaKey.NUM_STEPS_CURRENT_ROUND, epoch_len) self.log_info(fl_ctx, "Local training finished. Returning shareable") return dxo.to_shareable() else: return make_reply(ReturnCode.TASK_UNKNOWN) def local_train(self, fl_ctx, weights, epoch_len, abort_signal): # Your training routine should respect the abort_signal. ... # Your local training loop ... for e in range(epoch_len): ... if abort_signal.triggered: self._abort_execution() ... def _abort_execution(self, return_code=ReturnCode.ERROR) -> Shareable: return make_reply(return_code)
您可以看到您的任務(wù)實(shí)現(xiàn)可以執(zhí)行許多不同的任務(wù)。您可以計(jì)算每個客戶機(jī)上的摘要統(tǒng)計(jì)信息,并與服務(wù)器共享(記住隱私限制),執(zhí)行本地?cái)?shù)據(jù)的預(yù)處理,或者評估已經(jīng)訓(xùn)練過的模型。
在 FL 培訓(xùn)期間,您可以在每輪培訓(xùn)開始時繪制全局模型的性能。對于本例,我們在 CIFAR-10 的異構(gòu)數(shù)據(jù)拆分上運(yùn)行了八個客戶端。在下圖(圖 2 )中,我顯示了默認(rèn)情況下 NVIDIA FLARE 2.0 中可用的不同配置:
FedAvg
FedProx
FedOpt
使用同態(tài)加密進(jìn)行安全聚合的 FedAvg ( FedAvg HE )
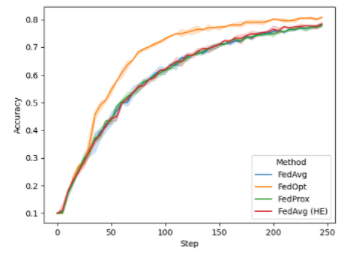
圖 2 。訓(xùn)練期間不同 FL 算法全局模型的驗(yàn)證精度
雖然 FedAvg 、 FedAvg HE 和 FedProx 在這項(xiàng)任務(wù)中的性能相當(dāng),但您可以使用 FedOpt 設(shè)置觀察到改進(jìn)的收斂性,該設(shè)置使用 SGD with momentum 來更新服務(wù)器上的全局模型。
整個 FL 系統(tǒng)可以使用管理 API 進(jìn)行控制,以自動啟動和操作不同配置的任務(wù)和工作流。 NVIDIA 還提供了一個全面的資源調(diào)配系統(tǒng),可在現(xiàn)實(shí)世界中輕松安全地部署 FL 應(yīng)用程序,同時還提供了運(yùn)行本地 FL 模擬的概念驗(yàn)證研究。
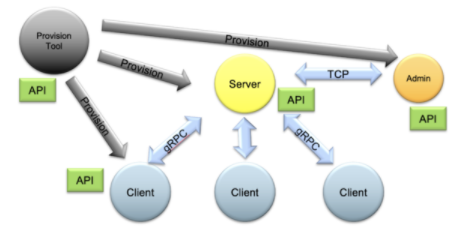
圖 3 。 NVIDIA FLARE 供應(yīng)、啟動、操作( PSO )組件及其 API
開始
NVIDIA FLARE 使 FL 可用于更廣泛的應(yīng)用。潛在使用案例包括幫助能源公司分析地震和井筒數(shù)據(jù)、制造商優(yōu)化工廠運(yùn)營以及金融公司改進(jìn)欺詐檢測模型。
關(guān)于作者
Holger Roth 是 NVIDIA 的高級應(yīng)用研究科學(xué)家,專注于醫(yī)學(xué)成像的深度學(xué)習(xí)。在過去幾年中,他一直與臨床醫(yī)生和學(xué)者密切合作,為放射應(yīng)用開發(fā)基于深度學(xué)習(xí)的醫(yī)學(xué)圖像計(jì)算和計(jì)算機(jī)輔助檢測模型。他擁有博士學(xué)位。來自英國倫敦大學(xué)學(xué)院。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5298瀏覽量
106247 -
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7654瀏覽量
90656 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5560瀏覽量
122745
發(fā)布評論請先 登錄
首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
英偉達(dá)GTC2025亮點(diǎn) NVIDIA推出Cosmos世界基礎(chǔ)模型和物理AI數(shù)據(jù)工具的重大更新
通用汽車和NVIDIA合作構(gòu)建定制化AI系統(tǒng)
NVIDIA 推出開放推理 AI 模型系列,助力開發(fā)者和企業(yè)構(gòu)建代理式 AI 平臺

NVIDIA發(fā)布Cosmos平臺,加速物理AI開發(fā)
NVIDIA推出加速物理AI開發(fā)的Cosmos世界基礎(chǔ)模型
NVIDIA推出面向RTX AI PC的AI基礎(chǔ)模型
NVIDIA推出多個生成式AI模型和藍(lán)圖
NVIDIA推出全新生成式AI模型Fugatto
全新NVIDIA NIM微服務(wù)實(shí)現(xiàn)突破性進(jìn)展
使用全新NVIDIA AI Blueprint開發(fā)視覺AI智能體
NVIDIA助力提供多樣、靈活的模型選擇
NVIDIA RTX AI套件簡化AI驅(qū)動的應(yīng)用開發(fā)
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型

揭秘NVIDIA AI Workbench 如何助力應(yīng)用開發(fā)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論